AWS 기술 블로그
Amazon MWAA와 Bedrock AgentCore로 MCP 기반 클라우드 정책 에이전트 구축하기
개요
조직의 클라우드 인프라가 성장하면서 IAM 정책, 보안 그룹, 스토리지 설정, 네트워크 구성 등 수백 개의 정책과 리소스 설정이 여러 계정과 리전에 분산됩니다. DevOps 팀은 인프라 상태를 파악하고, SecOps 팀은 과도한 권한을 찾아내며, Compliance 팀은 규정 준수 여부를 감사하고, FinOps 팀은 리소스 사용 현황을 분석해야 합니다. 그러나 이 모든 팀이 동일한 데이터를 서로 다른 관점에서 분석해야 하는데, 현재는 각 팀이 CLI를 수동 실행하거나 개별 스크립트로 데이터를 수집하고 JSON 파일로 저장하고 있어 교차 분석이 어렵습니다.
기존 AIOps 에이전트는 주로 모니터링 도구의 실시간 데이터를 분석하여 인시던트에 대응하는 데 집중합니다. 저희가 제안하는 솔루션은 접근 방식이 다릅니다. 정책 데이터의 수집을 자동화하고, 수집된 데이터를 벡터화하여 시맨틱 검색을 제공합니다. 또한 Strands Agent가 MCP(Model Context Protocol) 표준 도구를 활용하여, 여러 역할의 에이전트가 동일한 데이터에 다른 관점으로 접근할 수 있도록 설계된 거버넌스 아키텍처입니다. 데이터 수집부터 벡터화, 역할별 AI 에이전트 질의까지 전체 파이프라인을 End-to-End로 자동화한다는 점이 핵심 차별점입니다.
이 글에서는 Amazon Managed Workflows for Apache Airflow (Amazon MWAA)로 클라우드 정책 수집을 자동화하고, Amazon S3 Vectors로 시맨틱 검색을 구현하며, Amazon Bedrock AgentCore Runtime에 Strands Agent를 서버리스로 배포하여 DevOps, SecOps, Compliance, FinOps 역할별 전문 AI 에이전트를 제공하는 End-to-End 아키텍처를 소개합니다.
운영 복잡성과 과제
분산된 정책 데이터의 관리 어려움
클라우드 환경이 여러 계정과 리전으로 확장되면, 정책 데이터는 자연스럽게 분산됩니다. AWS 계정 3개, 리전 4개만 운영해도 IAM 정책, S3 버킷 정책, 보안 그룹 규칙, VPC 설정 등을 파악하려면 수십 번의 API 호출이 필요합니다. 여기에 타사 클라우드 환경까지 포함되면 복잡도는 더욱 증가합니다.
현재 대부분의 조직에서는 이 데이터를 수집하는 방식이 팀마다 다릅니다. DevOps 팀은 자체 스크립트로 EC2 인스턴스 목록을 뽑고, SecOps 팀은 별도 도구로 IAM 역할을 감사하며, FinOps 팀은 Cost Explorer만 확인합니다. 동일한 리소스에 대한 정보가 팀별로 분산되어 있어, “이 EC2 인스턴스의 보안 그룹은 적절한가?”와 같은 교차 분석 질문에 답하기 어렵습니다.
더불어 각 팀의 요구사항도 다릅니다. DevOps 팀은 인프라 상태와 배포 현황을, SecOps 팀은 IAM 권한과 보안 정책을, Compliance 팀은 규정 준수 여부를, FinOps 팀은 비용 관련 리소스를 각각 다른 관점에서 분석해야 하므로, 단일 인터페이스로 모든 팀을 지원하기 어렵습니다.
이처럼 데이터 수집의 분산, 팀별 분석 관점의 차이, 정책 변경 이력 추적의 어려움이 결합되면서, 수동 운영으로는 한계에 도달합니다.
솔루션 설계 기준
이러한 과제를 해결하기 위해 세 가지 설계 기준을 세웠습니다.
첫째, 데이터 수집의 완전 자동화입니다. 수동 스크립트 실행을 제거하고, 매일 정해진 시간에 모든 계정과 리전의 정책을 자동 수집해야 합니다. 특정 계정에서 수집이 실패해도 나머지 수집이 중단되지 않는 부분 실패 복원력이 필요합니다. Amazon MWAA는 DAG (Directed Acyclic Graphs) 기반의 복잡한 워크플로우를 관리형으로 실행하며, 스케쥴링·재시도·모니터링 기능을 제공하므로 이 요구사항에 적합합니다.
둘째, 자연어 기반 정책 검색입니다. 정확한 필드명이나 키워드를 몰라도 의미 기반으로 원하는 정보를 찾을 수 있어야 합니다. 본 워크로드는 실시간 색인이 아닌 일 단위 배치 수집 구조이며, 수억 건 이하의 정책 데이터를 비용 효율적으로 저장하는 것이 중요했습니다. 따라서, 별도 클러스터 관리 없이 벡터 임베딩 저장과 시맨틱 검색을 제공하는 Amazon S3 Vectors를 선택했습니다.
