AWS 기술 블로그
기존 개발 코드(Java)로 Amazon Neptune Analytics GraphRAG 구현하기
서론
수년간 운영해온 서비스에서 Knowledge Graph를 구성하려면 어디서부터 시작해야 할까요? 새 스키마를 처음부터 설계하는 방법도 있지만, ORM 엔티티나 데이터 모델 같은 개발 코드에는 도메인의 구조가, 비즈니스 로직에는 운영하면서 축적된 규칙과 제약조건이 이미 녹아있습니다.
이 지식을 AI로 구조화하면 Knowledge Graph의 출발점을 훨씬 빠르게 만들 수 있습니다.
이 글에서는 기존 Java/Spring 코드에서 그래프 스키마 명세를 추출하고, Amazon Neptune Analytics(그래프 분석에 최적화된 분석 데이터베이스 서비스)와 Amazon Bedrock Knowledge Bases(파운데이션 모델과 데이터 소스를 연결해 RAG를 구성하는 완전 관리형 서비스)를 연결해 GraphRAG를 구현하는 과정을 소개합니다.
이 글에서 다루는 내용
- 그래프 스키마 설계 : 기존 개발 코드에서 AI와 도메인 전문가 협업으로 Knowledge Graph 스키마를 추출합니다.
- Neptune Analytics 적재 : 설계된 스키마 기반으로 데이터를 변환하고 적재합니다.
- GraphRAG 질의 구현 : Amazon Bedrock Knowledge Bases를 활용해 자연어로 그래프를 탐색합니다.
사전 준비 사항
- AWS 계정
- Amazon Bedrock 모델 접근 권한 (Anthropic Claude Sonnet 4.5)
- Amazon S3 버킷 (CSV 데이터 업로드용)
- Java/Spring 기반 프로젝트 (또는 ORM이 포함된 개발 코드)
왜 기존 코드에서 시작하는가
RAG(Retrieval-Augmented Generation)는 LLM이 외부 지식을 참조해 답변하는 패턴으로 널리 쓰입니다.
공연 티켓 예매 서비스를 예로 들어, 다음 질문을 생각해봅시다.
“스타라이트 페스티벌 2025에 대한 정보와 예약 좌석 정보를 알려주세요.”

단순한 질문도 답하지 못하는데, “서울에서 열리는 공연 중 VIP석이 있고, K-Pop 아티스트가 출연하는 공연은?” 처럼 여러 조건이 결합된 질문이라면 상황은 더 어렵습니다. 이 질문에 답하려면 공연장의 도시, 공연과 공연장의 관계, 좌석 등급, 잔여 예약 수, 아티스트 장르라는 5개 엔티티에 걸친 연결 정보가 필요합니다.
LLM 단독으로는 이런 구조적 데이터를 알 수 없고, 벡터 유사도 검색은 의미적으로 가까운 텍스트 조각을 찾는 데 강하지만, 여러 엔티티를 거쳐야 하는 관계 기반 질의에서는 연결 경로를 추적할 수 없습니다.
Knowledge Graph는 데이터를 노드(개념)와 엣지(관계)의 네트워크로 표현합니다.
위와 같은 질문은 그래프 탐색을 활용하면 보다 효과적으로 처리할 수 있습니다.
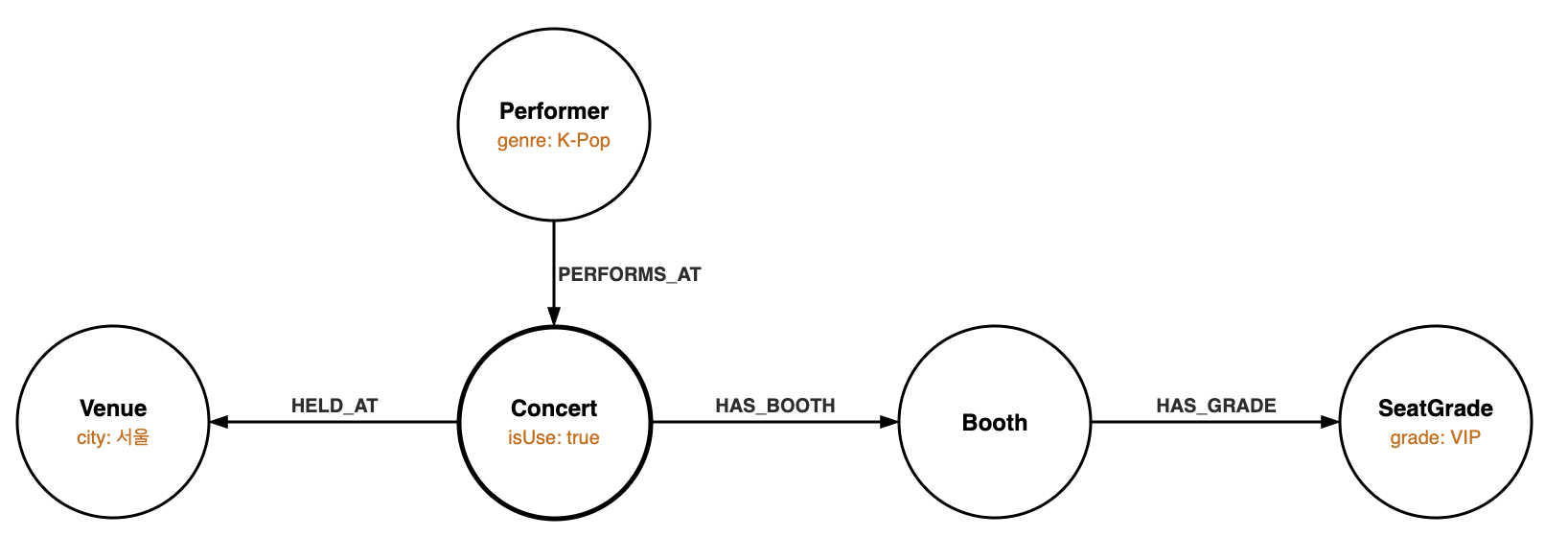
그렇다면 이 Knowledge Graph의 설계도, 즉 그래프 스키마는 어디서 가져올 수 있을까요?
