AWS 기술 블로그
프로덕션 Multi-Agent 시스템이 해결해야 할 5가지 문제 – Deep Insight 아키텍처로 배우는 실전 설계
AI Agent를 만드는 것 자체는 이제 어렵지 않습니다. 오픈소스 프레임워크와 클라우드 서비스 덕분에 에이전트 구축 자체는 수일 내에 가능해졌고, 툴 호출 몇 개, 프롬프트 몇 줄이면 그럴듯한 에이전트를 만들 수 있습니다. 그러나 파일럿을 넘어 실제 비즈니스에 적용하려는 순간, 많은 팀들이 비슷한 벽에 부딪힙니다. Agent를 프로덕션에 적용하려다가 막힌 분들이라면 다음 고민들에 공감하실 것입니다.
“왜 에이전트가 우리 비즈니스 로직대로 처리하지 않을까?”
“왜 필수 검증 단계를 건너뛸까?”
“왜 예외 상황을 감지하지 못할까?”
프롬프트를 고치고, 예시를 추가하고, 모델을 바꿔봐도 비슷한 문제가 계속 반복됩니다. 에이전트는 정해진 순서가 아니라 맥락에 따라 스스로 판단하기 때문에 지시사항만으로는 부족합니다. 어떻게 생각하고, 언제 확인하고, 실패하면 어떻게 할지 판단하는 방식 자체를 설계해야 합니다. 이것이 바로 단순한 프롬프트 엔지니어링을 넘어, 에이전트의 인지 구조와 실행 흐름 전체를 설계하는 일이 중요해진 이유입니다.
AWS Korea SA Team은 이러한 과제를 직접 풀기 위해 ‘Deep Insight’ 라는 프로덕션급 Multi-Agent 시스템을 개발했습니다. 이번 블로그 시리즈에서는 AWS Korea SA Team이 Deep Insight를 개발하며 직접 경험하고 해결한 내용을 3회에 걸쳐 공유합니다. Multi-Agent Architecture, Structured Note-Taking, Human-in-the-Loop 등 Anthropic이 제안한 Context Engineering 기법들을 실제 프로덕션 환경에 어떻게 적용했는지, 어떤 trade-off가 있었는지 코드와 함께 살펴보고, 이 에이전트를 AWS에 배포하고 운영하며 얻은 인사이트까지 실전에서 검증된 방법들을 상세히 다룹니다.
[시리즈 블로그 보기]
- Part 1: 프로덕션 Multi-Agent 시스템이 해결해야 할 5가지 문제 – Deep Insight 아키텍처로 배우는 실전 설계
- Part 2: Context Window 한계를 넘어서 – Deep Insight 개발 여정으로 배우는 Context Engineering 실전 기법 (발행 예정)
- Part 3: 개발에서 운영까지 – Deep Insight 에이전트를 AWS에 안전하게 배포하는 방법 (발행 예정)
첫 번째 블로그에서는 프로덕션 Multi-Agent 시스템이 반드시 해결해야 할 5가지 핵심 문제를 정의하고, Strands Agents SDK, Amazon Bedrock, Amazon Bedrock AgentCore, 그리고 Application Load Balancer와 AWS Fargate 등의 인프라가 각각 어떤 계층의 문제를 해결하는지를 함께 소개합니다. 두 번째 블로그에서는 LLM의 Context Window 한계를 극복하기 위한 4가지 계층의 핵심 기법과 구체적인 구현 방법을 다룹니다. 마지막 세 번째 블로그에서는 로컬 개발 환경에서 나아가 AWS VPC 상에 보안을 갖춘 Private Network로 에이전트를 배포하고 운영하기까지, 실제 운영에 필요한 모든 과정을 안내합니다.
Deep Insight 알아보기
Deep Insight는 복잡한 데이터 분석 작업을 자동화된 인사이트로 전환하는 Multi-Agent 시스템입니다. CSV 파일과 간단한 자연어 프롬프트를 입력하면, Coordinator, Planner, Supervisor, 그리고 Coder, Validator, Reporter, Tracker 등 전문화된 에이전트들이 계층적으로 협력하여 데이터를 로드하고, 분석하고, 차트를 생성하고, 계산을 검증한 뒤, 최종적으로 인용이 포함된 전문 보고서(.docx 파일)를 자동으로 생성합니다.
Deep Insight의 아키텍처와 설계 구조는 뒤에서 자세히 다룰 예정이므로, 먼저 실제로 Deep Insight가 어떻게 동작하는지를 살펴보겠습니다. 데모를 위해 가상의 식품판매 기업 Moon Market의 신선식품 판매 데이터(`moon-market-fresh-food-sales.csv`)와 컬럼 정의 파일(`column_definitions.json`)을 입력하고, "세일즈 및 마케팅 관점으로 분석을 해주고, 차트 생성 및 인사이트도 뽑아서 docx 파일로 만들어줘"라는 프롬프트를 전달하면, Deep Insight는 분석 계획을 생성하여 사용자에게 보여주고, 승인을 받은 후 데이터 분석을 수행합니다. 최종적으로 인용이 포함된 DOCX 보고서와 인용이 제외된 버전 두 가지, 그리고 분석 과정에서 생성된 차트 그래프(PNG)를 제공합니다.
| 내용 | |
| Input | CSV 데이터 파일 (‘moon-market-fresh-food-sales.csv’) + 컬럼 정의 JSON (‘column_definitions.json’) |
| 예시 프롬프트 | “세일즈 및 마케팅 관점으로 분석을 해주고, 차트 생성 및 인사이트도 뽑아서 docx 파일로 만들어줘” |
| Output | DOCX 보고서 (인용 포함/미포함 2종) + 차트 그래프 파일 (PNG) |
아래의 Deep Insight Web 버전 데모 영상에서 전체 워크플로우를 쉽게 확인할 수 있습니다. 데이터 업로드부터 분석 계획 검토, 실시간 스트리밍, 보고서 다운로드까지의 과정을 보여줍니다: https://youtu.be/zYDGI6X0UhY
어떻게 실행해볼 수 있나요?
