AWS 기술 블로그
Category: Technical How-to

Amazon Bedrock Vision LLM과 Amazon OpenSearch Service를 활용한 농약 제품 이미지 인식 시스템 구축기
(주)경농 파밍노트 고도화 프로젝트 — 농약 제품 사진 한 장으로 제품 정보를 자동 검색하는 AI 시스템의 설계와 구현 과정을 공유합니다. 경농 소개 ㈜경농은 1957년 설립된 농산업 토털 솔루션 기업으로, 작물보호제∙비료∙종자∙관수자재 등 다양한 농자재를 공급하며 한국 농업 기술 발전을 선도하고 있습니다. 경농 스마트팜사업부문은 복합환경제어기∙양액공급시스템 등 자체 기술과 글로벌 기업과의 협력을 기반으로 국내 최고 수준의 스마트팜 솔루션을 […]

Amazon Bedrock 위에서 Codex와 Claude Code 함께 쓰기: Harness Engineering으로 구현해보기
Codex + Claude Code, 이 조합 가능할까? 2026년 상반기, 터미널에서 도는 AI 코딩 에이전트는 더 이상 신기한 도구가 아니라 매일 쓰는 작업 환경이 되었습니다. 시장은 두 축으로 빠르게 수렴했습니다. 하나는 Anthropic의 Claude Code, 다른 하나는 OpenAI의 Codex입니다. 두 도구는 모두 터미널 CLI를 중심에 두면서 IDE·웹·클라우드·SDK까지 같은 엔진을 공유하고, claude -p와 codex exec 같은 헤드리스 모드로 […]

Sim-to-Real과 Real-to-Sim: 유능한 Physical AI를 가능하게 하는 핵심 엔진
이 글은 AWS Blog의 Sim-to-Real and Real-to-Sim: The Engine Behind Capable Physical AI by Dario Macagnano, Ignacio Sánchez, and Quinn Cheong 게시글을 번역한 글 입니다. 서론 Physical AI 시스템, 즉 현실 세계를 인지하고 추론하며 행동하는 로봇은 빠르게 발전하고 있습니다. Sim-to-Real 파이프라인은 이러한 발전의 핵심에 있습니다. 그러나 연구실 밖에서도 안정적으로 작동하는 모델을 만드는 것은 이 분야에서 […]

AWS 공간 데이터를 활용한 건물 검사 인텔리전스 구축
이글은 AWS Blog의 “Building Inspection Intelligence with AWS Spatial Data by Michael Prevost, Frantz Lohier, Graeme McHale, Jim Kennedy” 게시글을 번역한 글 입니다. AWS 기반 검사 워크플로를 위한 공간 데이터 관리 실용 가이드 서론 산업 전반에 걸쳐 검사 팀은 자산 상태를 정확하게 문서화하고, 규정 준수 요구사항을 충족하며, 데이터 수집 후 수개월 또는 수년이 지난 후에도 […]

Amazon Braket으로 양자-고전 하이브리드 알고리즘 실행하기 (1편)
고전 컴퓨팅 자원과 양자 컴퓨팅 자원을 결합한 하이브리드 알고리즘은 현재 NISQ (Noisy Intermediate-Scale Quantum) 시대의 양자 컴퓨터 기술 수준에서 실질적인 문제 해결에 접근할 수 있는 효과적인 방법론으로 주목받고 있습니다. 이번 블로그에서는 Amazon Braket을 활용하여 하이브리드 환경을 구성하고 사용할 수 있는 두 가지 방법, 즉 코드 기반 방식과 콘솔 기반 방식을 소개합니다. 이를 통해 독자들은 Amazon […]

GloZ의 Amazon OpenSearch Service를 기반으로 한 자연어 이력서 검색 시스템 구축 사례 — Part 2: 하이브리드 검색과 자연어 쿼리 변환
1. Part 1 요약 Part 1: 데이터 파이프라인과 인덱싱에서는 검색 정확도의 기반이 되는 데이터 파이프라인을 다루었습니다. 글로지(GloZ Inc.)는 약 10만 명의 번역가 이력서를 검색 가능한 형태로 구조화하기 위해, 문서 유형별 파싱 → LLM 기반 메타데이터 추출 → 동의어·표기 변형 정규화 → 환각 검증 → 임베딩 입력 전략 최적화로 이어지는 데이터 정제 파이프라인을 구축했습니다. Amazon OpenSearch […]

