AWS 기술 블로그
생성형AI를 통한 데브옵스 강화 – Part 2.운영 안정성 강화
이 블로그는 생성형 AI를 통한 데브옵스를 강화 시리즈의 두 번째입니다. DevOps Research and Assessment(DORA)에서 제시한 데브옵스 성숙도 측정 4가지 핵심 지표는 처리량 지표(변경 적용 시간, 배포 빈도)와 안정성 지표(변경 실패율, 장애 복구 시간)로 구분됩니다. 지난 생성형AI를 통한 데브옵스 강화 – Part 1.소프트웨어 딜리버리 가속화에 이어서 이번 편에서는 안정성 지표를 개선하여 운영 안정성을 높이는 방법에 대해 살펴봅니다.
데브옵스를 도입해야하는 이유
오늘날 비즈니스 환경에서 소프트웨어는 단순한 지원 도구가 아닌 핵심 경쟁력으로 자리 잡았습니다. 이러한 변화 속에서 데브옵스(DevOps)는 조직이 빠르게 변화하는 시장 요구에 대응하고 고객 가치를 지속적으로 전달하기 위한 필수 요소가 되었습니다.
전통적인 소프트웨어 개발 방식은 마치 한 팀이 레고 조각을 설계 및 제작하고 다른 팀이 설명서 없이 그것을 조립하는 것과 같았습니다. 개발자들이 코드를 작성하고 나면 이 후 코드를 실행하고 운영하는 것은 IT 운영팀의 몫이 되었습니다. 이러한 사일로화된 접근 방식은 세 가지 주요 문제를 야기했습니다:
- 조직 또는 팀간의 소통하는 데 소비되는 시간으로 인해 모든 과정이 지나치게 오래 걸렸습니다.
- 운영팀은 코드에 대한 세세한 부분을 알지 못하기 때문에 문제 발생 시 빠르게 대처하기 어려웠습니다.
- 조직들은 장애 복구에 막대한 비용을 지출해야 했습니다.
데브옵스는 이러한 문제를 해결하기 위해 전통적인 소프트웨어 개발과 IT 운영을 결합하며, 문화, 프로세스, 기술을 통합합니다. 이는 계획(Plan), 코드(Code), 빌드(Build), 테스트(Test), 배포(Deploy), 운영(Operate), 모니터링(Monitor)의 연속적인 사이클로 이루어집니다.
데브옵스를 도입함으로써 얻을 수 있는 주요 이점은 다음과 같습니다:
- 확장성(Scale): 데브옵스 도구와 관행은 중단 없이 애플리케이션과 서비스를 원활하게 반복적으로 확장할 수 있도록 도와줍니다.
- 속도(Speed): 지속적 통합(CI)과 지속적 배포(CD)를 통해 코드 커밋부터 프로덕션 환경까지의 시간을 단축합니다.
- 안정성(Reliability): 데브옵스는 일관된 성능과 장애로부터의 빠른 복구, 지속적인 모니터링을 통해 고객에게 영향을 미치기 전에 문제를 포착할 수 있게 합니다.
- 협업(Collaboration): 사일로화된 팀들이 서로 다른 목표와 목적을 가지고 작업하던 방식에서 벗어나, 통합된 책임과 목표를 가지고 함께 일하는 방식으로 전환합니다.
- 보안(Security): 보안은 더 이상 마지막 단계의 체크리스트가 아닙니다. DevSecOps를 통해 전체 데브옵스 라이프사이클에 보안이 통합되어 있습니다.
데브옵스 성숙도 측정
데브옵스 여정을 시작하거나 개선하기 위해서는 현재 조직의 데브옵스 성숙도를 객관적으로 측정하는 것이 중요합니다. DevOps Research and Assessment(DORA)에서 제시한 4가지 핵심 지표는 데브옵스 성숙도를 측정하는 데 널리 사용됩니다:
- 변경 적용 시간(Lead Time for Changes): 코드 변경이 커밋에서 프로덕션까지 걸리는 시간
- 배포 빈도(Deployment Frequency): 코드가 프로덕션에 배포되는 빈도
위 두 지표는 처리량 지표(Throughput Metrics)로, 시간에 따른 속도를 측정합니다.
- 변경 실패율(Change Failure Rate): 프로덕션 배포 후 수정이 필요한 비율
- 장애 복구 시간(Mean Time to Recovery, MTTR): 서비스 중단 시 복구까지 걸리는 평균 시간
위 두 지표는 안정성 지표(Stability Metrics)로, 배포의 품질과 장애 대응 능력을 측정합니다.
이러한 지표를 통해 조직은 자신의 데브옵스 성숙도 수준을 파악하고, 개선이 필요한 영역을 식별할 수 있습니다.
| 지표 | 최상 ? | 상 ? | 중 ? | 하 ? |
|---|---|---|---|---|
| 변경 리드 타임 | 1일 미만 | 1일 -1주 | 1주 – 1개월 | 1주 – 1개월 |
| 배포주기 | 상시 | 1/1일 – 1/주 | 1/주 – 1/월 | 1/주 – 1/월 |
| 실패율 | 5% | 10% | 15% | 64% |
| 복구시간 | 1시간 미만 | 1일 미만 | 1일 – 1주 | 1 – 6개월 |
운영 안정성 강화
안정적인 운영의 중요성
빠른 배포 속도만큼이나 중요한 것은 배포된 서비스가 안정적으로 운영되는 것입니다. 잦은 장애와 긴 복구 시간은 고객의 신뢰를 잃게 하고 비즈니스에 직접적인 손실을 초래합니다. DORA의 안정성 지표는 이러한 운영의 품질과 장애 대응 능력을 측정하는 핵심 기준입니다.
- 변경 실패율(Change Failure Rate): 프로덕션 배포 후 수정이나 롤백이 필요한 비율입니다. 이 지표가 낮을수록 배포 품질이 높다는 것을 의미합니다.
- 장애 복구 시간(Mean Time to Recovery, MTTR): 서비스 중단 발생 시 복구까지 걸리는 평균 시간입니다. 이 시간이 짧을수록 장애 상황에 신속하게 대처할 수 있음을 의미합니다.
현대의 소프트웨어 개발 환경에서 이 두가지 지표와 관련한 주요 문제는 다음과 같습니다.
1. 코드 품질 검토 미흡
- 형식적인 리뷰: 시간 압박으로 인해 표면적인 검토만 이루어지는 경우가 많습니다
- 비즈니스 우선순위 검증 부족: Jira 티켓의 비즈니스 요구사항과 기술적 구현 사이의 일치성이 제대로 검증되지 않습니다
- 일관성 없는 리뷰 기준: 리뷰어마다 다른 기준으로 코드를 검토하여 품질 편차가 발생합니다
2. 가시성(Observability)과 모니터링 부족
- 불충분한 메트릭 수집: 시스템의 상태를 파악하기 위한 핵심 지표들이 누락되는 경우가 많습니다
- 알림 설정 미흡: 장애 발생 시 적절한 시점에 알림이 전달되지 않아 대응이 지연됩니다
- 모니터링 도구 활용 부족: 다양한 모니터링 도구들이 있지만 효과적으로 활용하지 못하는 경우가 많습니다
3. 복잡한 문제 해결과 장애 대응 미흡
- 장애 분석 프로세스 부재: 체계적인 장애 분석 방법론이 없어 근본 원인 파악이 어렵습니다
- 장애 보고서 작성 지연: 팀이 바쁠 때 장애 보고서 작성이 후순위로 밀려 중요한 교훈을 놓치게 됩니다
- 지식 공유 부족: 과거 장애 경험이 체계적으로 공유되지 않아 동일한 문제가 반복됩니다
생성형 AI는 위 문제를 개선하여 팀이 더 안정적으로 소프트웨어를 제공할 수 있도록 지원합니다.
예시 프로젝트 소개
실제 프로젝트 예시를 통해 각 기능을 어떻게 활용하는지 살펴보겠습니다. 예시 프로젝트는 칠리콘의 동물 퀴즈 게임입니다. 이 게임은 스무고개 형식으로 진행되며, 사용자가 질문을 하면 생성형 AI가 답변을 통해 정답을 맞추는 Spring Boot 기반의 웹 애플리케이션입니다. 웹 기반 UI를 통해 사용자와 상호작용하며, 다양한 동물들이 정답으로 등록된 퀴즈 시스템과 REST API 구조로 구성되어 있습니다.

칠리콘 동물 퀴즈 게임의 실제 화면
이제 우리는 이 칠리콘 게임을 개발하는 애니컴퍼니의 개발 팀이라고 가정하고, 운영 안정성 강화를 위해 생성형 AI를 활용하는 구체적인 방법들을 살펴보겠습니다.
