AWS 기술 블로그
Amazon ElastiCache for Valkey의 CESC로 Interactive AI 스토리텔링 플랫폼 최적화하기
![]()
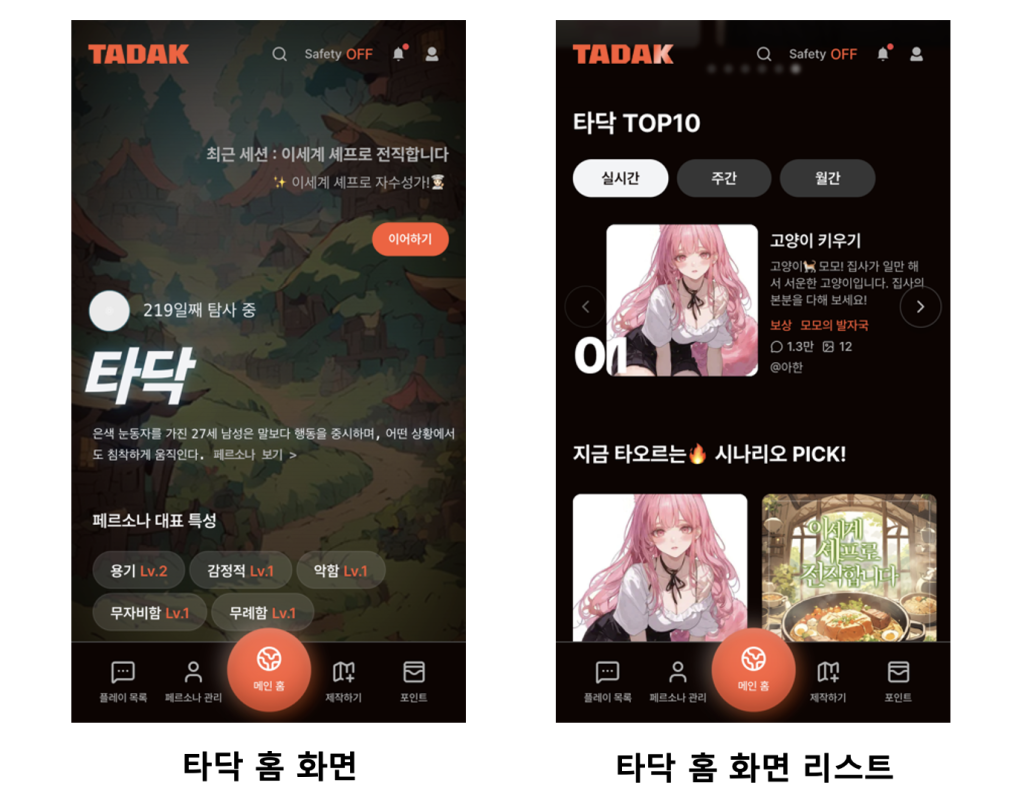
인공지능 기술의 발전은 텍스트 기반 게임의 지평을 넓히고 있습니다. 뷰컴즈(Viewcommz)가 운영하는 타닥(Tadak)은 단순한 텍스트 시뮬레이션을 넘어, 사용자가 직접 다양한 세계관을 창조하고 공유하는 ‘멀티버스 형 Interactive AI 스토리텔링 플랫폼’ 입니다.
