AWS 기술 블로그
Category: Storage
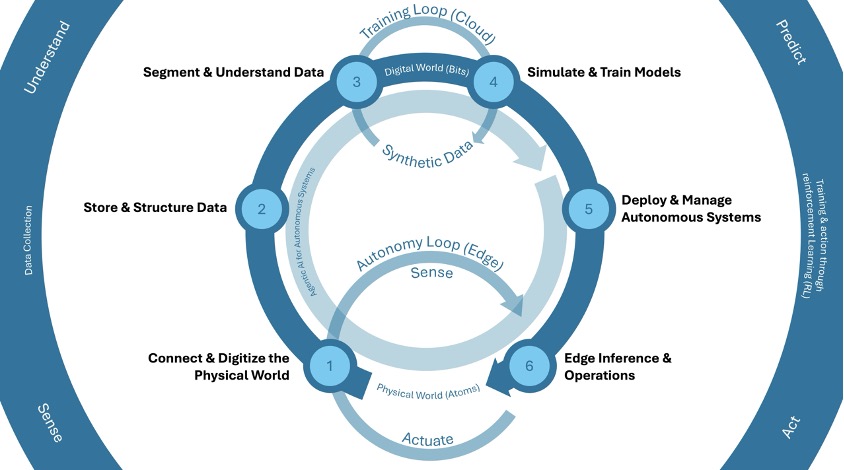
Physical AI: 자율 지능의 차세대 기반 구축
이 글은 아래 블로그 원문을 번역 하였습니다. Physical AI: Building the Next Foundation in Autonomous Intelligence 소개 세계는 자율 경제(Autonomous Economy)로 빠르게 전환되고 있습니다. 자율 경제란 AI, 엣지 컴퓨팅, 로보틱스, 공간 지능, 시뮬레이션 기술이 유기적으로 결합되어 시스템이 최소한의 인간 개입만으로 자율적으로 운영되는 혁신적인 경제 모델입니다. Physical AI는 이러한 기술 융합의 핵심이며, 컴퓨팅 시스템이 물리적 세계를 […]

Amazon Bedrock 및 Strands Agents를 이용한 롯데백화점의 AI 컨시어지 구축기
오프라인 리테일의 AI 혁신 대한민국 대표 백화점인 롯데백화점은 전국 수십 개 지점에서 프리미엄 쇼핑 경험을 제공하고 있습니다. 롯데백화점의 오프라인 매장 및 서비스 정보를 제공하는 롯데백화점 앱은 업계 최대인 약 700만 명의 가입자를 보유하고 있으며, 월간 활성 사용자 수(MAU)는 110만 명에 이릅니다. 롯데백화점은 이러한 디지털 접점을 더욱 강화하고 고객 경험을 한 단계 끌어올리기 위해 AI 기반의 […]

Amazon Bedrock 사용량 관리 및 최적화 하기
Amazon Bedrock을 이용하여 다양한 AI 서비스를 구축하고 Poc단계부터 실제 서비스를 런칭하는 단계까지 안정적인 AI 서비스를 구축하는 것은 쉽지 않은 긴 여정입니다. 특히 LLM의 토큰 사용량 관리와 토큰 최적화는 운영서비스를 런칭한 이후 겪게 되는 중요한 문제들이라고 할수 있습니다. AI 서비스를 성공적으로 런칭한 고객들 조차도 LLM 토큰 사용량에 대한 명확한 모니터링, 토큰 최적화, 그리고 리밋 증설하는 부분에서 […]

Amazon OpenSearch Service User Behavior Insights(UBI)로 사용자 행동 분석하기
대고객 서비스를 제공하는 워크로드의 경우 고객 경험을 지속적으로 향상시키기 위해서 다양한 이벤트나 프로모션을 진행합니다. 어떤 경우는 정기적으로 고객을 초청하여 인터뷰를 하며 서비스의 개선을 위한 피드백을 받기도 하고 어떤 경우는 웹 서비스상의 설문 조사를 통해 개선점을 수집하기도 합니다. 이커머스와 같은 서비스는 고객의 경험이 매출과 직결되는 대표적인 워크로드입니다. 따라서 다양한 고객의 피드백과 워크로드의 품질을 검토하기 위해서 해당 […]