Deep Insight는 Github에 전체 오픈소스로 실행 가이드와 함께 공개되어 있으며, 개발 단계부터 프로덕션 운영까지 지원하는 세 가지 배포 옵션을 제공합니다.
- 첫 번째는 Self-Hosted 버전으로, 로컬 환경에서 CLI로 실행하는 방식입니다. 빠른 반복 개발과 테스트에 최적화되어 있으며, 모든 에이전트, 프롬프트, 워크플로우에 대한 완전한 코드 접근 권한을 제공합니다. 약 10분 내에 설정을 완료할 수 있어 개발 환경에 적합합니다. (Self-Hosted 시연 영상은 Youtube에서 확인 가능합니다)
- 두 번째는 Web 버전으로, 브라우저 기반 UI를 통해 데이터 업로드, 분석 계획 검토(HITL), 보고서 다운로드까지 코드 한 줄 없이 수행할 수 있습니다. 비개발자도 쉽게 사용할 수 있는 인터페이스를 제공하여 비즈니스 유저가 직접 분석을 수행할 수 있습니다. (위의 데모 영상이 Web 버전에 해당합니다)
- 세 번째는 Managed AgentCore 버전으로, Amazon Bedrock AgentCore Runtime을 활용한 프로덕션 배포 옵션입니다. 100% Private VPC 내에서 안전하게 운영되며, AWS Fargate 인프라에서 별도 호스팅되는 Custom Code Interpreter와 함께 제공됩니다. 사용자별로 격리된 환경에서 에이전트가 동시 실행되므로 엔터프라이즈급 보안과 확장성이 필요한 경우에 적합합니다. AgentCore 버전의 상세한 배포 방법과 운영 노하우는 이후 블로그 Part 3에서 자세히 다룰 예정입니다.
세 버전 모두 동일한 Multi-Agent 아키텍처를 사용하기 때문에 개발 환경에서 검증한 에이전트를 프로덕션에 그대로 배포할 수 있습니다.
솔루션 개요
프로덕션 Multi-Agent 시스템을 구축하려면 “좋은 프롬프트”만으로는 부족합니다. 에이전트가 어떻게 협업하고, 어떻게 사고하며, 어디서 코드를 안전하게 실행하고, 어떻게 운영 상태를 모니터링할 것인지 — 각 문제를 해결하는 올바른 기술 스택과 인프라가 필요합니다. Deep Insight는 다음 5가지 영역의 문제를 해결합니다.
| 해결해야 할 문제 | 활용 기술 | 방법 요약 | |
| 1 | “멀티에이전트 간 실행 흐름을 어떻게 제어할까?” | Strands Agents SDK |
Strands의 ‘Graph’ 패턴을 활용해 에이전트 간 실행 순서 정의 및 Human-in-the-loop 분기 처리 구현 Strands의 ‘Agents as Tools’ 패턴을 활용해 Supervisor가 전문 에이전트 (Coder/Validator/Reporter/Tracker)를 필요 시점에 도구처럼 호출 |
| 2 | “에이전트가 어떤 LLM 모델을 사용해야 할까?” | Amazon Bedrock | 역할별 Claude 모델 선택 (Haiku: 간단 라우팅, Opus: 계획, Sonnet: 실행) |
| 3 | “완성한 에이전트를 프로덕션에서 어떻게 안정적으로 운영하지?” | Amazon Bedrock AgentCore | 관리형 런타임 및 모니터링, 세션 격리, Private VPC 배포 |
| 4 | “AI가 생성한 코드 실행 시의 보안 위험을 어떻게 방지할까?” | AWS Fargate + Application Load Balancer (ALB) | 세션별 임시 샌드박스 컨테이너 구현 (코드 격리 실행을 위한 Custom Code Interpreter) |
| 5 | “시스템을 어떻게 모니터링하고 관리하지?” | DynamoDB (작업 기록 저장) + Amazon SNS (실패 시 알림) + Cognito (보안) | 관리자 대시보드 및 장애 알림 시스템 구현 |
아키텍처 다이어그램으로 표현하면 아래 [Figure 1]과 같습니다. 그림에서 연두색 박스로 표현된 Strands Agents 멀티에이전트 구조를 통해 위 표의 1,2번 문제가 해결됩니다. 이에 대한 자세한 내용은 곧바로 이어질 [솔루션 상세 1: 멀티에이전트 시스템 설계] 섹션에서 다룹니다. 그리고 그 외에 그림에 표시된 모든 인프라 구성을 통해 3,4,5번 문제를 해결합니다. 이 부분은 이후 이어질 [솔루션 상세 2: 프로덕션 배포 및 운영] 섹션에서 찬찬히 살펴보겠습니다.
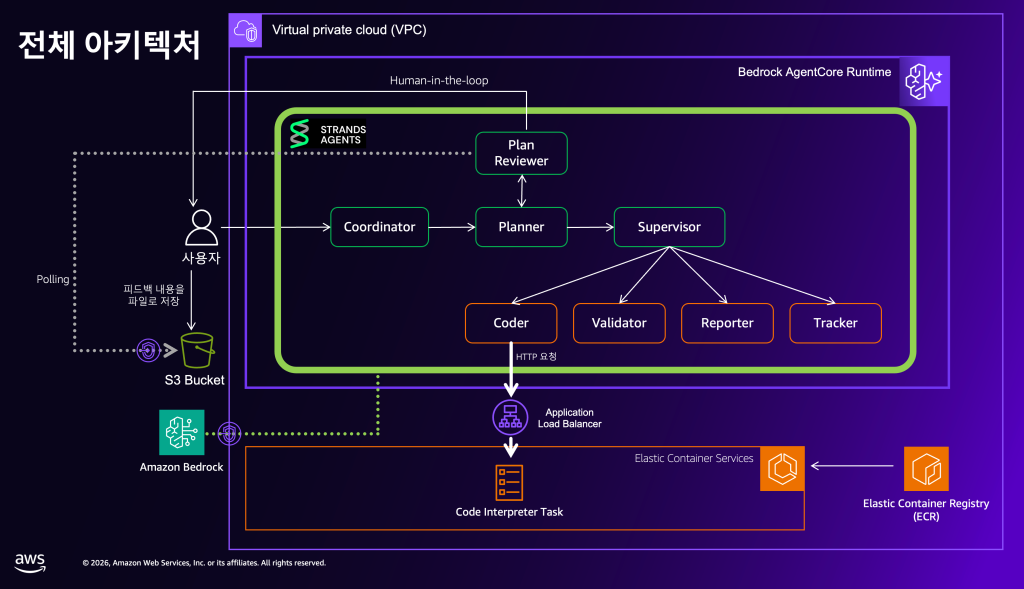
Figure 1. 솔루션 아키텍처
솔루션 상세 1: 멀티에이전트 시스템 설계
Deep Insight는 총 8개의 에이전트 간 협업을 통해 하나의 완성도 높은 결과물을 만드는 멀티에이전트 아키텍처를 채택하고 있습니다. 각 에이전트는 독립적인 context에서 전문 영역의 작업만 수행하고, 압축된 결과만 다음 에이전트에게 전달합니다.