셋째, 셋째, 표준 프로토콜 기반 확장성과 서버리스 운영입니다. 한 번 구축한 데이터 접근 계층을 여러 AI 도구에서 재사용할 수 있어야 합니다. MCP는 AI 에이전트가 사용할 도구의 입력과 출력을 표준화된 방식으로 정의하므로, 특정 프레임워크나 SDK에 종속되지 않고 MCP를 지원하는 다양한 에이전트 프레임워크, IDE, 애플리케이션에서 동일한 도구를 재사용할 수 있습니다. 본 아키텍처에서는 정책 검색과 조회 기능을 MCP 도구로 구현하여 Strands Agent뿐 아니라 Kiro 등 다양한 AI 도구와의 연계까지 염두에 두었습니다. 마지막으로 별도의 서버 관리 없이 에이전트를 운영할 수 있도록 Amazon Bedrock AgentCore Runtime을 선택했습니다.
솔루션 아키텍처
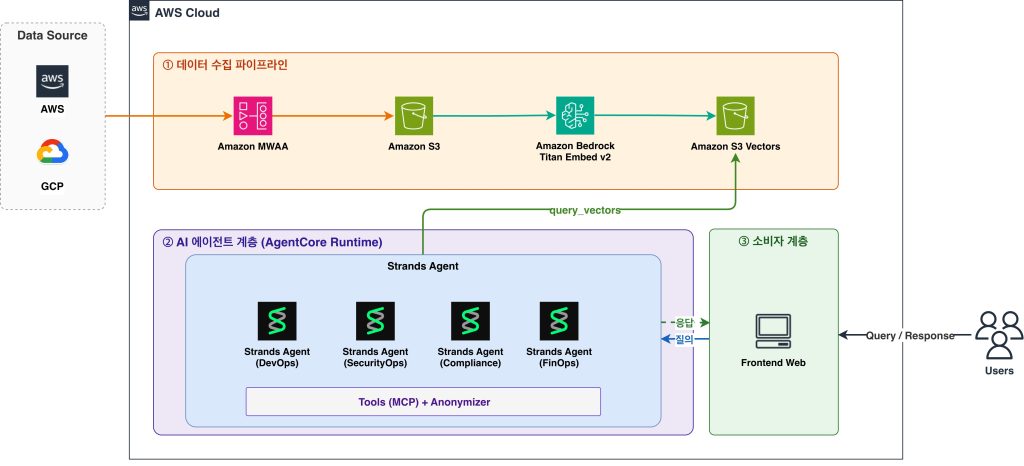
시스템은 세 계층으로 구성됩니다.
데이터 수집 계층: Amazon MWAA가 매일 AWS 10개 카테고리와 타 클라우드의 카테고리의 정책을 수집하여 Amazon S3에 날짜별 파티셔닝으로 저장합니다. 이어서 벡터 임베딩 DAG가 수집 데이터를 Amazon Bedrock Titan Embed v2 모델로 벡터화하여 Amazon S3 Vectors에 저장합니다.
AI 에이전트 계층: Strands Agent가 AgentCore Runtime에서 서버리스로 실행되며, MCP 표준으로 정의된 6개의 도구(시맨틱 검색, 정책 상세 조회, 정책 비교, 변경 이력, 수집 요약, 카테고리별 목록)를 제공합니다. 4개의 역할별 Strands Agent(DevOps, SecurityOps, Compliance, FinOps)가 이 MCP 서버의 도구를 호출하여 사용자 질의에 응답합니다. 에이전트는 Strands Agents SDK로 구현되어 AgentCore Runtime에 서버리스로 배포됩니다.
소비자 계층: Streamlit 대시보드, Kiro 등 다양한 AI 도구가 AgentCore Runtime의 에이전트에 접근합니다. MCP 표준 덕분에 Kiro 등 다양한 AI 도구에서도 동일한 도구를 재사용할 수 있습니다.
구현 상세
아래 시퀀스 다이어그램은 정책 수집부터 사용자 질의 응답까지의 전체 처리 흐름을 보여줍니다.
