AWS 기술 블로그
삼성전자 SmartThings, OpenSearch 도입으로 성능향상과 비용절감 달성기
시작하며,
이 글에서는 SmartThings 기록 시스템의 DB 교체 여정에 대해 소개합니다. 기존 HBase는 다양한 서비스의 요구를 충족하지 못해 SPOF 및 확장성 부족 등의 문제가 있었습니다. 이를 해결하기 위해 다양한 DB 솔루션을 검토한 후 OpenSearch를 도입해 기록 시스템의 안정성과 성능을 개선했습니다. SmartThings는 앞으로도 각 마이크로서비스의 요구에 맞는 최적의 DB 솔루션을 도입할 계획입니다.
SmartThings Data Platform이란?
그림 1. Data Platform을 활용하는 대표적인 기록/통계 서비스
기록 시스템의 역할
기록 시스템은 Data Platform의 일부로, 다양한 기기에서 발생한 이벤트, 자동화 실행 기록, 알림, 이력 정보 등을 저장하고 서비스하는 기능을 담당합니다. 이러한 정보는 SmartThings 앱을 통해 조회할 수 있습니다.
기존 DB의 개선 필요성
기존 DB를 개선해야 할 필요성에 대해서는 이전 블로그 게시글인 ‘SmartThings 통계 DB 교체 여정 ‘데이터 혁신의 어드벤처’ 에서 이미 설명한 바 있습니다. 이를 기록 시스템에 맞춰 간략하게 요약하면 다음과 같습니다.
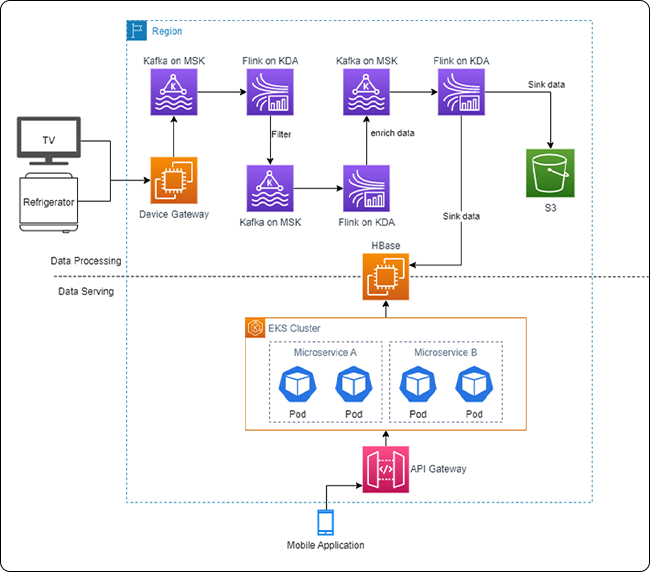
그림 2. 기존 Data Platform 구조
위 그림을 보면 하나의 (Self-Managed) HBase를 여러 서비스에서 다양한 용도로 사용하고 있음을 알 수 있습니다. HBase는 AWS EC2 인스턴스에 직접 HBase 관련 컴포넌트를 설치해 운영하며, Terraform, Ansible, Spinnaker 등을 통해 자동화됩니다.
기존 DB를 개선해야 할 필요성에 대해서는 이전 블로그에서 이미 설명한 바 있습니다. 이를 기록 시스템에 맞춰 간략하게 요약하면 다음과 같습니다.
- 여러 서비스가 하나의 데이터베이스를 공유함에 따라 마이크로서비스의 장점이 제대로 발휘되지 못했습니다. 이로 인해 HBase가 단일 장애 지점(Single Point of Failure, SPOF)이 되는 상황이 빈번하게 발생했습니다.
- 각 서비스마다 기능이 달라 이에 따른 쿼리 패턴도 다양했으며, HBase의 제약으로 인해 기능 구현이 지연되기도 했습니다. 따라서 각 기능별로 적절한 DB가 필요한 상황이었습니다.