![]()
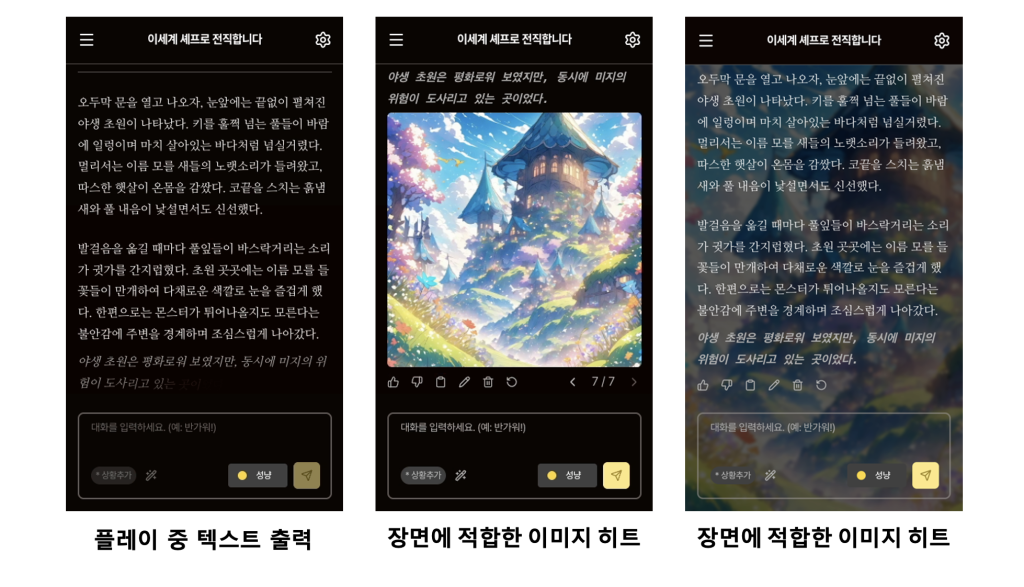
현재 뷰컴즈는 사용자 경험을 극대화한 차세대 버전의 ‘타닥 v2’를 준비하고 있습니다. 타닥 v2 개발의 핵심 목표는 ‘끊김 없는 몰입(Seamless Immersion)’ 입니다. 타닥의 수많은 세계 안에서 상상력을 시각화할 수 있는 일러스트는 사용자의 몰입감에 결정적인 역할을 수행하지만, 생성형 AI(Generative AI)를 이용한 실시간 이미지 생성은 높은 비용과 함께 긴 지연 시간이라는 과제를 안고 있었습니다.
본 게시물에서는 타닥 v2의 핵심 엔진으로 탑재될 CESC(Context Enabled Semantic Caching) 아키텍처를 소개합니다. 뷰컴즈는 Amazon ElastiCache for Valkey의 벡터 검색 기능을 활용하여, 사용자 창작 컨텐츠 환경에서 이미지 로딩 속도를 획기적으로 개선했습니다.
1. Amazon ElastiCache for Valkey
Amazon ElastiCache for Valkey는 완전관리형 인메모리 캐시 서비스로 Valkey 7.2부터 지원되고 있으며, Redis OSS와도 완전하게 호환됩니다. Valkey는 Linux Foundation에서 관리하는 오픈소스 고성능 Key-value 데이터 스토어로 Redis OSS의 Drop-in 대체재로 설계되었습니다. Amazon ElastiCache for Valkey는 다음과 같은 특장점을 가지고 있습니다.
1.1. 비용효율성
Amazon ElastiCache for Valkey는 서버리스로 사용 시 Redis OSS 엔진 대비 33% 저렴한 가격으로 제공되고 있으며, 노드 기반으로 사용할 때는 Redis OSS 엔진 대비 20% 저렴한 가격으로 제공됩니다.
1.2. 향상된 성능
최근 ElastiCache에서 Valkey 8.0의 지원이 시작되었습니다. Valkey 8.0의 새로운 I/O Multi-thread 아키텍처는 최대 230% 높은 처리량과 최대 70% 개선된 지연 시간을 제공하고 있습니다.
1.3. Generative AI 및 Agentic AI 지원
Amazon ElastiCache for Valkey는 벡터 검색(Vector Search)과 시맨틱 캐싱(Semantic Caching)으로 생성형 AI와 에이전트 기반 서비스에 필요한 기능을 지원하고 있습니다. 마이크로초 단위의 지연 시간으로 수십억 개의 고차원 벡터 검색이 가능하고, 벡터 임베딩을 활용해 유사한 쿼리의 의미를 비교하고 캐시된 응답을 재사용하여 LLM 호출에 대한 비용과 지연 시간을 함께 절감하실 수 있습니다.
Amazon ElastiCache for Valkey의 벡터 검색과 시맨틱 캐싱은 Valkey 8.2 부터 사용하실 수 있습니다. 최대 99%의 재현율(Recall)을 달성하실 수 있고, HNSW(Hierarchical Navigable Small World) 및 FLAT 알고리즘을 지원하며, 벡터, 태그, 숫자 필터를 조합한 하이브리드 검색이 가능합니다.