LINE Games의 AI Agent를 통한 게임 퍼블리싱 가속화 여정
더 재미있고 품질 좋은 게임을 빠르게 유저와 만날 수 있도록 하기 위해 외부 개발사와의 원활한 협업은 게임 퍼블리싱 비즈니스에서 필수입니다. LINE Games는 다양한 게임 개발사가 빠르게 게임을 출시할 수 있도록 인앱결제, 빌드 배포, 계정 관리 등 퍼블리싱을 위한 플랫폼을 제공하고 있습니다. 하지만 각 개발사가 처한 상황이 다르고, 사용하는 게임 엔진(Unity와 Unreal)과 프레임워크 등 다양한 환경에 […]

AWS X Remember GenAI 해커톤 사례: 영업팀을 위한 AI 솔루션 샐리(Sales:Re) 개발기
지난 10월 17일, AWS와 리멤버앤컴퍼니가 함께 진행한 GenAI Hackathon이 성황리에 마무리되었습니다. 이번 해커톤에는 총 12개 팀이 참가하여 생성형 AI를 활용한 다양한 프로젝트를 선보였습니다. 리멤버앤컴퍼니는 국내 대표 비즈니스 네트워크 서비스, ‘리멤버’를 운영하는 기업으로, 직장인들의 커리어 성장과 비즈니스 연결을 돕고 있습니다. 500만 명 이상의 회원을 보유한 리멤버는 명함 관리, 채용, 콘텐츠 등 다양한 서비스를 제공하며, 최근에는 생성형 […]

삼성전자 로봇 설비 데이터 인사이트 혁신, Part 1: Amazon Quick Sight 대시보드
이 블로그 포스트는 삼성전자의 최석원님과 함께 작성되었습니다. 개요 삼성전자에서는 다양한 방법으로 로봇과 설비가 협업 할 수 있는 방법에 대해 고민하고 있습니다. 특히 양팔 로봇, 협동로봇, AMR (Autonomous Mobile Robot) 등과 자동화 설비를 이용한 통합 시스템을 구성하기 위하여 노력 하고 있습니다. 초기 AWS IoT Core와 AWS IoT Greengrass를 사용 데이터를 수집한 뒤 MongoDB에 실시간으로 데이터를 저장하는 […]

AWS Backup를 활용하여 백업 데이터 복원 테스트를 구현하기
미션 크리티컬 애플리케이션은 전자상거래부터 의료에 이르기까지 다양한 분야를 지원하므로, 견고한 백업 전략은 단순한 모범 사례가 아닌 필수 요소입니다. 랜섬웨어와 같은 위협이 점점 더 정교해지는 상황에서 AWS 사용자에게는 백업 보유만으로는 충분하지 않습니다. 조직들은 재해가 발생했을 때 이러한 안전장치가 제대로 작동할 것이라는 확신이 필요합니다. 수동 테스트는 필수적이지만 IT 리소스를 소모합니다. 정기적인 자동화된 복원 테스트를 통해 조직은 효율성 향상뿐만 아니라 백업 무결성 검증, […]

AWS와 함께하는 웅진AI Runner Challenge 5부: Amazon Bedrock으로 바꾼 컨택센터 상담 품질 관리
지난 2025년 7월 9일, AWS와 함께하는 ‘Gen AI Runner Challenge 2025’가 진행되었습니다. AI 기술이 고도화되면서, AI는 개인과 조직의 역량을 강화할 수 있는 열쇠가 되고 있습니다. 이번 AI Runner Challenge는 구성원의 상상력을 AI를 통해 직접 실현하는 자리이며, AI역량을 향상하고 실제 업무에 적용할 수 있는 기회였습니다. 본 게시글은 5부로 구성되어 있으며, 웅진의 AI Runner Challenge에 참가한 팀 […]

AWS와 함께하는 웅진 AI Runner Challenge – 3부: Amazon Bedrock 기반의 렌탈 제품 추천 AI 에이전트
지난 2025년 7월 9일, AWS와 함께하는 ‘Gen AI Runner Challenge 2025’가 진행되었습니다. AI 기술이 고도화되면서, AI는 개인과 조직의 역량을 강화할 수 있는 열쇠가 되고 있습니다. 이번 AI Runner Challenge는 구성원의 상상력을 AI를 통해 직접 실현하는 자리이며, AI역량을 향상하고 실제 업무에 적용할 수 있는 기회였습니다. 본 게시글은 5부로 구성되어 있으며, 웅진의 AI Runner Challenge에 참가한 팀 […]