AWS 기술 블로그
Inner Loop 엔지니어링으로 본 Deep Insight Chatbot – 대화형 분석 챗봇의 4가지 설계 결정
CSV 파일을 LLM에게 전달하고 차트를 생성하는 챗봇은 반나절이면 만듭니다. 하지만 같은 챗봇을 분석가가 매일 쓰게 만들려면 다른 질문에 답해야 합니다. 데이터가 AWS 계정 밖으로 나가지 않도록 어떻게 막을지, group by 하나에 수십 초 이상 걸리지 않게 어떻게 빠르게 답할지, 결과값을 분석가가 못 믿겠으면 어떻게 직접 열어보고 확인하게 할지, 수십 턴짜리 대화의 LLM 비용을 어떻게 줄일지. 이 네 가지가 “반나절 챗봇”과 “매일 쓰는 도구”를 가르는 질문입니다. 그 중에서도, 차트의 숫자가 원본과 일치하는지를 보장하는 데이터 정확성이 가장 중요한 판단 기준입니다.
이 글은 Deep Insight 시리즈의 네 번째 편입니다. Deep Insight는 데이터를 분석해 의사결정 산출물을 자동 생성하는 프로덕션 멀티 에이전트 시스템입니다. 앞선 세 편은 아키텍처 설계(1편), Context Engineering(2편), 하네스 엔지니어링(3편) 순서로 시스템의 세 층위를 다뤘고, 이번 4편은 “Inner Loop 엔지니어링으로 본 Deep Insight Chatbot, 대화형 분석 챗봇의 4가지 설계 결정”을 다룹니다.
[시리즈 블로그 보기]
- Part 1 – 프로덕션 Multi-Agent 시스템이 해결해야 할 5가지 문제 – Deep Insight 아키텍처로 배우는 실전 설계
- Part 2 – Context Window 한계를 넘어서 – Deep Insight 개발 여정으로 배우는 Context Engineering 실전 기법
- Part 3 – 하네스 엔지니어링으로 본 Deep Insight – 로컬 개발에서 프로덕션 운영까지의 설계 여정
- Part 4 – Inner Loop 엔지니어링으로 본 Deep Insight Lightweight – 대화형 분석 챗봇의 4가지 설계 결정
시작하며
소프트웨어 엔지니어링에는 inner loop와 outer loop라는 구분이 있습니다. Outer loop는 CI/CD처럼 “한 번 돌리면 완성품이 나오는” 느린 사이클, inner loop는 초 단위로 피드백을 받으며 반복하는 빠른 사이클입니다. 분석가의 작업도 마찬가지입니다 . 시리즈 1-3의 자동 분석이 분석의 Outer Loop라면, 분석가가 같은 데이터를 직접 파고드는 이번 챗봇은 분석의 Inner Loop입니다.
Outer Loop 편은 80여 개 Fargate task가 20여 분간 돌아 의사결정용 산출물을 자동 생성하는 무거운 워크플로입니다. 반면 Inner Loop는 같은 데이터셋을 두고 질문 → 차트 → 의문 → SQL 수정 → 다시 질문을 30초~몇 분 단위로 반복합니다. Outer Loop 편 워크플로를 이 빈도로 돌리기엔 비용도, 응답 지연도, 결과 형식(DOCX)도 맞지 않습니다.
이런 이유로 같은 데이터·같은 보안 원칙 위에 Inner Loop를 위한 별도 아키텍처를 하나 더 만들었습니다. 이 글은 그 Chatbot 편의 설계 기록입니다. Outer Loop를 위해 만들었던 도구를 Inner Loop에 그대로 쓰지 않고, Inner Loop의 요구에 맞춰 다시 설계한 4가지 설계 결정을 풀어냅니다.
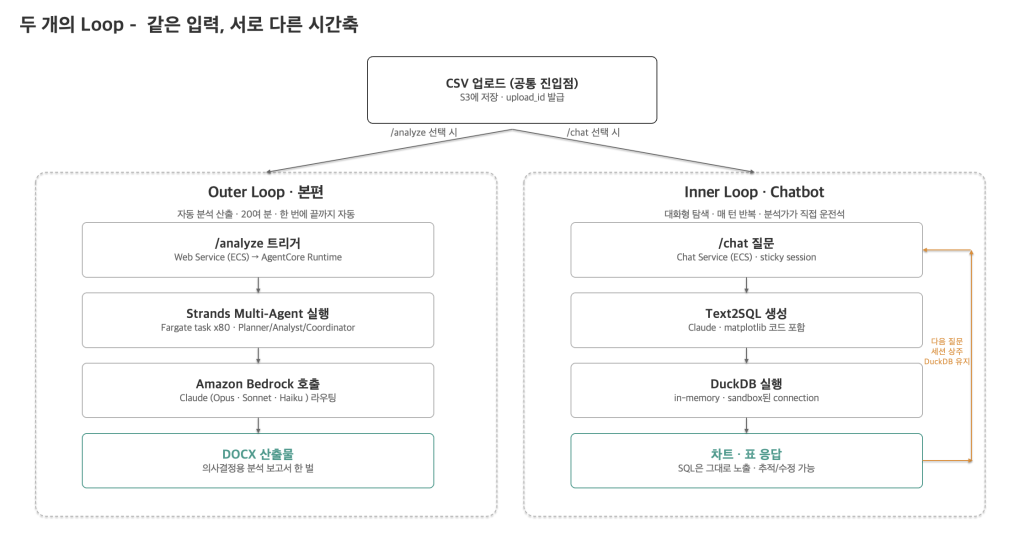
그림 1 – 분석의 Outer Loop vs Inner Loop
각 결정은 Inner Loop가 요구하는 4가지 속성인 데이터 보호 · 속도 · 신뢰성 · 비용 에 1:1로 답합니다.