1.4. Valkey GLIDE – 엔터프라이즈급 Valkey 클라이언트 라이브러리
Valkey GLIDE는 AWS가 개발한 오픈소스 클라이언트 라이브러리로, Valkey와 Redis OSS에 대한 엔터프라이즈급 안정성과 운영 우수성을 제공합니다. Valkey GLIDE가 갖는 주요 특징은 다음과 같습니다.
① 다중 언어 지원
② 향상된 가용성
③ 관찰 가능성 강화
Valkey GLIDE를 이용하면 Amazon ElastiCache for Valkey의 벡터 검색 기능과 함께 시맨틱 캐싱을 구현하실 수 있으며, 다음과 같은 작업을 수행하실 수 있습니다.
① 벡터 인덱스 생성 및 관리
② 벡터 데이터 저장
③ 벡터 유사도 검색 또는 하이브리드 검색
2. 해결 과제: 멀티버스 환경에서의 실시간성 확보
타닥은 사용자가 직접 월드(World)를 제작하고 공유하는 UGC(User Generated Content) 중심의 플랫폼입니다. 판타지, SF, 로맨스 등 다양한 장르의 월드가 공존하고 있으며, 각 월드마다 고유한 화풍과 설정이 존재합니다.
뷰컴즈는 사용자의 행동에 맞춰 즉각적인 시각적 피드백을 제공하고자 했으나, 다음과 같은 기술적 어려움에 부딪혔습니다.
① 생성 지연(Latency) : 고품질 이미지를 실시간으로 생성하는데 평균 3-5초가 소요됩니다. 이는 대화형 스토리텔링의 빠른 호흡을 끊는 큰 원인이 됩니다.
② 맥락의 파편화 : 단순 키워드 매칭으로는 각 월드가 가진 고유한 설정(세계관과 캐릭터 외형 등)을 반영하기 어려웠습니다.
③ 비용 효율성 : 유사한 상황이 반복되는 게임의 특성상, 매번 동일한 이미지를 새로 생성하는 것은 불필요한 컴퓨팅 자원을 낭비하게 됩니다.
뷰컴즈는 이러한 문제를 해결하기 위해 ‘맥락을 이해하는 캐싱(Semantic Caching)’ 도입을 결정하였습니다.
2.1. CESC(Context Enables Semantic Caching)이란?
시맨틱 캐싱은 사용자의 요청이 이전에 있었던 요청과 문자열이 완전하게 일치하지 않더라도, 의미적으로 유사하면 캐시된 결과를 반환하는 기법입니다. 예를 들어, “용을 공격해!” 라는 문장과 “드래곤에게 검을 휘둘러!”라는 문장은 서로 다른 문자열을 가지고 있지만, 의미적으로 유사한 장면을 묘사하기 때문에 동일한 이미지를 재사용할 수 있습니다. 그러나 타닥과 같은 멀티버스 플랫폼에서는 단순한 시맨틱 캐싱만으로는 충분하지 않습니다.
CESC는 이러한 문제를 해결하기 위해 뷰컴즈가 설계한 캐싱 전략입니다. 사용자 입력의 의미(Semantic)에 더해, 해당 입력이 발생한 맥락(Context) 정보를 함께 임베딩 벡터로 반영하는 것입니다.
2.2. 설계 Deep Dive
뷰컴즈는 CESC 구현을 위해 다음 세 가지 정보를 결합하여 하나의 벡터를 생성하였습니다.
① 사용자 입력(User Input): 사용자가 실제로 수행한 행동 (예시: “공격해!”)
② 월드 메타데이터(World Metadata): 현재 플레이하고 있는 월드의 ID, 장르, 화풍 등의 세계관 정보
③ 캐릭터 상태(Character Status): 현재 캐릭터의 위치와 장비, 상황 등 게임 내 상태 정보
이 세 가지 정보를 결합하여 생성된 벡터를 Amazon ElastiCache for Valkey에 저장하고, 이후 유사한 맥락의 요청이 들어오게 되면, 벡터 검색을 통해 기존에 생성된 이미지를 즉시 반환하게 됩니다. 이를 통해 동일한 텍스트 입력이 들어오더라도, 월드에 따라서 서로 다른 캐시 결과를 정확하게 제공할 수 있습니다.
