AWS 기술 블로그
Amazon Bedrock을 활용한 (주)레듀텍의 독서 교육 콘텐츠 생성 자동화 시스템 구축

에듀테크 산업에서 양질의 교육 콘텐츠를 지속적으로 생산하는 것은 중요한 과제입니다. 특히 독서 교육 분야에서는 다양한 도서에 대한 맞춤형 문제와 활동을 개발하는 데 상당한 시간과 인력이 소요됩니다.
(주)레듀텍(Redutec, Inc.)은 한글을 읽을 수 있는 유아부터 중등 학생을 대상으로 독서교육 서비스 리딩오션을 제공하는 에듀테크 기업입니다. 본 글에서는 레듀텍이 Amazon Bedrock을 활용하여 독서 교육 콘텐츠 생성 과정을 자동화하고 운영 효율성을 크게 향상시킨 사례를 소개합니다.
회사 및 서비스 소개
리딩오션은 체계적인 독서 교육을 위한 종합 플랫폼으로, 다음과 같은 핵심 기능을 제공합니다:
- 독서능력진단: 학생별 독서 능력 수준 평가 및 맞춤형 학습 경로 제시
- 전자책 라이브러리: 2,060권 이상의 검증된 도서를 전자책으로 제공 (2025년 6월 기준)
- 독후 활동: 독서 문항 풀이, 글쓰기, 게임 등 다양한 학습 활동
- 교사 지원 시스템: 학생 관리, 활동 이력 추적, 교육 자료 제공
리딩오션에서 제공하는 독후활동 콘텐츠는 다음과 같은 다양한 형태로 구성되어 있습니다:
낱말 퍼즐 – 제공되는 화면 예시
매칭 게임 – 제공되는 화면 예시
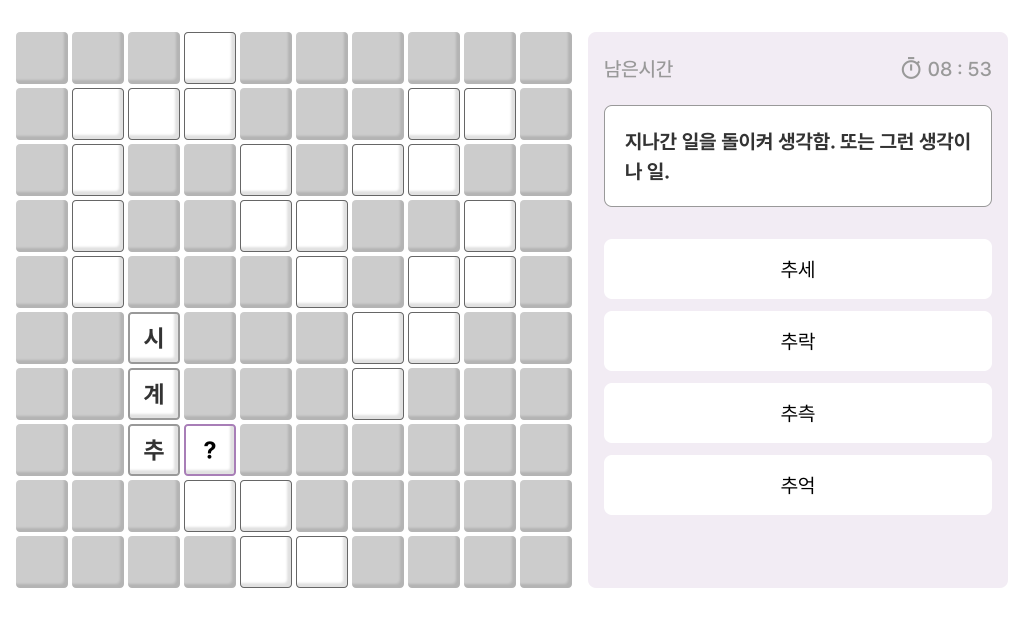
OX 퀴즈 – 제공되는 화면 예시
객관식 퀴즈 – 제공되는 화면 예시
주관식 퀴즈 – 제공되는 화면 예시
기존 독서 교육 콘텐츠 개발 과정의 한계점
레듀텍은 2,060권의 실물 도서를 전자책으로 제공하며, 각 도서별로 다양한 독후활동 콘텐츠를 지속적으로 개발·추가하고 있습니다. 독서문항 콘텐츠는 낱말퍼즐, 매칭게임(순서맞추기), OX, 주관식, 객관식 퀴즈 등으로 구성되어 있으며, 학생의 독해력과 사고력을 평가할 수 있도록 설계됩니다.