변경 실패율 감소
코드 품질과 리뷰 개선
변경 실패율을 낮추는 첫걸음은 배포 전에 코드의 결함을 철저히 검토하는 것입니다. 하지만 인적 리뷰는 시간이 많이 걸리고 일관성을 유지하기 어렵습니다. 생성형 AI를 활용하면 코드의 맥락과 비즈니스 요구사항까지 이해하는 DevOps Bot을 코드 리뷰 프로세스에 참여시킬 수 있습니다.
아래는 생성형 AI를 활용하여 DevOps Bot이 코드리뷰를 진행하여 코드 품질과 프로세스를 개선하는 예시를 보여주며 이후에 이 예시를 구축한 아키텍처를 함께 살펴보겠습니다.
개발자가 기능을 수정한 뒤 GitHub에 Pull Request(PR)를 생성하면, 사전에 구축된 워크플로우가 트리거 됩니다.
PR을 작성할 때 제목만 입력하고 내용을 넣지 않고 요청합니다.
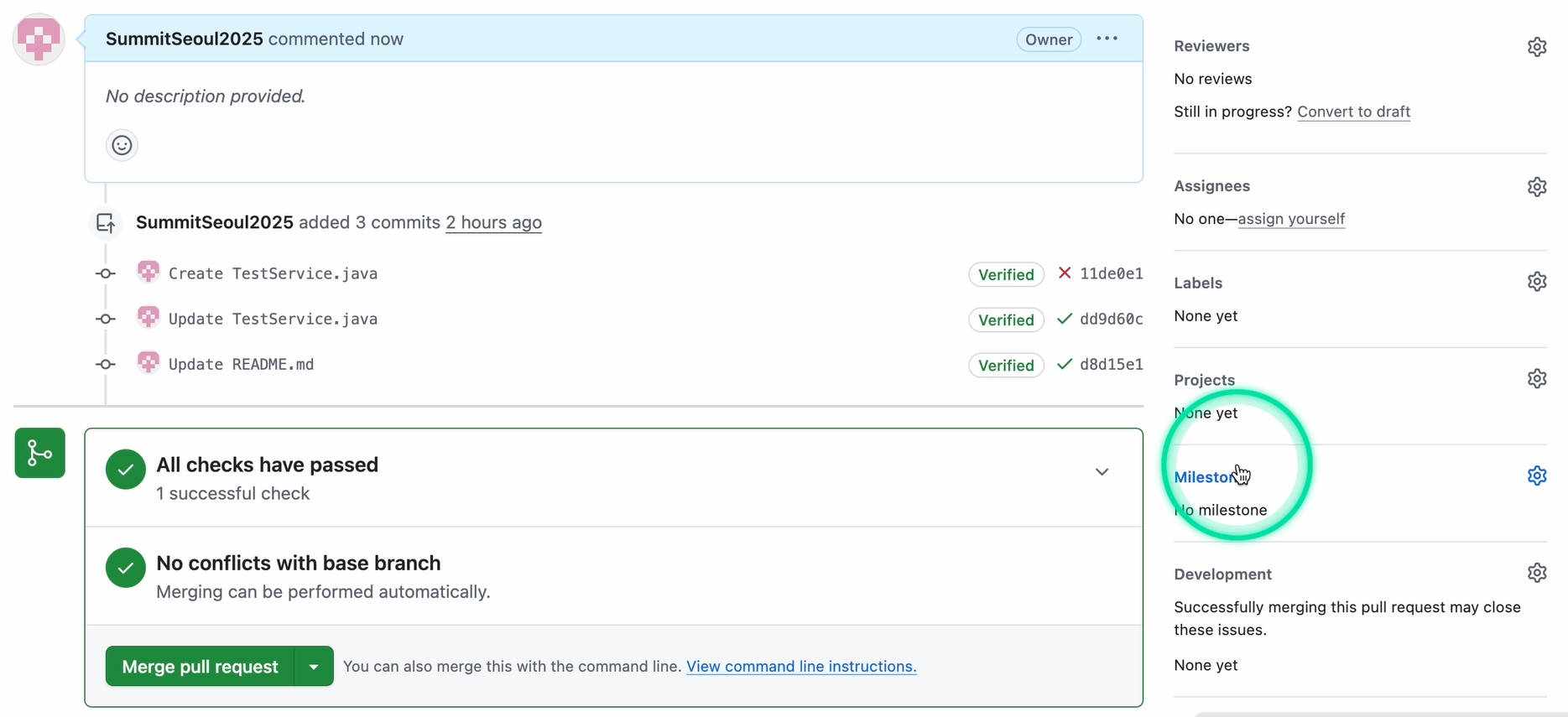
워크플로우가 실행된 후, 잠시 뒤 ‘DevOps Bot’이라는 AI 리뷰어가 PR에 자동으로 상세한 코멘트를 남깁니다. 이 코멘트는 단순한 문법 오류 지적을 넘어, 다음과 같은 깊이 있는 내용을 포함합니다.
- 주요 체크 포인트 검토

- 개선이 필요한 부분
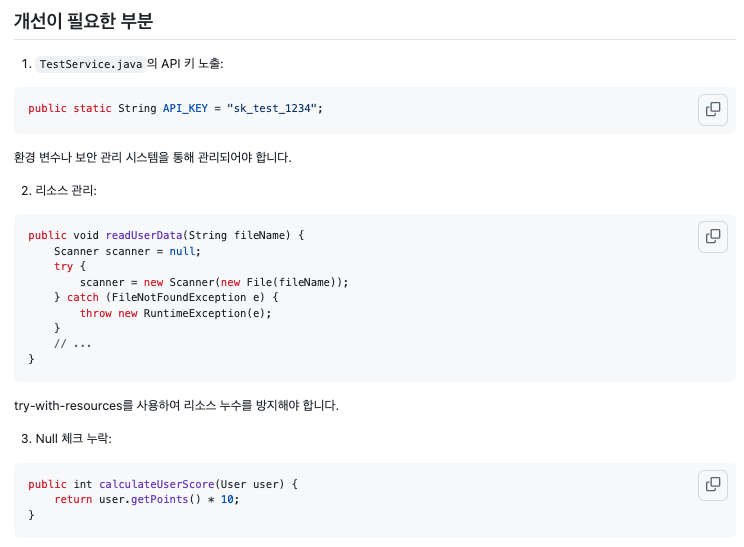
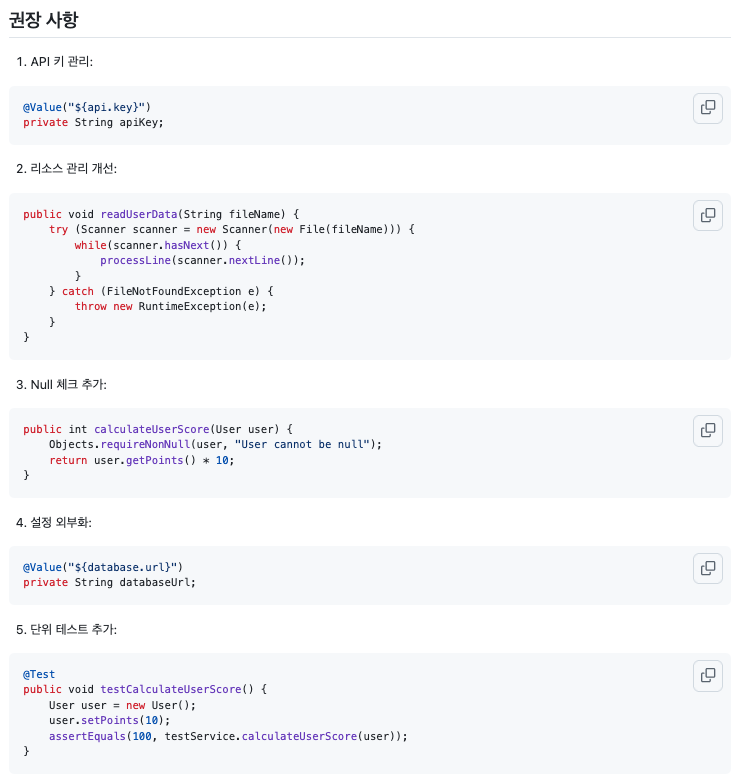
- 권장 사항
코드 리뷰 개선 아키텍처
위에서 생성형 AI를 활용하여 코드리뷰 개선한 프로세스를 AWS 아키텍처로 보면 아래와 같습니다.
