AWS 기술 블로그
하네스 엔지니어링으로 본 Deep Insight – 로컬 개발에서 프로덕션 운영까지의 설계 여정
AI에게 단순히 “잘 해봐”라고 시키는 것과, AI가 스스로 만들고 평가하고 개선하는 Agentic 시스템을 설계하는 건 완전히 다른 결과물을 만들어냅니다. AWS Korea SA Team은 Agentic AI 시스템을 개발할 때 마주하는 다양한 기술적 챌린지들을 직접 풀기 위해 ‘Deep Insight’, 사용자가 업로드한 CSV 데이터와 분석 질문을 받아 최종 DOCX 리포트를 생성하는 프로덕션 Multi-Agent 시스템을 개발했고, 세 편의 블로그 시리즈를 연재하며 Deep Insight 개발 여정에서 직접 경험하고 해결한 내용을 공유하고 있습니다.
앞선 Part 2에서 소개한 Context Engineering 기법으로 에이전트 로직을 효율적으로 구현하는 데 성공했다면, 이제 이 에이전트가 장기간동안 안정적으로 작업할 수 있는 환경을 만들어야 합니다. 이번 블로그에서는 Deep Insight가 이러한 문제들을 해결하기 위해 하네스 엔지니어링 (Harness Engineering) 관점에서 어떤 설계 결정을 내렸는지, 그리고 로컬 개발 환경에서 시작해 AWS 프로덕션 인프라로 전환하기까지의 여정을 공유합니다.
[시리즈 블로그 보기]
- Part 1: Deep Insight란 무엇인가? – 프로덕션급 Multi-Agent 시스템의 필요성과 아키텍처
- Part 2: Context Window 한계를 넘어서 – Deep Insight 개발 여정으로 배우는 Context Engineering 실전 기법
- Part 3: 하네스 엔지니어링으로 본 Deep Insight – 로컬 개발에서 프로덕션 운영까지의 설계 여정
- Part 4: Inner Loop 엔지니어링으로 본 Deep Insight Lightweight – 대화형 분석 챗봇의 4가지 설계 결정
시작하며
하네스 엔지니어링이 무엇이고 Deep Insight가 이를 어떻게 구현했는지를 설명하기 전에, 이러한 개념이 등장한 배경을 되짚어보겠습니다.
2024년 하반기부터 2026년 상반기까지는 AI 에이전트가 PoC 단계를 넘어 프로덕션 배포의 현실적 과제와 정면으로 마주한 시기입니다. Gartner는 2028년까지 기업용 소프트웨어의 33%가 Agentic AI를 포함하고, 일상 업무 의사결정의 15%가 에이전트에 의해 자율적으로 이루어질 것으로 전망했습니다. 학계와 산업계의 논의도 빠르게 축적되었습니다. Anthropic의 ‘Building Effective Agents‘가 7가지 설계 패턴을 제시했고, Model Context Protocol (MCP) 및 Agent-to-Agent (A2A)와 같은 상호운용성 표준도 이 시기에 자리잡았습니다. 그러나 이러한 논의의 초점은 대부분 에이전트의 추론과 오케스트레이션에 머물렀고, 에이전트가 프로덕션에서 안정적으로 동작하기 위한 인프라 설계와 운영 엔지니어링은 상대적으로 공백으로 남아 있었습니다.
하네스(Harness) 라는 용어 자체는 소프트웨어 테스팅 분야에서 오랫동안 사용되어 왔습니다. 기존 개념에서의 하네스는 컴포넌트 실행을 제어하고 결과를 검증하는 프레임워크를 지칭했지만, AI 에이전트 시대에 들어서면서 하네스가 다뤄야 할 범위가 크게 넓어졌습니다. 에이전트는 매번 다른 경로로 추론하고 (즉 “비결정론적”이고), 한 번에 수십 분씩 장기 세션으로 실행되며, 자율적으로 외부 도구를 호출하고, 여러 사용자의 작업을 동시에 격리하여 처리해야 합니다. 기존 소프트웨어와는 질적으로 다른 이 요구사항들 때문에, 하네스 엔지니어링은 2026년에 들어서야 독립적인 엔지니어링 분야로 비로소 조명받기 시작했습니다. 이러한 배경에서, 학계에서도 관련 연구가 이어지고 있습니다. LLM 시스템의 성능이 모델 자체보다 주변 하네스 코드에 더 크게 좌우된다는 실증 결과, 프롬프트 인젝션 공격의 평균 성공률이 84.30%에 달한다는 보안 보고, 에이전트 전용 Zero Trust 아키텍처 제안 등이 대표적입니다. OWASP도 2025년 2월 ‘Agentic AI Threats and Mitigations‘를 발표하며 에이전트 고유의 위협 모델과 완화 전략을 체계화했습니다.
클라우드 사업자들도 에이전트 전용 관리형 인프라를 경쟁적으로 내놓고 있습니다. AWS의 Amazon Bedrock AgentCore를 비롯한 관리형 서비스들은 에이전트 인프라를 이제 “개별 팀이 자체 구축해야 하는 영역”이 아니라, “클라우드 플랫폼이 제공하는 핵심 인프라 계층”으로 빠르게 발전시키고 있습니다. 이러한 기술 환경에서, 에이전트의 추론 로직과 실행 인프라 사이의 간극을 메우는 체계적인 엔지니어링 방법론의 필요성이 대두되고 있습니다. 본 블로그에서는 이를 하네스 엔지니어링의 개념으로 정의하고, Deep Insight의 설계 여정을 통해 그 실천 방법을 공유합니다.
하네스 엔지니어링이란?
AI 에이전트 맥락에서 하네스란, 에이전트가 실행되는 제어 환경과 규칙 모음을 말합니다. 말 그대로 ‘마구(馬具)’처럼 에이전트의 행동을 묶고, 방향을 잡고, 안전하게 제어하는 구조입니다. 구체적으로는 이런 것들을 포함합니다:
- 에이전트에게 주어지는 도구(tool) 목록과 권한 범위
- 에이전트에 들어가는 Context 범위 관리
- 에이전트가 호출할 수 있는 API/함수의 실행 환경
- 로깅 및 모니터링 레이어
하네스 엔지니어링은 AI 에이전트가 장기간에 걸쳐 효과적으로 작업할 수 있도록 이 하네스를 설계하는 일이며, 그 범위는 에이전트 시스템에서 LLM 모델 자체를 제외한 거의 모든 것에 걸쳐 있습니다. 프롬프트 구성, 도구 정의, 실행 환경, 세션 관리, 인증, 네트워크 격리, 모니터링까지, 하나하나 보면 이미 우리가 해왔거나 익숙한 개념들이기도 합니다. 같은 모델이라도 이러한 하네스를 어떻게 설계하느냐에 따라 에이전트의 성능과 안정성이 크게 달라집니다. 쉽게 말해 마치 인간 엔지니어가 효율적으로 일할 수 있도록 개발 환경, 버전 관리 시스템, 테스트 프레임워크를 제공하는 것처럼, AI 에이전트를 위한 작업 환경과 프로세스를 설계하는 것이 하네스 엔지니어링입니다.
Deep Insight의 하네스 엔지니어링 설계
Deep Insight의 하네스는 두 가지 목적 아래 설계되었습니다.
- 에이전트 행동 제어 — “에이전트는 항상 올바른 결과를 도출해야 하고, 이를 검증 가능해야 한다.”
- 인프라 설계 — “에이전트 시스템은 안전한 환경에서 안정적으로 실행될 수 있어야 한다.”
Part 2에서 다룬 내용: Context Engineering
첫 번째 목적인 ‘에이전트 행동 제어’는 Part 2에서 다뤘습니다. Part 2에서는 Context Anxiety 문제를 해결하기 위한 다양한 Context Engineering 기법들 (Note-taking, 파일 기반 외부화, Skills, Prompt Caching 등)과 Validator/Tracker를 통해 에이전트 결과의 정확성을 검증하는 방법을 소개했습니다. 이러한 기법들은 에이전트가 장기간 작업하면서도 Context 한계에 부딪히지 않고, 중요한 정보만 유지하며, 결과를 지속적으로 검증할 수 있게 만든 일종의 하네스가 됩니다. 자세한 내용은 Part 2를 참고해 주세요.