| 속성 | 결정 | 한 줄 요약 |
| 데이터 보호 | 결정 1: DuckDB 샌드박싱 + Text2SQL | LLM은 SQL만 생성, 실행은 샌드박싱된 DuckDB이 담당하여 환각·유출 경로 모두 차단 |
| 속도 | 결정 2: 세션마다 OLAP 엔진 상주 | 세션마다 DuckDB 상주, 쿼리 응답 수백 ms |
| 신뢰성 | 결정 3: SQL 투명성 + 응답 스타일 강제 | SQL 노출 및 직접 수정/재실행 하여 분석가가 직접 검증 |
| 비용 | 결정 4: 멀티턴 비용 통제 | Prompt cache 90%+ hit, 불필요 호출 0회 |
이 4가지가 동시에 만족되어야 분석가가 “비싸고 느리고 못 믿겠어서” 챗봇을 끄고 원래 쓰던 분석 도구로 돌아가는 일을 막을 수 있습니다. 먼저 두 워크플로가 어떻게 인프라를 공유하는지 아키텍처 개요로 위치를 잡고, 이어서 4가지 결정을 하나씩 풀겠습니다.
아키텍처 개요
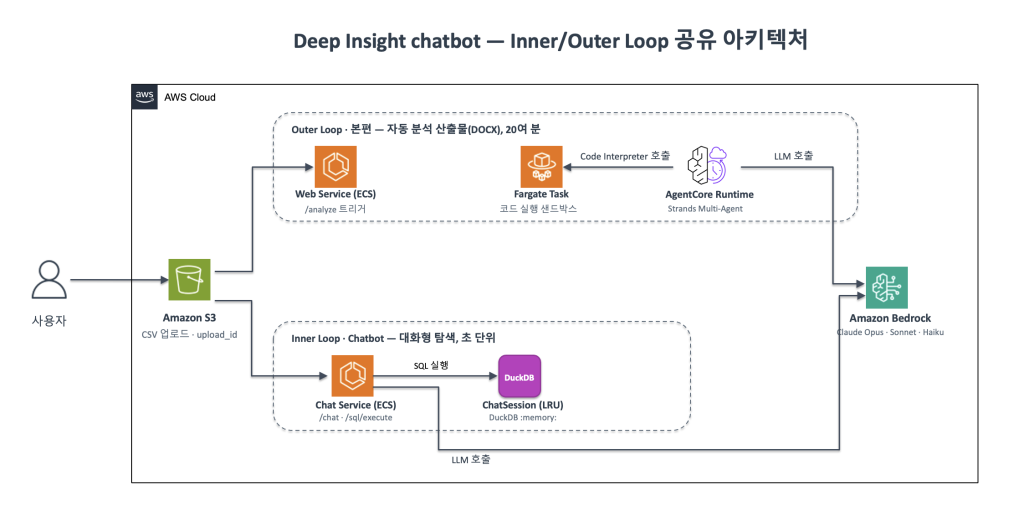
그림 2 – Deep Insight 아키텍처 – Outer Loop 과 Inner Loop 인프라 공유 구조
Outer Loop 편의 모델 라우팅(Planner=Opus, 그 외 분석 에이전트=Sonnet, Coordinator=Haiku)은 시리즈 1·2에서 다뤘습니다. 이 글의 챗 워크플로는 단일 모델(Sonnet)로만 돌아가므로, 이후 결정 1–4에서 모델 선택은 추가 변수가 아닙니다.
두 워크플로의 시작점은 같습니다. 사용자는 CSV를 한 번 업로드하면 S3에 저장되고 upload_id를 받습니다. 그 다음은 사용자의 선택입니다.
- Outer Loop만 – 의사결정에 인사이트를 줄 산출물을 자동으로 만들고 싶을 때 /analyze만 트리거
- 챗만 – 같은 데이터를 직접 탐색하고 싶을 때 /chat만 사용
- 둘 다 동시에 – 분석이 20여 분 도는 동안 챗으로 가설을 빠르게 검증
이 세 패턴이 자연스럽게 동작하려면 두 워크플로가 서로 영향을 주지 않아야 합니다. 그래서 Outer Loop 분석 워크플로(/analyze)와 Q&A 챗봇(/chat, /sql/execute)은 각각 별도 ECS service로 격리되어 있습니다. 챗 트래픽이 분석 SSE 스트림을 끊지 않고, 분석의 long-lived connection이 챗 응답을 막지 않습니다.
이 글의 주제인 Q&A 챗봇은 Chat service 안에서 처리됩니다. 업로드 단위로 in-memory 세션이 생성되고, 데이터는 프로세스 메모리 밖으로 나가지 않습니다. 세션 내부 구조와 LRU eviction 정책은 결정 2에서 다룹니다.