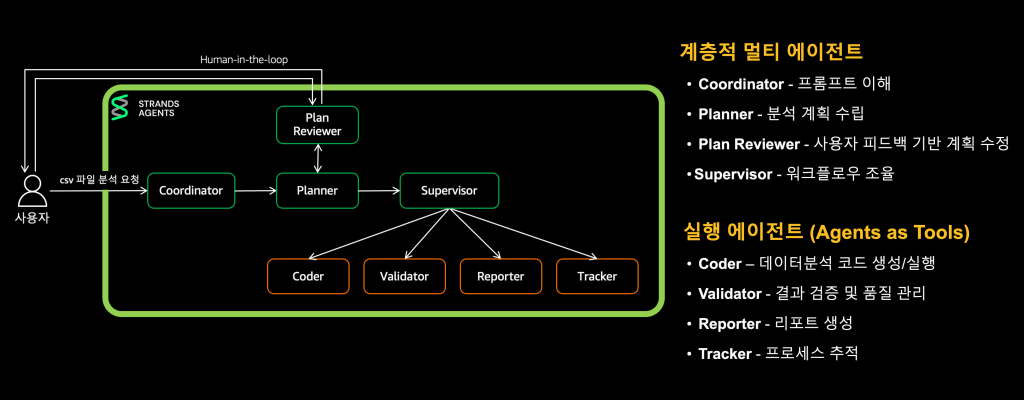
Figure 2. 멀티에이전트 구조
Coordinator는 사용자 요청을 라우팅하고, Planner는 작업을 단계별로 분해하며, Plan Reviewer는 사용자 검토를 받고, Supervisor는 계획에 따라 적절한 전문 에이전트를 호출합니다. Coder는 데이터 분석 코드를 작성 및 실행하고, Validator는 계산을 검증하며, Reporter는 최종 보고서를 생성하고, Tracker는 진행 상황을 추적합니다. 이를 3개의 레이어로 나누어 설명하겠습니다.
- [1st Layer] Coordinator, Planner, Plan Reviewer: 요청 분석 및 실행 계획 수립
- [2nd Layer] Supervisor: 전문 에이전트 오케스트레이션
- [3rd Layer] Coder, Validator, Reporter, Tracker: 전문 작업 실행
이러한 멀티에이전트들의 실행 흐름을 제어하는 데에는 Strands Agents SDK가 제공하는 두 가지 핵심 패턴 조합이 사용되었습니다.
첫째, Graph 패턴을 사용해 에이전트들의 실행 순서와 흐름을 방향 그래프로 정의합니다. 사용자 요청은 Coordinator → Planner → Plan Reviewer → Supervisor 순서로 진행되며, Plan Reviewer에서 사용자가 수정을 요청할 경우 조건부 분기를 통해 다시 Planner로 돌아가 계획을 재작성합니다. 이처럼 상황에 따라 다음 단계를 동적으로 결정할 수 있어 HITL (Human-in-the-Loop)이나 에러 처리 같은 복잡한 워크플로우를 유연하게 구현할 수 있습니다.
둘째, Agents-as-tools 패턴을 활용해 Supervisor가 Coder, Validator, Reporter, Tracker 같은 전문 에이전트들을 마치 도구처럼 필요한 시점에만 호출합니다. 각 전문 에이전트는 독립적인 context에서 작업을 수행하고 결과만 Supervisor에게 반환하므로, 전체 시스템의 context 사용량을 최소화하면서도 전문성을 유지할 수 있습니다.
이 섹션에서는 이러한 아키텍처가 라우팅, 계획 수립, 오케스트레이션의 문제들을 어떻게 해결하는지 살펴봅니다.
[1st layer] Coordinator, Planner, Plan Reviewer
1.1 Coordinator (라우팅) – 모든 요청에 비싼 오케스트레이션이 필요하지는 않다
Coordinator는 사용자 요청의 진입점입니다. 단순한 인사말이나 자기소개 질문은 직접 처리하고, 데이터 분석과 같은 복잡한 작업은 handoff_to_planner 마커를 응답에 포함시켜 Planner에게 라우팅합니다.
핵심 설계 결정은 모델 선택입니다. Coordinator는 빠른 분류만 수행하므로 가장 경량인 Claude Haiku 모델을 사용합니다. 이를 통해 단순 인사말에 Opus급 비용을 지출하는 낭비를 방지하고 유저에게 빠른 응답을 제공하도록 합니다.
# builder.py — 조건부 엣지로 라우팅 결정
builder.set_entry_point("coordinator")
builder.add_edge("coordinator", "planner", condition=should_handoff_to_planner)
Coordinator의 라우팅 조건은 프롬프트에 명시된 판단 기준에 따라 결정됩니다. 도구 사용, 추론, 또는 다단계 사고가 필요한 요청은 모두 Planner에게 전달됩니다.
1.2 Planner (계획 수립): 복잡한 분석은 실행 전에 분해가 필요하다
Deep Insight의 멀티에이전트 구조에서 Planner 에이전트는 각 에이전트에게 업무를 분담하는 중요한 역할을 수행합니다. 본격적인 작업을 수행하기에 앞서 Planner 에이전트가 초반에 큰 작업을 작은 단계들로 분해하는 역할을 담당하고, 이후 각 전문 에이전트는 그 계획에 맞춘 작업을 한 번에 하나씩 순차 실행함으로써 각 에이전트의 context를 줄입니다.