이러한 접근 방식의 핵심 이점은, 캐시 키가 단순 문자열이 아닌, 맥락이 반영된 벡터이기 때문에, 표현이 다르더라도 맥락이 유사하다면 캐시 적중이 가능하고, 반대로 문자열이 같더라도 맥락이 다르면 서로 다른 결과를 반환할 수 있다는 점입니다.
3. 솔루션
3.1. CESC 적용
CESC는 결국 사용자의 단순 입력뿐 아니라, 월드 정보와 현재 상황을 결합하여 캐싱하는 전략입니다. 이를 위해 다음의 과정이 포함됩니다.
① Context Ingestion : 사용자 입력(“공격해”) + 월드 메타데이터(World ID, 장르) + 캐릭터 상태 → 임베딩 벡터 생성
② Vector Search : ElastiCache for Valkey에서 코사인 유사도(Cosine Similarity) 기반으로 벡터 검색
3.2. 캐시 친화적인 게임 구조 설계(Design for Cacheability)
뷰컴즈는 단순히 CESC만 도입한 것이 아닙니다. 타닥 v2의 기획 단계부터 캐시 적중률을 극대화할 수 있는 구조를 설계했습니다.
월드 진입(Intro), 보스 조우(Encounter), 아이템 획득(Acquisition) 등 게임 내의 주요 이벤트 맥락을 구조화하여, 서로 다른 사용자가 플레이 하더라도 유사한 시각적 맥락(Visual Context)이 빈번하게 발생할 수 있도록 유도했습니다. 이러한 구조적 설계는 트래픽이 늘어날 수록 캐시 적중률이 자연스럽게 상승하는 기반이 됩니다.
4.아키텍처 및 구현 상세
뷰컴즈의 서비스는 NodeJS 기반의 Backend 애플리케이션에서 AWS SDK과 Valkey GLIDE 클라이언트를 사용해 Amazon Aurora(메타데이터), Amazon ElastiCache for Valkey(벡터 스토어)와 통신합니다.
4.1. 아키텍처
단순한 검색(Retrieval)을 넘어, 검색된 결과가 현재 맥락에 적합한지 판단하는 LLM 검증(Verification) 단계가 포함되어 있습니다.
