소개
지난 1부에서는 VoD 환경에서의 비디오 분석 파이프라인 구축을, 2부에서는 AWS 미디어 서비스를 활용한 준실시간 분석 파이프라인을 다루었습니다. 이번 3부에서는 한 단계 더 나아가, AI 에이전트가 스스로 판단하고 도구를 선택하여 영상을 분석하는 에이전틱(Agentic) 비디오 엔진을 구축하는 방법을 소개합니다.
기존 1부와 2부의 파이프라인은 미리 정해진 순서대로 영상을 임베딩하고 검색하는 고정된 워크플로 방식이었습니다. 하지만 실제 영상 분석 요구사항은 이보다 훨씬 다양합니다. “이 축구 영상을 요약하고 골 장면을 찾아주고 자막은 VTT포맷을 유지한채 인도네시아어로 번역해줘”라는 요청에는 영상 임베딩, 영상 검색, 영상 요약, 자막 추출 등 여러 기능이 상황에 맞게 조합돼야 합니다.
물론 고정된 워크플로 방식을 활용할 수 있지만 개인별 영상을 처리하고자 하는 방식은 다양함으로 신규 영상 시나리오별 워크플로를 구성하고 자주 사용하지 않는 워크플로는 삭제해야 합니다. 이때, AI 에이전트를 활용하면 사용자의 자연어 요청을 이해하고, 원하는 결과를 도출하기 위해 어떤 도구를 어떤 순서로 사용할지 결정하고 어떤 에이전트와 협업할지 스스로 판단하게 할 수 있습니다. 이 글에서는 AWS가 오픈소스로 공개한 Strands Agents SDK를 사용하여, TwelveLabs의 비디오 AI 모델과 다양한 AWS 서비스를 통합한 에이전틱 비디오 엔진을 구축하는 예시를 단계별로 설명합니다.
Strands Agents SDK란?
Strands Agents SDK는 AWS가 오픈소스로 공개한 AI 에이전트 개발 프레임워크입니다. 개발자가 AI 에이전트를 빠르게 구축하고, 관리하고, 배포할 수 있도록 설계되었습니다.
핵심 개념: 에이전트 = 모델 + 도구 + 프롬프트
Strands에서 에이전트는 세 가지 요소로 구성됩니다.
- 모델(Model): 에이전트의 “두뇌” 역할을 합니다. Amazon Bedrock의 Claude, Nova 등 다양한 LLM을 지원합니다.
- 도구(Tool): 에이전트가 실제 작업을 수행할 때 사용하는 함수입니다. API 호출, 데이터 처리, 외부 서비스 연동 등 어떤 Python 함수든 도구로 만들 수 있습니다.
- 시스템 프롬프트(System Prompt): 에이전트의 역할과 행동 규칙을 정의합니다.
가장 간단한 에이전트는 단 3줄로 만들 수 있습니다.
from strands import Agent
agent = Agent()
response = agent("Amazon Bedrock에 대해 알려줘")
이 코드만으로도 Amazon Bedrock의 Claude 모델을 기본으로 사용하는 에이전트가 생성됩니다.
* BedrockModel을 명시적으로 선언하면 모델 ID와 리전을 원하는 대로 지정할 수 있습니다. 모델을 지정하지 않고 Agent()만 호출하면 기본값으로 us-west-2` 리전의 Claude Sonnet 4 모델이 사용됩니다. (참조)
에이전트 루프(Agent Loop)
Strands 에이전트의 동작 방식을 이해하는 것이 중요합니다. 에이전트는 단순히 LLM에 한 번 질문하고 답을 받는 것이 아닙니다. Agent Loop을 사용하면 다음과 같은 반복적인 추론-실행 루프를 수행합니다.
- 사용자 요청을 LLM에 전달
- LLM이 응답 생성 – 이때 도구 호출이 필요하다고 판단하면 도구를 선택
- 선택된 도구 실행 및 결과 수집
- 도구 실행 결과를 다시 LLM에 전달
- LLM이 추가 도구 호출이 필요한지 판단 – 필요하면 2번으로 돌아감
- 최종 응답을 사용자에게 반환
이 루프 덕분에 에이전트는 복잡한 작업도 여러 단계에 걸쳐 자율적으로 처리할 수 있습니다.