- 수집: MWAA DAG가 매일 AWS와 타사 클라우드의 정책을 수집하여 S3에 저장
- 임베딩: 임베딩 DAG가 수집 데이터를 Titan Embed v2로 벡터화하여 S3 Vectors에 저장
- 질의: 사용자가 대시보드에서 역할 선택 후 자연어 질문 입력
- 검색: Strands Agent가 MCP 도구를 호출하여 S3 Vectors에서 관련 정책 검색
- 응답: 익명화된 결과를 Amazon Bedrock API로 분석하여 한국어로 답변
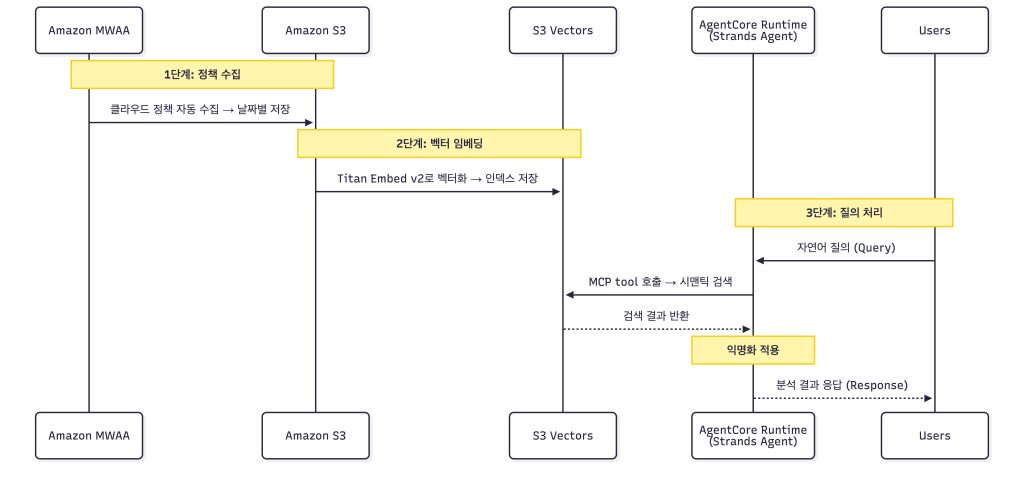
Sequence Diagram
1. Amazon MWAA로 정책 수집 파이프라인 구축
Amazon MWAA의 DAG가 AWS와 타사 클라우드 정책을 카테고리별로 수집하여 S3에 저장하고, Bedrock Titan Embed v2로 벡터화하여 S3 Vectors에 저장하는 전체 파이프라인입니다.

정책 수집 및 벡터 임베딩 파이프라인
Step 1: MWAA 환경 생성
Amazon MWAA 콘솔에서 환경을 생성합니다. DAG 소스 코드를 저장할 S3 버킷과, 수집된 정책 데이터를 저장할 S3 버킷을 지정합니다. MWAA 실행 역할에는 정책 데이터 S3 버킷에 대한 읽기/쓰기 권한을 부여하고, AWS는 STS AssumeRole로 교차 계정 접근을 처리하고, 타사 클라우드는 Workload Identity Federation 또는 AWS Secrets Manager에 저장된 서비스 계정 키로 인증합니다. DAG에서 사용하는 외부 라이브러리는 MWAA의 requirements.txt에 명시합니다. 타사 클라우드 인증 정보는 Airflow Variable이나 환경 변수로 주입합니다.
Step 2: 수집 DAG 작성
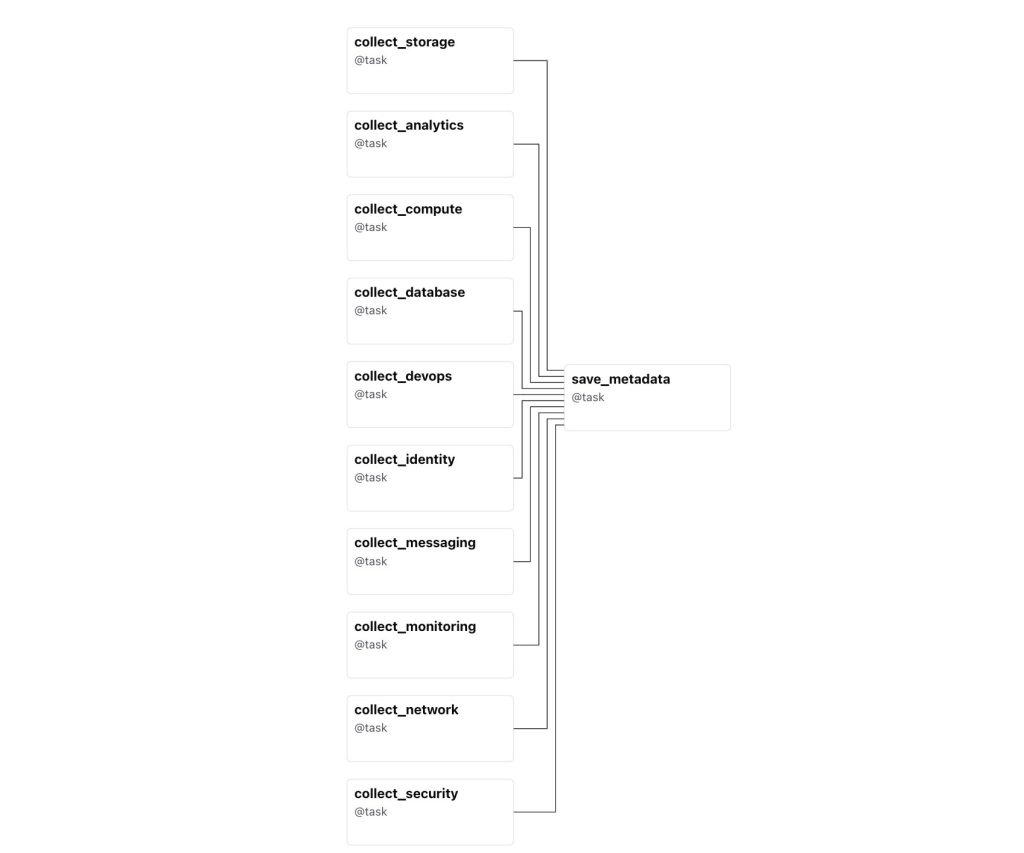
각 카테고리별로 독립적인 DAG를 작성합니다. 카테고리별 DAG가 독립적이므로 병렬 실행이 가능하고, 특정 카테고리의 실패가 다른 카테고리에 영향을 주지 않습니다. 수집 대상은 다음과 같습니다.