Planner는 ‘Extended Thinking (확장 사고)’이 활성화된 Claude Opus 모델을 사용하여 분석 계획을 수립하고, [ ] 체크리스트 형식으로 각 에이전트에게 배정할 작업을 구체적으로 명시하여 full_plan 변수로 저장합니다. Planner는 아래와 같이 사용자 요청을 받아 5-10개의 명확한 단계로 분해합니다.
1.3 Plan Reviewer
Plan Reviewer는 HITL (Human-in-the-Loop) 노드로, 생성한 계획을 사용자에게 보여주고 승인 또는 수정 피드백을 받습니다. 피드백이 있으면 Planner로 되돌아가 계획을 수정하고, 승인되면 Supervisor로 작업을 넘깁니다. 이때 최대 수정 횟수(MAX_PLAN_REVISIONS)를 설정하여 무한 루프를 방지합니다.
# builder.py — Plan Reviewer의 양방향 조건부 엣지
builder.add_edge("plan_reviewer", "planner", condition=should_revise_plan)
builder.add_edge("plan_reviewer", "supervisor", condition=should_proceed_to_supervisor)
builder.set_max_node_executions(25)
Deep Insight의 Web 버전에서는 Plan Reviewer가 브라우저에 모달 창을 표시하여, 사용자가 계획을 읽고 승인하거나 수정 피드백을 입력할 수 있습니다. 카운트다운 타이머(300초)가 표시되며, 시간 내에 응답이 없으면 자동으로 승인됩니다.
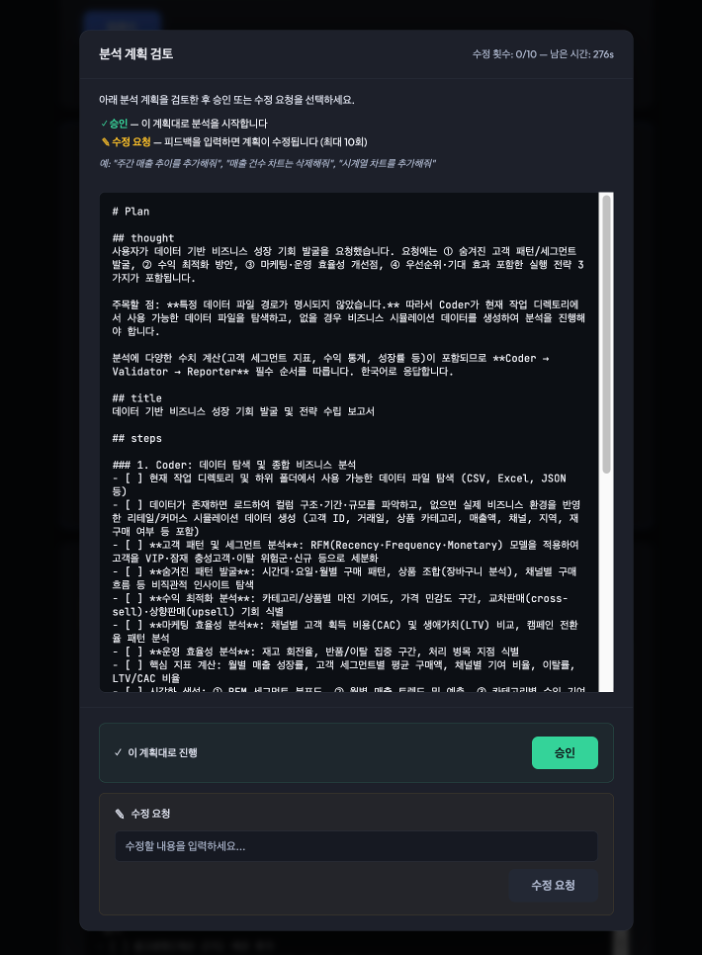
Figure 3. Plan Reviewer 에이전트 실행 Web 화면
Planning 없이 작업하면 에이전트가 즉석에서 모든 것을 결정해야 하고, 중간에 방향 전환이 필요하면 이전 작업이 무효화됩니다. 또한 사용자는 진행상황을 전혀 파악할 수 없습니다. Deep Insight에서는 Planner와 Plan Reviewer 에이전트를 통해 사용자가 plan을 검토하고 수정할 수 있게 하며, 각 단계별 진행상황을 실시간으로 확인하고 만일 특정 단계가 실패하더라도 해당 단계만 재실행할 수 있도록 설계했습니다.
[2nd layer] Supervisor (오케스트레이터): 전문 에이전트에게는 지휘자가 필요하다
Supervisor는 Planner가 생성한 full_plan의 체크리스트를 순서대로 실행하는 오케스트레이터입니다. 핵심 특징은 3rd layer의 전문 에이전트들을 Tool Use로 호출한다는 점입니다. 즉, Coder, Validator, Reporter, Tracker와 같은 다른 전문 에이전트들이 Supervisor의 도구 (Tool)로 등록되어 있습니다.
# nodes.py — Supervisor 에이전트에 Sub Agent를 Tool로 등록
agent = strands_utils.get_agent(
agent_name="supervisor",
system_prompts=apply_prompt_template(prompt_name="supervisor", prompt_context={}),
model_id=os.getenv("SUPERVISOR_MODEL_ID", os.getenv("DEFAULT_MODEL_ID")),
prompt_cache_info=(True, "default"),
tool_cache=True,
tools=[coder_agent_tool, reporter_agent_tool, tracker_agent_tool, validator_agent_tool],
streaming=True,
)
Supervisor의 시스템 프롬프트는 엄격한 워크플로우 규칙을 정의합니다:
- 필수 실행 순서: Coder → Tracker → Validator → Tracker → Reporter → Tracker와 같이, 각 에이전트 실행 후 Tracker로 필수로 작업을 넘기게 하여 진행 상태를 추적함으로써 Supervisor가 전체 작업 상태를 관리할 수 있도록 합니다.