에이전트 훅(Agent Hook)
Strands는 에이전트 루프의 각 단계(모델 호출 전후, 도구 실행 전후 등)에 콜백 함수를 등록할 수 있는 Hook 시스템을 제공합니다. 이를 통해 도구 호출 횟수 제한, 실행 로깅, 도구 결과 후처리 같은 프로덕션 요구사항을 에이전트 코드 수정 없이 구현할 수 있습니다. 예를 들어, 비용이 큰 비디오 임베딩 생성 도구의 호출을 요청당 1회로 제한하거나, 모든 도구 호출을 모니터링 시스템에 기록하는 등의 제어가 가능합니다.
사용하는 AWS 서비스 및 AI 모델
본 블로그에서 구축하는 예시 에이전틱 비디오 엔진은 다음 서비스들을 통합합니다.
| 서비스 |
역할 |
| Amazon Bedrock – Claude Sonnet |
에이전트의 추론 엔진 (LLM). 사용자 요청을 이해하고 도구 호출을 결정 |
| Amazon Bedrock – TwelveLabs Marengo 3.0 |
비디오 임베딩 모델. 영상을 벡터로 변환하여 의미 기반 검색 지원 |
| Amazon Bedrock – TwelveLabs Pegasus 1.2 |
비디오 이해 모델. 영상 내용을 분석하고 텍스트로 요약 |
| Amazon S3 Vectors |
벡터 데이터베이스. 임베딩된 영상 클립의 벡터를 저장하고 유사도 검색 수행 |
| Amazon S3 |
소스 영상 파일 및 임베딩 결과 저장 |
| Amazon DynamoDB |
영상 처리 작업의 메타데이터 및 상태 관리 |
| Amazon Transcribe |
영상의 음성을 텍스트로 변환 (STT) |
| Amazon Bedrock – Claude Haiku |
자막 텍스트에서 키워드 추출 등 경량 NLP 작업 |
단계 1: 환경 설정 및 초기화
코드는 노트북 인스턴스에서 테스트해볼 수 있습니다. 먼저 필요한 라이브러리를 설치하고 AWS 서비스 클라이언트를 초기화합니다.
pip install --upgrade boto3 botocore strands-agents
import boto3, json, time, uuid, hashlib
from botocore.config import Config
from strands import Agent, tool
from strands.models import BedrockModel
from typing import Dict, Any
REGION = 'us-east-1'
S3_VECTORS_BUCKET = 'twl-marengo-3' # S3 Vectors 버킷, 원하시는대로 변경 필요
S3_VECTORS_INDEX = 'marengo3' # 벡터 인덱스, 원하시는대로 변경 필요
DYNAMODB_TABLE = 'strands-video-tasks' # 작업 관리 테이블, 원하시는대로 변경 필요
MARENGO_MODEL_ID = 'twelvelabs.marengo-embed-3-0-v1:0' # 임베딩 모델
PEGASUS_MODEL_ID = 'us.twelvelabs.pegasus-1-2-v1:0' # 요약 모델
ACCOUNT_ID = boto3.client('sts').get_caller_identity()['Account']
# AWS 서비스 클라이언트
# signature_version='v4'를 지정하여 StartAsyncInvoke에서 SigV4 서명 사용을 보장합니다.
# Bedrock API Key(Bearer Token) 인증 환경에서는 S3 자격증명이 전달되지 않아
# 비동기 호출이 실패할 수 있으므로, 명시적으로 SigV4를 지정합니다.
bedrock_runtime = boto3.client(
'bedrock-runtime', region_name=REGION,
config=Config(signature_version='v4')
)
s3 = boto3.client('s3', region_name=REGION)
s3vectors = boto3.client('s3vectors', region_name=REGION)
dynamodb = boto3.resource('dynamodb', region_name=REGION)
task_table = dynamodb.Table(DYNAMODB_TABLE)
transcribe = boto3.client('transcribe', region_name=REGION)
# Strands에서 사용할 LLM 모델
claude_model = BedrockModel(
model_id='us.anthropic.claude-sonnet-4-20250514-v1:0',
region_name=REGION
)
아래 샘플 코드를 실행하기 전에, 사전에 S3 Vector 버킷을 생성하고 벡터 인덱스를 생성한 뒤 코드 내 변수 값을 해당 환경에 맞게 수정해야 합니다. 또한 DynamoDB 작업 관리용 테이블도 미리 생성해야 하며, 동일하게 코드에서 해당 테이블 정보를 올바르게 설정해야 합니다.