| 카테고리 | 주요 리소스 |
|---|---|
| Category | Resources |
| Identity | IAM Role, Policy, User |
| Compute | EC2 Instance |
| Storage | S3 Bucket |
| Database | RDS Instance |
| Network | VPC, Subnet |
| Security | GuardDuty Detector |
| DevOps | CodePipeline |
| Messaging | SNS Topic |
| Monitoring | CloudWatch Alarm |
| Analytics | Redshift Cluster |
타사 클라우드 환경에 대해서도 IAM, Compute, Storage 카테고리에 대해 동일한 패턴으로 DAG를 작성합니다.
수집된 데이터는 다음과 같은 JSON 스키마로 S3에 저장됩니다.
{
"cloud": "aws",
"category": "identity",
"subcategory": "iam_roles",
"collected_at": "2026-05-08T00:00:00Z",
"region": "us-east-1",
"data": [
{"RoleName": "AdminRole", "Arn": "arn:aws:iam::123456789000:role/AdminRole"}
],
"metadata": {"total_count": 1}
}
Airflow UI DAG 목록
Step 3: DAG 활성화 및 실행
작성한 DAG 파일을 MWAA의 DAG S3 버킷에 업로드하면, 1~2분 후 Airflow UI에서 DAG가 나타납니다. DAG를 활성화하면 스케줄에 따라 자동 실행됩니다. Airflow UI의 Graph View에서 Task별 실행 상태를 확인하고, 실행이 완료되면 Amazon S3 버킷에 JSON파일이 생성되었는지 확인합니다.
2. Amazon S3 Vectors로 시맨틱 검색 구현
Step 1: S3 Vectors 벡터 버킷 및 인덱스 생성
S3 Vectors 콘솔에서 벡터 버킷을 생성하고, 클라우드 제공자별로 벡터 인덱스를 만듭니다. 이 예제에서는 aws-policies-index와 gcp-policies-index 처럼 두 개의인덱스를 생성하여, 검색 시 클라우드별로 분리되도록 했습니다. 인덱스 생성 시 차원은 1024(Titan Embed v2 출력 차원), 거리 메트릭은 코사인을 지정합니다. 차원은 한 번 생성하면 변경할 수 없으므로 임베딩 모델 출력과 일치시켜야 합니다.
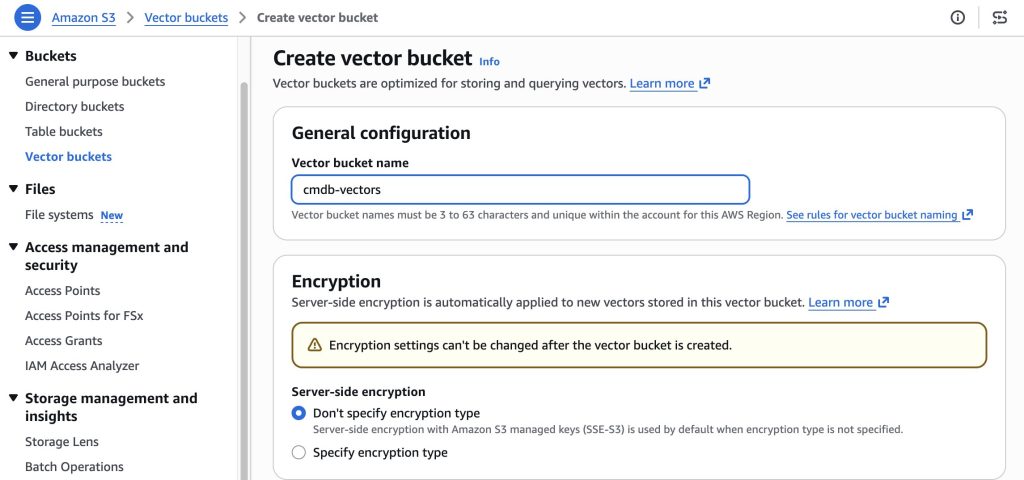
S3 Vectors 벡터 버킷 생성 화면
Step 2: 벡터 임베딩 DAG 작성
수집 DAG 이후에 실행되는 벡터 임베딩 DAG를 작성합니다. 이 DAG는 당일 수집된 정책 데이터를 S3에서 로드하고, Amazon Bedrock Titan Embed v2 모델로 벡터로 변환하여 S3 Vectors에 저장합니다. 이 예제에서는 1024차원을 사용합니다.