< 아래 유튜브 영상이 접근이 안되시는 분은 이 URL 사용하세요. “https://youtu.be/i5NoAIq7sDk?list=PLrAWXV_UoWzhwubfImuoz6GCHlZnrRdDc”>
그림 3 – Deep Insight Q&A 시연: 데이터 업로드부터 모델이 차트 형태까지 자가 결정하는 흐름
설계 결정 1: DuckDB 샌드박싱과 Text2SQL 채택
출발점: LLM이 데이터를 직접 읽지 않게 한다
가장 일반적인 패턴은 ChatGPT/Claude.ai처럼 provider의 sandbox에서 LLM이 CSV를 직접 읽고 Python을 실행하는 방식입니다. 이 방식은 Inner Loop와 두 가지 점에서 어긋납니다. LLM이 숫자를 기억해서 답하는 순간 추적이 끊기고, provider sandbox로 CSV를 올리면 데이터가 AWS 계정 밖으로 나가 Outer Loop 편의 보안 원칙(데이터가 계정 안에 머문다)과 충돌합니다.
그래서 DuckDB in-memory + Text2SQL 구조를 선택합니다. LLM은 SQL(차트가 필요하면 matplotlib 코드까지)만 생성하고, 실행은 Chat service의 DuckDB와 matplotlib이 담당합니다. 컨테이너에는 한국어 폰트(NanumGothic)와 matplotlib 스타일 helper가 영구 배포되어 있어, LLM이 어떤 차트 코드를 짜든 Outer Loop 편과 같은 시각 규칙을 따라 렌더링됩니다.
결과 숫자는 모두 DuckDB 실행기에서 나오므로 수치 자체에는 LLM 환각이 끼어들 자리가 없고(차트나 텍스트 요약은 LLM이 작성하므로 별도), 사용된 SQL은 그대로 사용자에게 노출돼 직접 추적하고 수정할 수 있습니다.
# deep-insight-web/chat_agent.py (발췌)
conn = duckdb.connect(":memory:")
conn.execute(
"CREATE TABLE data AS SELECT * FROM read_csv_auto(?, header=True)",
[csv_path],
)진짜 문제: 사용자에게 SQL을 노출하는 순간 공격면이 열린다
이 샌드박싱이 방어하는 위협은 두 가지입니다. (1) 사용자가 악의적 SQL로 데이터를 외부로 빼내는 것, (2) LLM이 환각으로 생성한 SQL이 의도치 않게 시스템 자원에 접근하는 것. 둘 다 같은 메커니즘으로 차단됩니다.
DuckDB에 read-only flag만 거는 건 부족합니다. read-only는 DML(INSERT/UPDATE/DELETE)을 막지만, 외부 접근 경로(COPY TO, read_csv(‘s3://…’), INSTALL)를 차단하지는 않습니다.
DuckDB는 기본 설정에서 COPY … TO ‘path’로 임의 디스크 경로에 쓰거나, SELECT * FROM read_csv(’s3://…’)로 외부 객체 스토리지를 읽거나, INSTALL/LOAD로 임의 확장을 끌어올 수 있습니다. SQL을 사용자에게 노출하는 순간 이게 전부 공격면이 됩니다.
선택한 방법: connection 자체를 sandbox로
CSV 로드 직후 connection을 샌드박싱(SQL이 메모리 안에서만 동작하도록 외부 디스크·네트워크·확장 접근을 차단)합니다.
# deep-insight-web/chat_agent.py (발췌)
# 1) CSV materialize
# table은 upload_id 기반 UUID로 시스템이 생성 — 사용자 입력값이 아님
conn.execute(
f"CREATE TABLE {table} AS SELECT * FROM read_csv_auto(?, header=True)",
[tmp_path],
)
# 2) 샌드박싱 - 외부 접근 차단
conn.execute("SET enable_external_access=false")
conn.execute("SET allow_unsigned_extensions=false")
conn.execute("SET lock_configuration=true") # 사용자 SQL이 위의 SET 명령을 되돌리지 못함
# 3) 디스크에 임시로 쓴 CSV는 즉시 삭제 - 메모리 테이블로 이미 옮겨졌고
# 샌드박싱된 connection은 더 이상 디스크를 읽을 수 없다
tmp_path.unlink()이 시점부터 사용자 SQL이 무엇을 보내든 다음은 모두 거부됩니다:
- COPY data TO ‘/tmp/leak.csv’ : Cannot execute statement: external access disabled
- SELECT * FROM read_csv(‘s3://anywhere/x.csv’) : 동일
- INSTALL httpfs; LOAD httpfs; : extension load 차단
- SET enable_external_access=true : configuration locked
왜 이 방식인가
- 메모리 테이블만 노출 : 사용자가 보는 것은 본인이 업로드한 CSV의 in-memory 사본 하나뿐. 그 외 어떤 것도 노출되지 않습니다.
- XSS 방어 : 백엔드가 to_html(escape=True)로 SQL 결과의 특수문자를 HTML entity로 변환하므로, 프론트가 innerHTML로 삽입해도 스크립트가 실행되지 않습니다.
- 공격면 자체를 줄임 : 입력 검증으로 막는 대신 connection 자체를 sandbox로 만듭니다.