Part 3에서 다루는 내용: 인프라 격리 및 아키텍처
이번 블로그에서는 두 번째 목적인 인프라 설계를 다룹니다. 로컬 개발 환경에서 잘 작동하던 에이전트를 실제 프로덕션에 올리는 순간, 우리는 또다른 차원의 문제들과 마주하게 됩니다.
- 에이전트가 생성한 코드를 어디서 실행해야 할까?
- 특정 도구의 실행이 너무 길어지면 이걸 Agent를 실행하는 인프라 안에서 돌리는 게 비효율적이지는 않을까?
- 에이전트가 30분 동안 잘못된 방향으로 달려가고 있다면 어떻게 중간에 개입해야 하지?
- 중요한 데이터를 다루는 시스템을 인터넷에 노출시키지 않으려면 어떻게 해야 할까?
이번 Part 3에서는 이러한 질문들을 해결하기 위해 Deep Insight가 내린 세 가지 핵심 설계 결정을 공유합니다.
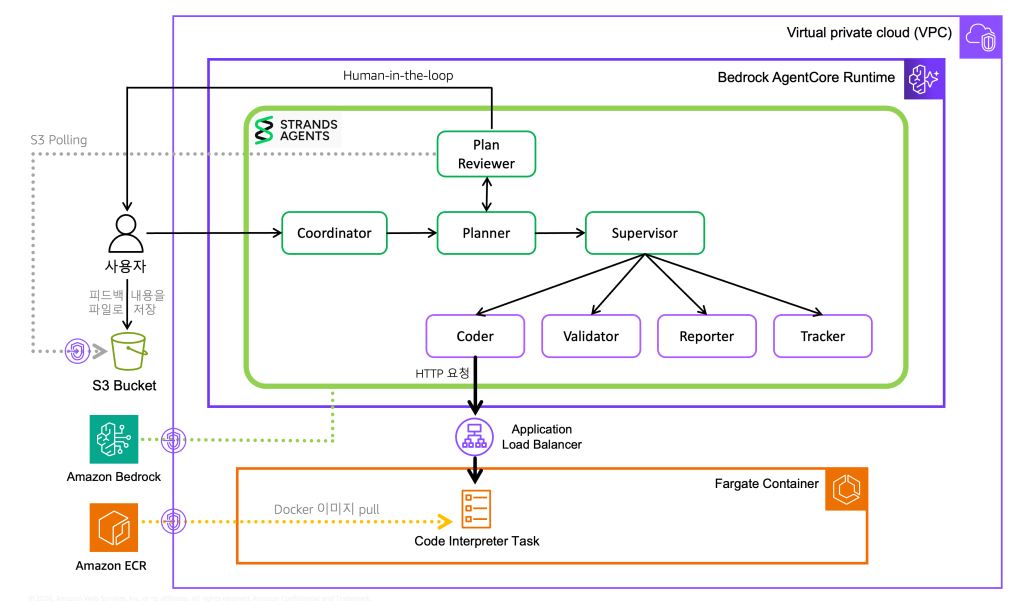
[Figure 1: 전체 아키텍처]
Amazon Bedrock AgentCore Runtime
Deep Insight는 에이전트 실행 환경으로 Amazon Bedrock AgentCore Runtime를 사용합니다. 구체적인 설계 결정을 이야기하기 전에, Deep Insight가 AgentCore Runtime을 선택한 이유부터 짚어보겠습니다.
AgentCore Runtime은 AI 에이전트를 위해 설계된 서버리스 실행 환경입니다. 로컬에서 돌아가던 에이전트를 프로덕션에 올리려면 기존에는 서버를 띄우고 스케일링과 세션 관리와 인증 등을 구현해야 했지만, 관리형 인프라인 AgentCore Runtime은 이 부담을 상당 부분 덜어줍니다. AgentCore Runtime을 선택한 네 가지 이유는 다음과 같습니다.
- microVM 기반 세션 격리: 각 사용자 세션마다 독립된 microVM이 프로비저닝되어 CPU/메모리/파일시스템이 완전히 분리됩니다. 세션이 끝나면 해당 microVM은 종료되고 메모리 역시 초기화되며, 이는 단순히 프로세스 수준이 아닌 커널 수준의 격리이므로 멀티테넌트 환경에서 고객 데이터를 다루는 Deep Insight에게는 필수적인 요건이었습니다.
- 장기 실행 지원 (세션당 최대 8시간): Deep Insight의 데이터 분석 작업은 질문 복잡도와 데이터 규모에 따라 수분에서 30분 이상까지 다양한 시간이 걸리는데, AgentCore Runtime은 세션 중간에 상태를 유지하면서 여러 차례 호출을 이어갈 수 있어 복잡한 멀티턴 워크플로우에 적합합니다.
- Active CPU 기반 과금 구조와 자동 스케일링: AI 에이전트는 LLM 응답을 기다리거나 도구 호출 결과를 기다리는 I/O 대기 시간이 전체 실행 시간의 30~70%를 차지하는데, AgentCore Runtime은 CPU를 실제로 소비하는 시간에 대해서만 과금하고 I/O 대기 중에는 CPU 비용이 발생하지 않습니다. 요청이 없을 때는 세션이 0으로 유지되고, 갑작스럽게 요청이 많아질 때에도 자동으로 세션이 스케일링되어 프로덕션 수준의 가용성을 손쉽게 구현할 수 있습니다.
- VPC 모드와 AWS PrivateLink 조합으로 구현 가능한 네트워크 격리: AgentCore Runtime은 기본적으로 Amazon 관리 네트워크에서 실행되지만, VPC 모드를 활성화하면 고객의 VPC 내부 Private Subnet에 배치되어 VPC Endpoint (AWS PrivateLink)를 통해서만 다른 AWS 서비스와 통신하도록 구성할 수 있습니다. 분석 데이터가 퍼블릭 인터넷을 경유하지 않고 AWS 백본 네트워크 내에서만 흐르므로, 민감 데이터의 네트워크 격리 요건을 기본 기능으로 충족합니다. 실제 VPC 구성과 Security Group 및 IAM Role 설계는 이후 [Decision 3: 완전한 네트워크 격리] 섹션에서 자세히 다룹니다.
이러한 이유로 Deep Insight는 에이전트 추론 환경으로 AgentCore Runtime을 선택했습니다. 아래부터는, AgentCore Runtime을 기본 인프라로 사용하면서 에이전트가 프로덕션 환경에서 안전하고 효율적으로 동작하게 하기 위한 3가지 설계 결정을 공유하겠습니다.
Decision 1: 코드 실행 환경의 완전한 분리
Deep Insight의 Coder 에이전트는 데이터분석에 필요한 Python 코드를 생성한 뒤, write_and_execute_tool을 호출하여 코드를 실행합니다. 로컬 개발 환경 (Self-Hosted)에서 이 write_and_execute_tool이 동작하는 방식은 어렵지 않습니다. 코드를 .py 파일로 저장한 뒤, 이 파일을 subprocess.run() 을 통해 즉시 실행합니다.
# Self-Hosted 방식에서의 write_and_execute_tool.py 내부 동작 요약
# Step 1: 코드를 파일로 저장
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
# Step 2: 저장한 파일을 즉시 실행
subprocess.run(
f"python {file_path}",
shell=True,
capture_output=True,
timeout=300
)이 구조는 단일 사용자 개발 환경에서는 잘 돌아갑니다. 실제로 Deep Insight 초기 버전은 EC2 위에 self-hosted 모드 그대로 올라가있었고, 단일 분석 요청은 문제없이 끝났습니다. 그런데 여러 분석 요청을 동시에 보내 보니 한 건만 성공하고 나머지는 줄줄이 실패하곤 했습니다. 이유를 살펴보니 에이전트 추론과 코드 실행이 같은 Runtime 안에서 자원을 다투고 있었던 겁니다. 이 실패가 “프로덕션에 올리기 전에 코드 실행을 분리해야 한다” 는 판단의 출발점이 됐고, 지금의 Managed AgentCore 아키텍처로 이어졌습니다.