벡터화할 텍스트의 품질이 검색 품질을 결정합니다. 정책 데이터는 JSON 구조이므로, 클라우드 제공자, 카테고리, 정책 이름 등 검색에 유의미한 정보를 추출하여 자연어 텍스트로 변환합니다.
bedrock = boto3.client("bedrock-runtime") s3vectors = boto3.client("s3vectors") # 정책 텍스트를 벡터로 변환 resp = bedrock.invoke_model( modelId="amazon.titan-embed-text-v2:0", contentType="application/json", accept="application/json", body=json.dumps({"inputText": "IAM policy: AdminAccess with full permissions"}), )embedding = json.loads(resp["body"].read())["embedding"] # S3 Vectors에 메타데이터와 함께 저장 s3vectors.put_vectors( vectorBucketName="cmdb-vectors", indexName="aws-policies-index", vectors=[ { "key": "aws/identity/iam_policies/20250715", "data": { "float32": embedding }, "metadata": { "cloud": "aws", "category": "identity", "original_s3_key": "aws-policies/20260513/identity/iam_policies.json" } } ]
Step 3: 시맨틱 검색 실행
사용자가 자연어 질의를 입력하면, 동일한 Titan Embed v2 모델로 질의를 벡터로 변환합니다. 이 질의 벡터와 S3 Vectors에 저장된 정책 벡터 간의 코사인 유사도를 계산하여 가장 관련도 높은 정책을 반환합니다. returnMetadata=True 옵션으로 원본 S3 키, 클라우드 정보 등 메타데이터도 함께 반환되어 원본 데이터를 추적할 수 있습니다.
# 시맨틱 검색: 질의 벡터와 코사인 유사도 기반 매칭
query_embedding = generate_query_embedding("과도한 권한을 가진 IAM 역할")
results = s3vectors.query_vectors(
vectorBucketName="cmdb-vectors",
indexName="aws-policies-index",
queryVector={"float32": query_embedding},
topK=10,
returnMetadata=True,
filter={"category": {"eq": "identity"}},
)검색 결과는 다음과 같은 형태로 반환됩니다. distance 값으로 유사도를 판단하고, original_s3_key를 통해 원본 정책 데이터에 직접 접근할 수 있습니다.
# 시맨틱 검색 결과 예시
{
"vectors": [
{
"key": "aws/identity/iam_policies/20260513",
"distance": 0.2341,
"metadata": {
"cloud": "aws",
"category": "identity",
"subcategory": "iam_policies",
"original_s3_key": "aws-policies/20260513/identity/iam_policies.json"
}
}
]
}3. Strands Agent 구축 및 AgentCore Runtime 배포
Step 1: MCP 표준 도구 구현
CMDB 데이터에 접근하는 6개 도구를 MCP 표준으로 구현합니다. 각 도구는 Strands Agent의 tool로 등록되어 AgentCore Runtime에서 서버리스로 실행됩니다. S3 원본 데이터와 S3 Vectors 벡터 인덱스에 접근하며, 모든 응답에 Anonymizer 모듈이 적용되어 민감 정보가 자동으로 마스킹됩니다.