# S3 Vectors 버킷 생성
try:
s3vectors.create_vector_bucket(vectorBucketName=S3_VECTORS_BUCKET)
print(f'버킷 생성 완료: {S3_VECTORS_BUCKET}')
except s3vectors.exceptions.ConflictException:
print(f'기존 버킷 사용: {S3_VECTORS_BUCKET}')
# 벡터 인덱스 생성
try:
s3vectors.create_index(
vectorBucketName=S3_VECTORS_BUCKET,
indexName=S3_VECTORS_INDEX,
dataType='float32',
dimension=EMBEDDING_DIMENSION,
distanceMetric='cosine'
)
print(f'인덱스 생성 완료: {S3_VECTORS_INDEX}')
except s3vectors.exceptions.ConflictException:
print(f'기존 인덱스 사용: {S3_VECTORS_INDEX}')
# DynamoDB Table 생성
try:
table = dynamodb.create_table(
TableName=DYNAMODB_TABLE,
KeySchema=[{'AttributeName': 'task_id', 'KeyType': 'HASH'}],
AttributeDefinitions=[{'AttributeName': 'task_id', 'AttributeType': 'S'}],
BillingMode='PAY_PER_REQUEST'
)
table.wait_until_exists()
print(f'테이블 생성 완료: {DYNAMODB_TABLE}')
except dynamodb.meta.client.exceptions.ResourceInUseException:
table = dynamodb.Table(DYNAMODB_TABLE)
print(f'기존 테이블 사용: {DYNAMODB_TABLE}')
BedrockModel은 Strands에서 Amazon Bedrock의 모델을 사용하기 위한 래퍼 클래스입니다. 모델 ID와 리전만 지정하면 바로 에이전트에 연결할 수 있습니다.
단계 2: 도구(Tool) 만들기 – @tool 데코레이터
Strands에서 도구를 만드는 방법은 매우 간단합니다. 일반 Python 함수에 @tool 데코레이터를 추가하면 됩니다. Strands는 함수의 독스트링(docstring)과 타입 힌트를 자동으로 분석하여 LLM이 이해할 수 있는 도구 명세를 생성합니다.
도구 1: 비디오 임베딩 생성
TwelveLabs Marengo 3.0 모델을 사용하여 영상을 6초 단위 클립으로 분할하고, 각 클립의 시각적/음성적 특징을 벡터로 변환합니다. 생성된 벡터는 Amazon S3 Vectors에 저장되어 이후 의미 기반 검색에 활용됩니다.
@tool
def create_video_embedding(s3_uri: str) -> Dict[str, Any]:
'''비디오 임베딩 생성 (완료까지 대기 후 S3 Vectors 저장).'''
task_id = str(uuid.uuid4())[:8]
bucket = s3_uri.split('/')[2]
key = '/'.join(s3_uri.split('/')[3:])
# DynamoDB에 작업 기록
task_table.put_item(Item={
'task_id': task_id, 's3_uri': s3_uri,
's3_bucket': bucket, 's3_key': key,
'status': 'processing', 'created_at': int(time.time())
})
# Marengo 임베딩 비동기 호출
response = bedrock_runtime.start_async_invoke(
modelId=MARENGO_MODEL_ID,
modelInput={
'inputType': 'video',
'video': {
'mediaSource': {
's3Location': {'uri': s3_uri, 'bucketOwner': ACCOUNT_ID}
},
'embeddingOption': ['visual', 'audio'],
'embeddingScope': ['clip'],
'segmentation': {'method': 'fixed', 'fixed': {'durationSec': 6}}
}
},
outputDataConfig={
's3OutputDataConfig': {'s3Uri': f's3://{bucket}/embeddings/{task_id}/'}
}
)
invocation_arn = response['invocationArn']
# 완료까지 대기
for _ in range(60):
status = bedrock_runtime.get_async_invoke(
invocationArn=invocation_arn
)['status']
if status == 'Completed':
break
time.sleep(10)
# 결과 파싱 및 S3 Vectors에 저장
output_uri = bedrock_runtime.get_async_invoke(
invocationArn=invocation_arn
)['outputDataConfig']['s3OutputDataConfig']['s3Uri']
prefix = '/'.join(output_uri.split('/')[3:])
objs = s3.list_objects_v2(Bucket=bucket, Prefix=prefix)
json_key = next(o['Key'] for o in objs['Contents'] if o['Key'].endswith('output.json'))
data = json.loads(s3.get_object(Bucket=bucket, Key=json_key)['Body'].read())
clips = data.get('data', [])
# 벡터를 S3 Vectors에 배치 저장
vectors = [{
'key': f"{task_id}_{c['embeddingOption']}_{c['startSec']}_{c['endSec']}",
'data': {'float32': c['embedding']},
'metadata': {'task_id': task_id, 'startSec': c['startSec'], 'endSec': c['endSec']}
} for c in clips]
for i in range(0, len(vectors), 100):
s3vectors.put_vectors(
vectorBucketName=S3_VECTORS_BUCKET,
indexName=S3_VECTORS_INDEX,
vectors=vectors[i:i+100]
)
return {
'task_id': task_id,
'status': 'completed',
'stored_clips': len(clips)
}
여기서 Marengo 모델은 비동기 호출(start_async_invoke)을 사용합니다. 영상 길이에 따라 수 분이 소요될 수 있기 때문입니다.