- 사실상 HBase는 확장성이 부족하고 낭비되는 비용이 많이 발생했습니다.
이러한 문제를 해결하기 위해 각 기능(서비스)에 맞는 적절한 데이터베이스로 교체하려는 노력이 필요했습니다. 이번 블로그 포스팅에서는 그 중 기록 시스템에 초점을 맞추어 설명하려 합니다.
DB 솔루션 검토
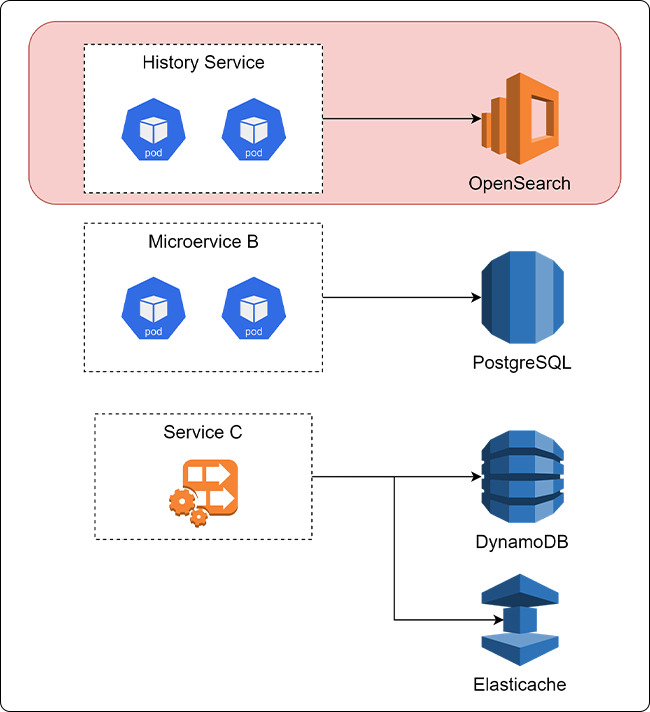
그림 3. 변경 후 Data Platform 구조
DB 솔루션을 선택하는 데는 서비스의 요구사항이 가장 중요한 요인입니다. 기록 시스템의 요구사항을 정의하면 다음과 같습니다.
- 기록(History)은 앱에서 다양한 형태로 표시되므로 다양한 필터 지원이 필요합니다. 이는 DB 관점에서 검색에 사용되는 키가 매우 다양하다는 것을 의미합니다.
- ST World에서 발생하는 대부분의 이벤트를 저장해야 하므로 쓰기 작업의 양이 매우 많습니다.
- 기록의 TTL은 7일입니다.
- 기록 유형이 다양하므로 스키마리스(schemaless) 구조로 설계해야 하며, 필요시 어떠한 필드라도 검색에 활용할 수 있어야 합니다.
후보 솔루션
DynamoDB가 처음 고려되었으나 1번 요구사항을 충족하지 못해 제외되었습니다. 검색 조건이 추가될 때마다 GSI를 추가해야 하는 구조로 인해 비용이 기존보다 증가할 것으로 예상되었기 때문입니다. 또한 Flink → DynamoDB 간 테스트 결과 성능이 기대에 미치지 못했습니다.
RDB의 경우 쓰기 작업이 많은 구조에 적합하지 않고, DB 자체에서 TTL을 지원하지 않기 때문에 선택에서 제외되었습니다. 그 외에 AWS Keyspace(Cassandra) 등도 유사한 이유로 검토 대상에서 제외되었습니다.
OpenSearch를 선택한 이유
OpenSearch도 분명 제약이 있지만, 위 요구사항을 충족할 수 있는 DB 솔루션이라는 점에서 선택하게 되었습니다. 또한 PoC를 진행하여 요구사항 충족 여부를 다방면으로 검토했습니다. 자세한 내용은 지면 관계상 생략하겠습니다.
AWS OpenSearch 구성
AWS OpenSearch는 오픈 소스 기반의 OpenSearch를 활용한 AWS 관리형 솔루션입니다. 검색에 최적화되어 있어 필드를 자유롭게 정의할 수 있으며 어떤 필드로 검색하더라도 일관된 성능을 보장합니다.