Strands Agent가 search_policies 도구 호출하면 내부적으로 다음 단계를 수행합니다:
- 질의를 벡터로 변환 → 대상 인덱스 선택 → S3 Vectors 쿼리 → 결과 정렬
| 도구 | 설명 |
|---|---|
| search_policies | 자연어 시맨틱 검색으로 정책 탐색 |
| get_policy_details | 특정 정책의 상세 JSON 조회 |
| compare_policies | 두 날짜 간 정책 변경 사항 비교 |
| get_policy_history | 정책의 변경 이력 추적 (최대 30일) |
| get_collection_summary | 수집 결과 요약 (성공/실패 건수) |
| list_policies_by_category | 카테고리별 정책 목록 조회 |
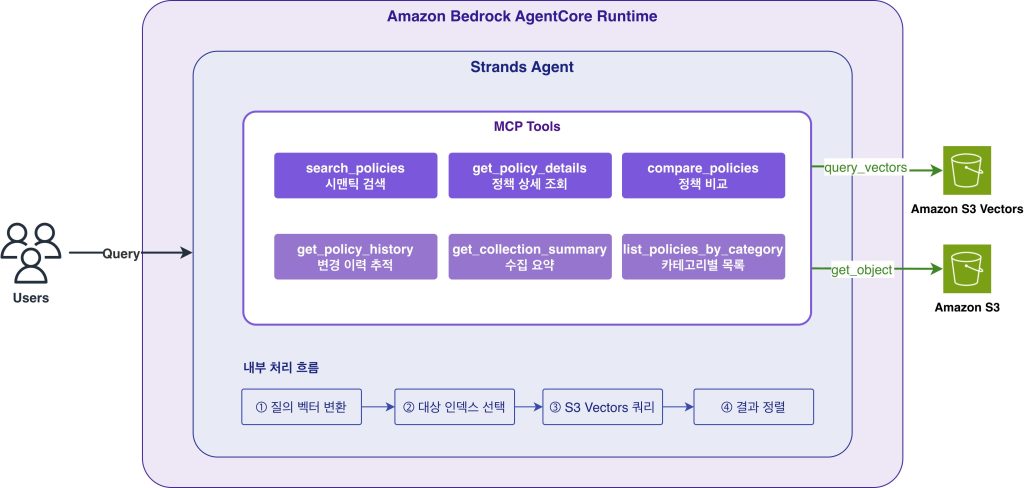
Strands Agent와 MCP 도구 아키텍처
Step 2: AgentCore Runtime에 서버리스 배포
에이전트 실행을 위해 AWS Lambda, Amazon ECS, Amazon EKS와 같은 일반적인 컴퓨팅 서비스를 사용할 수도 있습니다. 그러나 본 예제에서는 에이전트 실행 환경의 운영보다 에이전트 로직 구현에 집중하기 위해 Amazon Bedrock AgentCore Runtime을 선택했습니다. AgentCore Runtime은 에이전트 배포, 실행, 확장성을 관리형으로 제공하므로 운영 부담을 줄일 수 있습니다. 구현한 Strands Agent를 Amazon Bedrock AgentCore Runtime에 배포합니다. AgentCore Runtime은 에이전트를 컨테이너로 패키징하여 서버리스 환경에서 실행되며 사용량 기반 과금 모델을 제공합니다. 또한, 동시 요청이 증가하면 자동으로 인스턴스를 추가합니다.
# AgentCore 프로젝트 생성 (Strands Agent)
agentcore create --name cmdb_governance_agent --defaults --framework Strands
# AgentCore Runtime에 배포
agentcore deploy배포가 완료되면 AgentCore Runtime이 HTTPS 엔드포인트를 제공합니다. Streamlit 대시보드는 bedrock-agentcore 클라이언트의 invoke_agent_runtime API를 사용하여 사용자 질의를 전달하고, 스트리밍 응답을 받아 화면에 표시합니다.
보안: 2단계 민감 정보 익명화
에이전트의 모든 도구는 응답을 반환하기 전에 2단계 익명화를 적용합니다.
| 단계 | 시점 | 설명 |
|---|---|---|
| 1차 | 도구 응답 시 | 각 도구가 S3 데이터를 조회한 결과를 반환할 때 익명화 |
| 2차 | 최종 응답 시 | 에이전트가 사용자에게 답변을 전달하기 전, 추가 익명화 |
동일한 계정 ID는 항상 같은 마스킹 결과([AWS_ACCOUNT_ID-a1b2c3d4])를 생성하여, 익명화된 상태에서도 데이터 간 관계를 파악할 수 있습니다. 오류 발생 시에는 원본 데이터를 반환하지 않고 빈 문자열을 반환하는 안전 실패(fail-safe) 원칙을 따릅니다.
4. Strands Agent 기반 역할별 에이전트
에이전트 설정과 접근 제어
사용자가 대시보드에서 역할을 선택하면, 해당 역할의 설정이 로드됩니다. 설정에는 시스템 프롬프트, 허용된 도구 목록, 허용된 카테고리 목록이 포함됩니다. Strands Agent는 이 설정을 기반으로 초기화되며, 도구를 호출할 때 허용된 카테고리만 요청합니다.
예를 들어 SecOps Agent는 허용 카테고리(identity, security, network)만 검색하도록 시스템 프롬프트에 정의되어, compute나 storage 카테고리의 데이터에는 접근하지 않습니다.