하지만 이러한 다양한 독서 콘텐츠를 제공하기 위해서는 다음과 같은 어려움이 있었습니다:
문제점 1: 높은 콘텐츠 개발 비용
독서 문항 개발은 교육적 효과를 보장하기 위해 사내 콘텐츠팀에서 직접 도서를 읽고 문제를 개발하는 방식으로 진행됩니다. 이 과정에서 도서 1권당 1~3 man-day의 작업 시간이 소요되며, 특히 분량이 많고 난이도가 높은 도서일수록 더 많은 시간이 필요합니다.
문제점 2: 콘텐츠 다양성 확보의 어려움
단일 팀에서 모든 독서 문항을 개발하다 보니 콘텐츠 유형이 고착화되고 내용이 유사해지는 경향이 나타났습니다. 이로 인해 학생들에게 제공되는 학습 경험의 다양성이 제한되는 문제가 발생했습니다.
Amazon Bedrock을 활용한 해결 방안
레듀텍은 이러한 문제를 해결하기 위해 Amazon Bedrock의 대규모 언어모델(LLM)을 활용한 유형별 독서문항 초안 자동 생성 기능(독서문항생성AI)을 개발하였습니다.
이 시스템을 통해 콘텐츠 개발자는 다음과 같은 프로세스로 작업할 수 있습니다:
- 도서 PDF를 업로드
- 생성할 문항 유형과 수를 입력
- 프롬프트 기반으로 콘텐츠 초안을 생성하여 Excel 파일로 제공
- 개발자가 결과물을 검토·수정하여 최종 콘텐츠로 활용
이를 통해 독서문항 개발에 소요되는 시간을 단축하고, 콘텐츠의 다양성을 확보하고자 하였습니다.
독서문항생성 시스템 아키텍처
독서 문항 생성 시스템은 리딩오션 관리자 페이지를 통해 접근할 수 있으며, 다음과 같은 AWS 서비스들로 구성됩니다:
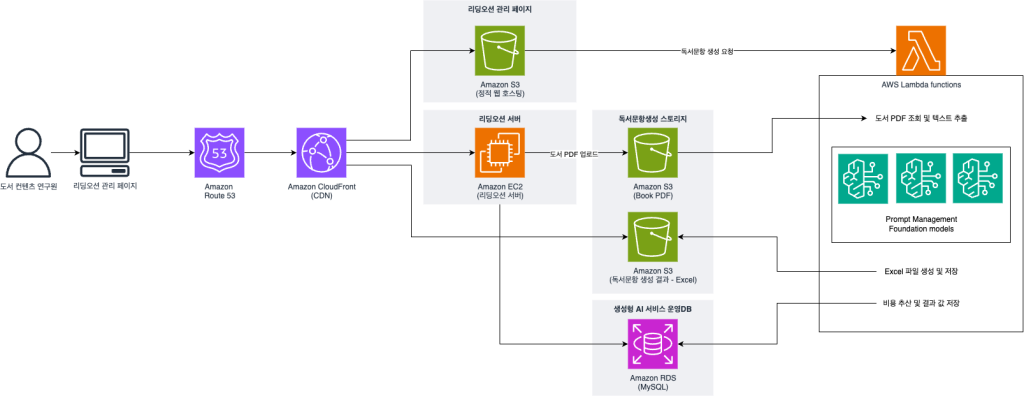
시스템 구조 – 독서문항생성
웹 인프라 구성
관리자 페이지는 다음과 같은 AWS 서비스로 구성되어 있습니다:
- Amazon Route 53: DNS 라우팅 및 도메인 관리를 담당합니다. 지연 시간 기반 라우팅, 지리적 라우팅, 가중치 기반 라우팅 등 다양한 라우팅 정책을 지원하여 트래픽을 효율적으로 분산시킵니다.
- Amazon CloudFront: 글로벌 콘텐츠 전송 네트워크(CDN) 서비스로, 전 세계 사용자에게 낮은 지연 시간과 높은 전송 속도로 콘텐츠를 제공합니다. 원본 서버의 부하를 줄이고 사용자 경험을 개선하는 역할을 합니다.