사실 우리가 이미 잘 알고 있는 곳에 있습니다. 개발 코드의 ORM(예: JPA 엔티티의 @ManyToOne, @OneToMany) 관계는 이미 그래프 엣지이고, 서비스 로직(예: 유효성 검증, 상태 전이 조건)은 비즈니스 규칙으로 활용할 수 있습니다.
새로 설계하는 것보다 이미 코드에 있는 도메인 지식을 구조화하는 편이 훨씬 빠릅니다.
전체 파이프라인
전체 흐름은 다음과 같습니다.
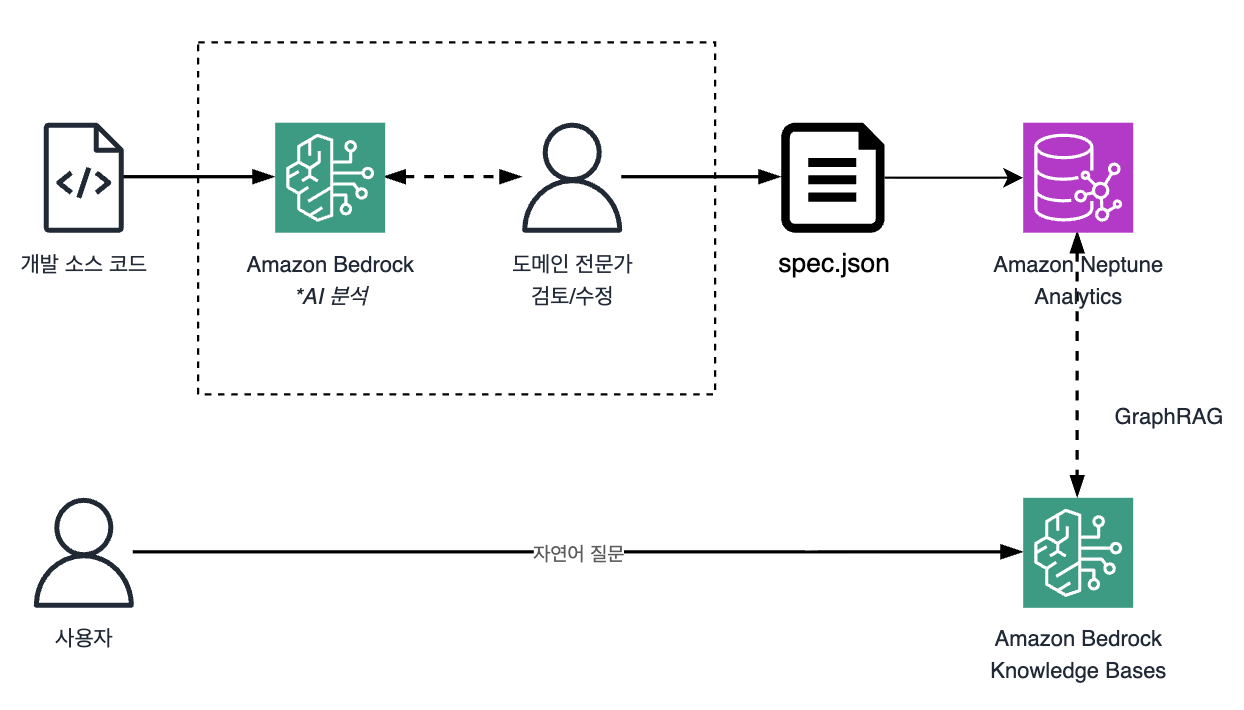
핵심은 코드에서 AI와 도메인 전문가의 협업으로 만들어지는 spec.json이라는 그래프 스키마 명세입니다.