도구 2: 비디오 클립 검색
사용자의 텍스트 쿼리를 벡터로 변환한 뒤, S3 Vectors에서 가장 유사한 영상 클립을 찾아 반환합니다.
@tool
def search_video_clips(query: str, top_k: int = 10) -> Dict[str, Any]:
'''텍스트로 비디오 클립 검색. 결과에 video, timestamp, start_sec, end_sec 포함.'''
# 텍스트 쿼리를 벡터로 변환
response = bedrock_runtime.invoke_model(
modelId=MARENGO_MODEL_ID,
body=json.dumps({
'inputType': 'text',
'text': {'inputText': query}
}),
contentType='application/json'
)
emb = json.loads(response['body'].read())['data'][0]['embedding']
# S3 Vectors에서 유사도 검색
results = s3vectors.query_vectors(
vectorBucketName=S3_VECTORS_BUCKET,
indexName=S3_VECTORS_INDEX,
queryVector={'float32': emb},
topK=top_k,
returnDistance=True,
returnMetadata=True
)
clips = []
for v in results.get('vectors', []):
meta = v.get('metadata', {})
task_info = task_table.get_item(Key={'task_id': meta.get('task_id')}).get('Item', {})
start = int(meta.get('startSec', 0))
end = int(meta.get('endSec', 0))
clips.append({
'video': task_info.get('s3_key', ''),
's3_bucket': task_info.get('s3_bucket', ''),
'timestamp': f'{start//60}:{start%60:02d}-{end//60}:{end%60:02d}',
'start_sec': start,
'end_sec': end,
})
return {'query': query, 'clips': clips}
@tool
def get_clip_playback_url(s3_bucket: str, s3_key: str, start_sec: int, end_sec: int) -> Dict[str, Any]:
'''S3 영상의 특정 구간 재생 가능한 presigned URL 생성.'''
base_url = s3.generate_presigned_url(
'get_object', Params={'Bucket': s3_bucket, 'Key': s3_key}, ExpiresIn=3600
)
return {'playback_url': f'{base_url}#t={start_sec},{end_sec}'}
도구 3: 영상 요약
TwelveLabs Pegasus 1.2 모델은 영상을 직접 시청하고 내용을 텍스트로 요약할 수 있는 비디오 이해 모델입니다.
@tool
def summarize_video(s3_uri: str, prompt: str = '이 영상을 챕터별로 3문장 정도로 요약해줘') -> Dict[str, Any]:
'''Pegasus 모델로 영상 요약 생성.'''
response = bedrock_runtime.invoke_model(
modelId=PEGASUS_MODEL_ID,
body=json.dumps({
'inputPrompt': prompt,
'mediaSource': {
's3Location': {'uri': s3_uri, 'bucketOwner': ACCOUNT_ID}
}
}),
contentType='application/json'
)
result = json.loads(response['body'].read())
return {'s3_uri': s3_uri, 'summary': result.get('message', result)}
Pegasus 모델의 특징은 프롬프트를 통해 요약 방식을 자유롭게 지정할 수 있다는 점입니다. “챕터별로 요약해줘”, “주요 이벤트만 추출해줘” 등 다양한 형태의 요약을 요청할 수 있습니다.