- Amazon S3 Static Web Hosting: 정적 웹사이트 호스팅 기능을 통해 HTML, CSS, JavaScript 파일들을 간단하고 비용 효율적으로 호스팅합니다. 99.999999999%(11 9’s)의 내구성을 제공하여 데이터 손실 위험을 최소화합니다.
- Amazon EC2: 실제 애플리케이션 서버가 운영되는 환경으로, 동적 콘텐츠 처리와 비즈니스 로직을 담당합니다.
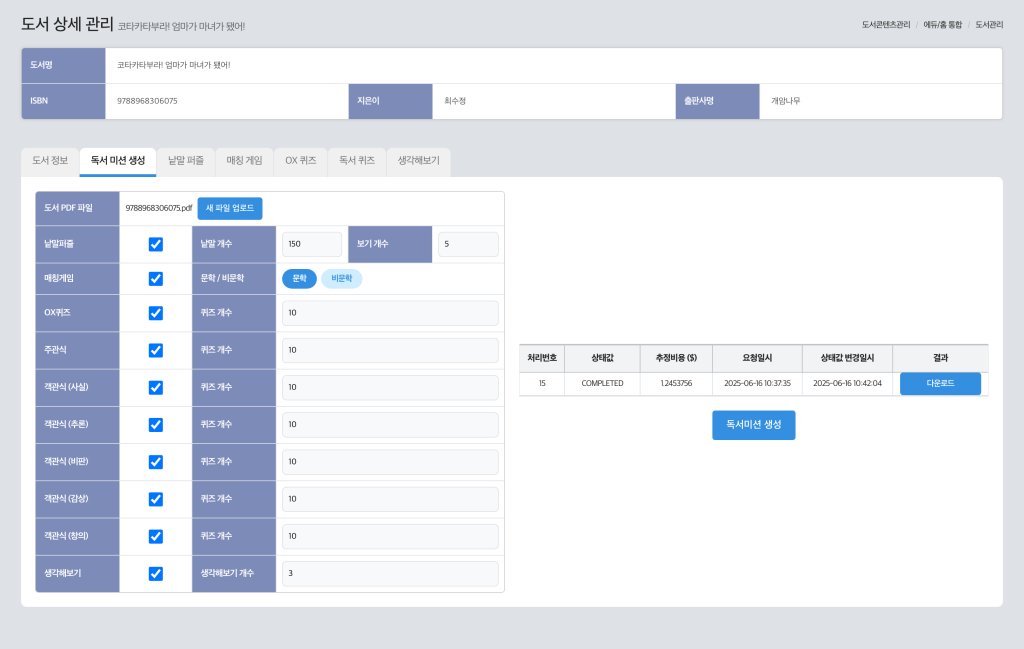
리딩오션 관리자 페이지 – 독서문항생성
사용자 워크플로우
콘텐츠 개발자는 관리자 페이지에서 다음과 같은 과정을 통해 독서문항을 생성할 수 있습니다:
- 독서문항 초안을 생성하고자 하는 도서의 PDF를 Amazon S3에 업로드
- 생성하고자 하는 독서문항의 유형, 문항의 수, 도서의 유형을 입력
- 독서문항생성 기능 실행
- Amazon RDS의 요청 상태를 폴링하여 처리 진행 상황을 실시간으로 확인
- 완료 후 Amazon S3에서 결과물을 다운로드
이와 같은 형태의 기능을 제공하여 콘텐츠 개발자들이 기존의 업무 프로세스를 크게 변경하지 않으면서도 실질적인 도움을 받아 업무를 효율적으로 진행할 수 있도록 돕습니다.