이 파일이 어떻게 생성되고, Neptune Analytics 적재와 GraphRAG까지 어떻게 이어지는지 순서대로 살펴보겠습니다.
이 글에서는 공연 티켓 예매 서비스(Spring Boot 3.2 + JPA)를 예시 도메인으로 가정하고 진행합니다.
1단계. 코드에서 그래프 스키마 설계하기
AI에게 제공할 파일
우리가 AI에게 전달할 개발 코드는 크게 두 종류입니다. 코드가 많다면 핵심 도메인을 담당하는 파일 위주로 선택합니다.
| 코드종류 | AI가 추출하는 것 | Spring/JPA 예시 |
|---|---|---|
| 데이터 모델 – 엔티티, 테이블 정의 등 | 노드, 속성, 관계 (엣지) | @Entity 클래스 |
| 비즈니스 로직 – 서비스, 유효성 검증 등 | 제약 규칙, 상태 전이, 수량 제한 | ServiceImpl, RepositoryImpl |
AI와 대화하며 스키마 설계
Amazon Bedrock의 Anthropic Claude Sonnet 4.5 모델에 소스코드와 함께 다음 프롬프트를 전달합니다.
당신은 소프트웨어 도메인을 분석해 Knowledge Graph 스키마를 설계하는 전문가입니다.
현재폴더의 개발 소스 코드들을 깊게 읽고 분석해 그래프 스키마 명세를 spec.json 으로 기록해야 합니다.
단 기록하기에 앞서 우리는 내용을 검토하고, 대화를 이어가며 누락된 개념 추가,규칙 수정, 범위 조정을 반복해야합니다.
반드시 모호한 부분은 질문하며 기록하기위해 내용을 고도화해야 합니다
### 분석 기준
**노드와 관계 추출**
- ORM 엔티티나 데이터 모델이 있다면 이를 기반으로 노드, 속성, 관계를 도출
- 관계명은 FK 필드명이 아닌 도메인 언어로 정의 (동사_전치사, 예: PERFORMS_AT)
- 도메인 맥락상 필요하지만 코드에 없는 개념도 제안할 것
**비즈니스 규칙 추출**
- 코드에서 제약조건, 상태 전이, 수량 제한 등 서비스/비즈니스 규칙이 발견되면 추출
- 하드코딩된 값이 있고 의미가 모호하다면 그 의미를 질문할 것
**검증**
- 자연어 질의 시나리오를 3개 이상 생성하고 그래프 탐색으로 답할 수 있는지 검증AI의 초안을 도메인 전문가가 검토하고, 대화를 이어가며 수정합니다. 이 과정에서 AI는 자체적으로 판단하기 어려운 부분을 질문하게 되는데, 다음과 같은 유형이 있습니다.
- DB데이터를 함께 분석해야 알 수 있는 케이스.
- [질문] boothName 필드가 있는데 이것은 구역 코드 (예 “A-1” , “VIP-05”)인가? 자유 텍스트인가요?
- [질문] Concert-Venue 관계의 제약 – 현재는 Concert가 하나의 Venue에 속하는데 동일 공연이 “여러 날짜”, “여러 장소”에서 열릴 수 있나요?
- 비즈니스규칙을 개발에서 제대로 찾지 못한 케이스
- [질문] 예약 상태 전이 규칙 – 코드에서 PENDING으로 시작하는 것을 봤는데 PENDING → CONFIRMED 전이는 언제 일어나나요? 이 전이 조건은 그래프 규칙으로 명시해야 하나요?
- 구성하고자 하는 제품의 핵심기능이나 MSA로 구성 되어있어 식별되지 않은 케이스.
- [질문] 현재 코드에서는 예약시스템에서 일반적으로 필요한 Payment 개념이 없는데 결제 정보를 그래프로 포함해야 하나요?
AI가 80%, 사람이 20%
AI가 구조를 빠르게 만들지만 나머지는 코드만으로 알 수 없습니다. 이 프로젝트에서 사람이 결정한 것은 다음과 같습니다.
| 구분 | AI가 한 것 | 사람이 결정한 것 |
|---|---|---|
| 도메인 개념 | 코드의 4개 엔티티(Concert, Booth, Reservation, User) 추출 | Venue, Performer, SeatGrade 3개 개념 추가 결정 |
| 코드 하드코딩 값 | count < 100 → “Booth당 최대 100개” 규칙 추출 |
100은 임시값, 오류이며 DB Booth.maxCapacity 존재를 알림 |
| 스키마 범위 | (User)-[LIKES]->(Performer) 관계 제안 |
현재 코드에 없는 기능은 범위 밖, 제외 결정 |
도메인이 무엇을 표현해야 하는가는 그 서비스를 이해하는 사람 (도메인전문가)만이 판단할 수 있습니다.