도구 4: 자막 생성 및 키워드 추출
Amazon Transcribe를 사용하여 영상의 음성을 텍스트로 변환하고, 추출된 자막에서 Claude Haiku 모델로 키워드를 뽑아냅니다.
def _get_transcript_data(s3_uri: str):
'''S3에서 자막 JSON 데이터를 가져오는 헬퍼 함수.'''
bucket = s3_uri.split('/')[2]
job_name = f"transcript-{hashlib.md5(s3_uri.encode()).hexdigest()[:8]}"
return json.loads(
s3.get_object(Bucket=bucket, Key=f'transcripts/{job_name}.json')['Body'].read()
)
def _ensure_transcript(s3_uri: str) -> Dict[str, Any]:
'''자막이 없으면 Amazon Transcribe로 생성하는 헬퍼 함수.'''
bucket = s3_uri.split('/')[2]
job_name = f"transcript-{hashlib.md5(s3_uri.encode()).hexdigest()[:8]}"
output_key = f'transcripts/{job_name}.json'
try:
status = transcribe.get_transcription_job(
TranscriptionJobName=job_name
)['TranscriptionJob']['TranscriptionJobStatus']
except transcribe.exceptions.BadRequestException:
transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': s3_uri},
MediaFormat='mp4',
LanguageCode='ko-KR',
OutputBucketName=bucket,
OutputKey=output_key
)
status = 'IN_PROGRESS'
if status == 'IN_PROGRESS':
while status == 'IN_PROGRESS':
time.sleep(5)
status = transcribe.get_transcription_job(
TranscriptionJobName=job_name
)['TranscriptionJob']['TranscriptionJobStatus']
return {'transcript_file': f's3://{bucket}/{output_key}'}
@tool
def get_transcript_file(s3_uri: str) -> Dict[str, Any]:
'''자막 파일 S3 경로 반환 (없으면 생성).'''
return _ensure_transcript(s3_uri)
@tool
def get_transcript(s3_uri: str) -> Dict[str, Any]:
'''자막을 타임스탬프와 함께 테이블 형식으로 반환. 없으면 자동 생성.'''
try:
data = _get_transcript_data(s3_uri)
except:
_ensure_transcript(s3_uri)
data = _get_transcript_data(s3_uri)
# 5초 단위로 그룹핑
grouped = {}
for item in data['results']['items']:
if item['type'] == 'pronunciation':
sec = int(float(item.get('start_time', 0)))
key = f"{sec//5*5//60}:{sec//5*5%60:02d}"
grouped[key] = grouped.get(key, '') + ' ' + item['alternatives'][0]['content']
return {'transcript': [{'시간': k, '자막': v.strip()} for k, v in grouped.items()]}
@tool
def get_keywords(s3_uri: str) -> Dict[str, Any]:
'''영상 자막에서 키워드 추출.'''
try:
data = _get_transcript_data(s3_uri)
except:
_ensure_transcript(s3_uri)
data = _get_transcript_data(s3_uri)
transcript = ' '.join([
i['alternatives'][0]['content']
for i in data['results']['items']
if i['type'] == 'pronunciation'
])[:2000]
# Claude Haiku로 키워드 추출
response = bedrock_runtime.invoke_model(
modelId='us.anthropic.claude-3-5-haiku-20241022-v1:0',
body=json.dumps({
'anthropic_version': 'bedrock-2023-05-31',
'max_tokens': 256,
'messages': [{
'role': 'user',
'content': f'핵심 키워드 10개 JSON 배열로만:\n{transcript}'
}]
}),
contentType='application/json'
)
return {'keywords': json.loads(response['body'].read())['content'][0]['text']}
여기서 주목할 점은 서로 다른 AI 모델을 목적에 맞게 조합하는 방식입니다. 음성 인식은 Transcribe가, 키워드 추출은 Claude Haiku가 담당합니다. 대형 모델 대신 경량 모델을 사용하여 비용과 속도를 최적화할 수 있습니다.