생성 결과물 예시
다음은 시스템에서 생성된 Excel 파일의 예시입니다:
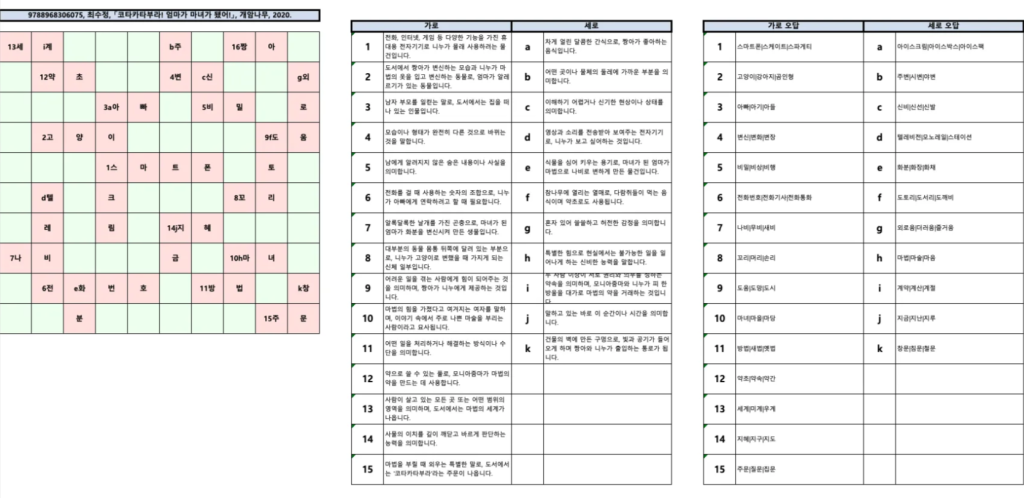
생성된 낱말퍼즐 – 결과물 예시

생성된 객관식 – 결과물 예시
독서문항생성 기능 구현 상세
전체 프로세스 개요

독서 문항 생성 기능은 AWS Lambda function에서 실행되며, 다음과 같은 단계로 진행됩니다:
- 요청 초기화: 기능 실행 후 즉시 Amazon RDS에 요청 데이터를 저장하여 처리 상태를 추적합니다.
- PDF 조회: Amazon S3에 저장된 도서 PDF 파일을 가져옵니다.
- 텍스트 추출: pdfplumber 모듈을 사용하여 PDF의 텍스트를 추출합니다.
- 프롬프트 조회: Amazon Bedrock Prompt Management에서 요청된 유형별 프롬프트를 조회합니다.
4-1. 모든 프롬프트의 목록을 조회하기 위해 ListPrompt 요청을 수행합니다.
4-2. 수행하여야 하는 프롬프트의 상세정보를 조회하기 위하여, 4-1.의 반환값 중 필요한 PromptIdentifier목록을 추출하여 병렬로 GetPrompt 요청을 수행합니다. - AI 콘텐츠 생성: Amazon Bedrock Invoke Model API를 호출하여 독서 문항을 생성합니다.
5-1. 원활한 Prompt Caching을 위하여 하나의 프롬프트에 대한 InvokeModel을 요청합니다.
5-2. 나머지 프롬프트에 대해 InvokeModel를 병렬로 요청합니다. - 결과물 처리: 생성된 콘텐츠를 Excel 파일 형태로 파싱하여 xlsx 파일을 생성하고, Amazon S3에 업로드합니다.
- 비용 계산 및 상태 업데이트: 토큰 사용량을 기반으로 비용을 계산하고, 처리 결과를 Amazon RDS에 업데이트합니다.
독서문항생성 기능 구현 상세
Amazon Bedrock 통합 구현
다음은 Amazon Bedrock에 기능을 요청하는 부분의 핵심 코드입니다:
def get_prompt(prompt_summaries, option):
'''
prompt_summaries: 프롬프트 목록
option: {'name': 프롬프트 이름, ...}
'''
prompt_summary = next((item for item in prompt_summaries if item['name'] == option['name']), None)
get_prompt_response = bedrock_agent_client.get_prompt(promptIdentifier=prompt_summary['id'])
return {
"option": option,
"prompt": get_prompt_response
}
def get_prompts(quiz_options):
# 프롬프트 목록 조회
prompt_summaries = bedrock_agent_client.list_prompts()['promptSummaries']
return [get_prompt(prompt_summaries, option) for option in quiz_options]프롬프트 상세를 조회하기 위해서는 각 프롬프트의 promptIdentifier를 가져와야 합니다. 따라서 list_prompt()를 통해 모든 프롬프트의 ID를 조회하고, 그 중에서 필요한 프롬프트를 get_prompt()를 통해 상세 조회합니다.