설계 결정 2: pandas 대신 OLAP 엔진을 세션 단위로 메모리 상주
핵심 트레이드오프 – 메모리에 무엇을 둘 것인가
CSV 분석 챗봇이 “메모리 세션”을 두는 것 자체는 흔합니다. 매 메시지마다 컨테이너에 CSV를 다시 로드하면 챗봇의 “초 단위 응답”이라는 핵심 가치가 사라지니까요. 진짜 결정은 메모리에 무엇을 두느냐입니다.
가장 흔한 선택은 pandas DataFrame입니다. 손에 익고 가볍지만, 수백 MB CSV에서 group by·aggregation·window 함수 같은 분석 쿼리를 pandas의 기본 엔진으로 돌리면 수백 ms~수 초가 걸릴 수 있습니다. SQLite in-memory는 SQL 인터페이스는 주지만 행 지향 OLTP 엔진이라 분석 쿼리(특히 큰 group by)에 약합니다.
DuckDB는 컬럼 지향 OLAP 엔진으로, 벡터화 실행 방식 덕분에 동일 group by·aggregation 쿼리를 pandas 대비 수 배 이상 빠르게 처리합니다.
이 시스템은 DuckDB :memory: 인스턴스를 세션 단위로 상주시킵니다.
분석 쿼리가 빠르다는 건 분석가가 차트를 보고 떠올린 다음 질문을 망설임 없이 던질 수 있다는 뜻입니다. 한 번의 응답은 초 단위로 끝나고, 그 응답들이 모인 한 번의 탐색 사이클이 분 단위입니다 . Inner Loop의 초 단위 응답은 결국 이 엔진 선택에서 나옵니다.
엔진을 세션 단위로 메모리에 상주시키는 만큼 두 가지 안전장치를 답니다. 격리(세션 사이에 데이터가 새지 않도록)와 eviction(메모리가 무한히 쌓이지 않도록)
선택한 방법
업로드마다 ChatSession 1개를 만들고, 그 안에 DuckDB :memory: connection과 Strands Agent를 함께 둡니다.
# deep-insight-web/chat_agent.py (발췌)
class SessionManager:
def __init__(self, max_sessions: int = 32):
self._sessions: OrderedDict[str, ChatSession] = OrderedDict()
self._lock = threading.Lock()
self._max = max_sessions
def get_or_create(self, upload_id: str) -> ChatSession:
# ... LRU touch + create + evict ...업로드마다 별도 :memory: DB이므로 A의 쿼리가 B의 데이터에 닿지 않고, 세션 간 격리가 자연스럽게 보장됩니다.
확장 경로
이 구조의 한계는 한 프로세스의 메모리에 담을 수 있는 세션 수입니다. Outer Loop 편은 stateless job(요청마다 Fargate fleet을 새로 띄우고 작업이 끝나면 사라짐)이라 task 수를 늘리는 것만으로 자유롭게 확장되지만, 챗은 stateful in-memory session(턴 사이에 DuckDB 인스턴스가 살아있어야 함, 즉 결정 2 그 자체)이라 같은 사용자의 후속 요청이 세션을 가진 task로 가도록 라우팅이 필요합니다.
동시 사용자가 더 늘어나면 ECS task를 더 띄우고, ALB에 sticky session(upload_id 기반)을 걸어 후속 요청이 세션을 가진 task로 라우팅되도록 하면 됩니다. 결정 2(OLAP 엔진을 프로세스 메모리에 상주)의 본질은 그대로 유지됩니다.
설계 결정 3: SQL 투명성 + 응답 스타일 강제
출발점: Outer Loop 편은 결과를 전달하는 구조였다
Outer Loop 편은 LLM 멀티 에이전트가 분석을 직접 수행해 결과를 전달하는 구조였습니다. 분석가는 결과를 받아보지만, 그 숫자가 어떤 SQL에서 나왔는지 들여다보거나 손볼 통로가 좁았죠. 의심이 들면 결국 원래 쓰던 분석 도구로 돌아가야 했습니다. Inner Loop는 다릅니다. 결과를 손볼 수 있어야 합니다.
선택한 방법: 생성 SQL 노출 + 인라인 에디터
- 생성된 SQL을 항상 채팅 버블에 노출 : 기본 접힘, 클릭으로 펼치기
- 인라인 SQL 에디터 : ▶ 실행, ✎ 편집
아래는 채팅 버블 안에서 생성 SQL과 실행/편집 버튼이 함께 노출되는 예시 UI입니다. 평소에는 SQL이 접혀 있고(왼쪽), SQL ▶을 클릭하면 쿼리·실행 버튼·결과 테이블이 펼쳐집니다(오른쪽).