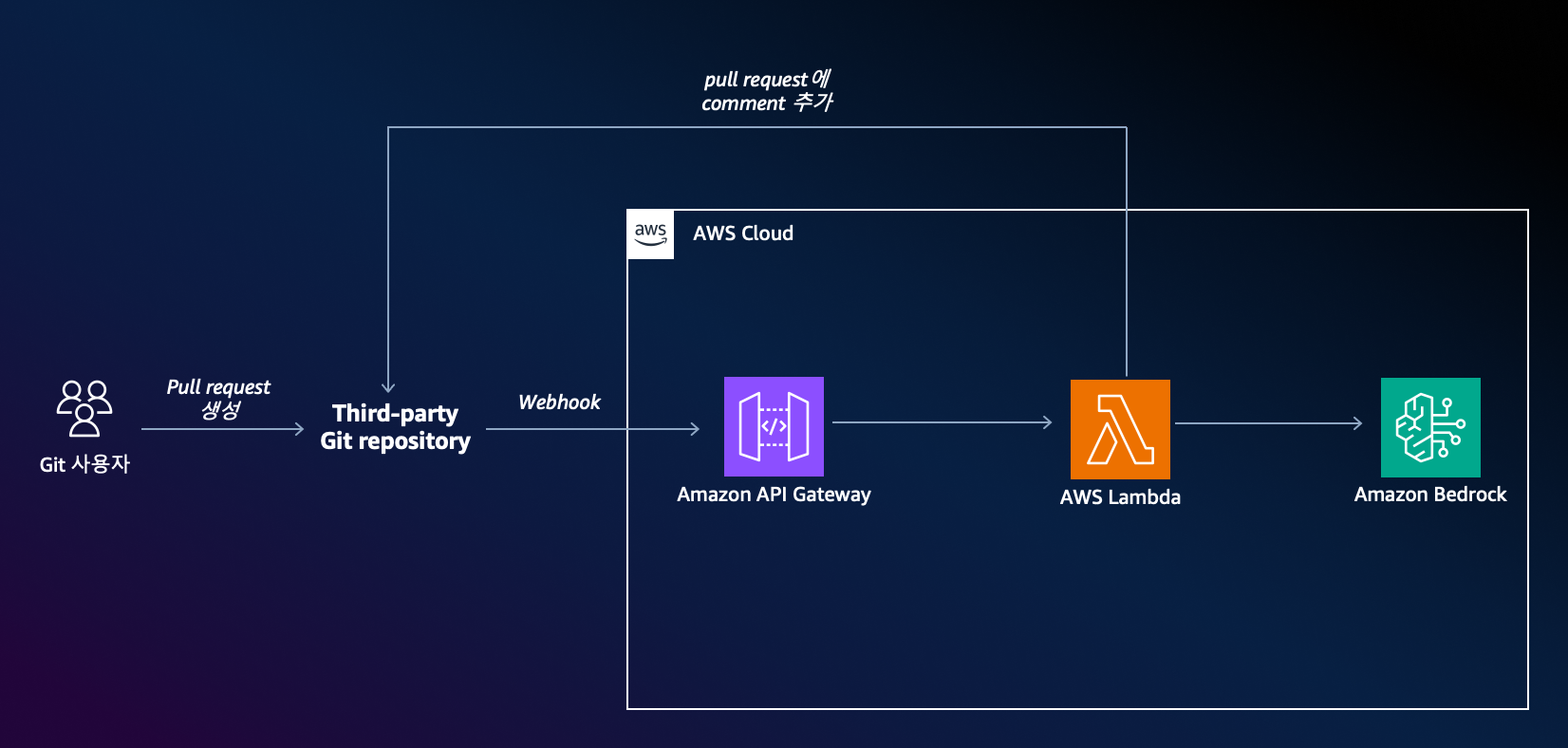
- 개발자가 Pull request(PR)을 생성하면 Git repository에서 설정된 Webhook이 실행됩니다.
- Webhook으로 호출된 API는 Amazon API Gateway를 통해 Lambda 함수를 호출합니다.
- 이 Lambda 함수는 PR의 코드 변경 내용, 커밋 메시지, 그리고 PR 설명에 포함된 Jira티켓 ID를 추출합니다.
- 그리고 이 데이터를 Amazon Bedrock에 하나의 프롬프트로 조합하여 호출하고 LLM이 리뷰를 작성합니다.
- 이 리뷰 내용을 PR의 comment로 작성하여 리뷰를 완료 합니다.
이처럼 비즈니스 맥락까지 이해하는 AI 기반의 자동화된 리뷰는 잠재적인 결함을 배포 전에 식별하여 변경 실패율을 크게 낮추고, 개발팀의 전반적인 코드 품질 표준을 상향 평준화시킵니다.
모니터링 강화
서비스 장애를 빠르게 인지하고 대응하려면 체계적인 모니터링과 경보 설정이 필수적입니다. 하지만 수많은 지표 중에서 어떤 것을, 어떤 기준으로 모니터링해야 할지 결정하는 것은 특히 클라우드 환경에서 어려운 작업일 수 있습니다.
Amazon Q Developer는 이러한 고민을 해결하는 데 도움을 줄 수 있습니다.
개발자가 서비스의 인프라를 정의하는 AWS Cloud Development Kit (CDK) 코드를 작성하고 있다고 가정해 보겠습니다.
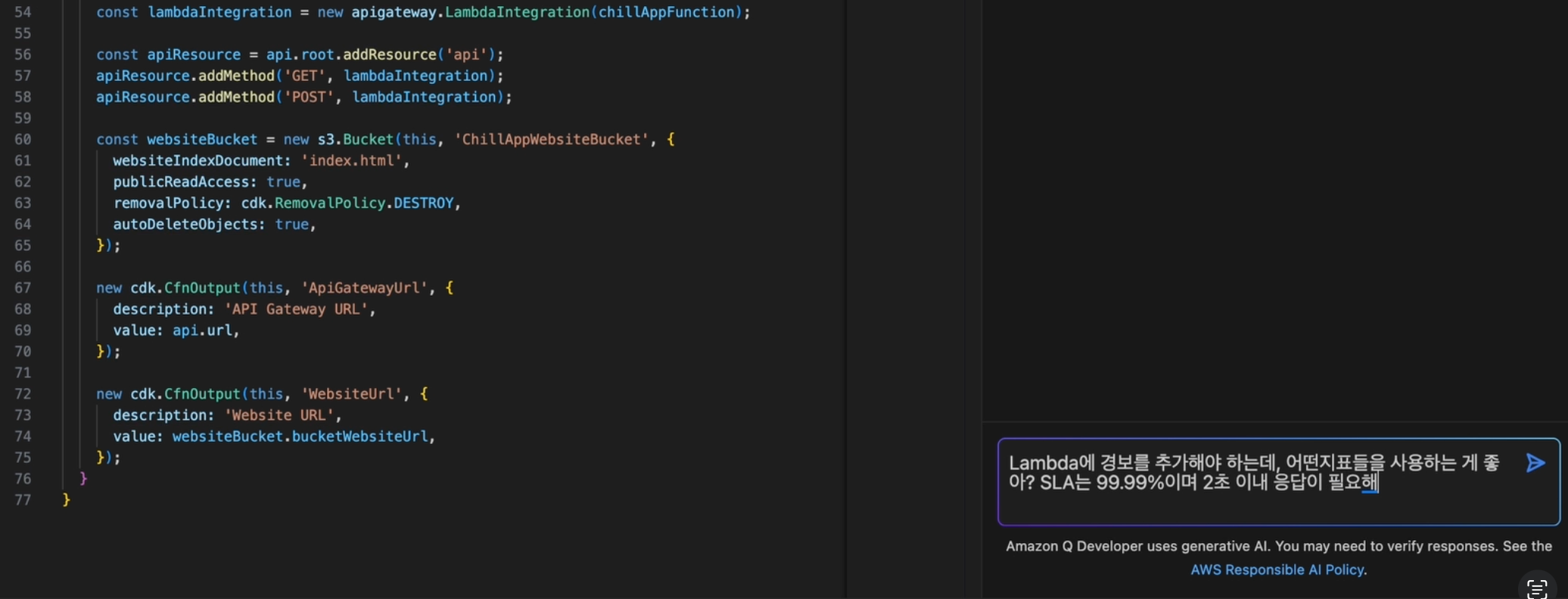
개발자는 Amazon Q Developer 채팅창에 서비스 수준 목표(SLO)와 함께 무엇을 해야 할지 질문합니다.