그래서 AgentCore Runtime을 선택한 뒤에도, 데이터 분석 코드를 Runtime 내에서 직접 실행하지는 않기로 했습니다. AgentCore Runtime은 에이전트 추론에 최적화된 관리형 서비스이고, 그 위에 코드 실행까지 얹으면 공통적인 문제가 그대로 재등장하기 때문입니다. 그 문제들을 정리하면 다음과 같습니다.
- 첫째, 보안 위험이 발생합니다. LLM이 생성한 코드를 Runtime 내부에서 그대로 실행하면 악성코드나 무한루프가 같은 세션에서 돌고 있는 에이전트 로직에 영향을 줄 수 있습니다. microVM 격리 덕에 다른 사용자 세션으로 번지지는 않지만, 해당 세션 자체는 분석 코드의 불확정성에 그대로 노출됩니다.
- 둘째, Agent Runtime과 Compute의 워크로드 특성이 다릅니다. AgentCore Runtime은 I/O-wait 지배적 에이전트 실행에 최적화된 환경인데 CPU-heavy 분석은 이 최적화를 살리지 못합니다.
- 셋째, 확장성에 한계가 발생합니다. Runtime과 코드 실행이 묶여 있으면, Agent 세션과 Compute 작업, 그리고 그 사이 트래픽 분배라는 각각의 컴포넌트를 각각의 특성에 맞게 독립적으로 스케일링할 수 없습니다. 사용자 요청이 몰리면 Runtime 세션만 늘리고, CPU 가 과포화되면 Fargate task 만 증설하는 식의 세밀한 조절이 불가능해집니다.
결론은 명확했습니다. ‘코드 생성’은 LLM 추론이 필요한 작업이므로 AgentCore Runtime에서 수행하고, ‘코드 실행’은 단순 compute 작업이므로 별도 환경에서 수행해야 한다는 것이었습니다.

[Figure 2: 코드 실행 환경 분리 아키텍처]
AWS Fargate를 활용한 Custom Code Interpreter 구축
코드 실행 환경을 별도의 인프라로 분리하기로 결정한 뒤, 세 가지 옵션을 검토했습니다.
| 옵션 | 장점 | 제약 / 단점 |
| EC2 | 유연한 환경 구성 | 스케일링 / 패치 관리 부담 |
| Lambda | 서버리스의 간편함 | 실행 시간 15분 제한으로 긴 데이터 분석 부적합 |
| AWS Fargate | 서버 관리 부담 없음, 시간 제한 없음 | (Deep Insight에 가장 적합) |
AWS Fargate는 서버 관리의 부담 없이 시간 제한 없는 실행을 제공하기에 Deep Insight의 요구에 정확히 맞았습니다.
Fargate를 선택한 또 다른 핵심 이유는 실행 환경의 자유도입니다. Amazon Bedrock AgentCore Code Interpreter와 같은 관리형 Sandbox는 편리하지만 환경이 세션별로 초기화되어, 예컨대 한국어 데이터 분석에서 matplotlib 차트에 한글 라벨을 그리려면 시스템 한글 폰트를 매 세션마다 다시 설정해야 하는 부담이 있습니다. Dockerfile로 실행 환경을 직접 패키징하면 필요한 시스템 라이브러리, 언어팩, 특정 버전으로 고정된 Python 패키지, SQL 드라이버 같은 새 의존성을 build-time에 자유롭게 추가할 수 있고, 이렇게 만든 하나의 이미지를 ECR에 올리면 프로덕션의 모든 Fargate Task가 동일한 환경을 보장받습니다. 관리형 실행 환경이 제공하는 편의성과 build-time 제어가 주는 자유도 사이에서, Deep Insight는 향후 분석 도메인이 확장될 것을 고려해 후자를 선택했습니다.
Fargate로 코드 실행을 분리하려면 먼저 실행 환경 자체를 패키징해야 합니다. 그래서 write_and_execute_tool이 의존하는 라이브러리 (pandas, numpy, matplotlib, seaborn 등)와 고정된 Python 및 패키지 버전을 담은 Docker 이미지를 구성하고 ECR에 등록했습니다. 트래픽이 늘어나면 Fargate는 이 ECR에서 이미지를 읽어와 동일한 Task를 증설합니다. 실제로 Deep Insight의 Fargate 이미지는 다음과 같이 정의되어 있습니다.
주목할 점은 fc-cache로 폰트 캐시를 갱신하고, matplotlib.font_manager를 빌드 타임에 한 번 호출해 폰트 캐시를 미리 만들어 둔다는 것입니다. 이렇게 해 두면 컨테이너가 뜬 뒤 첫 차트를 그릴 때 폰트 스캔으로 인한 지연이 없습니다. 관리형 sandbox였다면 이러한 최적화 자체를 적용할 기회가 없었을 것입니다.
Fargate 내부에서 안정적으로 코드를 실행하기
Self-Hosted에서 subprocess.run(f"python {file_path}") 한 줄이면 충분했던 코드 실행은, Fargate로 옮기는 순간 추가적인 복잡함을 마주하게 됩니다. LLM이 생성한 코드에는 특수문자, 멀티라인 문자열, 한글, shell escape가 필요한 따옴표가 섞여 있을 수 있고, 이 내용을 ALB를 거쳐 HTTP로 컨테이너에 전달한 뒤 컨테이너 내부에서 파일 저장과 실행을 수행해야 했습니다. Deep Insight의 write_and_execute_tool은 이를 두 단계로 분리해 해결했습니다.
첫 번째 단계는 컨테이너 내부에서 파일 쓰기만 수행합니다. LLM이 생성한 Python 코드에는 한글 차트 라벨, 작은따옴표, 백슬래시, 멀티라인 f-string 같은 요소가 섞일 수 있고, 이 내용을 shell 명령에 그대로 실어 HTTP → ALB → bash 경로로 흘려보내면 각 레이어의 해석 규칙이 충돌할 여지가 큽니다. 그래서 원본 코드를 Base64로 인코딩해 ASCII 안전 영역으로 옮긴 뒤, 컨테이너 측에서 base64.b64decode로 복원해 파일로 저장하는 방식으로 처음부터 설계했습니다. 이 단계는 subprocess를 띄우지 않고 같은 Python 프로세스 내부에서 처리되므로, GIL 영향이 없고 수 밀리초 안에 끝납니다.
# 1단계: 파일 쓰기 (in-process, subprocess 없음)
content_b64 = base64.b64encode(content.encode('utf-8')).decode('ascii')
write_code = f'''
import base64, os
file_path = "{file_path}"
os.makedirs(os.path.dirname(file_path), exist_ok=True)
content = base64.b64decode("{content_b64}").decode('utf-8')
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
'''
session_manager.execute_code(write_code, f"Write: {file_path}")이어지는 두 번째 단계는 저장된 파일을 subprocess로 실행합니다. 이 때 BASH: 로 시작하는 prefix를 넣어 실행 경로를 구분하고, 긴 실행에는 timeout 유틸리티로 강제 종료 시간을 지정합니다. subprocess 기반이므로, 무한루프에 빠지거나 장시간 실행되는 코드도 상위 Runtime에 영향을 주지 않고 타임아웃으로 정리할 수 있습니다.