- 섹션 완료 규칙: 현재 에이전트의 모든 체크리스트가
[x]가 될 때까지 다음 에이전트로 넘어가지 않습니다. - 컨텍스트 보존: 각 도구 에이전트에게
clues변수와full_plan변수를 전달함으로써 전체 컨텍스트를 유지하고 맥락 손실을 방지합니다.
[3rd layer] Coder, Validator, Reporter, Tracker: 분업이 완성도를 만든다
Layer 3의 각 전문 에이전트 Coder, Validator, Reporter, Tracker는 PythonAgentTool로 래핑되어 Supervisor의 Tool Use 호출을 받습니다. 이들은 각각 Strands SDK의 독립된 Agent() 인스턴스로 생성되며, 자체적인 시스템 프롬프트와 모델 ID, 그리고 도구 세트를 갖습니다.
| 에이전트 | 역할 | 보유 도구 | 주요 출력물 |
| Coder | 데이터 분석, 차트 생성, 인사이트 도출 | write_and_execute_tool, bash_tool, file_read, skill_tool | *.png 차트, calculation_metadata.json |
| Validator | 수치 계산 재검증, 인용 생성 | write_and_execute_tool, bash_tool, file_read | citations.json, validation_report.txt |
| Reporter | DOCX 보고서 생성 | write_and_execute_tool, bash_tool, file_read | final_report.docx, final_report_with_citations.docx |
| Tracker | 체크리스트 진행 상태 업데이트 | 없음 (LLM 추론만 사용) | 업데이트된 full_plan |
Supervisor는 Planner의 체크리스트를 기반으로 다음 순서대로 Tool Use를 호출합니다.
- Coder — 데이터를 로드하고 분석 코드를 작성/실행합니다. 분석의 결과물로 시각화 차트 (PNG 파일)를 생성하고, 어떤 분석을 진행했는지를
all_results.txt파일에 상세히 누적해 기록하며, 수치 검증용 파일인calculation_metadata.json을 남겨 정확한 데이터 분석을 할 수 있도록 합니다. - Tracker (1차) — Coder가 완료한 체크리스트 항목을
[ ]에서[x]로 업데이트합니다. Supervisor는 이 결과를 보고 다음 에이전트로 넘어갈지 판단합니다. - Validator — Coder가 남긴
calculation_metadata.json파일을 읽고, 각 계산을 소스 데이터에서 다시 수행하여 결과를 비교합니다. 0.01 오차 범위 내에서 일치하면 검증을 통과한 것으로 표시하고, 불일치하면 오류를 플래그합니다. 검증된 계산은citations.json파일에 저장되어 이후 Reporter 에이전트가 리포트에 인용으로 포함할 수 있습니다. - Tracker (2차) — Validator 완료 상태를 체크리스트에 반영합니다.
- Reporter —
all_results.txt(분석 결과)와citations.json(인용 메타데이터)을 읽어 최종 DOCX 보고서를 인용 포함/미포함 2종으로 생성합니다. - Tracker (3차) — 모든 작업의 완료 상태를 최종 반영합니다.
Tracker가 매 에이전트 실행 후 반복 실행되는 이유는, Supervisor가 “현재 어디까지 완료되었는지”를 정확히 파악하고, 모든 항목이 [x]가 될 때까지 다음으로 넘어가지 않는 섹션 완료 규칙을 강제하기 위해서입니다. Tracker는 도구 없이 LLM 추론만으로 체크리스트를 갱신하는 경량 에이전트이므로, 오버헤드를 최소화하면서 진행 상태를 관리합니다.
에이전트별 LLM 모델 구성
Deep Insight는 각 에이전트의 역할에 맞게 서로 다른 모델과 설정을 사용합니다. 이는 단순한 모델 선택이 아닌, 비용과 품질을 최적화하는 아키텍처적 결정입니다.
| 에이전트 | 모델 | Extended Thinking | Prompt Caching | 역할 |
| Coordinator | Haiku | 비활성화 | No | 빠른 라우팅 — 비용 최소화 |
| Planner | Opus | 활성화 (약 8192 토큰) | No | 심층 사고 — 최고 품질 계획 수립 |
| Supervisor | Sonnet | 비활성화 | Yes | 실행 오케스트레이션 — 캐싱으로 비용 절감 |
| Coder | Sonnet | 비활성화 | Yes | 코드 생성/실행 — 반복 호출에 캐싱 효과적 |
| Validator | Sonnet | 비활성화 | No | 수치 검증 — 매번 다른 데이터로 캐싱 불필요 |
| Reporter | Sonnet | 비활성화 | Yes | 보고서 생성 — 긴 프롬프트에 캐싱 효과적 |
| Tracker | Sonnet | 비활성화 | No | 상태 업데이트 — 경량 작업으로 캐싱 불필요 |
Prompt Cache가 활성화된 Supervisor, Coder, Reporter 에이전트는 시스템 프롬프트와 도구 정의를 캐싱하여 반복 호출 시 입력 토큰 비용을 최대 90%까지 절감합니다. 반면 Coordinator는 단 한 번 호출되고, Validator/Tracker는 매번 다른 컨텍스트로 호출되므로 캐싱의 효과가 낮아 비활성화했습니다. 이러한 선택적 캐싱 전략은 의도적인 비용/성능 트레이드오프입니다.
솔루션 상세 2: 프로덕션 배포 및 운영
앞선 [솔루션 상세 1: 멀티에이전트 시스템 설계]의 내용이 “무엇을 하는가”를 정의한다면, 이 섹션은 “어디서, 어떻게 안전하게 실행하는가”를 정의합니다. 즉, 아래부터는 프로덕션 운영을 위한 인프라적 결정 사항이 이어집니다. 자세히는 LLM이 생성한 코드의 안전한 실행 환경과 팀을 위한 운영 가시성을 다루겠습니다.