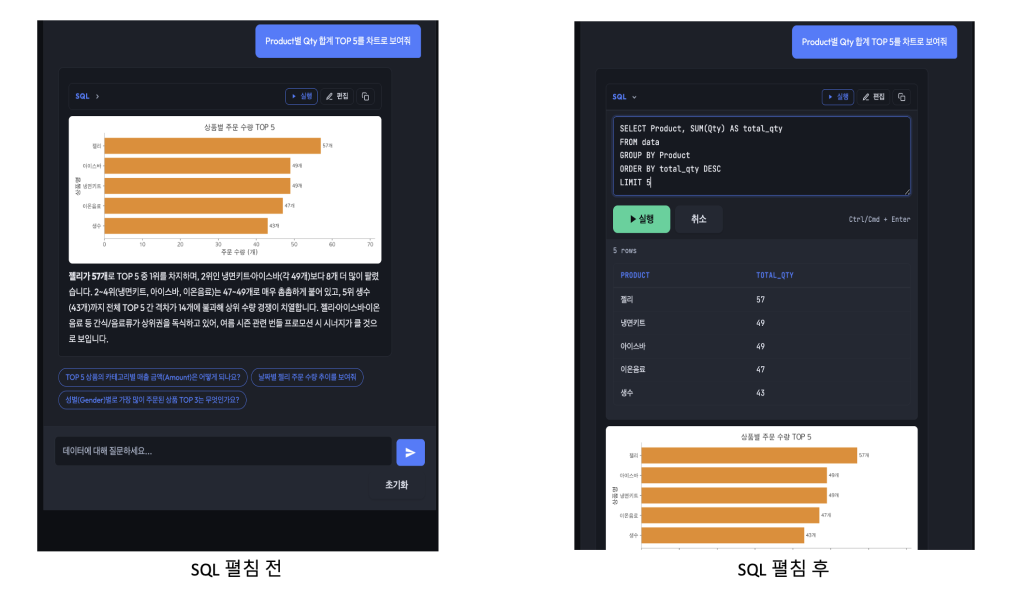
핵심: SQL을 직접 수정·실행하는 경로
분석가가 SQL을 직접 작성하거나 수정해 실행할 때는 SQL 생성 단계가 없으므로 LLM 호출 없이 곧바로 DuckDB로 향합니다.
# deep-insight-web/app.py (발췌)
# POST /sql/execute
@app.post("/sql/execute")
def sql_execute(request: SqlExecuteRequest):
return execute_sql_for_session(request.upload_id, request.sql)
def execute_sql_for_session(upload_id: str, sql: str, max_rows: int = 500) -> dict:
session = session_manager.get_or_create(upload_id)
session.ensure_data_loaded()
df = session.run_query(sql).df()
# ... truncate to max_rows, render to_html(escape=True), return
LLM 호출이 없으므로 응답시간은 DuckDB 쿼리 시간 + HTML 직렬화로 끝납니다. 결과는 최대 500행으로 제한하며, 초과분은 잘라냅니다. 이것이 ChatGPT/Claude.ai와 가장 큰 UX 차이입니다. 분석가는 SQL을 직접 튜닝하면서 LLM 비용 없이 빠른 탐색이 가능합니다.LLM 호출이 없으므로 응답시간은 DuckDB 쿼리 시간 + HTML 직렬화로 끝납니다. 결과는 최대 500행으로 제한하며, 초과분은 잘라냅니다. 이것이 ChatGPT/Claude.ai와 가장 큰 UX 차이입니다. 분석가는 SQL을 직접 튜닝하면서 LLM 비용 없이 빠른 탐색이 가능합니다.
분석가에게 SQL 통제권을 이렇게 넓게 열어줄 수 있는 건 결정 1의 connection 샌드박싱이 외부 유출 경로를 잠가둔 덕분입니다. 사용자가 어떤 SQL을 짜든 in-memory 테이블 밖으로는 빠져나가지 못하므로, 직접 수정·재실행을 자유롭게 허용해도 데이터 보호가 무너지지 않습니다.
그리고 응답 스타일 – Insight-first 규칙
투명성만으로는 부족합니다. SQL 결과를 분석가가 한 번에 받아들이려면 LLM 응답 자체가 숫자 우선이어야 합니다. system prompt로 응답 스타일을 강제합니다:
[응답 규칙]
1. 첫 문장은 반드시 구체적인 숫자로 시작하라
✅ "3월 매출은 4.2억으로 전월 대비 23% 증가했습니다"
❌ "데이터를 분석한 결과 매출이 증가하는 경향이 있습니다"
2. 다음 표현을 절대 사용하지 말 것:
- "경향이 있습니다"
- "것으로 보입니다"
- "나타났습니다"
- "확인됩니다"
3. column_definitions.json의 비즈니스 용어를 우선 사용하라system prompt만으로 100% 강제되지는 않습니다. 모델이 가끔 금지 표현을 다시 사용하는 경우가 있어, 운영에서는 응답 후처리로 위 금지 표현을 한 번 더 필터링하는 편이 안전합니다. 핵심은 어떤 표현을 금지할지가 결정의 본질이라는 점입니다. 분석 챗봇 응답이 “분석한 결과…경향이 있습니다”가 아니라 “4.2억, +23%”로 시작하도록 만드는 것입니다.
3번 규칙이 가리키는 column_definitions.json은 도메인 지식을 시스템 프롬프트에 주입하는 별도 자산입니다. 파일이 없으면 자동 생성되고, 채워두면 SQL 정확도와 응답의 비즈니스 용어 정합성이 눈에 띄게 올라갑니다.
{
"revenue": {
"description": "세전 순매출액 (반품 차감)",
"unit": "원",
"aggregation": "SUM"
},
"customer_grade": {
"description": "고객 등급 (1=VIP, 2=Gold, 3=Silver)",
"note": "낮은 숫자가 높은 등급"
}
}설계 결정 4: 멀티턴 비용 통제
Inner Loop는 한 세션 안에서 LLM을 여러 번 호출합니다. 비용은 결국 호출 수 × 호출당 토큰 비용의 곱이므로, 이 설계는 이 두 항을 세 가지 기법으로 줄입니다. 호출 수는 “원래 1회씩 호출하던 두 동작(웰컴 시작 질문 / 후속 질문)”을 0회로 만들고(4-2, 4-3), 호출당 토큰 비용은 prompt cache로 멀티턴 입력 토큰의 ~90%를 cache read 가격으로 처리합니다(4-1). 따로 노는 기법 셋이 아니라, 비용 공식의 두 항을 함께 깎는 하나의 결정, 세 가지 기법입니다.