이 예제에서는 시스템 프롬프트로 카테고리 접근을 제한하지만, 프로덕션 환경에서는 도구 함수 내부에서 category 파라미터를 검증하고 IAM 정책으로 도구별 접근 권한을 분리하는 방식을 권장합니다.
AGENT_CONFIGS = {
"devops": {
"name": "DevOps Agent",
"system_prompt": "인프라 모니터링, 리소스 상태, 배포 현황을 분석합니다. "
"CMDB 데이터를 기반으로 인프라 상태를 파악하고 권고합니다.",
"allowed_tools": ["search_policies", "get_policy_details", "compare_policies",
"get_policy_history", "get_collection_summary", "list_policies_by_category"],
"allowed_categories": ["compute", "network", "storage", "devops", "monitoring", "messaging"],
},
"securityops": {
"name": "SecurityOps Agent",
"system_prompt": "보안 정책 분석, IAM 권한 검토, 감사 로그 분석, 취약점 탐지를 수행합니다. "
"CMDB 데이터를 기반으로 보안 위험을 식별하고 개선 방안을 제시합니다.",
"allowed_tools": ["search_policies", "get_policy_details", "compare_policies",
"get_policy_history", "list_policies_by_category"],
"allowed_categories": ["identity", "security", "network"],
},
# Compliance, FinOps Agent도 동일한 패턴으로 정의
}실제 사용 시나리오
각 역할별 에이전트에 동일한 CMDB 데이터를 기반으로 질문했을 때, 역할에 맞는 관점에서 분석 결과를 제공합니다.
SecurityOps Agent: 관리자 권한 역할 탐지
SecOps 팀원이 “IAM 정책 중 관리자 권한을 가진 역할을 찾아줘”라고 질문하면, Strands Agent는 search_policies 도구로 identity 카테고리를 시맨틱 검색하고, get_policy_details로 상세 데이터를 조회한 뒤, 고위험 역할을 식별하여 보안 권고사항을 제시합니다. 응답에서 ARN은 [ARN-50670044] 형태로 익명화되어 표시됩니다.
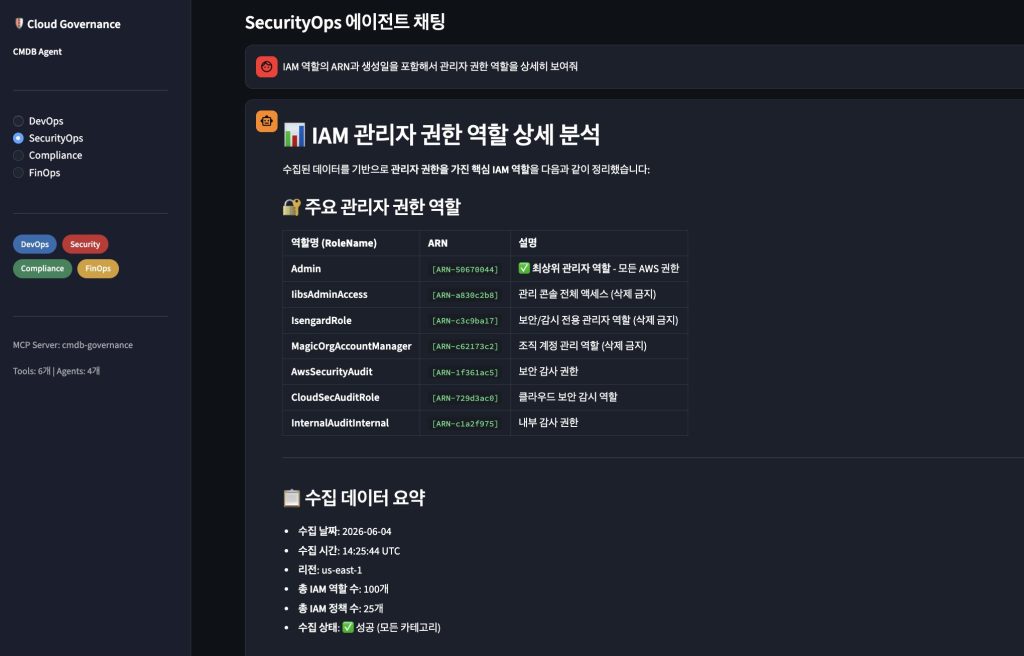
SecOps Agent – IAM 관리자 권한 역할 분석
DevOps Agent: 컴퓨팅 리소스 현황 분석
DevOps 팀원이 “사용 중인 컴퓨팅 리소스 현황을 분석해줘”라고 질문하면, Strands Agent는 compute 카테고리의 EC2 인스턴스와 보안 그룹 데이터를 조회하여 인프라 현황을 분석하고, Default 보안 그룹 정리와 CloudWatch 모니터링 설정 등 운영 관점의 권고를 제공합니다.