4.1.1. 동기 작업
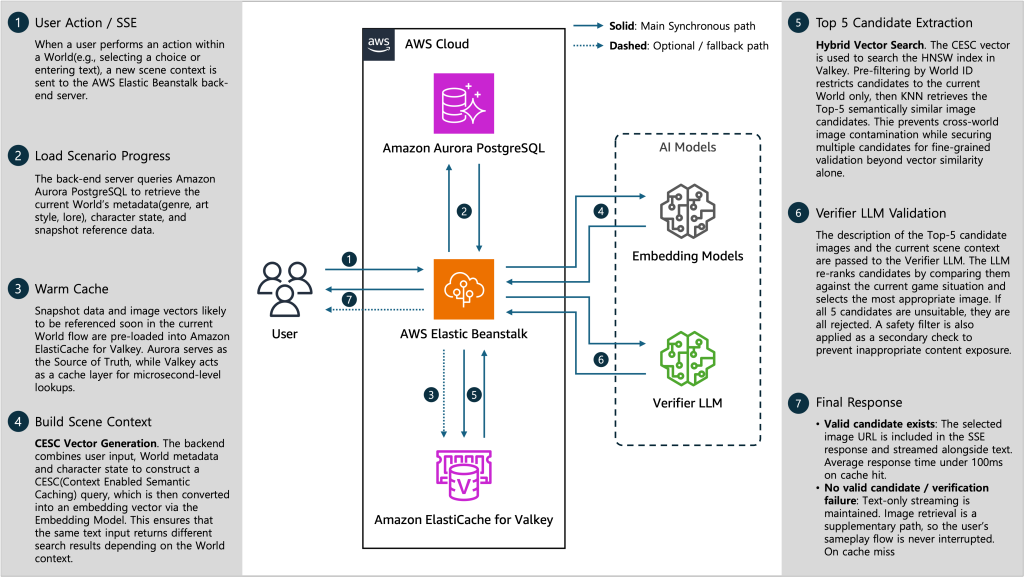
4.1.2. 비동기 작업
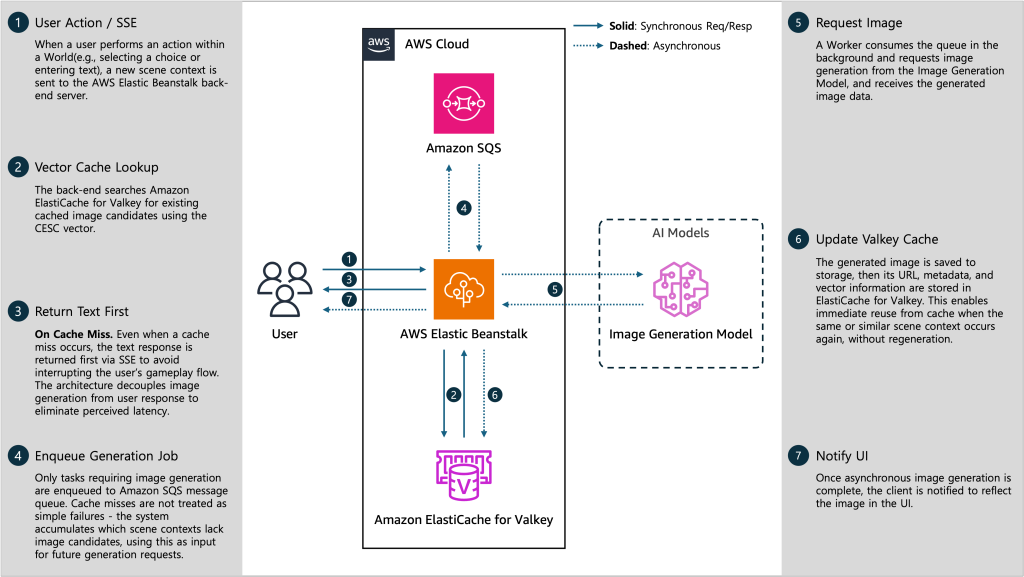
4.2. 데이터 스키마 및 인덱스 전략
타닥은 멀티버스 플랫폼 특성상 수많은 월드가 존재합니다. 서로 다른 세계관의 이미지가 섞이는 것을 방지하기 위해, 뷰컴즈는 Valkey의 Hash 구조에 메타데이터를 함께 저장하고 HNSW(Hierarchical Navigable Small World) 인덱스를 적용했습니다.
HNSW 인덱스는 고차원 벡터 검색을 위한 그래프 기반의 근사 최근접 이웃 검색 알고리즘(Approximate Nearest Neighbor)입니다. 이 알고리즘은 다층 그래프 구조를 구축하므로 데이터가 늘어나더라도 효율적인 벡터 검색이 가능합니다.
인덱스에 포함되는 데이터는 다음과 같습니다.
① Partition Key : World ID를 Tag 필드로 지정하여 물리적인 파티셔닝 없이도 논리적으로 검색 범위를 완전하게 분리하였습니다.
② Vector Data : 이미지 묘사(Description)을 임베딩한 고차원 벡터를 Image Vector 필드에 저장하게 됩니다.
4.3. 검색 구현: Valkey GLIDE를 활용한 Hybrid Search
NodeJS 환경에서 Valkey GLIDE 라이브러리를 사용하면 하이브리드 검색(Pre filtering + KNN) 구현이 가능합니다. 단순히 가장 유사한 1건(Top 1)만 가져올 경우 벡터 유사도는 높지만 미묘한 설정(예시: 캐릭터의 표정 또는 소품)이 어긋날 수 있습니다. 이를 해결하기 위해 뷰컴즈는 상위 5개(Top 5)의 후보군을 추출하는 전략을 사용했습니다. 다음은 실제 구현된 검색 로직의 핵심 코드 스니펫입니다.