1. 코드 실행: LLM이 생성한 코드에는 안전한 실행 환경이 필요하다
Coder 에이전트는 데이터 분석을 위한 Python 코드를 작성하고 실행합니다. Self-Hosted 버전에서는 로컬에서 직접 subprocess.run()으로 코드를 실행하지만, 로컬이 아닌 프로덕션(AgentCore) 환경에서는 보안과 격리가 필수적입니다. LLM이 생성한 코드를 프로덕션 서버에서 직접 실행하는 것은 여러 보안 위험을 발생시킬 수 있습니다. 예를 들어, LLM이 의도치 않게 시스템 파일을 삭제하는 코드를 생성하거나, 무한 루프로 서버 리소스를 고갈시키거나, 다른 사용자의 분석 데이터가 저장된 디렉토리에 접근할 수도 있습니다. Deep Insight는 AWS Fargate 컨테이너와 ALB를 활용해 세션별 임시 컨테이너를 제공하여 이 문제를 해결합니다.
- 커스텀 컨테이너 도커 이미지: 한글폰트 설치 및 멀티 에이전트가 사용하는 시스템 라이브러리, Python Packages 설치를 통하여 최적화된 코드 샌드박스 환경을 생성 합니다.
- 컨테이너 격리: 각 분석 세션마다 독립적인 Fargate 컨테이너가 생성됩니다. 컨테이너는 Private VPC 서브넷에서 실행되며, 직접적인 인터넷 접근이 없습니다.
- 2-step 실행: LLM이 생성한 코드는 base64로 인코딩되어 HTTP로 전송됩니다. 컨테이너 내에서 파일을 쓰고(Step 1), subprocess로 실행(Step 2)하는 2단계 과정을 거칩니다.
- 세션 친화성: 에이전트가 여러 번 코드를 실행하더라도 같은 컨테이너로 라우팅되도록 ALB Sticky Session 쿠키를 사용합니다.
- 아티팩트 관리: 분석이 완료되면 생성된 차트, 보고서, 로그가 S3에 업로드됩니다. 컨테이너는 1시간 후 자동으로 종료됩니다.
2. 운영과 모니터링: 팀에게는 가시성이 필요하다
프로덕션 시스템은 코드만으로 완성되지 않습니다. 팀이 시스템의 상태를 파악하고, 문제를 진단하며, 결과를 확인할 수 있어야 합니다. 이를 위해 Deep Insight는 Web UI와 Ops 대시보드를 제공합니다.
Web UI (deep-insight-web)
FastAPI 기반의 웹 인터페이스로, AgentCore Native Protocol (boto3.invoke_agent_runtime())을 통해 백엔드와 통신합니다. 사용자는 브라우저에서 데이터를 업로드하고, 분석 프롬프트를 입력하면 SSE (Server-Sent Events) 스트리밍으로 실시간 분석 진행 상황을 확인할 수 있습니다. 분석 계획이 생성되면 모달 창이 나타나 승인 또는 수정 피드백을 입력할 수 있으며 (HITL), 완료 후 생성된 보고서를 직접 다운로드할 수 있습니다. 한국어/영어 다국어를 지원합니다.
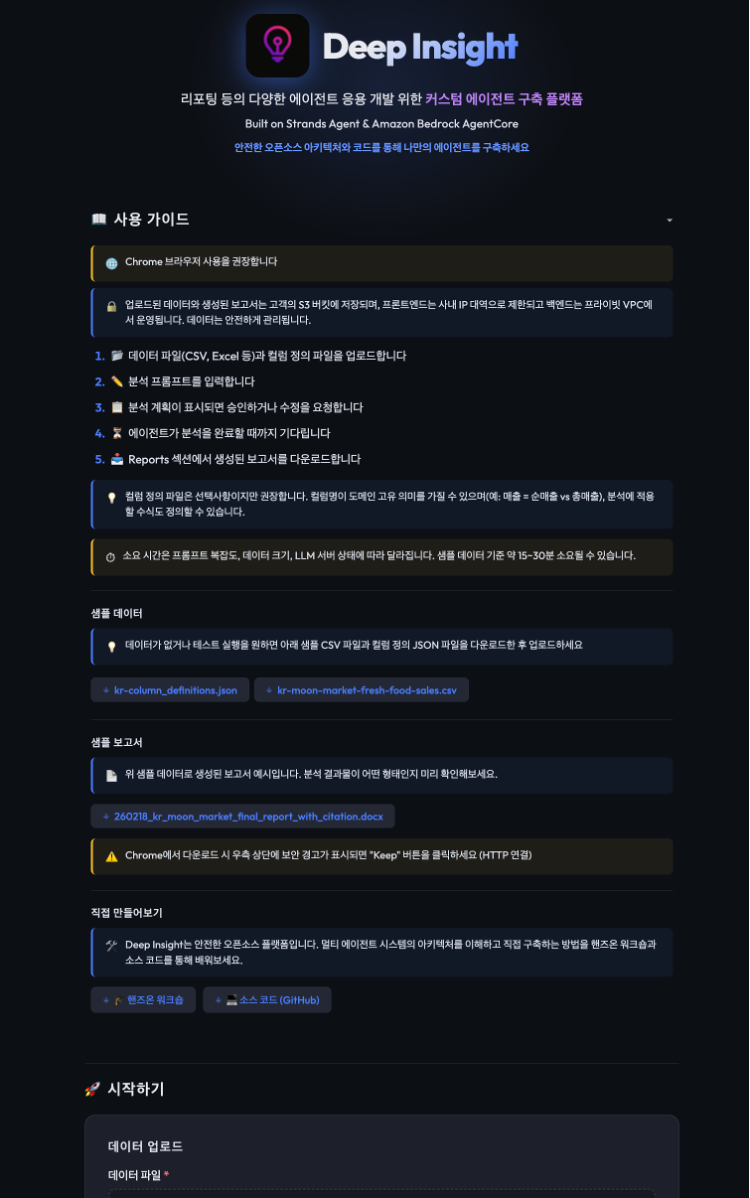
Figure 4. Deep Insight Web 버전 스크린샷
Ops 대시보드 (deep-insight-web/ops)
Ops 대시보드는 필수가 아니며, 필요 시 추가할 수 있습니다. 운영팀을 위한 모니터링 장치로, 추가하지 않더라도 Deep Insight는 정상 작동하지만 다음과 같은 추가 기능이 구현되어 있어 운영팀이 필요에 따라 사용할 수 있습니다:
- 작업 추적: DynamoDB에 상태, 토큰 사용량, 소요 시간과 같은 모든 분석 작업 메트릭을 기록합니다.