4-1. Bedrock Prompt Caching로 멀티턴 입력 토큰 ~90% hit
매 턴마다 전체 context를 새로 전송하는 게 일반적인 흐름입니다. 하지만, Bedrock Prompt Caching으로 system prompt + tool specs + 대화 히스토리에 cache point를 지정합니다.
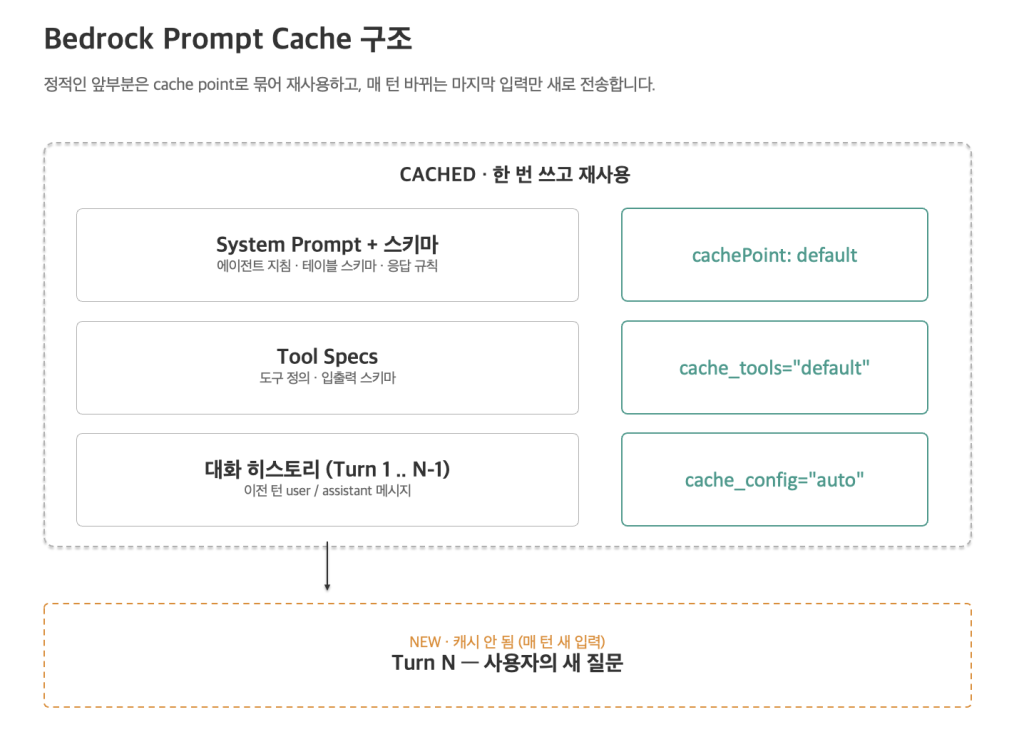
그림 4 – Bedrock Prompt Caching 구조
Strands SDK 기준 실제 코드는 다음 형태입니다:
# deep-insight-web/chat_agent.py (발췌)
bedrock_kwargs["cache_tools"] = "default"
bedrock_kwargs["cache_config"] = CacheConfig(strategy="auto")
system_prompt_value = [
{"text": system_prompt_text},
{"cachePoint": {"type": "default"}},
]실측 데이터 (5턴 세션)
| Turn | Total Input | Cache Read | Hit% |
| 1 | 5,938 | 2,653 | 44.7% |
| 2 | 12,243 | 10,822 | 88.4% |
| 3 | 10,963 | 9,760 | 89.0% |
| 4 | 13,048 | 12,112 | 92.8% |
| 5 | 15,281 | 14,038 | 91.9% |
Turn 2부터 입력 토큰의 ~90%가 cache read 가격으로 처리됩니다.
Bedrock Claude Sonnet 기준 cache read 토큰은 일반 input 토큰 대비 10% 가격으로 처리됩니다 (90% 할인). 첫 턴의 cache write는 일반 input의 1.25배(25% 비쌈)이지만, 2턴 이상 대화하면 곧바로 손익분기점을 넘습니다. 위 5턴 세션의 steady-state 기준으로 계산하면:
유효 입력 비용 = (cache hit 비율 × cache read 단가) + (miss 비율 × 정상 단가) = 0.9 × 0.1 + 0.1 × 1.0 ≈ 0.19
단, 첫 턴은 cache write(1.25×)가 발생합니다. 2턴째부터 cache hit이 시작되므로, 2턴 이상 대화하면 곧바로 손익분기점을 넘습니다.
즉, cache 적용 후 입력 토큰 비용은 cache 미적용 대비 ~20% 수준까지 떨어집니다 (출력 토큰 비용은 별도). 5턴에서 이미 ~90%에 도달하므로, 수십 턴짜리 대화에서는 그 효과가 그대로 누적됩니다.