'''
prompt: 프롬프트 상세
props: 프롬프트에 전달할 변수
'''
book_content = next((prop for prop in props if prop['name'] == 'book_content'), '')
# 프롬프트 상세에서 요청 프롬프트 가져오기
text = prompt['variants'][0]['templateConfiguration']['chat']['messages'][0]['content'][0]['text']
# 도서 전문을 삽입하고 프롬프트 캐싱을 위한 phrase 삽입
text_list.insert(1, {"type": "text", "text": book_content['content'], "cache_control": {"type": "ephemeral"}})
# Claude Sonnet 4 InvokeModel을 위한 요청 데이터 구성
body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": prompt['variants'][0]['inferenceConfiguration']['text']['maxTokens'],
"stop_sequences": prompt['variants'][0]['inferenceConfiguration']['text']['stopSequences'],
"system": prompt['variants'][0]['templateConfiguration']['chat']['system'][0]['text'],
"messages": [
{
"role": "user",
"content": text_list
}
],
}
response = bedrock_runtime_client.invoke_model(
body=json.dumps(body),
modelId=prompt['variants'][0]['modelId'],
accept='application/json',
contentType='application/json'
)
response_body = json.loads(response.get('body').read())
return {
"name": prompt['name'],
"content": next((row for row in response_body['content'] if row.get('type') == 'text'), {text: ''}).get('text'),
"usage": response_body['usage']
}조회한 프롬프트의 내용과 요청된 내용을 조합하여 모델 요청에 맞는 형태로 가공합니다. Prmopt Mnanagement의 프롬프트에는 도서 내용, 난이도,생성하는 문항의 수 를 변수로 넣어 실행할 수 있는 형태로 구성되어 있습니다. 변수를 적절한 문자열로 대체하고, 많은 분량을 차지하는 도서 내용이 캐싱될 수 있도록 Prompt Caching을 위한 구문을 추가하였습니다.
성능 최적화를 위한 비동기 처리
기능의 특성상 도서의 내용을 포함한 LLM 요청을 최대 9개까지 요청할 수 있어, 모델 처리시간이 많이 소요됩니다. 이러한 시간을 단축하기 위하여 InvokeModel을 병렬적으로 요청할 수 있도록 구현하였습니다:
async def invoke_model_async(prompt, props, book_info):
return await asyncio.to_thread(invoke_model, prompt, props, book_info)
REQUEST_SEMAPHORE = asyncio.Semaphore(3) # 최대 3개 동시 요청
async def invoke_model_with_retry(prompt, variables, book_info, max_retries=3):
"""재시도 로직이 포함된 invoke_model_async 래퍼"""
async with REQUEST_SEMAPHORE: # 동시성 제한
for attempt in range(max_retries):
try:
await asyncio.sleep(random.uniform(0.1, 0.5)) # 요청 간 간격
return await invoke_model_async(prompt, variables, book_info)
except Exception as e:
if "ThrottlingException" in str(e) and attempt < max_retries - 1:
# Exponential backoff
wait_time = (2 ** attempt) + random.uniform(0, 1)
await asyncio.sleep(wait_time)
else:
raise e
async def generate_quiz_content_batched(prompts, book_content, book_info, batch_size=2):
"""배치 단위로 요청을 나누어 처리"""
generated_quiz_contents = []
quiz_prompts = [prompt for prompt in prompts if 'quiz-prompt' in prompt['option']['name']]
# 프롬프트 캐싱을 위하여, 첫 번째 요청은 따로 처리
if len(quiz_prompts) > 0:
first_prompt = quiz_prompts.pop(0)
generated_quiz_contents.append(
await invoke_model_with_retry(
first_prompt['prompt'],
[
{"name": "book_content", "content": book_content},
{"name": "count", "content": first_prompt['option']['count']}
],
book_info
)
)
# 나머지를 배치로 처리
all_tasks = [invoke_model_with_retry(
prompt['prompt'],
[
{"name": "book_content", "content": book_content},
{"name": "count", "content": prompt['option']['count']}
],
book_info
) for prompt in quiz_prompts]
# 배치 단위로 실행
for i in range(0, len(all_tasks), batch_size):
batch = all_tasks[i:i + batch_size]
batch_results = await asyncio.gather(*batch, return_exceptions=True)
for result in batch_results:
if result is not None and not isinstance(result, Exception):
generated_quiz_contents.append(result)
# 배치 간 대기
if i + batch_size < len(all_tasks):
await asyncio.sleep(1)
return generated_quiz_contents특히 최근에 출시된 새로운 모델인 Claude Sonnet 4의 경우, 동시에 요청할 수 있는 횟수에 제한이 있어 배치를 활용하였습니다. InvokeModel에서는 사용하는 모델에 맞추어 조회한 프롬프트를 적절히 가공하여 요청 데이터를 구성하며, 여기서도 마찬가지로 도서 내용에 대해 Prompt Caching 기능을 통해 캐싱이 될 수 있도록 하는 구문을 추가하였습니다.