출력: spec.json
분석과 검토가 완료되면 AI에게 확정된 내용을 JSON으로 출력하도록 요청합니다.
샘플 프로젝트의 결과물은 7개 노드, 7개 엣지, 8개 비즈니스 규칙으로 구성됩니다. 핵심 구조만 발췌하면 다음과 같습니다.
{
"domain":"공연 티켓 예매 서비스",
"version":"1.0",
"source":"ticket-sample",
"nodes":[
{
"label":"Concert",
"koreanName":"공연",
"properties":["concertName","isUse","concertDate"]
},
{
"label":"Venue",
"koreanName":"공연장",
"properties":["venueName","city","totalCapacity"]
},
{
"label":"Performer",
"koreanName":"아티스트",
"properties":["performerName","genre"]
},
{
"label":"SeatGrade",
"koreanName":"좌석등급",
"properties":["grade","price"]
},
{
"label":"User",
"koreanName":"사용자",
"properties":["userName","email"]
},
{
"label":"Booth",
"koreanName":"구역",
"properties":["boothName"],
"constraints":["최대 100명까지 예약 가능"]
},
{
"label":"Reservation",
"koreanName":"예약",
"properties":["status"]
}
],
"edges":[
{"label":"HELD_AT","from":"Concert","to":"Venue"},
{"label":"PERFORMS_AT","from":"Performer","to":"Concert"},
{"label":"HAS_BOOTH","from":"Concert","to":"Booth"},
{"label":"HAS_GRADE","from":"Booth","to":"SeatGrade"},
{"label":"RESERVED_BY","from":"Reservation","to":"User"},
{"label":"FOR_BOOTH","from":"Reservation","to":"Booth"},
{"label":"FOR_CONCERT","from":"Reservation","to":"Concert","derived":true}
],
"businessRules":[
"Concert.isUse = false → 예약 생성 불가",
"(User, Concert, Booth) 조합의 Reservation은 유일해야 함",
"Booth당 CONFIRMED Reservation 수 < 100 (선착순)"
]
}2단계. Neptune Analytics에 데이터 적재하기
1단계에서 만든 spec.json은 그래프의 구조(스키마)를 정의합니다.
이제 이 스키마에 맞춰 기존 데이터베이스의 실제 데이터를 Neptune Analytics에 적재해야 합니다.
이 글에서는 데모용 샘플 데이터로 진행하고, 운영 환경의 적재 방법은 하단 “더 나아가기” 섹션에서 간략히 소개합니다.
spec.json → Neptune CSV 스키마 생성
Amazon Bedrock의 Anthropic Claude Sonnet 4.5 모델을 이용해 Neptune CSV의 스키마(헤더)를 생성합니다.
프로젝트의 spec.json을 참조하여 Neptune Analytics Bulk Loader용 CSV 스키마 (헤더)를 생성해주세요.
- nodes/ 폴더: 각 노드 타입별 CSV
헤더: ~id, ~label, 속성명:타입
- edges/ 폴더: 각 엣지 타입별 CSV
헤더: ~id, ~from, ~to, ~label
- ~id 형식: {label소문자}:{id값} (예: concert:1)생성 결과 노드 7개, 엣지 7개 파일의 스키마가 만들어집니다.
neptune-csv/
├── nodes/
│ ├── concert.csv
│ ├── venue.csv
│ ├── performer.csv
│ ├── booth.csv
│ ├── seatgrade.csv
│ ├── reservation.csv
│ └── user.csv
└── edges/
├── held_at.csv
├── performs_at.csv
├── has_booth.csv
├── has_grade.csv
├── for_booth.csv
├── reserved_by.csv
└── for_concert.csv
# nodes/concert.csv
~id,~label,concertId:Int,concertName:String,isUse:Bool,concertDate:String
# edges/performs_at.csv
~id,~from,~to,~label데이터베이스에서 CSV 채우기
스키마가 확정되면 데이터베이스의 데이터를 CSV에 채웁니다.
Kiro 같은 AI IDE를 활용하면 프로젝트 컨텍스트 안에서 DB를 읽고 CSV를 한 번에 생성할 수 있습니다.
# nodes/concert.csv
~id,~label,concertId:Int,concertName:String,isUse:Bool,concertDate:String
concert:1,Concert,1,스타라이트 페스티벌 2025,true,2025-08-15
concert:2,Concert,2,재즈 나이트,true,2025-09-20
concert:3,Concert,3,한여름 클래식 콘서트,true,2025-10-05
concert:4,Concert,4,가을 뮤직 페어,false,2025-11-01
# edges/performs_at.csv
~id,~from,~to,~label
performs_at:1,performer:1,concert:1,PERFORMS_AT
performs_at:2,performer:2,concert:2,PERFORMS_AT
performs_at:3,performer:3,concert:3,PERFORMS_AT
performs_at:4,performer:4,concert:4,PERFORMS_ATNeptune Analytics에 적재
생성된 CSV를 S3에 업로드한 뒤, Neptune Analytics 콘솔의 데이터 가져오기로 적재합니다.