TTL은 5분입니다 (Bedrock ephemeral cache 기본값). 대화 턴 간격과 잘 맞습니다. ¹⁾
¹⁾ 2026년 1월부터 Bedrock은 1시간 TTL 옵션도 지원합니다. 긴 분석 세션에서 턴 간격이 5분을 넘을 수 있다면 1시간 TTL을 고려해볼 수 있습니다 (cache write 비용은 1.25× → 2×로 올라가므로 hit rate와 세션 길이에 따라 판단이 필요합니다).
4-2. 웰컴 화면은 LLM 호출 0회
페이지 로드 시 “이 데이터로 무엇을 물어볼까요?”를 LLM에게 물어보는 대신, 스키마 휴리스틱 기반 시작 질문 3개를 즉시 만듭니다.
# deep-insight-web/chat_agent.py (발췌)
def generate_suggestions(upload_id: str) -> list[str]:
"""업로드된 CSV의 컬럼 타입을 보고 시작 질문 3개를 생성한다."""
session = session_manager.get_or_create(upload_id)
session.ensure_data_loaded()
# table_name은 UUID 기반 시스템 생성값 — SQL injection 경로 없음
cols = session.run_query(f"DESCRIBE {session.table_name}").fetchall()
suggestions: list[str] = []
if numeric_col := _pick_numeric(cols):
suggestions.append(f"{numeric_col}의 기본 통계를 보여줘")
if category_col := _pick_category(cols):
suggestions.append(f"{category_col}별 TOP 5는?")
if date_col := _pick_date(cols):
suggestions.append(f"{date_col} 기준 월별 추이를 그려줘")
return suggestions[:3] or _default_suggestions()
웰컴 로드 시 LLM 비용 0원, 응답 지연은 DuckDB DESCRIBE 한 번이라 사실상 즉시입니다.
4-3. 후속 질문은 같은 응답에 임베드
응답 후 “추가로 물어볼 것”을 별도 API로 생성하면 추가 LLM 호출 1회가 더 발생합니다. 그 대신 LLM이 같은 응답 안에 후속 질문 3개를 함께 emit하도록 system prompt에 규칙을 추가합니다:
응답 마지막에 반드시 다음 형식으로 후속 질문 3개를 포함하라:
[SUGGESTIONS]질문1|질문2|질문3[/SUGGESTIONS]
프론트는 받은 응답에서 마커를 정규식으로 떼어내고, 본문에서는 마커를 제거한 뒤 후속 질문 버튼으로 렌더링합니다.
// chat.js
const RE = /\[SUGGESTIONS\]([\s\S]*?)\[\/SUGGESTIONS\]/;
const m = html.match(RE);
if (m) {
const chips = m[1].split("|").map(s => s.trim()).filter(Boolean);
renderFollowUpChips(chips);
html = html.replace(RE, ""); // 본문에서는 숨김
}
추가 LLM 호출 0회. 응답 토큰이 약간 늘어나지만, 별도 호출의 input/output 토큰을 모두 새로 태우는 것보다 훨씬 쌉니다 (input은 cache hit이 적용되고, 추가되는 건 후속 질문 3개의 짧은 output
추가 LLM 호출 0회. 응답 토큰이 약간 늘어나지만, 별도 호출의 input/output 토큰을 모두 새로 태우는 것보다 훨씬 쌉니다 (input은 cache hit이 적용되고, 추가되는 건 후속 질문 3개의 짧은 output 토큰뿐).
누적 효과: Inner Loop 한 사이클당 LLM 호출 수
분석가의 한 사이클(웰컴 → 첫 질문 → SQL 수정 → 후속 질문)에서 발생하는 LLM 호출은 사실상 1회입니다.
| 단계 | 일반적인 구성 (LLM 호출) | 이 시스템 (LLM 호출) |
| 웰컴 시작 질문 생성 | 1회 | 0회 (스키마 휴리스틱) |
| 사용자 첫 질문 | 1회 | 1회 (cache write) |
| SQL 수정 후 재실행 | 1회 | 0회 (DuckDB 직접 실행) |
| 후속 질문 버튼 | 1회 | 0회 (같은 응답에 임베드) |
| 두 번째 질문 | 1회 | 1회 (입력의 ~90% cache hit) |
같은 사이클이 일반적인 구성으로는 5회 LLM 호출인데 비해, 이 시스템은 2회(첫 턴 cache write, 두 번째 턴부터 ~90% cache hit)로 끝납니다. Inner Loop의 “탐색을 망설이지 않는 비용”이 이 차이에서 나옵니다.
적용 범위와 한계 : 단일 테이블에서 멀티 테이블로
이 글의 사례는 테이블 1개짜리 환경입니다. 실제 기업 환경은 테이블이 수십~수백 개입니다. 이 구조를 그대로 100개 테이블에 적용하면 두 가지 벽에 부딪힙니다.
- 스키마 토큰 폭발
테이블 100개의 스키마를 전부 system prompt에 넣으면 수만 토큰이 됩니다. Prompt cache 덕에 turn 2부터는 cache read로 처리되지만, 첫 턴의 cache write 비용이 커지고, 무관한 테이블이 LLM의 추론을 흐릴 수 있습니다.
- 어느 테이블을 쿼리할지 결정하는 문제
테이블 1개면 자명하지만 100개면 “어떤 테이블이 이 질문과 관련 있는가”를 먼저 풀어야 합니다. 이 단계가 없으면 SQL 정확도가 급락합니다.