단계 3: 단일 에이전트 구성
정의한 도구들을 모두 하나의 에이전트에 연결합니다. 시스템 프롬프트에 각 도구의 용도와 사용 가이드라인을 명확하게 작성하는 것이 중요합니다.
from strands.handlers.callback_handler import PrintingCallbackHandler
SYSTEM_PROMPT = '''당신은 영상 분석 에이전트입니다. 한국어로 응답하세요.
## 사용 가능한 도구
1. **create_video_embedding(s3_uri)**: 영상 임베딩 생성 및 벡터 DB 저장
2. **search_video_clips(query, top_k)**: 텍스트로 비디오 클립 검색
3. **get_clip_playback_url(s3_bucket, s3_key, start_sec, end_sec)**: 재생 URL 생성
4. **summarize_video(s3_uri, prompt)**: Pegasus 모델로 영상 요약
5. **get_transcript(s3_uri)**: 자막 조회 (없으면 자동 생성)
6. **get_keywords(s3_uri)**: 자막에서 키워드 추출
## 도구 선택 가이드라인
- 임베딩 생성 또는 요약 → summarize_video, create_video_embedding
- 클립 검색 또는 특정 장면 찾기 → search_video_clips
- 자막, 키워드 → get_transcript, get_keywords
- 복잡한 요청은 여러 도구를 순차적으로 사용
'''
orchestrator = Agent(
model=claude_model,
tools=[create_video_embedding, search_video_clips,
get_clip_playback_url, summarize_video,
get_transcript, get_keywords],
system_prompt=SYSTEM_PROMPT,
callback_handler=PrintingCallbackHandler()
)
이제 자연어로 복합 요청을 보낼 수 있습니다. 사용할 예시 영상 uri를 사용하여 검색해볼 수 있습니다.
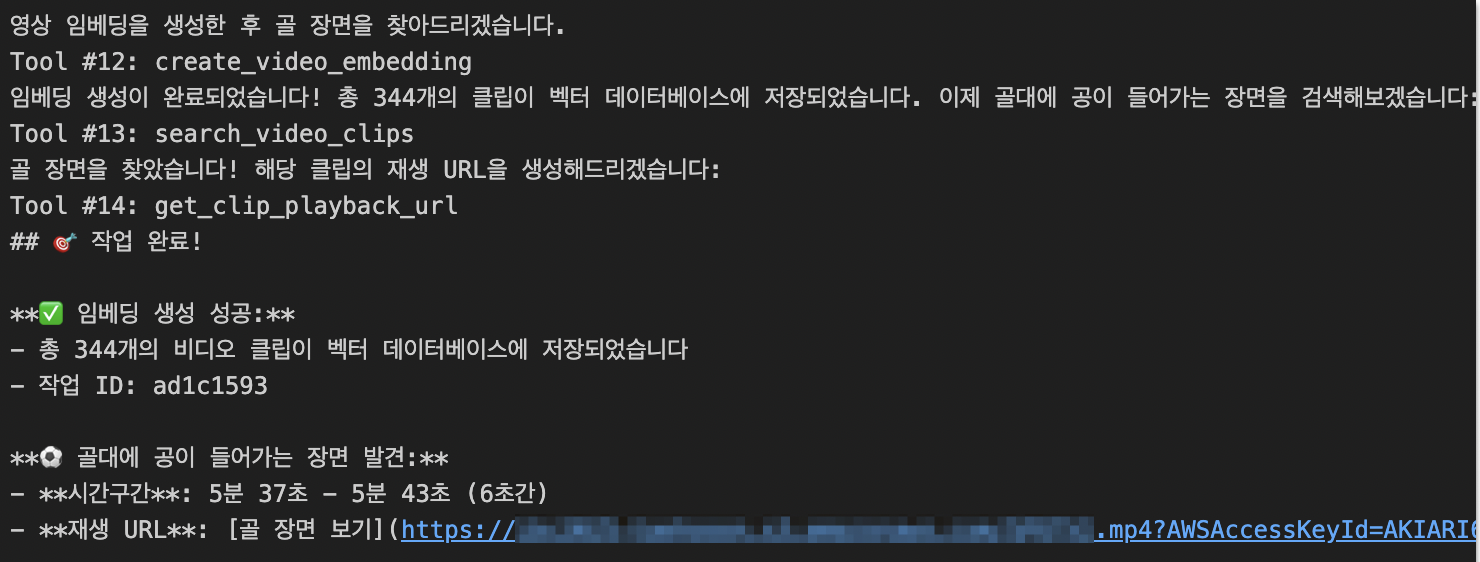
response = orchestrator(
"s3://my-bucket/sample-video.mp4 영상 임베딩해줘"
"그 후에 골대에 공이 들어가는 장면 찾아줘"
)
아래는 노트북 인스턴스에서 확인한 결과입니다. 에이전트가 다양한 Tool을 사용하여 요청한 내용에 대한 결과를 아웃풋으로 제공한 것을 볼 수 있습니다.
