AWS 기술 블로그
Category: Compute

AWS Transform for migrations, 이제 13개 언어에 대한 현지화 지원
이 글은 AWS Blog의 “AWS Transform for migrations now supports localization for 13 languages” by Jamie Vinciguerra and Jason Amaya 게시글을 번역한 글 입니다. 마이그레이션 프로젝트를 수행하는 조직이 항상 하나의 공통 언어로 운영되는 것은 아닙니다. 마이그레이션 팀은 여러 지역에 걸쳐 있으며, 워크로드에 가장 가까운 사람들이 종속성, 비즈니스 컨텍스트, 운영 리스크를 가장 잘 이해하고 있는 경우가 […]

분산 학습을 위한 AWS 컴퓨트 선택 가이드 (1편: 모델 규모와 하드웨어 선택)
대규모 언어 모델(LLM) 학습을 준비하는 팀이 가장 먼저 부딪히는 질문은 결국 “어떤 GPU를 얼마나, 어떻게 확보할 것인가”로 귀결됩니다. 그러나 이 질문은 H100이냐 B200이냐를 고르는 단순한 하드웨어 선택으로 끝나지 않습니다. 하나의 노드로 충분한지, 아니면 여러 노드로 확장해야 하는지, On-Demand로 그때그때 띄울지, Capacity Block으로 미리 예약할지, 평범한 EC2 클러스터로 감당이 되는지, 아니면 Amazon EC2 울트라클러스터(UltraClusters)나 Amazon EC2 […]

스트라드비젼의 AWS 클라우드 기반 피지컬 AI End-to-End 파이프라인 가속화 사례
자동차가 스스로 주변상황을 인식하고 판단하려면, 수백, 수천만 장의 도로 이미지 데이터가 필요합니다. 그런데 만약 AI가 학습해야 할 상황이 현실에서는 거의 일어나지 않는 희귀한 장면이라면 어떨까요? 예를 들어, 사람이 차 바로 앞으로 뛰어드는 상황이나, 인도 도로 한복판에 소가 누워 있는 상황을 카메라로 찍어 모아야 한다면? 스트라드비젼은 자동차의 카메라가 세상을 보고 이해할 수 있게 하는 Vision AI […]

하나투어의 Amazon Neptune과 Amazon Bedrock AgentCore를 활용한 여행상품 기획 에이전트 구축기
“오사카 3박 4일, 벚꽃 시즌, 예산 150만 원.” 이 조건 한 줄로 여행 패키지 기획 초안을 만들 수 있다면 어떨까요? 하나투어는 상품기획자(MD, Merchandiser)가 수작업으로 2~3일에 걸쳐 만들던 패키지 일정 초안을, 지식 그래프 기반의 AI 에이전트로 2~3분 만에 생성하는 시스템을 구축했습니다. 이 글에서는 하나투어가 두 번의 시행착오 끝에 Amazon Neptune 기반 GraphRAG(그래프 기반 검색 증강 생성)와 Amazon Bedrock AgentCore에 도달하기까지의 […]

Amazon Bedrock AgentCore로 구축하는 AgentOps (2): 관측성, 평가, 그리고 AgentOps 라이프사이클
본 사례는 AWS 3A(Agentic AI Acceleration) 프로그램에서 재사용 가능한 레퍼런스 asset으로 개발되었습니다. 이 글은 프로덕션 환경에서 에이전틱 AI를 운영하기 위한 2부작 시리즈입니다. 파운데이션을 세우는 것에서 시작해, 이를 안정적으로 운영하는 AgentOps까지 다루며, 이번 글은 그 두 번째 편입니다. Part 1: Amazon Bedrock AgentCore로 구축하는 AgentOps (1): 파운데이션과 게이트웨이 Part 2: Amazon Bedrock AgentCore로 구축하는 AgentOps (2): […]