AWS Lambda function 선택 이유
독서문항생성 기능을 AWS Lambda function으로 구현한 주요 이유는 다음과 같습니다:
1. 최적의 LLM 모델 활용
독서문항 생성 기능의 성능은 LLM 모델의 성능에 크게 좌우됩니다. 긴 분량의 도서 내용과 유형마다 주어지는 요구사항들을 복합적으로 판단하여 결과물을 생성해야 하고, 교육적으로 도움이 되는 정보와 어휘를 사용해야 하기 때문입니다.
Amazon Bedrock Playground에서 여러 LLM 모델을 비교한 결과, 2025년 4월 당시 최신 모델이었던 Claude 3.7 Sonnet v1의 결과물이 가장 두드러지게 나타나 이 모델을 사용하기로 결정했습니다. 2025년 5월 말에 Claude Sonnet 4가 출시된 이후, 추가적인 성능 비교 후 LLM 모델을 Claude Sonnet 4로 변경하였습니다.
2. 크로스 리전 아키텍처 구현
Claude 3.7 Sonnet v1 모델 등 상위 LLM 모델은 일부 리전에서만 사용할 수 있고, 기존 리딩오션 서비스의 인프라가 있는 서울(ap-northeast-2) 리전에서는 사용할 수 없었습니다.
이에 Amazon Bedrock의 인프라는 해당 모델을 사용할 수 있는 오레곤(us-west-2) 리전에 두고 AWS Lambda function에서 boto3.client를 통해 호출하여 사용하는 방식으로 Amazon Bedrock 기능을 활용하였습니다. 이를 통해 서울 리전의 Amazon S3, Amazon RDS 등의 인프라를 사용하면서 Amazon Bedrock 기능을 사용할 수 있는 구조를 설계하였습니다.
3. 외부 모듈 및 라이브러리 활용
기능에는 PDF 파일에서 텍스트를 추출하거나 Excel 파일을 생성하고, Amazon RDS 상의 MySQL에 쿼리를 요청하는 등의 외부 모듈이 필요한 기능이 포함되어 있습니다. 이에 AWS Lambda Layer를 사용해 pdfplumber, openpyxl, pymysql 등의 모듈을 등록하여 사용할 수 있도록 하였습니다.

4. 리소스 격리 및 확장성
여러 리소스를 조회, 생성하고, 복수의 모델을 실행하는 만큼 많은 메모리와 시간을 소요하게 되는데, 이를 Amazon EC2의 서버에서 실행하게 되면 많은 리소스를 요구하여 기존 서비스 운영에도 지장이 생길 수 있습니다.
하지만 AWS Lambda function은 메모리와 제한 시간을 유동적으로 늘려 작업을 수행하는데 제한이 없도록 하여, 기존 서버와 독립적으로 기능을 수행할 수 있다는 장점이 있었습니다.
Amazon Bedrock Prompt Management를 활용한 유형별 프롬프트 관리
독서문항은 낱말퍼즐(십자말풀이), 매칭게임(순서맞추기), OX, 주관식, 객관식, 글쓰기 주제의 6가지 형태와, 도서에 대한 사실적, 비판적, 추론적, 감상적, 창의적 이해를 묻는 5가지 유형이 있습니다. 또한 도서의 난이도나, 문학/비문학 등의 도서 유형에 따라서 결과물의 변동이 필요합니다.
이에 결과물의 형태와 유형에 따라 많은 종류의 프롬프트를 만들고 지속적으로 관리 및 고도화할 필요가 있습니다.

이에 여러 개의 프롬프트에 대한 형상관리와 프롬프트 작성에 도움을 주는 Amazon Bedrock Prompt Management를 사용하였습니다. 특히 ‘변형비교’ 기능을 사용하여 프롬프트 작성 후 이전 버전의 프롬프트와의 테스트를 바로 진행하여 보다 유의미한 결과물을 생성할 수 있는 프롬프트를 작성하는 것에 도움을 받았습니다.