- 장애 알림: 분석 실패 시, Amazon SNS를 통해 관리자에게 즉시 이메일을 발송합니다.
- 관리자 대시보드: 관리자 전용 대시보드를 Amazon Cognito의 JWT 인증으로 보호하여 안전하게 작업을 모니터링할 수 있습니다.
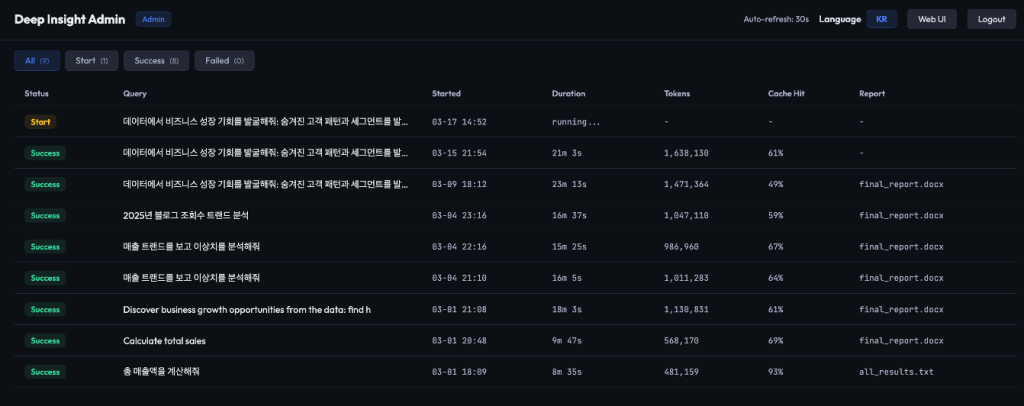
Figure 5. Deep Insight Ops 대시보드 스크린샷
Deep Insight 아키텍처의 확장 사례
Deep Insight의 멀티 에이전트 아키텍처는 데이터 분석 보고서 생성이라는 하나의 도메인에 국한되지 않습니다. 다음 두 가지 사례를 통해, 계층적 오케스트레이션 설계 원리가 전혀 다른 도메인에서도 유효함을 확인할 수 있습니다.
사례 1: LG전자 – Agentic AI 기반 마케팅 인사이트 추출 시스템
LG전자 한국영업본부는 데이터 분석 요청부터 결과 수령까지 2~3주가 걸리고, 마케터와 데이터 사이언티스트 사이에서 의도가 유실되며, 시장 타이밍을 놓치는 일이 반복되었습니다. 이 문제를 해결하기 위해 LG전자는 Deep Insight와 동일한 멀티 에이전트 아키텍처를 채택한 ChatInsight 시스템을 구축했습니다. Coordinator가 요청의 복잡도를 판단하여 라우팅하고, Planner가 분석 전략을 수립한 뒤 Task Tracking으로 완료 상태를 관리하며, Supervisor가 Coder와 Reporter를 오케스트레이션하는 구조입니다. 에이전트 간 정보 전달 역시all_results.txt 파일 기반의 누적 방식을 그대로 적용하여, 컨텍스트 유실 없이 대규모 분석 결과를 전달합니다.
결과는 놀라웠습니다. 3일 걸리던 분석이 30분으로 단축되어 생산성이 288배 향상되었습니다. 마케터가 SQL이나 분석 방법론을 몰라도, “어떤 질문을 해야 할지” 고민하지 않아도, 에이전트가 자율적으로 데이터를 탐색하고 패턴을 찾아 실행 가능한 마케팅 전략까지 제안합니다.

Figure 6. LG전자의 Agentic AI 기반 마케팅 인사이트 추출 활용 사례
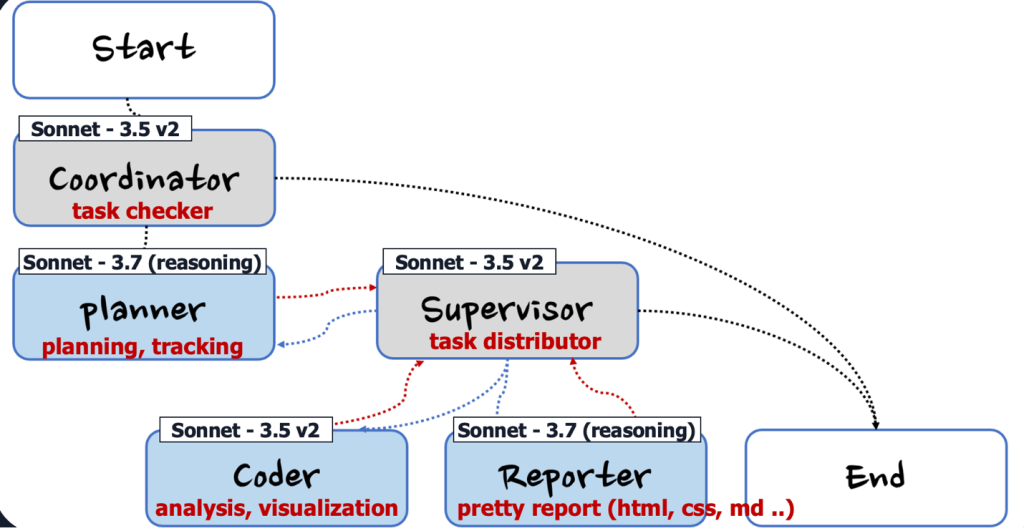
Figure 7. LG전자의 Agentic AI 기반 마케팅 인사이트 추출 시스템 아키텍처
(자세히 보기: LG전자의 Agentic AI 기반 인사이트 추출 시스템 개발기 – AWS Tech Blog)
사례 2: TechRecon – AI 기반 기술 정찰 에이전트 (re:Invent 2025)
AWS re:Invent 2025 세션 SNR203: “A leader’s guide to emerging technologies: From insights to rapid action”에서 발표된 TechRecon은 Deep Insight의 아키텍처를 기술 전략 도메인에 적용한 사례입니다. TechRecon은 기업 리더를 위한 기술 정찰을 자동화합니다. 회사명과 산업 분야를 입력하면, Researcher 에이전트가 Tavily 검색과 웹 크롤링으로 신기술 동향을 수집하고, Coder가 데이터를 분석하며, Validator가 검증한 뒤, Reporter가 두 종류의 결과물 — 1/Landscape Analysis(신기술 전체 분석)와 2/Technical Position Paper(특정 기술 심층 분석)를 생성합니다.