예시 사용자 질의 : Lambda에 경보를 추가해야하는데, 어떤 지표를 사용하는게 좋은지, SLA는 99.99%이며 2초 이내 응답이 필요합니다.
 |
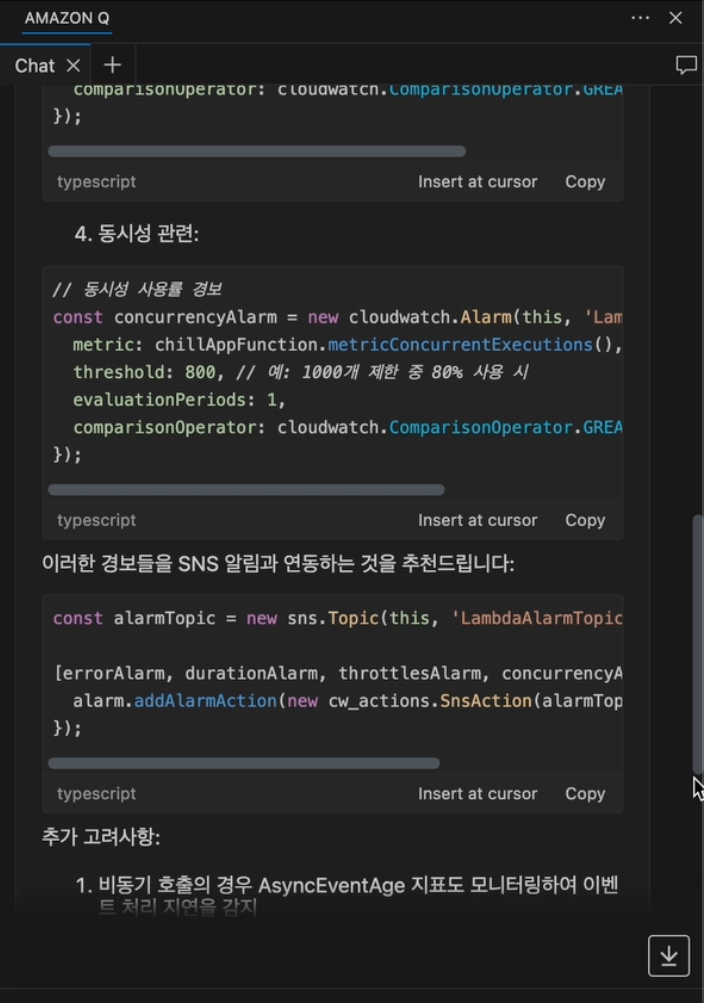 |
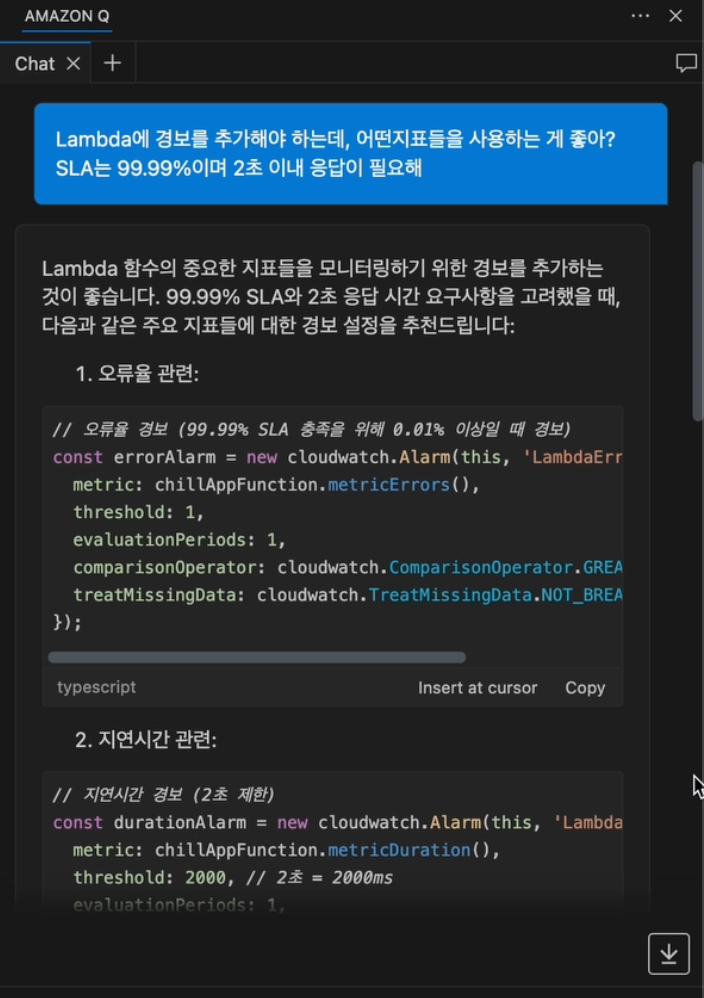
Amazon Q는 질문을 분석하여, SLA를 충족하기 위해 모니터링해야 할 핵심 지표(오류율, 지연 시간, 병목 현상, 동시성)와 그 이유를 전문가처럼 상세히 설명해 줍니다.
 |
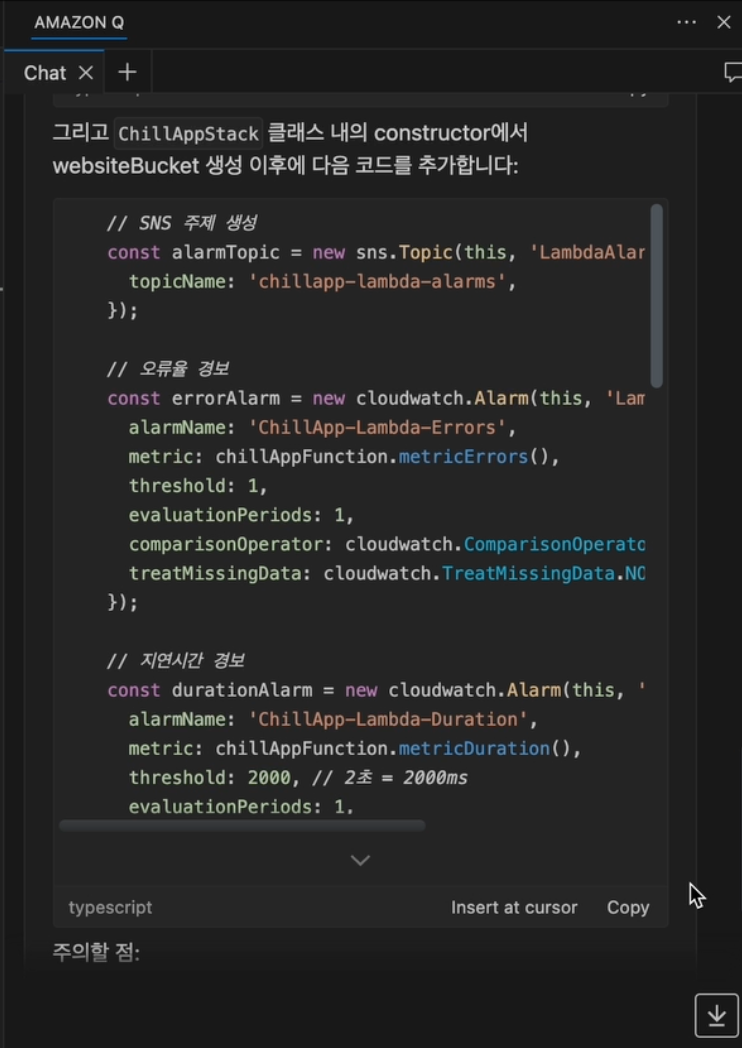 |
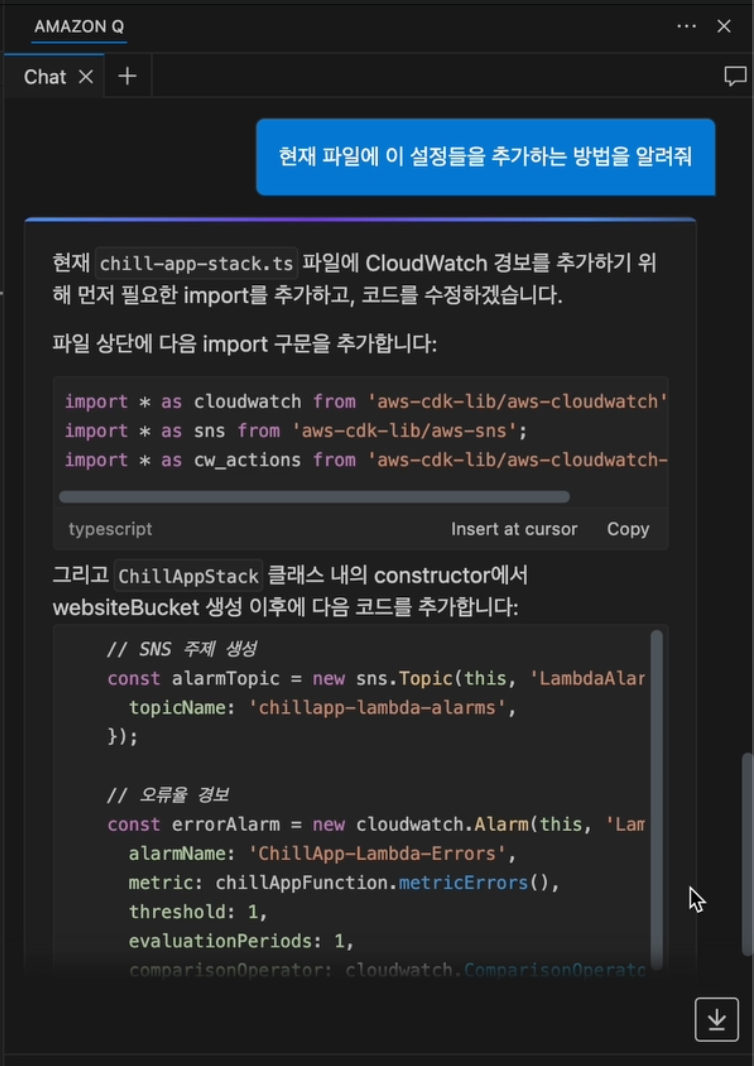
여기서 더 나아가, 개발자는 추천받은 경보를 실제 코드로 작성해달라고 요청할 수 있습니다. Amazon Q는 즉시 현재 파일(CDK)의 맥락에 맞는 코드를 생성해주고, 개발자는 ‘Insert at cursor’ 버튼 클릭 한 번으로 코드를 삽입할 수 있습니다.