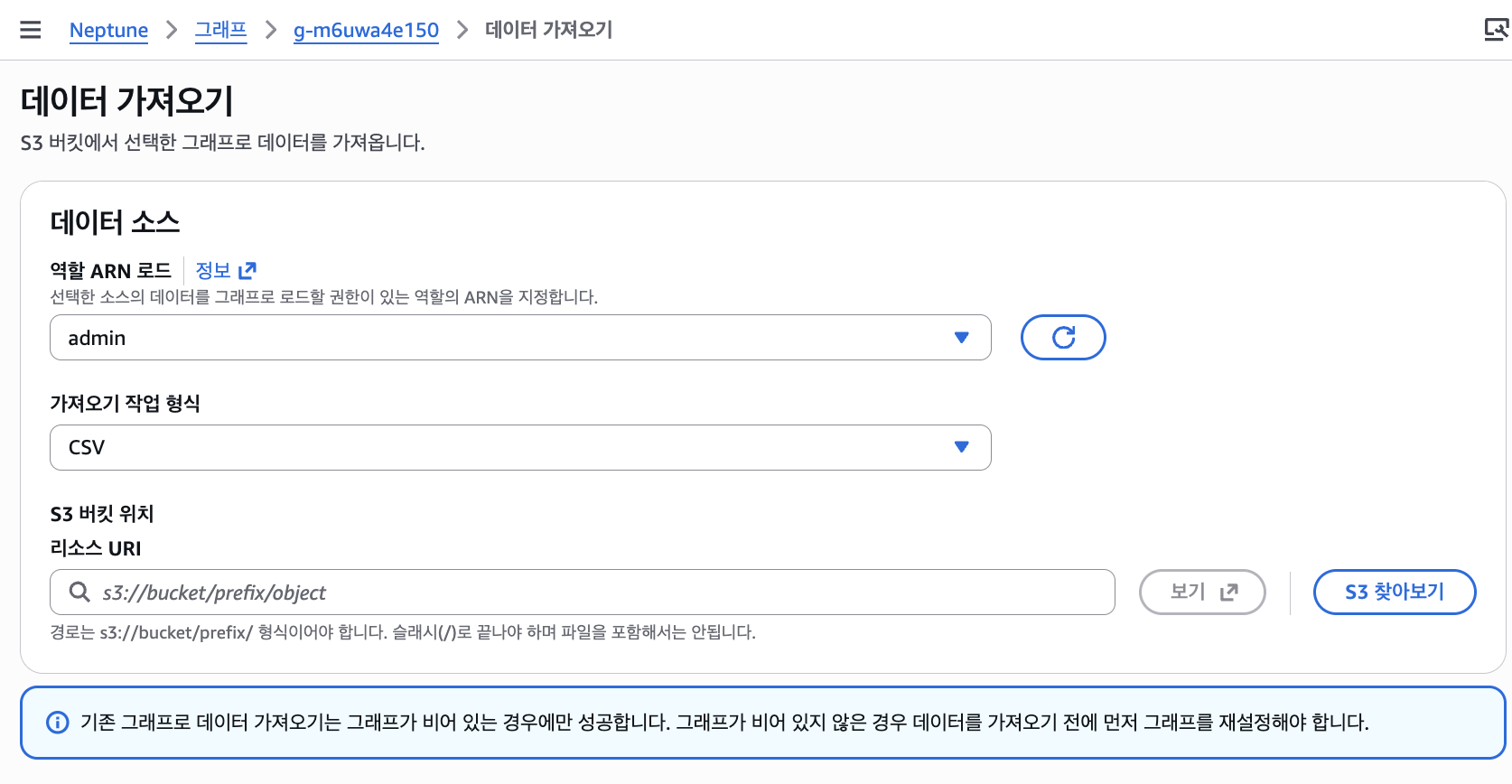
3단계. Amazon Bedrock Knowledge Bases로 GraphRAG 연결하기
Neptune Analytics에 데이터가 적재됐으니, 사용자가 자연어로 질문하면 Knowledge Graph를 탐색해 답변하는 GraphRAG를 구성합니다.
일반 RAG와 GraphRAG의 차이
[일반 RAG] 사용자 질문 → 벡터 유사도 검색 → 유사 문서 조각 반환 → LLM답변
[GraphRAG] 사용자 질문 → 그래프 구조 탐색 → 엔티티 간 관계 기반 결과 반환 → LLM답변Bedrock Knowledge Bases 연결
Amazon Bedrock Knowledge Bases는 Neptune Analytics를 활용한 GraphRAG를 지원합니다.