# 2단계: 파일 실행 (subprocess + timeout)
if timeout and timeout > 30:
bash_code = f"BASH: timeout {timeout} {execute_cmd}"
else:
bash_code = f"BASH: {execute_cmd}"
session_manager.execute_code(bash_code, f"Execute: {execute_cmd}")
이 2단계 구조의 핵심은 “파일 쓰기”와 “코드 실행”의 문제를 격리하는 것입니다. 쓰기 단계에서 발생하는 escape 문제는 Base64로 우회하고, 실행 단계에서 발생하는 무한루프나 런타임 오류는 timeout으로 격리됩니다. 에이전트 입장에서는 여전히 write_and_execute_tool(file_path, content) 한 번의 호출이지만, 그 내부에서는 하네스가 LLM 코드의 불확정성을 안전하게 흡수하고 있는 것입니다.
AgentCore Runtime과 Fargate를 연결하는 ALB
AgentCore Runtime과 Fargate 사이에는 ALB (Application Load Balancer)가 위치합니다. Fargate Task가 여러 개 떠 있을 때 요청을 적절히 분배해야 하기 때문입니다. Coder 에이전트가 write_and_execute_tool을 호출하면 생성된 코드는 HTTP 요청 형태로 ALB를 거쳐 Fargate Task 중 하나로 도달합니다.
ALB를 중간에 둔 이유는 단순한 로드밸런싱 이상입니다.
- 요청 분배: 여러 사용자가 동시에 분석을 요청할 때 각 요청을 서로 다른 Fargate Task 로 분배할 수 있습니다.
- Health Check 게이트: Target Group Health Check 를 통해 Fargate Task 가 완전히 준비된 후에만 트래픽을 보낼 수 있어, 컨테이너 부팅 중에 요청이 실패하는 문제를 방지합니다.
- Sticky session 으로 세션 연속성 보장: 같은 분석 세션의 후속 요청이 동일한 Fargate Task 로 라우팅되도록 Sticky session을 활용합니다. 데이터 분석은 여러 차례에 걸쳐 코드를 실행하는데, 이전 실행에서 생성한 중간 파일이나 로드한 데이터프레임이 같은 컨테이너에 남아 있어야 다음 단계를 이어갈 수 있기 때문입니다.
그리고 세션 진행 중에는 ALB sticky session 덕에 에이전트들이 같은 Fargate 컨테이너의 파일시스템을 통해 결과물을 공유하고, 세션이 완료되면 모든 결과물 (코드 파일, 그래프 PNG 파일, 전처리된 데이터 등) 이 S3로 일괄 업로드됩니다. S3의 전체 역할은 [Decision 2: S3를 중간 저장소로 활용하기]에서 자세히 다룹니다.
이 설계를 통해 Runtime은 항상 빠르게 반응할 수 있게 되었습니다. 코드 실행 시간과 무관하게, Runtime은 가볍게 유지됩니다. 에이전트가 Fargate로 HTTP 요청을 보낸 뒤 결과를 기다리는 동안에도 Runtime은 멈춰있는 게 아니라, 비동기 async로 동작하며 사용자에게 진행 상황을 스트리밍하거나 다른 세션의 요청을 처리하는 일을 동시에 할 수 있습니다. Fargate는 실제로 코드가 실행되는 시간만큼만 과금되므로 비용 효율도 확보할 수 있었습니다. 데이터 분석 요청이 몰리면 Fargate Task만 늘리면 되므로, Runtime에 영향 없이 필요한 인프라만 스케일링할 수 있다는 점도 큰 장점이었습니다.
세션 격리와 보안
ALB와 Fargate의 조합으로 기본 구조는 갖춰졌지만, 운영 수준에서는 더 세밀한 제어가 필요했습니다. 새로운 Fargate Task가 부팅되는 동안 ALB Health Check가 통과할 때까지 요청을 보류해야 하고, 분석이 끝난 컨테이너는 자동으로 정리해야 하며, 예외 상황(컨테이너 비정상 종료 등)도 처리해야 합니다.
이는 GlobalFargateSessionManager라는 자체 세션 관리 모듈 구현을 통해 해결했습니다 (구현 코드는 Deep Insight Github의 global_fargate_coordinator.py로 확인 가능합니다). 이 모듈은 Fargate Task의 생성부터 종료까지의 전체 생명주기를 관리합니다. 구체적으로는 분석 요청이 들어오면 새 Fargate Task를 프로비저닝하고, ALB Target Group에 등록한 뒤 Health Check가 통과할 때까지 대기합니다. 이후 각 세션에 고유한 HTTP Cookie를 발급하여 ALB sticky session을 통해 후속 요청이 동일한 Task로 라우팅되도록 보장하고, 분석이 완료되면 해당 Task를 Target Group에서 제거한 뒤 컨테이너를 종료합니다. 결과적으로, Runtime은 에이전트 추론에만 집중하고, 무거운 compute 작업은 Fargate에 맡기는 명확한 역할 분담을 구현할 수 있었습니다.
Decision 2: S3를 중간 저장소로 활용하기
첫 번째 설계 결정을 거치면서 Deep Insight는 이미 분산 시스템이 되었습니다. AgentCore Runtime과 Fargate 사이에 데이터를 주고받아야 했고, Part 2에서 다룬 파일 기반 Note-taking도 로컬이 아닌 프로덕션에서 동작해야 했습니다. 이 두 가지를 모두 해결할 중간 저장소로 S3를 선택했습니다. S3의 일레븐 나인 (99.999999999%)의 데이터 내구성, 파일 크기와 개수에 제한 없는 확장성, VPC Endpoint를 통한 Private Network 접근, 저렴한 비용, PUT/GET만으로 데이터를 공유할 수 있는 단순함이 그 이유입니다.
S3의 prefix 구조를 활용하면 세션별 데이터 격리도 자연스럽게 따라옵니다. 아래 예시와 같이, 각 세션에 고유한 session_id를 부여하고, 해당 prefix 아래 모든 파일을 저장하면 세션 간 데이터 충돌 없이 독립적인 클린업과 디버깅이 가능합니다. 또한 로컬에서는 새 분석을 시작하면 이전 결과가 덮어써졌지만, 프로덕션에서는 모든 세션의 결과를 timestamp별로 보관하므로 과거 분석의 비교, 감사 추적, 재현이 모두 가능해졌습니다.
s3://bucket/deep-insight/fargate_sessions/2026-04-10-14-30-abc123/s3://bucket/deep-insight/fargate_sessions/2026-04-10-14-31-def456/s3://bucket/deep-insight/fargate_sessions/2026-04-10-14-32-ghi789/
한 세션의 S3 디렉토리 구조는 다음과 같습니다.
이 구조 위에서 Deep Insight는 S3를 세 가지 용도로 활용합니다.
- 첫째, Fargate 실행 결과물의 보존입니다. Fargate에서 코드를 실행하면 matplotlib 그래프, 전처리된 CSV/Parquet 파일, 요약 통계 등 다양한 결과물이 생성됩니다. 세션이 진행되는 동안에는 ALB sticky session 으로 고정된 같은 Fargate 컨테이너 안에서 에이전트들이 직접 파일을 공유하지만, Fargate 컨테이너는 작업이 끝나면 삭제되므로 세션이 완료되는 시점에 모든 결과물을 S3 로 일괄 업로드합니다. 이렇게 보관된 파일들은 이후 사용자가 다운로드하거나 다음 세션에서 참조할 수 있는 영속적 아카이브가 됩니다. 이렇게 아카이브된 최종 DOCX가 어떤 모습인지는 Github의 샘플 산출물에서 직접 다운로드해 확인할 수 있습니다.