이 과정을 통해 개발자는 모니터링에 대한 깊은 전문 지식이 없어도 단 몇 분 만에 전문가 수준의 모니터링 및 경보 시스템을 구축하여 장애를 사전에 예방하고 빠르게 대응할 수 있는 기반을 마련할 수 있습니다.
장애 대응 개선
아무리 잘 준비해도 장애는 발생할 수 있습니다. 중요한 것은 얼마나 빨리 복구하는가, 즉 Mean Time to Recovery(MTTR)을 줄이는 것입니다. 생성형 AI는 긴박한 장애 상황에서 담당자가 해야 할 수작업을 자동화하고 과거의 장애 내역을 활용하여 MTTR을 획기적으로 단축시킵니다.
아래는 생성형 AI를 활용하여 장애 발생시에 장애 대응 후 보고서를 자동 생성하는 예시를 보여주며 이후에 이 예시를 구축한 아키텍처를 함께 살펴보겠습니다.
장애 보고서 자동 생성
장애 대응 후 보고서를 작성하는 것은 재발 방지를 위해 매우 중요하지만, 가장 번거롭고 누락되기 쉬운 업무입니다.
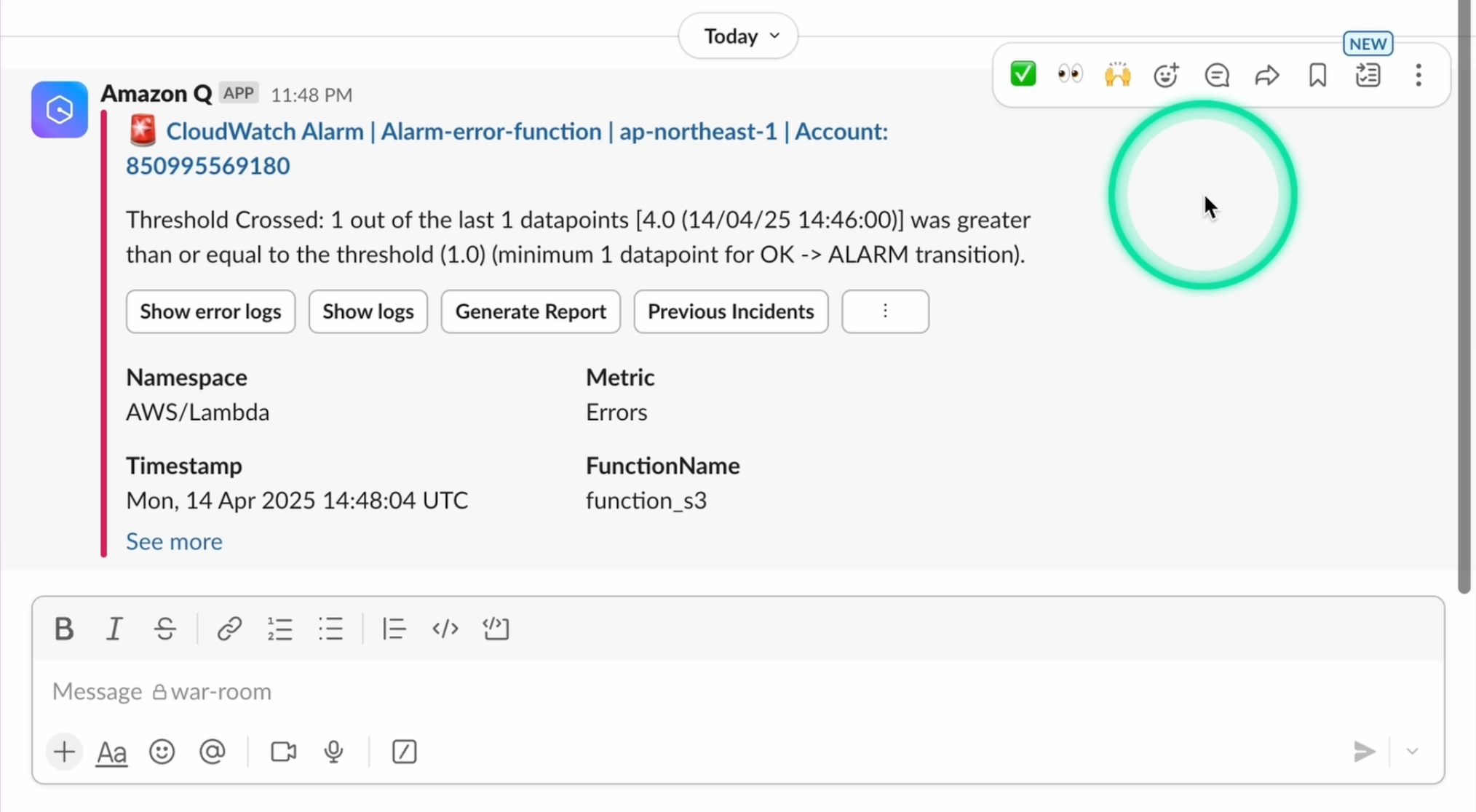
Amazon CloudWatch 경보를 Amazon Q Developer을 통해 슬랙등 메신저로 전송 할 수 있습니다. 이 예시에서도 장애가 발생하여 슬랙 채널에 Amazon CloudWatch 경보가 발생 되었습니다.