이제 기록 시스템의 요구사항을 충족하기 위해 OpenSearch를 어떻게 구성했는지 살펴보겠습니다.
클러스터 구성
사전에 읽기/쓰기 수와 데이터 양을 파악하여 이러한 데이터를 바탕으로 클러스터를 구성했습니다. 읽기/쓰기에 직접적인 영향을 미치는 데이터 노드를 결정할 때는 정해진 공식을 따릅니다. 예를 들어, 하나의 데이터 노드가 처리할 수 있는 읽기 요청 수는 다음과 같습니다.
![]()
이 수치를 바탕으로 마스터 노드와 데이터 노드의 사양을 결정했습니다. 또한 OpenSearch는 Hot, Ultra Warm, Cold 등 세 가지 스토리지 방식을 지원하는데, 기록 서비스의 경우 저장된 데이터가 자주 검색되므로 Hot Storage 방식을 채택했습니다.
데이터 노드 수
그림 4. 데이터 노드 불균형 현상
초기에는 3개의 AZ(Availability Zone)에 4개의 데이터 노드를 구성했습니다. 이때 데이터가 균등하게 분배되지 않는 불균형(Skew) 현상이 발생했습니다. 1개의 AZ에는 2개의 노드가 배치되고, 나머지 2개의 AZ에는 각각 1개의 노드만 배치된 상황이었습니다.
- AZ #1: 데이터 노드 2개 – 다른 노드에 비해 상대적으로 많은 양의 데이터 보유
- AZ #2: 데이터 노드 1개 – 적은 양의 데이터
- AZ #3: 데이터 노드 1개 – 적은 양의 데이터
OpenSearch는 내부적으로 AZ에 데이터를 고르게 분배하려 하지만, 노드 수가 불일치할 경우 한 개의 AZ에만 데이터가 집중될 수 있습니다. 이 문제는 AZ의 배수로 데이터 노드 수를 변경한 뒤 해소되었습니다. 데이터 노드 스케일링 시 주의해야 할 부분입니다.
Shard 크기
OpenSearch 가이드에 따르면, Shard 1개당 권장 크기는 10GB ~ 50GB입니다. 처음에는 이 권장사항을 충분히 고려하지 않고 Shard 1개의 크기를 10GB 이하로 설정했습니다. 그러나 이 설정으로 인해 API 지연 시간이 예상보다 높게 나타났습니다. 성능 개선 작업을 진행하면서 Shard 1개의 크기를 10GB~20GB로 조정했고, 아래와 같이 성능이 약 50% 향상되었습니다.
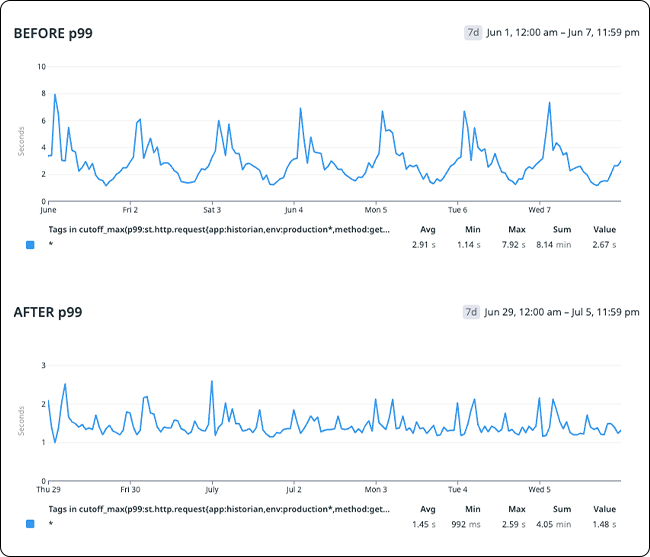
그림 5. Shard 크기에 따른 OpenSearch 성능
TTL
OpenSearch는 TTL을 인덱스 단위로만 지원하며, 레코드 단위로 TTL을 설정할 수 없습니다. 따라서 일반적으로 롤링 인덱스(rolling index) 방식의 구성을 사용합니다. 저희는 이벤트 시간을 기준으로 롤링 인덱스를 활용하여 7일간의 데이터만 저장한다는 요구사항을 충족하고자 했습니다.