또한 Amazon Bedrock Prompt Management에서 저장한 프롬프트를 조회하여 사용하는 구조를 통해 AWS Lambda function 등의 코드의 변화 없이 독립적으로 프롬프트를 지속적으로 업데이트할 수 있도록 하였습니다.
프롬프트 예시: 추론적 이해를 묻는 객관식 생성
다음은 실제 사용되는 프롬프트의 일부 예시입니다:
Amazon Bedrock Prompt Caching을 활용한 토큰 최적화
LLM 모델 호출 시 긴 분량의 input, output이 사용되므로 각 요청마다 수행시간이 길어 Invoke Model을 병렬로 처리합니다. 각 독서문항 생성 프롬프트는 유형별 요구사항에 도서의 내용 전문을 모두 넣는 방식으로 구성되어 있습니다.
따라서 도서의 분량에 비례하여 토큰 사용량이 크게 증가하게 됩니다. 이 중에서 도서의 내용이 공통적으로 처리되는 부분에 대해 프롬프트 캐싱을 적용하였습니다.
프롬프트 캐싱 구현
아래 코드는 Amazon Bedrock에서의 Claude Sonnet 모델에서 프롬프트 캐싱을 적용하는 예시 코드입니다.
# 도서 전문을 삽입하고 프롬프트 캐싱을 위한 phrase 삽입
text_list.insert(1, {
"type": "text",
"text": book_content['content'],
"cache_control": {"type": "ephemeral"}
})프롬프트 캐싱을 통해 중복되는 토큰 사용 비용을 21.5%까지 낮출 수 있었습니다. 이는 동일한 도서에 대해 여러 유형의 문항을 생성할 때 도서 내용 부분이 캐시되어 재사용되기 때문입니다.
구현 결과 및 성과
Amazon Bedrock을 활용한 독서문항생성 시스템 구축을 통해 다음과 같은 성과를 달성했습니다:
품질 및 다양성 개선
콘텐츠 개발팀의 평가에 따르면 다음과 같은 품질 향상을 확인했습니다:
- 콘텐츠 다양성 확보: 기존 단일 팀 개발로 인한 유사성 문제 해결
- 핵심 소재 반영: 도서의 줄거리와 핵심 내용을 정확하게 반영한 문항 생성
- 창의적 문항 구성: AI를 통한 새로운 관점의 문제 아이디어 발상
- 고난이도 도서 대응: 복잡하고 긴 분량의 도서에 대한 효율적인 문항 개발
운영 효율성 향상
- 자동화된 워크플로우: PDF 업로드부터 Excel 결과물 생성까지 완전 자동화
- 실시간 진행 상황 추적: Amazon RDS 기반 상태 모니터링으로 투명한 작업 진행 관리
- 확장 가능한 아키텍처: AWS Lambda function의 자동 스케일링으로 동시 다발적 요청 처리
- 크로스 리전 최적화: 서울 리전 인프라와 오레곤 리전 Amazon Bedrock 연동으로 최적 성능 확보
마무리
(주)레듀텍은 Amazon Bedrock과 AWS 클라우드 서비스를 활용하여 교육 콘텐츠 개발의 패러다임을 바꾸는 성과를 달성했습니다.
핵심 성과 요약
✅ 5~7분 초안 자동 생성: 생성된 초안을 수정·검토하는 방식으로 전환하여 업무 효율성 극대화
✅ 약 35% 작업시간 단축: 최종 결과물 도출까지의 시간을 단축
✅ 콘텐츠 다양성 확보: AI 기반 창의적 문항 생성으로 품질 향상
✅ AI 생성 비용: 권당 $0.5~2로 경제적 콘텐츠 생성 실현
✅ 21.5% AI 비용 최적화: 프롬프트 캐싱을 통한 토큰 비용 절감
이러한 성과는 단순한 기술 도입을 넘어 교육 콘텐츠 개발 프로세스의 근본적 혁신을 통해 달성되었습니다. 특히 Amazon Bedrock의 강력한 LLM 기능과 AWS의 확장 가능한 클라우드 인프라를 결합하여, 에듀테크 분야에서 생성형 AI의 실질적 가치를 입증했습니다.
레듀텍은 앞으로도 AWS와 함께 혁신적인 기술을 교육 분야에 적용하여, 더 많은 학생들에게 양질의 개인화된 학습 경험을 제공하겠습니다.