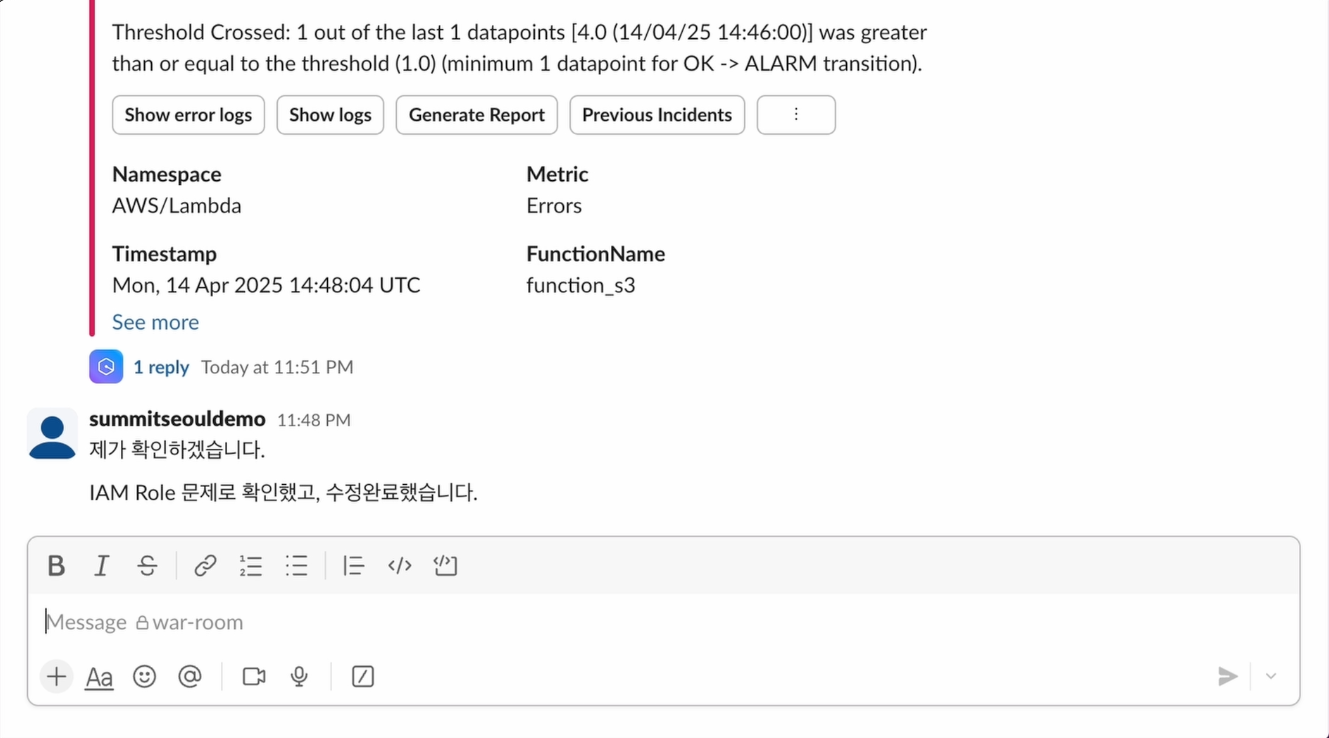
담당자는 원인을 분석했고, 조치를 취하여 장애를 해결합니다.
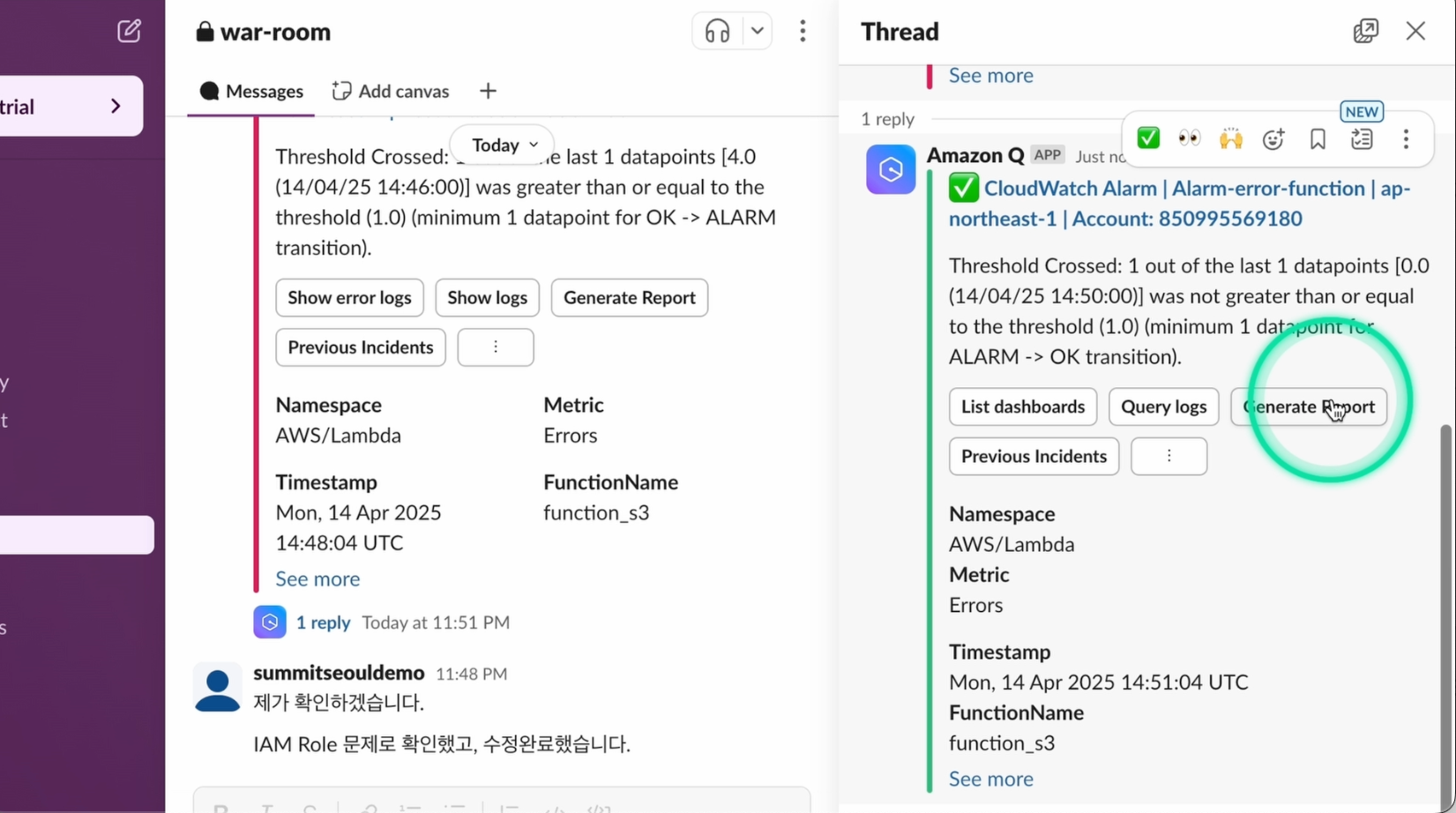
정상적으로 복구되고 CloudWatch에서 정상 알림을 공유하고, 담당자는 Generate Report(장애 보고서 생성) 버튼을 클릭합니다.
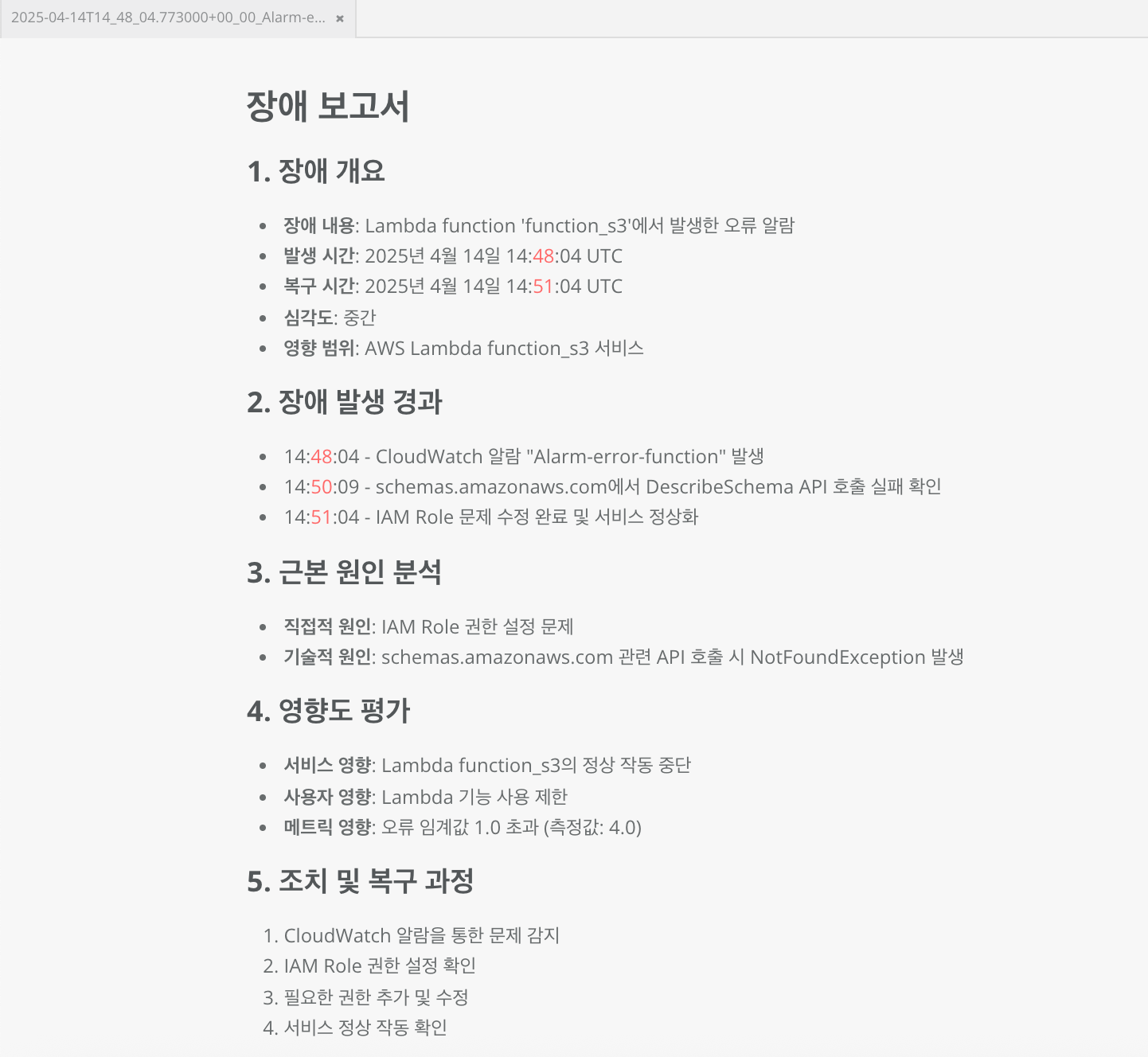
이미지와 같이 장애보고서가 생성되고 Slack 채널에서 공유 됩니다.