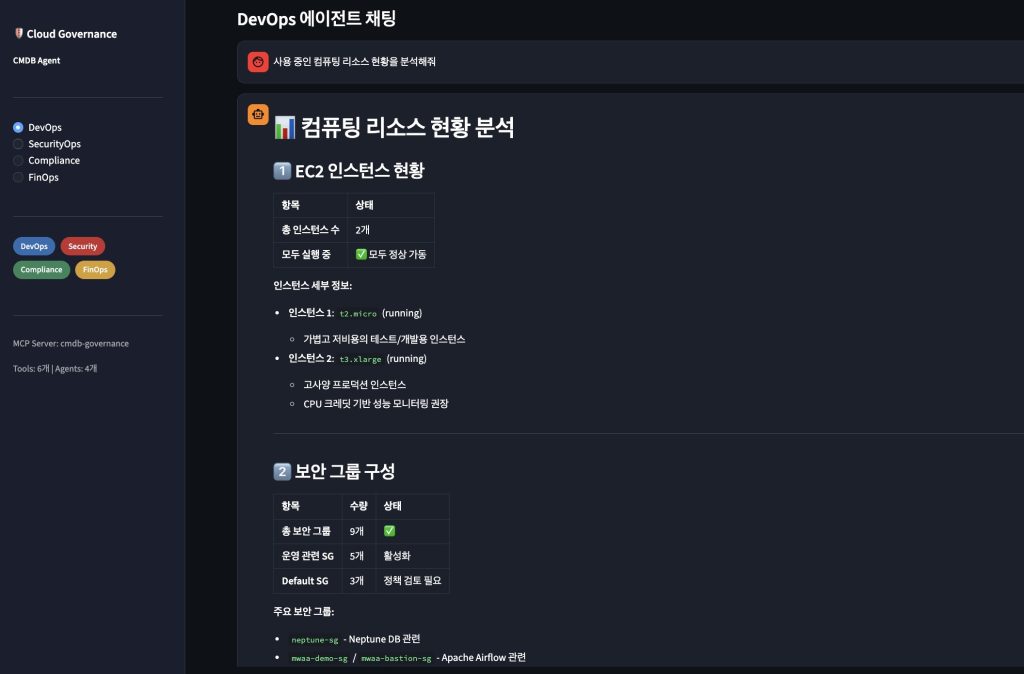
DevOps Agent – 컴퓨팅 리소스 현황 분석
이와같은 CMDB 데이터를 기반으로 SecurityOps는 보안 위험을, DevOps는 인프라 상태를 각각 다른 관점에서 분석합니다. 역할별 시스템 프롬프트와 허용 카테고리 설정이 에이전트의 분석 관점을 결정합니다.
기대 효과
이 아키텍처 도입으로 다음과 같은 효과를 기대할 수 있습니다.
- 수동 작업 시간 단축: Amazon MWAA 스케줄러가 매일 자동으로 정책을 수집하여, 수동 CLI 실행을 대체합니다.
- 자연어 정책 검색: Amazon S3 Vectors 기반 시맨틱 검색으로, 정확한 키워드를 몰라도 의미 기반으로 원하는 정보를 찾을 수 있습니다.
- 서버 관리 불필요: Amazon Bedrock AgentCore Runtime이 Strands Agent를 서버리스로 호스팅하여 가용성, 스케일링, 패치를 자동 관리합니다.
- 역할별 맞춤 분석: DevOps, SecOps, Compliance, FinOps 4개 전문 에이전트가 각 팀의 관점에 맞는 분석을 제공합니다.
- 표준 프로토콜 재사용: MCP 표준으로 한 번 정의한 도구를 Strands Agent와 Kiro 등 다양한 AI 도구에서 재사용합니다.
결론
이 프로젝트에서 얻은 핵심 성과는 세 가지입니다.
첫째, 데이터 수집 자동화입니다. 기존에 각 팀이 수동으로 수행하던 정책 수집 작업을 Amazon MWAA DAG로 완전 자동화하여, 매일 카테고리별 정책이 일관된 형식으로 수집됩니다. 부분 실패 복원력 설계 덕분에 특정 계정이나 리전의 장애가 전체 수집을 중단시키지 않습니다.
둘째, MCP 표준 기반 확장성입니다. MCP 표준으로 정의된 도구를 역할별 Strands Agent가 활용하고, Kiro 등 다양한 AI 도구에서도 동일한 도구를 재사용할 수 있습니다. 새로운 AI 도구가 추가되어도 에이전트를 수정할 필요가 없어, 조직의 AI 도구 도입 속도에 맞춰 자연스럽게 확장됩니다.
셋째, 역할별 접근 제어입니다. 동일한 데이터 소스에서 각 팀이 자신의 역할에 맞는 분석만 수행할 수 있도록 카테고리 기반 접근 제어를 구현했습니다. 이는 보안과 편의성을 동시에 달성합니다.