Knowledge Bases 생성 시 벡터 저장소를 새로 생성하거나, 기존 Neptune Analytics 그래프를 그대로 활용할 수 있어 별도 코드 없이 그래프 구조를 활용한 질의가 바로 가능합니다.
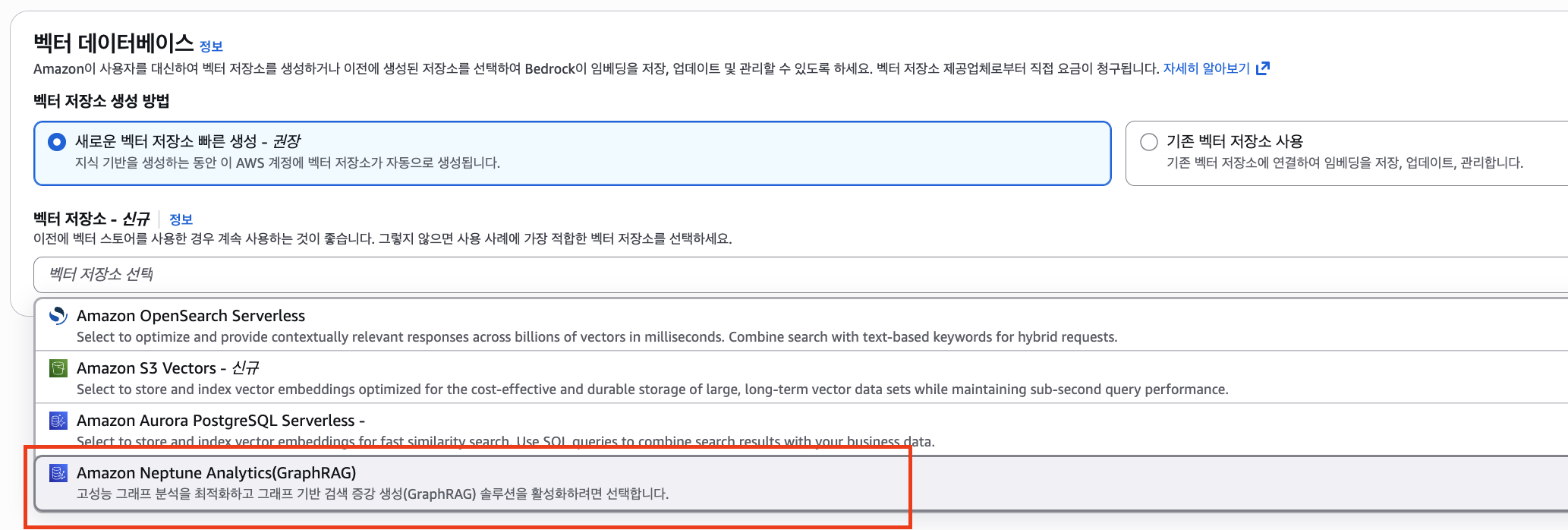
만들어진 Knowledge Bases에 데이터 소스를 동기화하여 그래프 데이터를 인덱싱합니다.