아키텍처는 Deep Insight와 거의 동일합니다. Router Planner → Supervisor → Tool Agents (Researcher, Coder, Reporter, Tracker, Validator) 구조를 Strands Agents SDK의 Graph 패턴 구현체인 GraphBuilder로 구현하고, Extended Thinking과 Prompt Caching을 적용했습니다. 핵심적인 차이는 Coder 대신 Researcher가 주요 실행 에이전트라는 점뿐이며, 계층적 오케스트레이션과 컨텍스트 격리라는 설계 원리는 그대로 유지됩니다.
이 두 사례는 Deep Insight의 아키텍처가 특정 유스케이스에 종속된 것이 아니라, 도메인을 교체해도 동작하는 범용적인 설계 패턴임을 보여줍니다. 에이전트의 역할과 프롬프트만 교체하면, 동일한 오케스트레이션 구조 위에서 전혀 다른 문제를 해결할 수 있습니다.
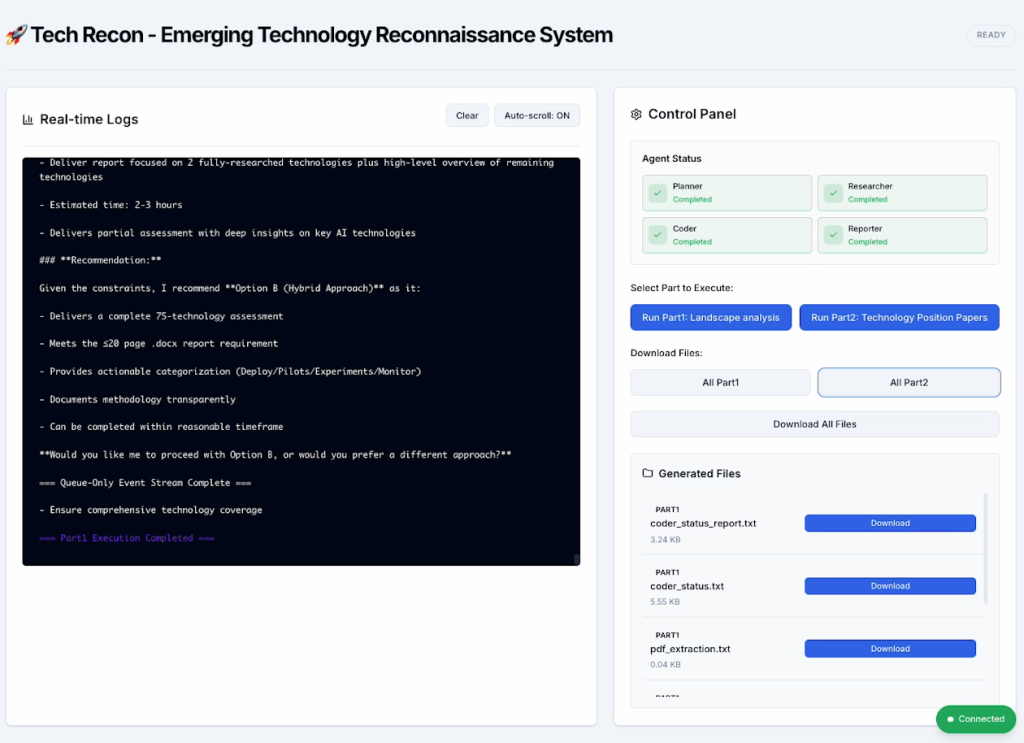
Figure 8. TechRecon 실행 화면

Figure 9. TechRecon 결과물
(자세히 보기: TechRecon Github | AWS re:Invent 강연 영상)
마무리
프로덕션에서 동작하는 에이전트를 만든다는 것은 모델의 능력이 아니라, 아키텍처의 문제입니다. Deep Insight는 이 질문에 대해 검증된 답을 제시합니다.
- 워크플로우 관리: Strands Agents SDK의 Graph 패턴으로 에이전트 간 실행 순서를 정의하고 HITL 분기 처리를 구현하며, Agents-as-tools 패턴으로 Supervisor가 전문 에이전트를 필요 시점에만 호출합니다.
- 추론 엔진: Amazon Bedrock의 Claude 모델을 역할별로 배치하여 (Haiku → Opus → Sonnet) 비용과 품질을 최적화합니다.
- 배포: Amazon Bedrock AgentCore로 관리형 런타임에 배포하여, 세션 격리와 Private VPC 배포, OpenTelemetry Observability를 확보합니다.
- 코드 실행: ALB + ECS (Fargate)로 LLM이 생성한 코드를 세션별 임시 샌드박스 컨테이너에서 격리 실행하여 시스템 파일 접근, 리소스 고갈, 데이터 유출 등의 보안 위험을 방지합니다.
- 운영: Web UI의 SSE 스트리밍과 Ops 대시보드(DynamoDB + Cognito + SNS)로 팀 전체에 가시성을 제공합니다.
이 설계 원리는 LG전자의 마케팅 인사이트 시스템과 re:Invent 2025의 TechRecon 사례를 통해 유효성이 입증되었습니다.
다음 블로그(Part 2)에서는 이 아키텍처 위에서 Context Window의 한계를 극복하기 위한 4가지 계층의 Context Engineering 기법을 상세히 다룹니다. 아키텍처 수준의 격리부터 프롬프트 설계, 도구 최적화, 검증 안전장치까지 — 각 계층이 어떻게 context를 효율적으로 관리하는지, Anthropic의 엔지니어링 리서치와 비교하며 소개합니다.
Deep Insight는 오픈소스로 공개되어 있습니다. 코드를 직접 확인하고 여러분의 도메인에 맞게 확장해 보시기 바랍니다.
- GitHub: https://github.com/aws-samples/sample-deep-insight
- Workshop: Deep Insight Workshop (한국어 | English)