- 둘째, Context 외부화를 통한 외부 메모리 도입입니다. Part 2에서 다룬 Note-taking 기법의 핵심은 파일 기반 Context 외부화였습니다. 에이전트가 생성하는 정보를 모두 Context에 담으면 금방 한계에 도달하므로, 중요한 정보를 artifacts/ 의 파일로 저장하고 필요할 때만 읽어옵니다. 이 파일들이 사실상 에이전트의 외부 메모리 역할을 하며, 같은 세션 안에서는 Fargate 컨테이너의 로컬 파일시스템으로 공유되고 세션 종료 후에는 첫째에서 설명한 S3 아카이브 덕에 장기 보존됩니다. (Part 2에서 다룬 내용을 짧게 요약한다면, all_results.txt는 각 분석 단계마다 결과를 누적 저장하여 Validator가 검증할 때나 Reporter가 최종 리포트를 작성할 때 참조하는 파일입니다. Context에는 “5단계 완료, 상세 내용은 all_results.txt 참조” 정도만 유지하면 됩니다. citations.json은 생성된 그래프 파일 경로나 표 데이터 위치를 기록하여, Reporter가 리포트에 이미지를 삽입할 때 사용합니다. 이렇게 하면 Context는 가볍게 유지하면서도 필요한 모든 정보는 S3에 안전하게 보관됩니다.)
- 셋째, Human-in-the-loop 피드백입니다. AI 에이전트가 아무리 똑똑해도, 도메인 컨텍스트는 사람이 더 잘 압니다. Deep Insight는 에이전트가 세운 계획을 사람이 검토하고 피드백을 줄 수 있도록 설계했습니다. 그런데 AgentCore Runtime은 스트리밍 아키텍처라서, 사용자에게 이벤트를 보낼 수는 있지만 사용자로부터 직접 입력을 받을 수는 없습니다. 이 제약을 S3 를 사이드 채널로 사용하는 방식으로 우회했습니다.
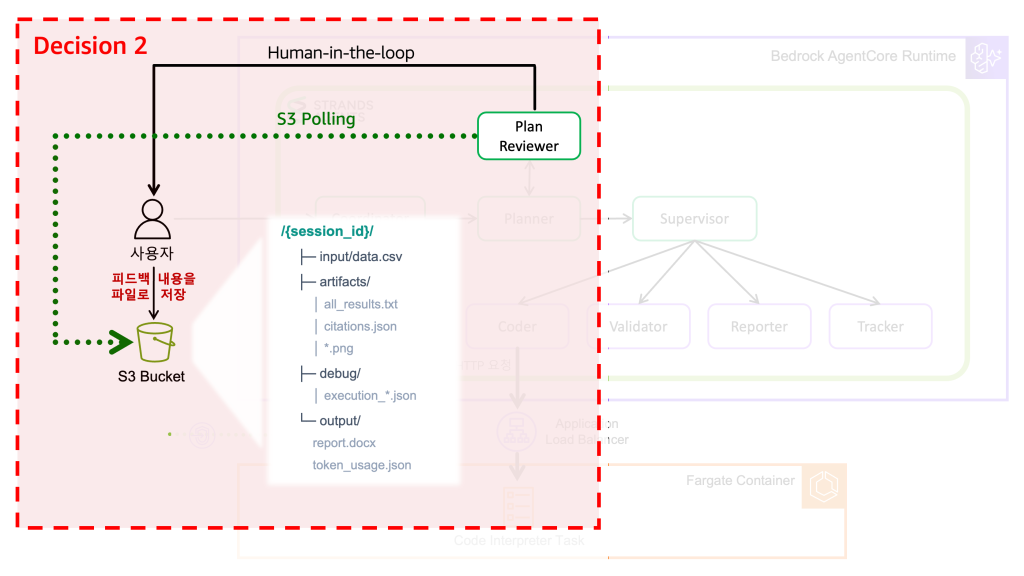
[Figure 3: S3 활용 구조]
- Planner가 사용자 질문을 분석해 단계별 계획을 생성합니다.
- Plan Reviewer가 생성된 계획을 plan_review_request 스트리밍 이벤트로 클라이언트에 전송합니다. 이벤트에는 피드백을 업로드할 S3 key도 함께 실려 나갑니다.
- 사용자 (Web UI)가 계획을 검토한 뒤 피드백 JSON 을 작성합니다 — 예: {“approved”: true} 또는 {“approved”: false, “feedback”: “3단계를 더 자세히 나눠줘”}.
- Web UI가 이 JSON 을 s3://{bucket}/deep-insight/feedback/{request_id}.json 에 업로드합니다.
- Plan Reviewer는 최대 5분 (PLAN_FEEDBACK_TIMEOUT=300) 동안 해당 S3 key 를 3초 간격으로 polling 하며, 동시에 약 6초마다 plan_review_keepalive 이벤트를 전송해 SSE 연결이 끊기지 않게 유지합니다.
- 피드백 파일이 발견되면 JSON을 읽어 내용을 처리한 뒤 S3 파일을 삭제합니다 (재처리 방지).
- “approved=true”면 Supervisor로 진행하고, “approved=false”이면 Planner로 되돌아가 계획을 다시 작성합니다 (최대 10회 반복, MAX_PLAN_REVISIONS=10).
- 5분 안에 피드백이 오지 않으면 “auto-approve” 하여 Supervisor로 진행합니다.
이 패턴의 핵심은 다음 polling 루프에 있습니다.
# managed-agentcore/src/graph/nodes.py::plan_reviewer_node (핵심 발췌)
# Step 1: 계획을 스트리밍 이벤트로 클라이언트에 전송
put_event({
"type": "plan_review_request",
"plan": full_plan,
"feedback_s3_path": f"s3://{s3_bucket}/{get_s3_feedback_key(request_id)}",
})
# Step 2: S3 에서 피드백 파일이 나타날 때까지 polling
while (time.time() - start_time) < PLAN_FEEDBACK_TIMEOUT: # 최대 5분
feedback_data = check_s3_feedback(request_id)
if feedback_data:
delete_s3_feedback(request_id) # 처리 후 삭제
break
# 스트리밍 연결이 끊기지 않도록 keepalive 이벤트 주기적 전송
if poll_count % 2 == 0:
put_event({"type": "plan_review_keepalive", ...})
await asyncio.sleep(PLAN_FEEDBACK_POLL_INTERVAL) # 3초 대기
주목할 점은 polling 루프 안에 keepalive 이벤트 를 주기적으로 내보낸다는 것입니다. Runtime과 클라이언트 사이의 SSE 스트리밍 연결은 일정 시간 응답이 없으면 idle timeout으로 끊길 수 있는데, 피드백을 기다리는 동안에도 연결이 살아있어야 사용자가 피드백을 보낸 즉시 Plan Reviewer가 반영할 수 있기 때문입니다. Human-In-The-Loop 루프는 사실상 “사용자 입력을 기다림”과 “스트리밍 연결 유지”라는 두 가지 일을 동시에 수행합니다.
S3를 중간 저장소로 활용하면서 얻은 핵심 이점은 느슨한 결합입니다. 세션 간 아카이브, Human-In-The-Loop 피드백, Context 외부화 같은 비동기 상호작용이 S3 라는 공용 허브를 통해 이뤄지므로 각 컴포넌트가 독립적으로 진화할 수 있고, 데이터 크기나 파일 수에 제약이 없습니다. 또한 VPC Endpoint를 통한 Private Network 접근으로 S3 버킷과 Deep Insight 에이전트 사이 데이터 보안도 확보할 수 있습니다. 데이터 보안에 대한 내용은 곧바로 이어질 [Decision 3: 완전한 네트워크 격리]에서 자세히 다룹니다. 이러한 설계를 통해 S3는 단순한 저장소가 아니라, 분산 시스템의 데이터 허브 역할을 하게 되었습니다.
Decision 3: 완전한 네트워크 격리
Deep Insight의 데이터 흐름, 즉 사용자가 CSV를 업로드하고, 에이전트가 Bedrock을 호출하여 코드를 생성하고, Fargate에서 분석을 수행하고, 결과를 S3에 저장하는 과정이 만약 퍼블릭 인터넷을 통한다면 각 단계마다 데이터 유출 위험이 존재합니다. 이에 안전한 프로덕션 운영을 위해 VPC와 VPC Endpoint를 활용한 네트워크 격리를 구현하게 되었습니다.
Private Subnet + VPC Endpoint 구조
Deep Insight의 모든 워크로드 (AgentCore Runtime, Fargate Task, ALB)는 인터넷 연결이 없는 Private Subnet에 배치됩니다. Private Subnet에는 Internet Gateway로의 라우팅이 없으므로, 워크로드가 인터넷에 직접 노출될 가능성 자체가 없습니다.