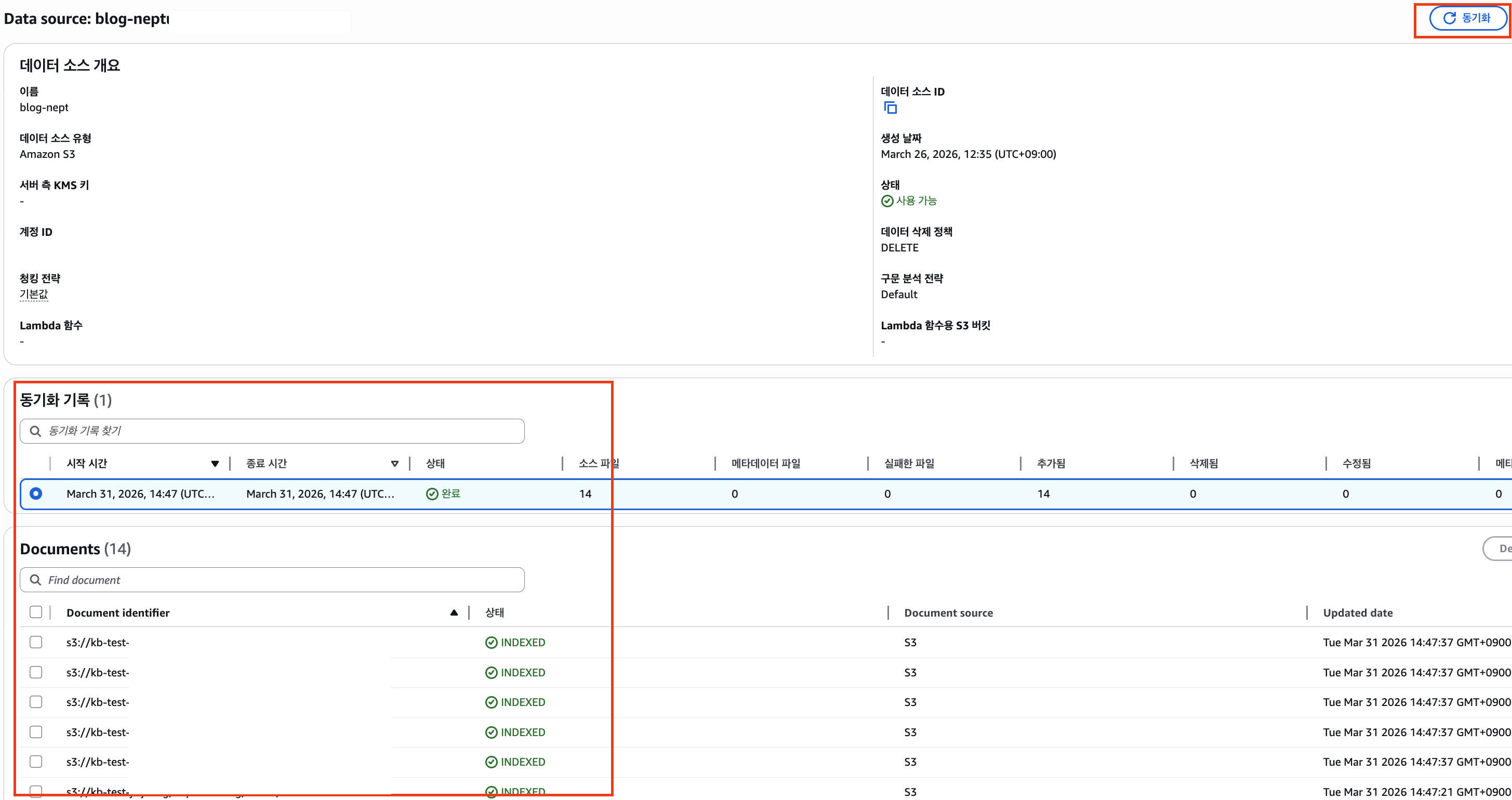
GraphRAG 질의 결과
Knowledge Bases는 다양한 파운데이션 모델을 선택해 질의를 테스트할 수 있는 환경을 제공합니다.
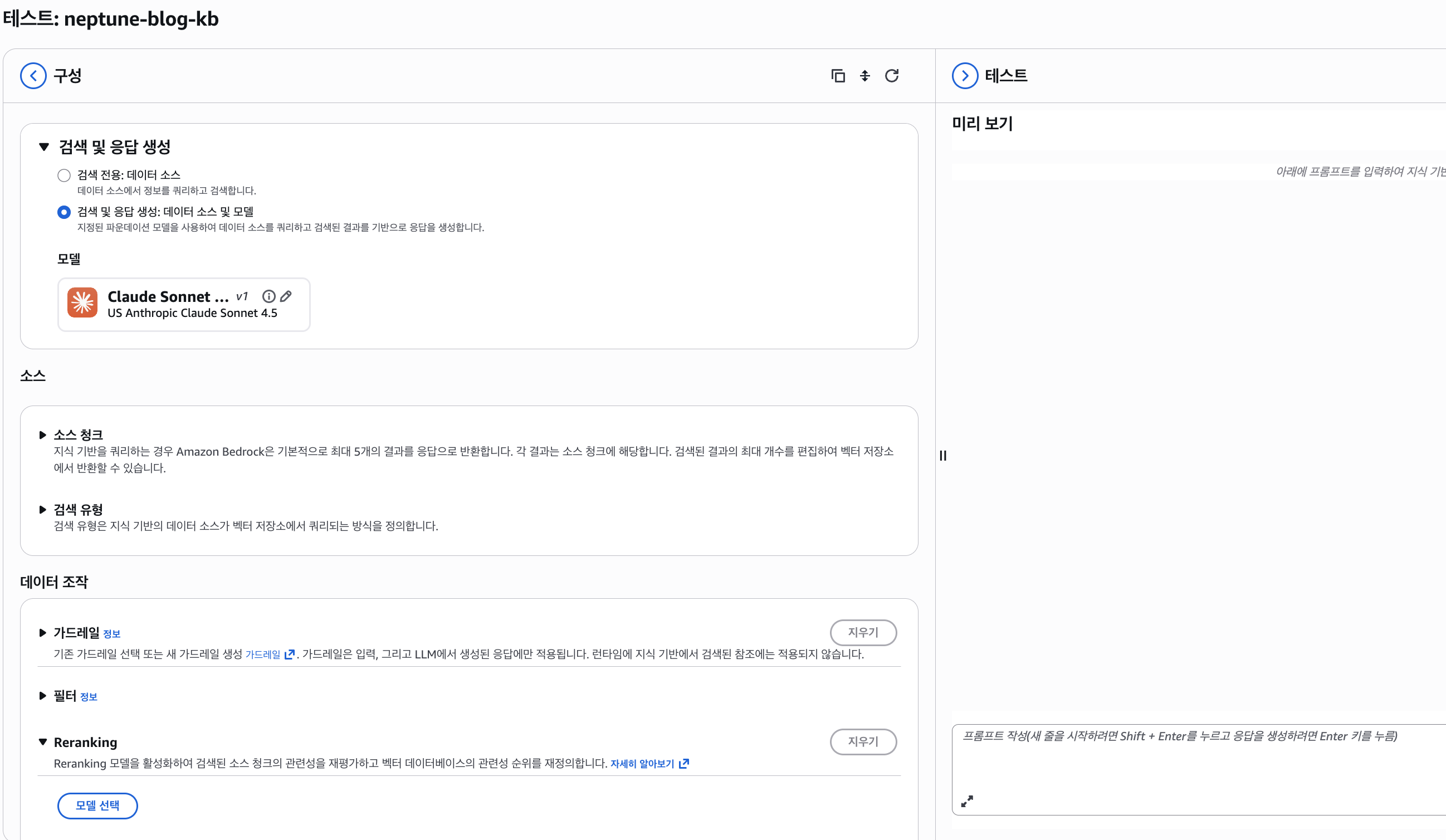
서론에서 LLM 단독으로는 답할 수 없었던 질문들을, 다양한 그래프 탐색 패턴으로 처리합니다.