단계 4: Agents as Tool – 멀티 에이전트 아키텍처
단일 에이전트 방식은 간단하고 구현이 쉽지만, 다루는 도메인이 늘어날수록 시스템 프롬프트가 복잡해지고 도구 간 역할 경계가 모호해질 수 있습니다. Agents as Tool 패턴은 복잡한 문제를 해결하기 위해 각자 고유한 전문성을 지닌 전문가들을 관리자가 조정하는 인간 팀의 역학을 모방합니다. 단일 에이전트가 모든 것을 처리하려 하기보다는, 작업이 가장 적합한 전문 에이전트에게 위임됩니다. 이를 통해 각 에이전트는 자신의 영역에 최적화된 프롬프트와 도구만 보유하게 되어, 모듈성과 유지보수성이 향상됩니다.
4-1. 전문 에이전트 생성
각 도메인별로 전문 에이전트를 생성하고 위에서 생성한 도구들을 에이전트 별 할당하는 예시입니다. 먼저 각 전문 영역을 독립된 에이전트로 분리하여 관심사를 명확히 나누고, 오케스트레이터 에이전트가 사용자가 선언한 system_prompt에 따라 요청에 적절한 전문 에이전트를 호출하는 구조입니다.
# 영상 분석 전문 에이전트
video_analysis_agent = Agent(
model=claude_model,
tools=[create_video_embedding, summarize_video],
system_prompt='당신은 영상 분석 전문 에이전트입니다. 영상 임베딩 생성과 요약을 담당합니다.'
)
# 검색 전문 에이전트
search_agent = Agent(
model=claude_model,
tools=[search_video_clips, get_clip_playback_url],
system_prompt='당신은 영상 검색 전문 에이전트입니다. 클립 검색과 재생 URL 생성을 담당합니다.'
)
# 자막 처리 전문 에이전트
transcript_agent = Agent(
model=claude_model,
tools=[get_transcript_file, get_transcript, get_keywords],
system_prompt='당신은 자막 처리 전문 에이전트입니다. 자막 생성, 조회, 키워드 추출을 담당합니다.'
)
4-2. 에이전트를 도구로 래핑
이제 각 전문 에이전트를 @tool 데코레이터로 감싸서 오케스트레이터가 사용할 수 있는 도구로 변환합니다.
@tool
def video_analysis_tool(query: str) -> str:
"""
영상 분석 도구 (임베딩 생성, 요약)
Use this tool for video embedding creation and summarization.
Args:
query: The analysis request (String)
Returns:
Analysis results (String)
"""
response = video_analysis_agent(query)
return str(response)
@tool
def video_search_tool(query: str) -> str:
"""
영상 검색 도구 (클립 검색, 재생 URL 생성)
Use this tool for searching video clips and generating playback URLs.
Args:
query: The search request (String)
Returns:
Search results with playback links (String)
"""
response = search_agent(query)
return str(response)
@tool
def transcript_tool(query: str) -> str:
"""
자막 처리 도구 (자막 생성/조회, 키워드 추출)
Use this tool for transcript generation, retrieval, and keyword extraction.
Args:
query: The transcript request (String)
Returns:
Transcript or keyword results (String)
"""
response = transcript_agent(query)
return str(response)
4-3. 오케스트레이터 생성
마지막으로 세 개의 에이전트 도구를 사용하는 최상위 오케스트레이터를 만듭니다. 아래 예시와 같이 오케스트레이터에게 에이전트별 사용 가이드라인을 제공해주는 것이 좋습니다.
from strands.agent.conversation_manager import SlidingWindowConversationManager
ORCHESTRATOR_PROMPT = """
You are the Video Processing Orchestrator Agent. Always respond in Korean.