Private Subnet에서 AWS 서비스에 접근하기 위해 VPC Endpoint를 사용합니다. VPC Endpoint는 AWS 서비스를 VPC 내부 Private Network로 가져오는 역할을 하며, 데이터는 인터넷을 경유하지 않고 AWS 백본 네트워크 내에서만 전송됩니다. Deep Insight가 설정한 VPC Endpoint 는 다음과 같습니다.
| 서비스 | Endpoint 타입 | Deep Insight 용도 |
| Bedrock | Interface | LLM 추론 호출 |
| AgentCore Runtime / Gateway | Interface | 에이전트 실행 및 API |
| ECR API / ECR Docker | Interface | Docker 이미지 관리 및 pull |
| CloudWatch Logs | Interface | 로그 전송 |
| S3 | Gateway | 아카이브, HITL 피드백, Context 외부화 |
필요한 최소한의 예외적 아웃바운드 통신을 위해 Public Subnet 에는 NAT Gateway 만 배치하고, 어떤 워크로드도 올리지 않는 2-Tier 구조를 유지합니다.

[Figure 4: VPC 구조 다이어그램]
Security Group을 통한 컴포넌트 간 통신 제어
네트워크 레벨의 격리에 더해, Security Group (보안그룹)으로 각 컴포넌트 사이의 통신도 최소한으로 제한했습니다. 핵심 원칙은 “각 컴포넌트는 바로 앞뒤의 컴포넌트하고만 통신한다”는 것입니다 (AgentCore Runtime → ALB → Fargate Task → VPC Endpoint → 타 AWS 서비스들).
이 체인에서 각 보안그룹은 자신의 직전/직후 컴포넌트만 inbound/outbound rule로 등록하여 허용합니다. ALB는 AgentCore Runtime으로부터의 인바운드만 받고 Fargate로만 내보냅니다. Fargate는 ALB의 8080 포트에서만 인바운드를 받고, 아웃바운드는 VPC Endpoint로의 HTTPS만 허용됩니다. VPC Endpoint는 Fargate와 AgentCore로부터의 요청만 수락합니다. 이 밖의 모든 경로는 차단됩니다. 각 보안그룹에 설정된 규칙을 정리하면 다음과 같습니다.
| Security Group | 인바운드 허용 | 아웃바운드 허용 |
| SG-AgentCore | (Runtime 관리형 — 사용자 제어 밖) | SG-ALB (HTTPS만 허용), SG-VPCEndpoint (HTTPS만 허용) |
| SG-ALB | SG-AgentCore 만 | SG-Fargate 만 |
| SG-Fargate | SG-ALB (8080 포트만 허용) | SG-VPCEndpoint (HTTPS만 허용) |
| SG-VPCEndpoint | SG-Fargate + SG-AgentCore 만 | (대상 AWS 서비스들) |
이 밖의 모든 경로는 차단됩니다. 설령 Fargate 컨테이너가 침해되더라도, 아웃바운드가 VPC Endpoint로만 제한되어 있으므로 인터넷으로 데이터를 유출할 수 없고, 다른 컴포넌트로의 횡적 이동도 보안그룹이 차단합니다.
AgentCore Runtime을 VPC에 배치하는 코드
Decision 3 (완전한 네트워크 격리) 의 “모든 워크로드는 Private Subnet에 배치된다”라는 원칙은 자동으로 적용되지 않습니다. AgentCore Runtime은 기본적으로 Amazon이 관리하는 네트워크에서 실행되므로, VPC 모드를 명시적으로 활성화해야 고객의 VPC/Private Subnet으로 편입됩니다. Deep Insight는 Runtime 배포 스크립트에서 configure() 호출로 VPC 설정을 지정하고, launch() 단계에서 Runtime 내부로 전달될 환경변수들을 함께 주입합니다.
# managed-agentcore/01_create_agentcore_runtime_vpc.py (발췌)
from bedrock_agentcore_starter_toolkit import Runtime
agentcore_runtime = Runtime()
# (1) VPC 모드로 Runtime 설정: Private Subnet에 배치, Security Group 지정
agentcore_runtime.configure(
agent_name="deep_insight_runtime_vpc",
entrypoint="agentcore_runtime.py",
execution_role=execution_role_arn,
region=AWS_REGION,
vpc_enabled=True,
vpc_subnets=[PRIVATE_SUBNET_1_ID],
vpc_security_groups=[SG_AGENTCORE_ID],
)
# (2) 환경변수: Runtime이 Fargate를 어떻게 스폰할지 + 에이전트별 모델 ID
env_vars = {
"AWS_REGION": AWS_REGION,
"S3_BUCKET_NAME": S3_BUCKET_NAME,
"ECS_CLUSTER_NAME": ECS_CLUSTER_NAME,
"ALB_DNS": ALB_DNS,
"TASK_DEFINITION_ARN": TASK_DEFINITION_ARN,
# 에이전트별 모델 ID (코드 변경 없이 재배포로 교체 가능)
"COORDINATOR_MODEL_ID": "global.anthropic.claude-haiku-4-5",
"PLANNER_MODEL_ID": "global.anthropic.claude-opus-4-7",
"SUPERVISOR_MODEL_ID": "global.anthropic.claude-sonnet-4-6",
# ... (Coder / Validator / Reporter / Tracker 동일 패턴)
}
agentcore_runtime.launch(env_vars=env_vars, auto_update_on_conflict=True)
여기에는 두 가지 하네스 관점의 설계가 담겨 있습니다.
- 첫째,
vpc_enabled=True로 Runtime의 네트워크 소속을 선언적으로 결정하므로, Decision 3에서 설계한 Private Subnet + VPC Endpoint + Security Group의 다층 격리가 비로소 실제 인프라와 연결됩니다. - 둘째, Runtime의 행동을 제어하는 거의 모든 설정이 환경변수로 외부화되어 있습니다. 에이전트별 모델 ID, Fargate 클러스터 주소, S3 버킷, ALB DNS가 모두 배포 시점에 주입되므로, 예컨대 Planner 모델을 Sonnet에서 Opus로 바꾸고 싶을 때 에이전트 코드를 고치지 않고 .env 파일만 수정해 재배포하면 됩니다. 이 “재빌드 없는 운영 루프” 는 프로덕션에서 모델 업그레이드와 파라미터 튜닝 비용을 크게 낮춥니다.
정리하면, Deep Insight의 보안 설계는 다층 방어 (Defense in Depth) 구조입니다. 네트워크 레벨에서는 Private Subnet으로 인터넷 노출을 차단하고, 서비스 레벨에서는 VPC Endpoint로 AWS 서비스 접근 경로를 한정하고, 애플리케이션 레벨에서는 Security Group으로 컴포넌트 간 통신을 제한하며, 권한 레벨에서는 IAM Role로 최소 권한만 부여합니다. 어느 한 레이어가 뚫리더라도 다른 레이어가 방어합니다. 이를 통해 “데이터가 인터넷을 경유하나요?”, “컨테이너가 침해되면 어떻게 되나요?”, “누가 S3에 접근할 수 있나요?”라는 질문들에 각각 VPC Endpoint, Security Group, IAM Role이라는 명확한 답을 할 수 있게 되었습니다.
블로그 초반의 [시작하며] 섹션에서 언급했던 “도구 환경에서 프롬프트 인젝션 공격 평균 성공률 84.30%” 라는 수치는 이 다층 방어의 가치를 재확인시켜 줍니다. Deep Insight는 에이전트가 외부 데이터 (사용자가 업로드한 CSV, 분석 지시 등) 를 읽고 자율적으로 코드를 생성하는 구조이므로, 인젝션 자체를 입력 단계에서 100% 차단하는 것은 현실적으로 어렵습니다. 그래서 하네스의 전략은 “인젝션을 막는다” 가 아니라 “인젝션이 성공하더라도 blast radius (즉, 피해가 미치는 범위)를 제한한다” 입니다. 인젝션된 코드가 실행되더라도 Runtime 본체가 아닌 격리된 Fargate microVM 안에서만 돌고 (Decision 1: 코드 실행 분리), 아웃바운드가 VPC Endpoint로만 제한되어 있어 탈취된 정보를 외부로 유출할 경로가 없으며 (Decision 3: 완전한 네트워크 격리), 세션이 끝나면 컨테이너와 함께 메모리/디스크가 모두 폐기됩니다.