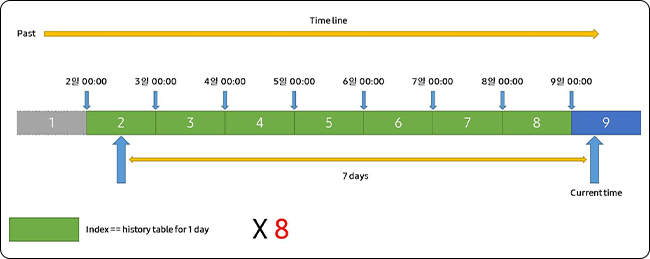
그림 6. TTL 구현 방안
7일 동안의 기록을 저장하기 위해 인덱스에 8일간의 TTL을 설정하고, 검색 시에는 7일치 데이터만 가져오는 방식으로 구성했습니다.
인덱스 템플릿
모든 인덱스는 생성될 때 정해진 템플릿을 따릅니다. 여기에는 앞서 언급한 갱신 간격(refresh interval)이나 검색 가능한 필드(searchable field) 정의 등이 포함됩니다.
인덱스 템플릿은 기능 요구사항, 성능 개선, 구조 개선 등 다양한 이유로 수정이 필요할 수 있습니다. 이러한 작업에 소요되는 리소스를 줄이기 위해 아래와 같이 간단한 파이프라인을 구성하여 사용하고 있습니다. 템플릿은 GitHub에 저장해 두고, 필요시 Jenkins를 통해 수동 트리거(manual trigger) 방식으로 관리합니다.

그림 7. 인덱스 템플릿 관리 방안
OpenSearch 대시보드
OpenSearch는 Kibana 기반의 대시보드를 제공합니다. 이를 통해 검색을 수행하고 다양한 분석용 그래프를 구성할 수 있습니다. 또한 ISM, 템플릿 등도 UI를 통해 관리할 수 있습니다.

그림 8. OpenSearch 대시보드
이 대시보드는 매우 유용한 도구지만, 관리 및 운영에는 추가적인 작업이 필요합니다. 특히 접근 제어나 권한 관리가 중요한 부분입니다.
OpenSearch 대시보드는 OIDC와 SAML 연동을 지원합니다. 저희는 Keycloak을 사용하여 대시보드 계정과 권한을 Keycloak 계정 기반으로 관리하고 있습니다. 또한 사내 정책에 따라 사내 IP 대역으로만 접근을 제한하고 있습니다.
DB 교체 결과
주요 목표는 기존 시스템의 제약을 극복하고 비용 효율성을 높이는 것이었지만, 성능과 비용이라는 중요한 비기능적 요구사항을 무시할 수는 없었습니다. 기록 시스템은 CQRS 패턴을 적용하여 구성되었으므로, 읽기/쓰기 성능 및 비용에 대해 각각 살펴보겠습니다. 자세한 내용은 지면 관계상 생략하겠습니다.
- 읽기: 기존 대비 약 19% 성능 향상 (API 지연 시간 – p99 기준)
- 쓰기: 기존 대비 약 38% 비용 절감
마치며
SmartThings의 다양한 마이크로서비스는 각각의 요구에 맞게 서로 다른 데이터베이스를 사용하고 있습니다. 요구를 충족하는 최적의 솔루션이 있다면 기존에 사용하지 않았던 시스템이라도 도입을 검토하고 있습니다. 이번 블로그 포스팅에서 소개한 OpenSearch가 그 좋은 예이며, 효율적인 구조를 구현하기 위한 이러한 노력은 앞으로도 계속될 것입니다.