장애보고서 자동 생성 아키텍처
위에서 생성형 AI를 활용한 장애보고서 자동생성 워크플로우를 AWS 아키텍처로 보면 아래와 같습니다.
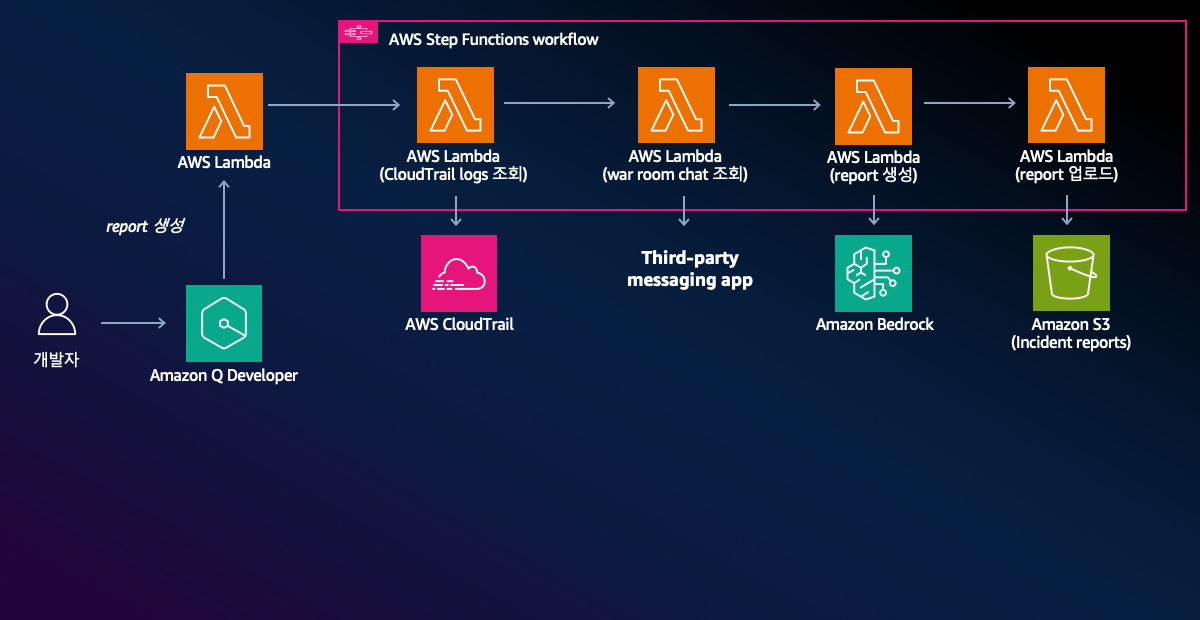
- Slack에서 ‘보고서 생성’이 트리거되면, AWS Step Functions의 워크플로는 장애 기간 동안의 AWS CloudTrail 로그와 Slack 대화 기록을 병렬로 수집합니다.
- 수집된 모든 텍스트 데이터를 Amazon Bedrock에 전달되어 ‘장애 관리 전문가’의 역할로 보고서를 작성합니다.
- 결과를 S3에 저장합니다.
동적 장애 처리 가이드 자동 생성
여기서 한 걸음 더 나아가, 축적된 장애 보고서를 기반으로 AI가 다음 장애 대응을 돕도록 만들 수 있습니다.
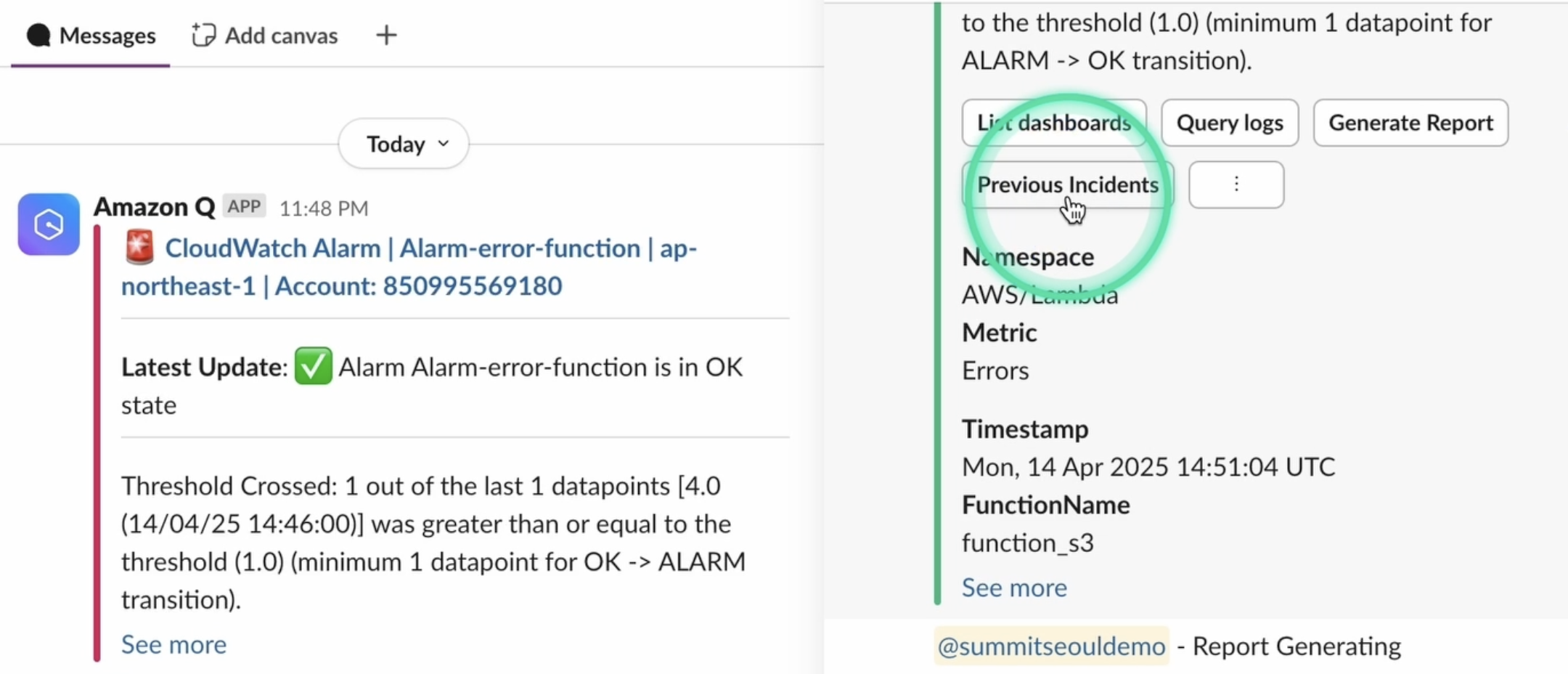
비슷한 유형의 장애가 다시 발생하였습니다. ‘Previous Incidents(이전 장애 대응 가이드)’ 버튼을 클릭합니다.