AWS Unified Operations: 주요 핵심 워크로드를 위한 복원력 있는 운영 구축
AWS Unified Operations를 통한 대규모 핵심 워크로드의 복원력 확보 – 고가용성, 빠른 마이그레이션, 신속한 인시던트 해결을 위한 AWS 최고 등급 지원 Shift-Left 패러다임: 사후 대응에서 사전 예방으로 주요 핵심 워크로드를 운영하는 조직들은 복원력을 약화시키고, 클라우드 도입을 늦추는 세 가지 중요한 구조적 문제점에 직면해 있습니다. 첫 번째 약점은 역량 부족(Skills gaps)입니다. 클라우드 네이티브 아키텍처 전문 인력은 시장에서 구하기 […]
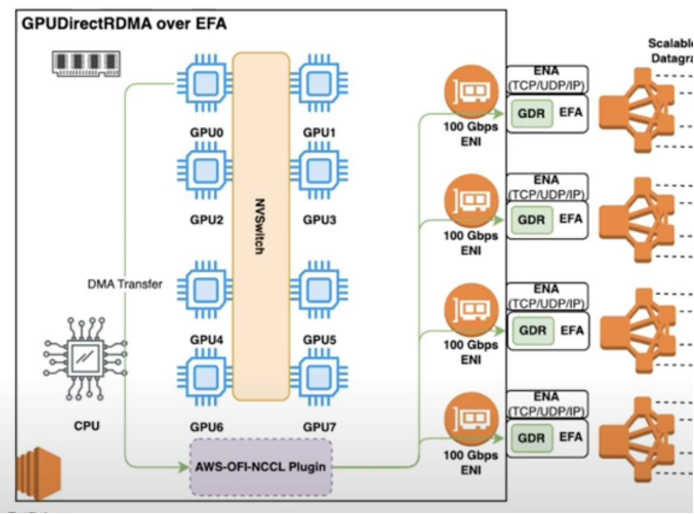
분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – 분산 트레이닝을 위해 알아야 할 GPU 간 고속 통신 기술
대규모 분산 훈련에서 GPU 간 통신 성능은 전체 훈련 효율을 좌우하는 핵심 요소입니다. 수백 대의 GPU가 그래디언트(gradient, 모델이 실수를 고치는 방향 지시서)를 주고받아야 하는 환경에서, 데이터가 GPU 메모리에서 네트워크를 거쳐 원격 노드의 GPU 메모리에 도달하기까지의 경로를 얼마나 효율적으로 설계하느냐가 곧 성능의 차이로 이어집니다. 이번 블로그는 이 시리즈의 마지막 편으로, AWS 인스턴스에서 활용되는 GPU 간 고속 […]

Part 3: Kiro로 RDS/Aurora 장애 분석 자동화하기 — 매일 자동으로 보고서 받기
이 글은 “Kiro로 RDS/Aurora 장애 분석 자동화하기” 시리즈의 세 번째 글입니다. Part 1: “Kiro로 RDS/Aurora 장애 분석 자동화하기 — IDE에서 분석하기” Part 2: “Kiro로 RDS/Aurora 장애 분석 자동화하기 — 터미널에서 분석하기” Part 3 (해당글): “Kiro로 RDS/Aurora 장애 분석 자동화하기 — 매일 자동으로 보고서 받기” 이 시리즈에서 구성하는 자동화 솔루션은 편의상 KIDA(Kiro Database Analyzer)라고 부릅니다. 이 […]

Part 2: Kiro로 RDS/Aurora 장애 분석 자동화하기 — 터미널에서 분석하기
이 글은 “Kiro로 RDS/Aurora 장애 분석 자동화하기” 시리즈의 두 번째 글입니다. Part 1: “Kiro로 RDS/Aurora 장애 분석 자동화하기 — IDE에서 분석하기” Part 2 (해당글): “Kiro로 RDS/Aurora 장애 분석 자동화하기 — 터미널에서 분석하기” Part 3: “Kiro로 RDS/Aurora 장애 분석 자동화하기 — 매일 자동으로 보고서 받기” 시리즈에서 구성하는 자동화 솔루션은 편의상 KIDA(Kiro Database Analyzer)라고 부릅니다. 이 시리즈에서는 […]