- 분기 탐색 : “스타라이트 페스티벌 2025에 대한 정보와 예약 좌석 정보를 알려주세요”
- 멀티홉 필터링 : “Classical 장르 공연 중 서울에서 열리는 공연은?”
- 역방향 탐색: “VIP석 예약이 가장 많은 공연은 무엇이고, 그 공연은 어디에서 열리나요?”
가장 복잡한 다음 질의도 한 번에 처리됩니다.
멀티 홉 분기 탐색 + 집계 : “서울에서 열리는 공연 중 VIP석이 있는 공연과 가격, 그리고 출연 아티스트를 모두 알려주세요. 그리고 예매자가 가장 많은 공연은 무엇인가요”

벡터 유사도 검색으로는 어려운 구조적 멀티홉 질의를, Knowledge Graph 기반으로 처리하는 것을 확인할 수 있습니다. 답변에는 소스 세부 정보가 함께 제공되어, 어떤 그래프 데이터를 참조했는지 추적할 수 있습니다.
마치며
핵심 인사이트
1. 기존 코드에 이미 그래프 스키마가 있다 — ORM의 관계 매핑은 그래프 엣지이고, 서비스 로직에 담긴 코드들은 비즈니스 규칙이 될 수 있습니다. 새로 설계하는 것이 아니라 이미 있는 지식을 구조화하는 것입니다.
2. AI는 추출하고, 사람은 결정한다 — AI가 80%를 빠르게 만들지만, 도메인 개념 추가, 하드코딩 값의 의미 해석, 스키마 범위 설정은 사람의 영역입니다.
3. spec.json이 파이프라인의 기반이다 — 그래프 스키마 설계부터 데이터 적재까지 하나의 명세가 기준이 됩니다. 새 도메인에도 같은 파이프라인을 그대로 적용할 수 있습니다.
자신의 프로젝트에 적용하기
- 데이터 모델 + 비즈니스 로직 코드 준비
- AI 프롬프트 실행 → spec.json 초안 생성
- 도메인 전문가와 함께 검토/수정 → 확정
- CSV 생성 프롬프트 실행 → Neptune Analytics 적재
- Amazon Bedrock Knowledge Bases 구성 → GraphRAG 자연어 질의 테스트
복잡한 도메인일수록 3번(검토/수정)에 더 많은 시간이 필요합니다. 그 시간이 Knowledge Graph의 품질을 결정합니다.
더 나아가기
이 글에서는 CSV 기반 정적 데이터를 활용했지만, 실제 환경에서는 지속적으로 변화하는 운영 데이터와의 연계가 중요합니다.
이를 위해 다음과 같은 확장 방향을 고려할 수 있습니다.
- 운영 데이터 동기화 : AWS Glue를 통한 배치 처리나 DMS 같은 CDC(Change Data Capture)를 활용해 기존 RDB의 변경 데이터를 그래프 구조로 변환하고 Neptune Analytics에 반영할 수 있습니다.
- 하이브리드 검색 : 벡터 기반 의미 검색에 그래프 탐색을 결합하여, 단순 유사도 검색을 넘어 관계 기반 추론을 강화할 수 있습니다.
비용 안내
이 글에서 사용한 Amazon Neptune Analytics, Amazon Bedrock 등의 서비스에는 비용이 발생할 수 있습니다.
테스트 후 불필요한 리소스는 삭제하시기 바랍니다. 자세한 내용은 각 서비스의 요금 페이지를 참고하세요.