4.4. 재현율 향상을 위한 후처리(LLM Verification)
검색된 5장의 후보 이미지는 ‘LLM Verifier’를 거쳐 최종적으로 선별됩니다. 이 단계는 RAG(Retrieval-Augmented Generation) 파이프라인의 Re-ranking 과정에 해당합니다. 후처리 과정은 다음과 같습니다.
① Context Comparison
– LLM에게 “현재 게임 상황”과 “후보 이미지 5장의 묘사”를 비교하게 합니다.
② Selection
– 상황과 가장 완벽하게 일치하는 1장을 선택합니다.
– 만약 5장의 이미지가 모두 부적합할 경우 ‘Reject’ 하게 됩니다.
– Reject이 발생하면, Fallback Strategy가 수행됩니다
③ Safety
– safetyFilterStatus 메타데이터를 재확인하여 부적절한 컨텐츠 노출 여부를 이중으로 방지합니다.
이러한 인간 수준의 검증 로직을 수행하여, 뷰컴즈는 0.1초라는 빠른 속도를 유지하면서도 엉뚱한 이미지가 몰입을 깨는 환각(Hallucination) 현상을 최소화할 수 있었습니다.
4.5. 캐시 미스 대응(Fallback Strategy)
Verifier LLM이 모든 후보를 거절하거나, 신규 월드라서 아직 캐시 데이터가 없는 경우에는 다음과 같은 UX 방어 로직이 작동합니다.
① Text-First
– 이미지 생성을 기다리게 하는 대신, 텍스트로 스토리를 즉시 출력하여 사용자의 플레이 흐름을 유지합니다.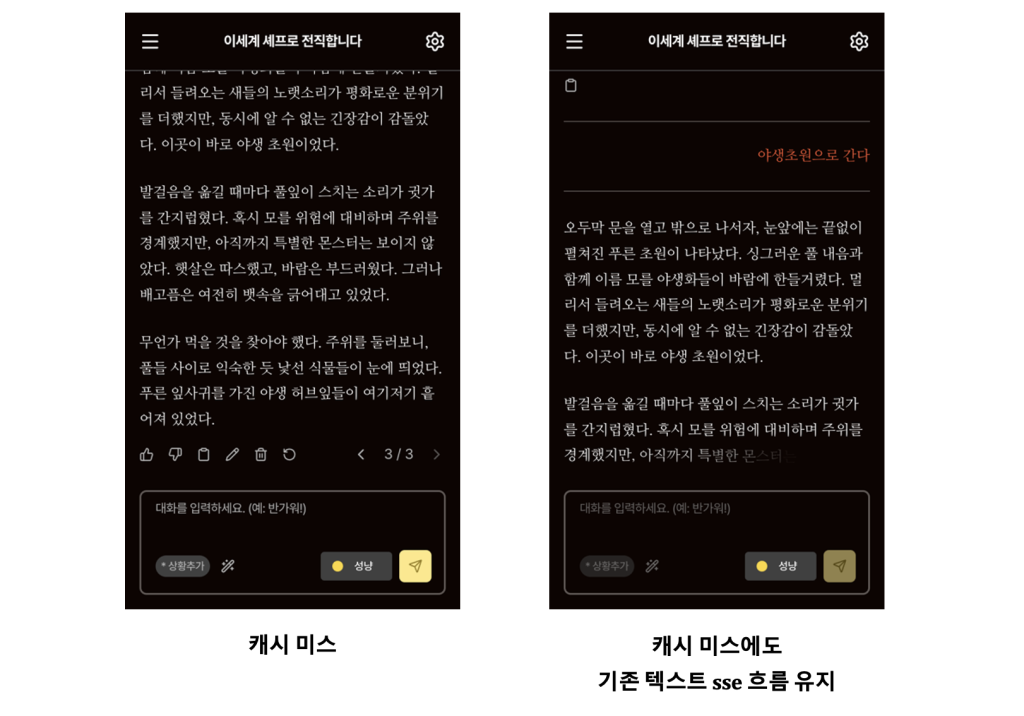
② Async Generation
– 백그라운드에서 메시지 큐(Message Queue)를 통해 이미지 생성을 요청합니다.