또한 [시작하며] 섹션에서 언급한 에이전트 전용 Zero Trust 아키텍처는 “커널 수준 격리” + “네트워크 이그레스 제한” + “프롬프트 무결성 프레임워크” 의 3층 방어를 제안합니다. Deep Insight가 각 층을 어떻게 구현하는지 정리하면 다음과 같습니다.
| Zero Trust 요소 | Deep Insight의 구현 |
| “커널 수준 격리” | AgentCore microVM (Runtime 세션) + Fargate 컨테이너 (코드 실행) |
| “네트워크 이그레스 제한” | Private Subnet + VPC Endpoint 로만 아웃바운드 허용 |
| “프롬프트 무결성 프레임워크” | Bedrock Guardrails에 위임 |
실제 Deep Insight 실행 기록 살펴보기
사용자가 질문과 CSV 데이터를 입력하고 시스템이 최종 DOCX 리포트를 돌려주는 한 분석 작업의 처음부터 끝까지, 세 결정이 함께 어떻게 작동하는지를 실측 기록으로 따라가 봅시다.
한 예로, 14일치 매출 데이터 (830건 거래) 를 분석한 22.5분짜리 세션을 처음부터 끝까지 관찰했습니다. 처음 8분 동안 Coder 에이전트가 9개 차트를 생성하고 (14개 스크립트 순차 실행), 이어서 Validator가 7개 검증 단계를 2분 내에 수행했습니다. 그 중 두 스크립트가 실패했으나 에이전트가 스스로 재작성해 복구했습니다. 이후 Reporter가 11개 단계로 최종 DOCX를 작성했습니다. 79개 Fargate 실행을 모두 합친 순수 코드 실행 시간은 19.8초로, LLM 추론 시간이 코드 실행 시간의 61배였습니다. Deep Insight가 생성하는 최종 분석 리포트의 형식 (1.3 MB 크기의 DOCX, 인용 번호 포함)은 Github의 샘플 DOCX로 직접 확인할 수 있습니다.
| 실행 # | 에이전트 | Fargate 실행 | 스크립트 / 이벤트 | 포인트 |
| 5 | Coder | 372 ms | coder_step1_explore.py | 첫 실제 작업 — 1초 미만 |
| 29 | Coder | 1,435 ms | coder_step12b_dashboard_clean.py | 세션 전체에서 가장 느린 실행 |
| 35 | Validator | 5 ms | ls ./artifacts/ | Coder → Validator 핸드오프 |
| 40 | Validator | 352 ms | validator_step2_validate.py (v1) | 첫 실패 |
| 42 | Validator | 356 ms | validator_step2_inspect.py | LLM 의 첫 재시도도 실패 |
| 44 | Validator | 325 ms | validator_step2_inspect2.py | LLM 이 문제를 더 작은 진단 스크립트로 분해 |
| 46 | Validator | 334 ms | validator_step2_validate.py (v2) | 재시도 성공 — 동일 파일명, 내용만 재작성 |
| 52 | Reporter | 5 ms | cat citations.json | Validator → Reporter 핸드오프 |
| 77 | Reporter | 266 ms | reporter_final.py | 최종 1.3 MB DOCX 작성 |
위 표는 아래와 같은 인사이트를 말해줍니다.
- 에이전트는 순차적으로 실행됩니다. Coder → Validator → Reporter 의 핸드오프가 timestamp로 명확히 구분됩니다. Part 1에서 설명한 계층 구조가 실제 실행에서 그대로 나타납니다.
- 순수 연산은 작고, LLM 추론이 지배적입니다. 모든 Fargate 실행은 1.5초 미만이고, 세션 전체 합계는 19.8초입니다. 22.5분의 대부분은 LLM 이 다음 단계를 계획하고 코드를 생성하는 시간이었고, 실제 연산 시간은 그 61분의 1에 불과합니다. 이 비율 자체가 추론 및 스트리밍 (I/O 지배적)과 compute (CPU 지배적) 의 워크로드 특성이 근본적으로 다르다는 사실을 보여주며, 앞서 [Decision 1]에서 두 환경을 분리한 근거를 사후에 확인해 줍니다.
- 79번의 실행이 단일 Fargate 컨테이너에서 돌았습니다. ALB 의 sticky session 라우팅이 같은 컨테이너를 22.5분간 Warm 상태로 유지한 덕분에, 에이전트는 전처리된 dataframe을 .pkl 캐시 파일로 저장해 모든 단계에서 재사용할 수 있었습니다. 만약 매 실행마다 컨테이너가 새로 뜨면, 이 14일치 830건 데이터셋을 매번 다시 로드해야 했을 것입니다.
- 실패가 작업을 죽이지 않습니다. Validator가 두 번 실패했지만 (#40, #42), 세 번째 시도에서 스스로 복구했습니다 (#46). 에이전트는 stderr를 읽고, 진단용 스크립트를 작성한 뒤, 원래 Validator를 다시 써서 재시도했습니다. 사람이 개입한 부분은 없습니다.
- 그 복구가 가능한 메커니즘은 놀라울 만큼 단순합니다. tool의 리턴 문자열에 stderr를 숨기지 않고 그대로 담아 돌려줍니다. 반환된 문자열은 에이전트의 다음 Bedrock 요청에 tool result로 실려 들어가고, LLM은 이 stderr를 자기 context에 포함한 채로 다음 코드를 생성합니다. 별도의 retry 로직이나 에러 classifier가 없으며, LLM 의 일반적 추론 능력이 그 자리를 대신합니다. “하네스가 실패를 다룬다”라는 표현은 여기서는 “실패 메시지를 숨기지 않고 그대로 LLM 에게 돌려준다“라는 뜻이 됩니다.
# managed-agentcore/src/tools/custom_interpreter_write_and_execute_tool.py (핵심 발췌)
exec_stdout = exec_result.get('stdout', '').strip()
exec_stderr = exec_result.get('stderr', '').strip()
if exec_result.get('error'):
results.append(f"✗ Execution failed: {exec_result['error']}")
if exec_stderr:
results.append(f"Stderr: {exec_stderr}")
return "\n".join(results) # ← 실패도 문자열로 그대로 LLM 에게 반환
# Success case
results.append("✓ Execution successful")
if exec_stdout:
results.append(f"Output:\n{exec_stdout}")
if exec_stderr:
results.append(f"Stderr:\n{exec_stderr}") # ← 경고도 숨기지 않음
return "\n".join(results)비용
한 세션 당 소요 비용을 공개 pricing 기준으로 추정하면 다음과 같습니다 (2026년 4월 us-west-2 기준이며, 아래 비용 외에 VPC 네트워크 서비스 비용은 별도 과금됩니다).
| 구성 요소 | 추정 비용 (USD) | 비중 |
| Bedrock 토큰 (Sonnet 4.6 메인 사용 + Haiku 4.5 일부) | ~$4.09 | ~98% |
| Fargate 컨테이너 (22.5분 sticky + 19.8초 execute) | ~$0.02 | <1% |
| AgentCore Runtime (active CPU ~20초, I/O-wait 무과금) | <$0.01 | <0.1% |
| ALB / S3 / data transfer | <$0.02 | <1% |
| 세션 총 비용 | ~$4.13 | 100% |
토큰 구성은 regular input 806K, output 91K, cache read 412K (90% 할인 적용), cache write 52K 였습니다. 이 breakdown 은 “LLM 추론 시간이 코드 실행 시간의 61배” 라는 시간 차원의 관찰과 같은 결론을 비용 차원에서도 보여줍니다. 인프라 분리 덕에 Runtime/Fargate/ALB 같은 compute 레이어의 비용은 이미 충분히 작고, 비용 절감의 여지는 압도적으로 LLM 쪽에 남아 있습니다.