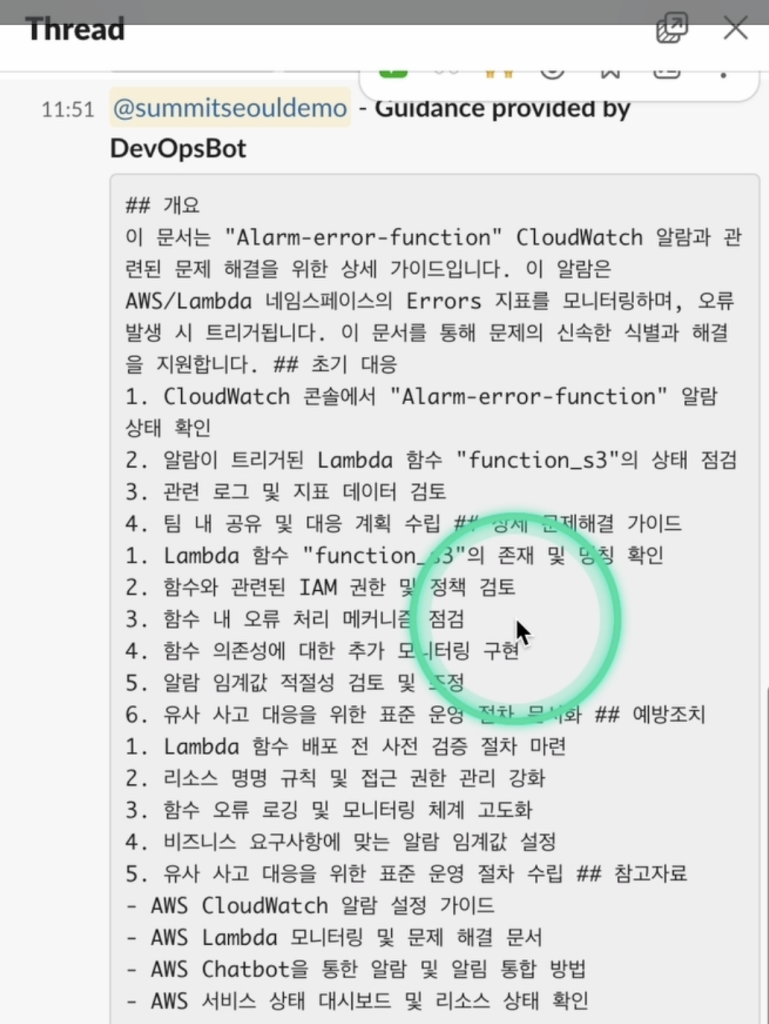
생성형 AI를 통해서 과거의 가장 유사한 상애 보고서를 기반으로, 현재 상황에 맞는 단계별 해결 가이드를 생성하여 Slack에 공유합니다.
동적 장애 처리 가이드 자동 생성 아키텍처
장애 처리 가이드 자동 생성 아키텍처를 살펴보겠습니다.
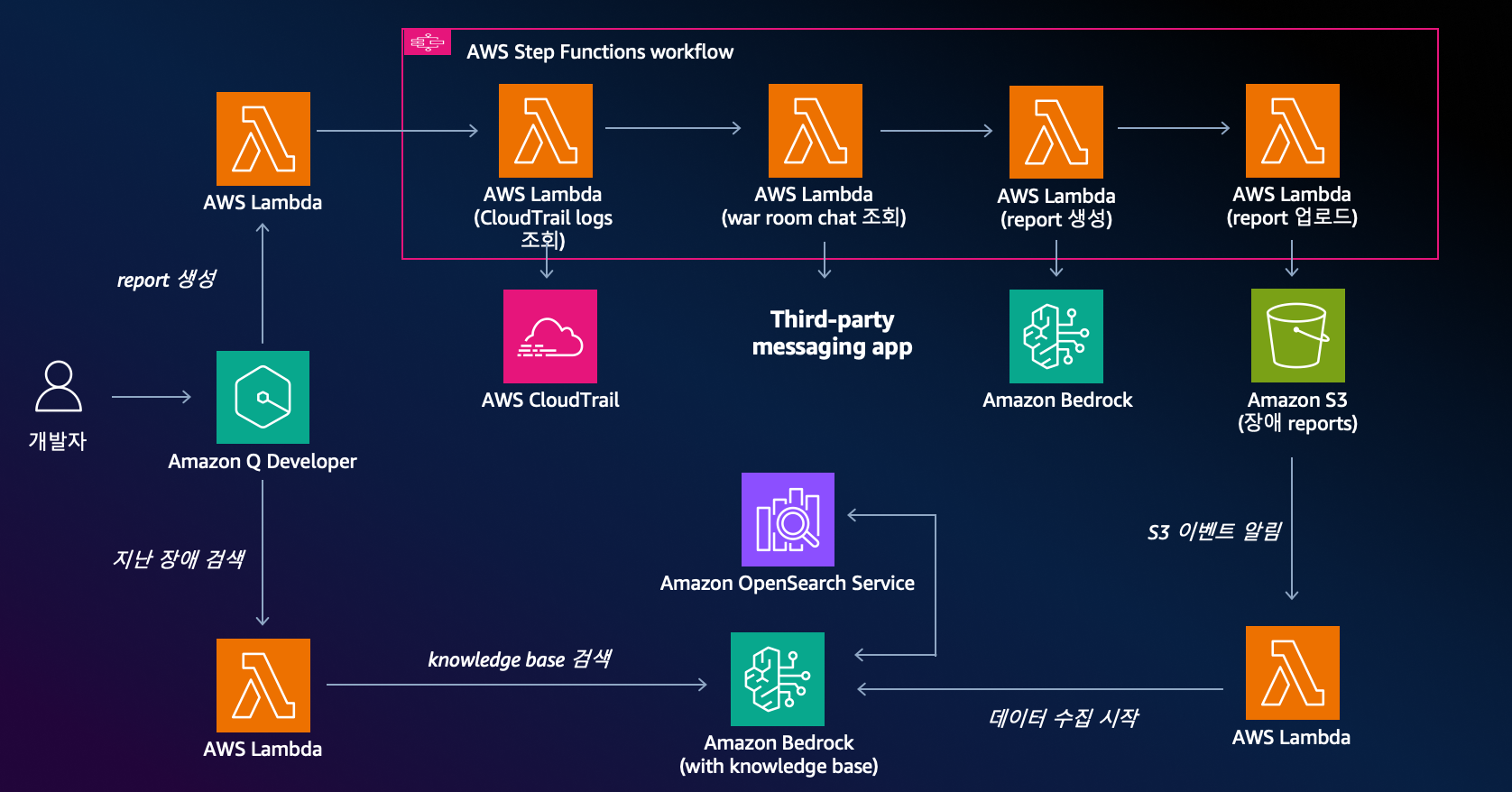
- 이 기능은 RAG(Retrieval-Augmented Generation) 패턴을 활용합니다.
- 장애 보고서가 S3에 저장될 때마다, Lambda가 이를 트리거하여 보고서 내용을 벡터(Vector)로 변환하여 Amazon OpenSearch Service에 저장합니다.
- 새로운 장애 발생 시, 현재 장애 정보를 기반으로 OpenSearch에서 가장 유사한 과거 사례를 검색(Retrieval)하고, 이 정보를 Bedrock에 함께 전달하여 더 정확하고 상황에 맞는 가이드를 생성합니다.
이 동적 가이드 작성은 팀의 장애 대응을 자산화하고, 담당자의 숙련도와 상관없이빠르고 정확하게 장애를 해결할 수 있도록 지원하여 MTTR을 획기적으로 단축시키는 강력한 무기가 됩니다.
결론
생성형 AI는 코드 리뷰를 지능화하여 코드 품질을 개선하고, 모니터링 설정을 고도화하며, 장애 대응 프로세스를 자동화함으로써 운영 안정성을 강화하는 세가지 핵심영역에서 살펴보았습니다.
DORA에서 정의한 처리량, 운영안정성 지표 개선을 위해 Part 1에서 다룬 ‘소프트웨어 딜리버리 가속화’와 이번 Part 2의 ‘운영 안정성 강화’에서 다뤘습니다. 생성형 AI는 데브옵스의 두 축인 속도와 안정성을 모두 향상시키는 핵심적인 역할을 합니다. 개발자는 반복적인 작업에서 해방되어 더 창의적이고 본질적인 문제 해결에 집중할 수 있으며, 조직은 더 빠르면서도 신뢰성 높은 서비스를 고객에게 제공할 수 있게 됩니다.
이 포스트는 2025 AWS Summit Seoul에서 세션으로 진행 되어 유튜브에서 다시 보실 수 있고 GitHub에서 오픈 소스 코드로도 확인하시고 적용 해보실 수 있습니다.
이제 여러분의 데브옵스 여정에 생성형 AI를 통합하여 차세대 운영 환경을 구축해 보시기 바랍니다.