– 생성된 이미지는 추후 동일한 맥락의 요청이 발생할 때 사용할 수 있도록 Amazon ElastiCache에 캐싱됩니다.
5. 도입 효과 및 성과
5.1. 지연 시간 및 리소스 최적화
Amazon ElastiCache for Valkey를 도입한 후, 이미지 제공 프로세스에서 다음과 같이 극적인 성능 향상을 확인할 수 있었습니다.
① 캐시 적중 시 응답 속도: 평균 100ms 미만(기존 대비 약 98% 단축)
② 리소스 효율화: 공통된 이벤트(월드 진입, 상점 이용 등)나 인기 월드에서 캐시 적중률이 높아짐에 따라, 고비용의 원인이었던 LLM 호출 횟수를 효과적으로 절감했습니다.
5.2. 비용최적화 : 트래픽이 늘어날 수록 더 저렴해지는 구조
생성형 AI 서비스를 운영함에 있어서 가장 큰 부담은 호출당 발생하는 높은 LLM 추론 비용입니다. 타닥에서 사용하는 고품질 이미지 생성 모델(Nano Banana 등)은 이미지 장당 약 50원의 비용이 발생합니다.
뷰컴즈는 Amazon ElastiCache for Valkey 기반의 CESC 도입을 통해 전체 트래픽의 35%를 캐시로 처리함으로써, 선형적으로 증가하던 변동 비용의 기울기를 낮추는 데 성공했습니다.
# 월 100만 회 요청 기준 비용 시뮬레이션
|
구분 |
도입 전 (Generation
Only) |
도입 후 (With
CESC) |
비고 |
|
처리 방식 |
100% 실시간 생성 | 65% 생성 + 35% 캐시 | 캐시 히트율 35% 기준 |
|
생성 API 비용 |
5,000만 원
(100만 회 x 50원) |
3,250만 원 (65만 회 x
|
월 1,750만 원 절감 |
|
검색 비용 |
0원 |
미미함 (Negligible) |
ElastiCache 고정 비용에 포함 |
| 총 비용 절감률 | – | 약 35%
절감 |
단순히 비용을 아끼는 것을 넘어, ElastiCache for Valkey를 기반으로 한 검색 비용은 트래픽이 증가하더라도 이미지 생성 비용 대비 매우 완만하게 증가합니다. 이는 서비스가 성장하고 사용자(DAU)가 늘어날 수록 사용자당 평균 비용(Cost per User)가 낮아지는 건강한 비즈니스 모델을 완성했음을 의미합니다.
5.3. UGC 생태계의 경험 개선
크리에이터가 만든 월드가 쌓일 수록 캐시 데이터도 함께 축적됩니다. 특히 앞서 언급한 ‘구조화된 게임 설계’ 덕분에, 월드와 스토리가 늘어날 수록, 재사용 가능한 맥락 데이터도 함께 늘어나므로 캐시 적중률은 지속적으로 상승할 수 있습니다.
이는 시간이 지날수록 서비스 전체의 응답 속도가 빨라지고, 월드의 시각적 일관성(Consistency)이 유지되는 데이터 네트워크 효과를 만들어낼 수 있는 기반이 됩니다.
6. 마치며
뷰컴즈는 Amazon ElastiCache for Valkey의 벡터 검색 기능을 통해, ‘속도’와 ‘몰입’ 이라는 두 마리 토끼를 모두 잡을 수 있었습니다. 이 아키텍처는 곧 출시될 타닥 v2에 전면 적용되어, 사용자가 게임 속 세상에서 지연 없이 상상력을 펼칠 수 있는 환경을 제공하게 될 것입니다.
향후 뷰컴즈는 v2 서비스 출시 이후 발생하는 실제 트래픽 패턴을 분석하여 캐시 미스에 대한 전략을 더욱 고도화하고, 이미지 뿐 아니라 사운드(BGM, SFX)와 영상에 대해서도 맥락 기반 추천을 확장하여, 진정한 의미의 멀티모달(Muti-modal) Interactive 플랫폼으로 거듭날 계획입니다.