비용은 유저 프롬프트의 데이터 분석 요건 및 데이터 사이즈에 따라 많이 달라집니다. 또한 현재의 시스템은 citation (인용)이 포함된 docx 파일과 citation 없는 docx 파일이 동시에 생성됩니다. 비용을 줄이기 위해서는 Reporter Agent의 프롬프트를 수정하여, 이 두 파일 중 하나만 생성하도록 하면 비용을 줄일 수 있습니다.
개발에서 프로덕션으로: 전환의 여정
세 가지 핵심 설계 결정 — Fargate 분리, S3 중간 저장소, VPC 격리 — 을 통해 Deep Insight는 로컬 개발 환경에서 프로덕션급 관리형 시스템으로 진화했습니다.
로컬 개발 환경의 장점은 단순함입니다. 모든 것이 한 곳에서 돌아가고 빠르게 테스트할 수 있습니다. 하지만 프로덕션에서는 신뢰성, 확장성, 보안이 우선합니다. 한 컴포넌트가 실패해도 전체 시스템이 멈추면 안 되고, 워크로드에 따라 독립적으로 확장할 수 있어야 하며, 데이터가 노출되지 않도록 철저히 격리되어야 합니다. 이 전환 과정에서 “개발 환경의 단순함을 유지하면서 프로덕션 환경의 요구사항을 충족하는 것은 불가능하다, 둘은 서로 다른 목표를 가진다”라는 교훈을 얻었습니다. 그래서 Deep Insight는 두 가지 버전을 명확히 분리했습니다.
| Self-Hosted | Managed AgentCore | |
| 사용 목적 | 개발/테스트 | 프로덕션 |
| 에이전트 실행 환경 | 로컬 환경 | AgentCore Runtime |
| 코드 실행 환경 | 로컬 환경 Python | AWS Fargate (Custom Code Interpreter) |
| 네트워크 | Public 인터넷 | 100% Private VPC Network (인터넷 미노출) |
| 데이터 격리 | X | VPC 완전 격리 (Security Groups, VPC Endpoints) |
| 스케일링 (고가용성) | 수동 | Auto Scaling |
| 결과물 저장 위치 | 로컬에 파일로 저장 (artifacts/ 디렉토리 내에 덮어쓰기) | S3 버킷 (timestamp 로 여러 결과물 히스토리 저장) |
| 토큰/비용 관찰 | TokenTracker (콘솔 로그 + 로컬 파일) | TokenTracker + OpenTelemetry → CloudWatch / S3 token_usage.json (에이전트별 자동 누적, 세션 간 비교 가능) |
| 관찰된 세션 1건 (22.5분, 830건 거래 분석) | 측정 사례 없음 (개발 용도) | 79 Fargate 실행 / 순수 연산 19.8초
총 1.36M 토큰 / 추정 $4.13 |
| 동시 실행 가능 건수 | 여러 건 (여러개의 Process를 실행하여 가능함) | 여러 건 (Fargate Auto Scaling + microVM 격리) |
마치며: 하네스 엔지니어링의 교훈
Deep Insight를 개발하면서 우리는 AI 에이전트는 코드만으로 완성되지 않는다는 것을 배웠습니다. Part 1에서는 프로덕션급 Multi-Agent 시스템의 필요성과 아키텍처를 소개했고, Part 2에서는 Context Engineering을 통해 에이전트가 장기간 작업할 수 있게 만드는 기법들을 다뤘으며, 이번 Part 3에서는 에이전트가 실제 프로덕션 환경에서 안정적으로 동작하도록 만드는 인프라 설계를 공유했습니다.
정리하면, Deep Insight의 하네스 엔지니어링은 다음 교훈으로 요약할 수 있습니다.
- 에이전트 추론과 코드 실행은 분리하라. 관찰한 세션에서 LLM 추론 시간이 코드 실행 시간의 61배였습니다. 이 비율은 I/O 지배적인 추론 및 스트리밍 작업과 CPU 지배적인 compute 작업의 워크로드 특성이 근본적으로 다르다는 사실을 보여주며, 두 환경을 같은 인프라에 묶으면 어느 쪽에도 최적이 아닌 상태가 됩니다.
- 신뢰성은 분산 시스템의 연결점에서 만들어진다. Sticky ALB, Health Check 게이트, S3로 외부화된 상태 — 이 연결 장치들이 없다면 Fargate 분리는 단순한 “분리”에 그칩니다.
- 하네스는 실패를 다룰 때 가장 빛난다. 성공 경로는 요구사항의 일부일 뿐입니다. Validator가 두 번 실패한 스크립트를 사람의 개입 없이 스스로 복구한 사례는, stderr를 다음 LLM turn으로 라우팅하는 단순한 하네스 하나에서 비롯됩니다.
- 측정 없이는 분리가 정당화되지 않는다. “22.5분 세션에서 LLM 추론이 코드 실행의 61배” 라는 비율은 per-execution latency 와 에이전트별 토큰 사용량을 분리 기록했기에 주장할 수 있었습니다. 도구와 관찰성이 없으면 “분리해서 좋아졌다”는 인상으로만 남았을 것입니다.
- 관리형 인프라는 “하네스 없음”을 의미하지 않는다. AgentCore Runtime은 microVM 격리와 I/O-wait 무과금을 제공하지만, 세션 bridge, 실패 복구, 비용 계측, 스트리밍 keepalive는 여전히 하네스의 책임으로 남아 있습니다.
자신의 도메인에 적용할 때
이 설계가 다른 팀의 에이전트 시스템에도 유용한지는, 아래 질문 중 몇 개에 “예” 라고 답하는지로 가늠할 수 있습니다.
| 질문 리스트 | 예/아니오 |
| 에이전트가 생성하는 코드나 도구 호출이 실행 시간을 크게 변동시킵니까? (예: 1초 ~ 30분) | |
| 한 세션 안에서 에이전트가 여러 차례 tool 을 호출하고, 결과가 다음 turn에 영향을 미치는 구조입니까? | |
| 여러 사용자의 세션을 동시에 처리해야 하며, 각 세션이 서로의 데이터에 접근하지 못해야 합니까? | |
| 에이전트가 다루는 데이터가 인터넷에 노출되면 안 되는 민감 정보를 포함합니까? | |
| 분석이나 추론 결과를 감사 (audit) / 재현 / 디버깅해야 할 가능성이 있습니까? | |
| 현재 프로토타입에서 동시 요청 시 성능 저하나 격리 문제를 이미 관찰한 적이 있습니까? |
“예” 가 2개 이상이라면 [Decision 1: 코드 실행 분리]와 [Decision 2: S3 중간 저장소]는 바로 검토해 볼 만한 설계입니다. “예” 가 4개 이상이라면 [Decision 3: 완전한 네트워크 격리]까지 포함한 Managed AgentCore 유형의 인프라가 필요할 가능성이 높습니다.
현재 Deep Insight는 AWS Korea에서 실제 고객들의 에이전트 설계에 참고자료로서 활용되고 있습니다. 하지만 여정은 계속됩니다. Claude의 Context Window가 커질수록 더 복잡한 분석이 가능해질 것이고, SQL이나 API 호출 등 다양한 데이터 소스 지원도 계획하고 있으며, 실시간 협업이나 다중 피드백 포인트 등 Human-in-the-loop의 개선도 진행 중입니다.
Deep Insight는 오픈소스로 공개되어 있습니다. 코드를 직접 확인하고 여러분의 도메인에 맞게 확장해 보시기 바랍니다.
- GitHub: https://github.com/aws-samples/sample-deep-insight
- Workshop: Deep Insight Workshop (한국어 | English)