확장 시 추가가 필요한 것은 다음 셋입니다:
- Schema Routing – 질문과 관련된 테이블만 선택해 프롬프트에 주입 (벡터 유사도 또는 keyword 기반).
- json 확장 – 테이블 간 관계(FK) 정보 추가.
- Two-step SQL generation – 먼저 관련 테이블을 선택하고, 그다음 SQL을 생성.
지금 구조는 Schema Routing 없이 단일 테이블에 최적화된 형태입니다. “AWS 계정 내 + LLM 비용 최소화”라는 출발점에서 만든 트레이드오프이며, 멀티 테이블 환경에서는 위 세 가지가 추가되어야 합니다.
또 다른 확장 축은 수평 확장입니다. 동시 사용자가 늘어 한 프로세스의 메모리 한계에 부딪히면, ECS task를 더 띄우고 ALB sticky session(upload_id 기반)으로 후속 요청을 세션을 가진 task로 라우팅하면 됩니다 (결정 2의 “확장 경로”에서 다룸).
정리: 가져갈 수 있는 5가지 자산
이 글의 Q&A 챗봇은 Inner Loop라는 작업 사이클에 맞춰 다시 설계한 결과입니다. 그 과정에서 나온 구성 중 다른 Text2SQL 챗봇 프로젝트로 그대로 가져갈 만한 것들을 정리하면 다음과 같습니다.
| 자산 | 이 글에서 검증된 형태 |
| DuckDB 사용자 SQL 샌드박싱 | enable_external_access=false + allow_unsigned_extensions=false + lock_configuration=true — connection을 외부 접근 불가 상태로 잠그는 설정 |
| 세션마다 OLAP 엔진 상주 | pandas/SQLite 대신 DuckDB :memory:를 세션 단위로 상주시켜 분석 쿼리를 수백 ms에 처리 |
| Bedrock prompt cache 배치 | System + tool specs + history에 cache point — turn 2부터 ~90% cache hit (5턴 실측) |
| SUGGESTIONS 마커 | 후속 질문 버튼을 별도 LLM 호출 없이 같은 응답에 임베드 |
| 도메인 지식 주입 파일 | column_definitions.json으로 LLM 응답에 비즈니스 용어 강제 |
셀프 체크리스트 – 내 서비스에 적용하기 전에
아래 6가지 항목이 여러분의 서비스에 해당한다면, 이 글의 설계 결정을 바로 재사용할 수 있습니다.
| 점검 항목 | 예/아니오 | 권고 사항 |
| CSV 업로드 직후 SQL 실행이 필요한가? | DuckDB In-Memory OLAP 도입 검토 | |
| 동시 사용자의 세션을 독립적으로 유지해야 하는가? | LRU 기반 SessionManager 적용 | |
| 반복 대화에서 동일 컨텍스트를 재전송하는가? | Bedrock Prompt Caching로 비용 최대 90% 절감 | |
| LLM 응답에 후속 탐색 방향을 심어야 하는가? | SUGGESTIONS 마커 패턴 채택 | |
| 도메인 용어·지표 정의가 필요한가? | column_definitions.json 구조 도입 |
|
| Outer Loop 파이프라인과 동일 데이터셋을 공유하는가? | Inner Loop 아키텍처 분리 고려 |
마치며
“CSV 분석 챗봇”은 쉽습니다. 하지만 기업 환경에서 신뢰할 수 있는 분석 도구는 다릅니다. 그리고 그 신뢰할 수 있는 도구도 한 모양이 아닙니다. Outer Loop는 의사결정용 자동 산출물의 모양이고, Inner Loop(Lightweight)는 분석가가 직접 깊이 들어가는 대화의 모양입니다.
이 글의 4가지 설계 결정은 모두 한 가지 질문에서 나왔습니다. Outer Loop의 도구를 Inner Loop에 그대로 쓰면 왜 안 되는가. 분석가에게 SQL 통제권을 넘기되 데이터 유출은 막는 결정 1·3의 보안-신뢰의 축, 세션마다 OLAP 엔진을 상주시켜 분석 쿼리를 수백 ms에 끝내면서 LLM 호출 비용은 누적해서 줄이는 결정 2·4의 속도-비용의 축, 이 두 축이 Inner Loop가 요구하는 “초 단위 응답 + 수십 원 단위 비용 + 즉시 다듬기”를 동시에 만들어냅니다.
선택은 어느 loop에 있는지에 달려 있습니다. 의사결정에 인사이트를 줄 산출물을 자동으로 만드는 거라면 Outer Loop로, 사람이 데이터를 직접 다루며 의미를 찾는 거라면 Inner Loop(Lightweight)로. 둘 다 같은 인프라 위에 있고, 같은 보안 원칙(데이터가 AWS 계정 밖으로 나가지 않는다)을 공유합니다. Outer Loop 편이 20여 분간 깊이 분석하는 동안, 분석가는 Lightweight으로 가설을 빠르게 검증할 수 있습니다. 두 Loop는 함께 돌아갈 때 가장 강합니다.
Deep Insight는 오픈소스로 공개되어 있습니다. 코드를 직접 확인하고 여러분의 도메인에 맞게 확장해 보시기 바랍니다.
- GitHub: https://github.com/aws-samples/sample-deep-insight
- Workshop: Deep Insight Workshop (한국어 | English)