Tool Selection Guidelines:
- For embedding creation or video summarization → video_analysis_tool
- For searching clips or specific scenes → video_search_tool
- For transcripts, subtitles, or keywords → transcript_tool
- For complex requests, use multiple tools in sequence
"""
orchestrator = Agent(
system_prompt=ORCHESTRATOR_PROMPT,
tools=[video_analysis_tool, video_search_tool, transcript_tool], #사용할 에이전트 지정
model=claude_model,
callback_handler=PrintingCallbackHandler(),
conversation_manager=SlidingWindowConversationManager(
window_size=20,
should_truncate_results=True
)
)
단계 5: 실행 및 결과
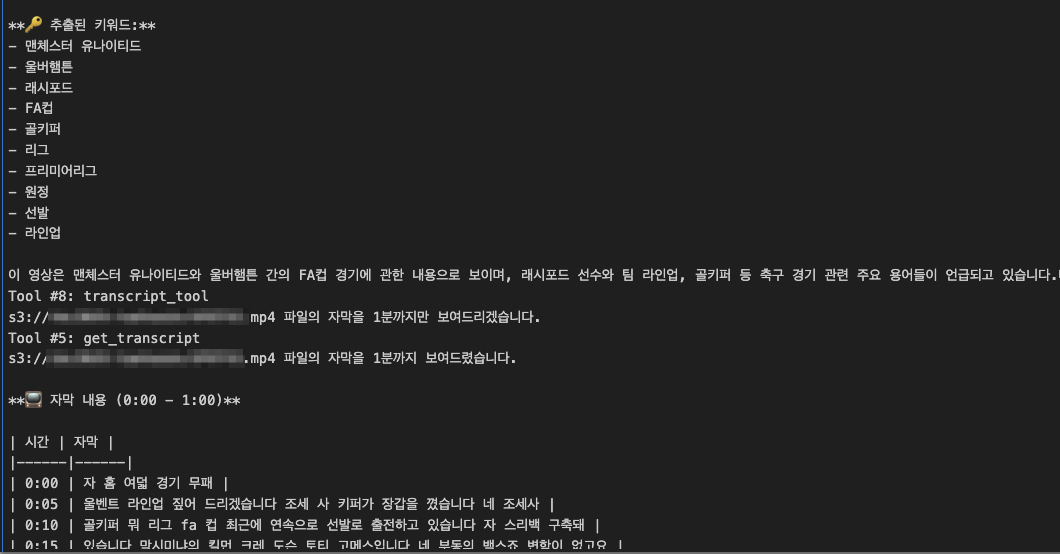
이제 복합적인 영상 분석 요청을 오케스트레이터에 보내봅니다.
response = orchestrator(
"s3://my-bucket/sample-video.mp4 내용 요약해주고 키워드 찾아줘."
"그 후에 자막을 1분까지만 보여줘."
)
결론
이 블로그에서는 Strands Agents SDK를 활용하여 TwelveLabs 비디오 AI 모델과 AWS 서비스를 통합한 에이전틱 비디오 엔진을 구축하는 과정을 단계별로 살펴보았습니다. Strands Agents SDK는 AI 에이전트를 빠르게 구축할 수 있는 오픈소스 프레임워크입니다. Amazon Bedrock의 TwelveLabs Marengo, Pegasus모델을 AWS의 다른 파워풀한 서비스인 Amazon S3 Vectors, Amazon DynamoDB, Amazon Transcribe 등과 통합하여 고도화된 비디오 에이전트를 구현할 수 있습니다.
클라우드 환경에서의 TwelveLabs 기반 비디오 인텔리전스 구현 블로그는 총 5개의 시리즈로 구성이 되어 있습니다. 아래에서 관심 있는 주제를 추가로 살펴보시기 바랍니다.
TwelveLabs로 시작하는 AI 영상 분석 1부 – VoD환경에서의 비디오 분석 파이프라인 구축하기
TwelveLabs로 시작하는 AI 영상 분석 2부 – 준실시간 환경에서 AWS Elemental을 활용한 분석 파이프라인 구축하기
TwelveLabs로 시작하는 AI 영상 분석 4부 – TwelveLabs Marengo 3.0 임베딩 및 검색 전략과 구현 가이드
TwelveLabs로 시작하는 AI 영상 분석 5부 – AWS에서 Marengo 3.0 비디오 임베딩을 저장하고 검색하기