Amazon Bedrock AgentCore로 구축하는 AgentOps (1): 파운데이션과 게이트웨이
본 사례는 AWS 3A(Agentic AI Acceleration) 프로그램에서 재사용 가능한 레퍼런스 asset으로 개발되었습니다. 이 글은 프로덕션 환경에서 에이전틱 AI를 운영하기 위한 2부작 시리즈입니다. 파운데이션을 세우는 것에서 시작해, 이를 안정적으로 운영하는 AgentOps까지 다룹니다. Part 1: Amazon Bedrock AgentCore로 구축하는 AgentOps (1): 파운데이션과 게이트웨이 (이번 글) Part 2: Amazon Bedrock AgentCore로 구축하는 AgentOps (2): 관측성, 평가 그리고 AgentOps […]

Amazon MWAA와 Bedrock AgentCore로 MCP 기반 클라우드 정책 에이전트 구축하기
개요 조직의 클라우드 인프라가 성장하면서 IAM 정책, 보안 그룹, 스토리지 설정, 네트워크 구성 등 수백 개의 정책과 리소스 설정이 여러 계정과 리전에 분산됩니다. DevOps 팀은 인프라 상태를 파악하고, SecOps 팀은 과도한 권한을 찾아내며, Compliance 팀은 규정 준수 여부를 감사하고, FinOps 팀은 리소스 사용 현황을 분석해야 합니다. 그러나 이 모든 팀이 동일한 데이터를 서로 다른 관점에서 […]

에잇퍼센트의 Kiro CLI 기반 Amazon ECS 현대화 여정
이 블로그는 에잇퍼센트와 AWS의 협업으로 작성되었습니다. 현업 운영을 병행하면서 2영업일 만에 레거시 서비스를 Amazon ECS로 전환하고, 월 운영 비용을 약 76% 절감할 수 있을까요? 에잇퍼센트는 AI 코딩 에이전트 Kiro CLI와 오픈소스 AI-Driven Modernization Prompt Sets를 결합해 이를 실현했습니다. 이번 글에서는 에잇퍼센트가 AWS Lift-On 프로그램의 지원을 받아, 소규모 백엔드 팀이 기능 개발과 장애 대응을 병행하면서도 Amazon […]
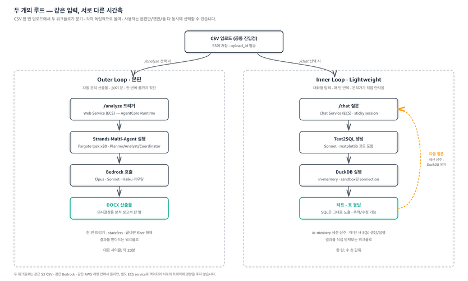
Inner Loop 엔지니어링으로 본 Deep Insight Chatbot – 대화형 분석 챗봇의 4가지 설계 결정
CSV 파일을 LLM에게 전달하고 차트를 생성하는 챗봇은 반나절이면 만듭니다. 하지만 같은 챗봇을 분석가가 매일 쓰게 만들려면 다른 질문에 답해야 합니다. 데이터가 AWS 계정 밖으로 나가지 않도록 어떻게 막을지, group by 하나에 수십 초 이상 걸리지 않게 어떻게 빠르게 답할지, 결과값을 분석가가 못 믿겠으면 어떻게 직접 열어보고 확인하게 할지, 수십 턴짜리 대화의 LLM 비용을 어떻게 줄일지. […]

프롬프트 인젝션 방어: AgentCore 기반 다층 보안 설계 패턴
들어가며 LLM 기반 에이전트를 프로덕션으로 옮기는 순간, 모든 팀이 한 번쯤 마주치는 질문이 있습니다. “에이전트가 다른 사용자의 데이터를 노출하지 않는다는 걸 어떻게 보장할 수 있나요?” 주문 내역, 의료 기록, 사내 문서, 금융 거래 – 도메인이 무엇이든 질문의 본질은 같습니다. 이 문제를 해결하기 위해 많은 팀이 처음에는 시스템 프롬프트로 해결하려고 합니다. 보안 규칙: – 사용자에게 내부 […]