- AWS Solutions Library
- Guidance for Media Extraction and Dynamic Content Policy Framework on AWS
Guidance for Media Extraction and Dynamic Content Policy Framework on AWS
Overview
This Guidance demonstrates how to accelerate your content analysis workflows by automating video metadata extraction, intelligence gathering, and content moderation. It enables you to efficiently process large volumes of video content, extract valuable insights, and make data-driven decisions through customizable policy evaluations. By automating these traditionally manual tasks, you can reduce operational costs, improve accuracy, and scale your content analysis capabilities while maintaining secure and reliable operations.
How it works
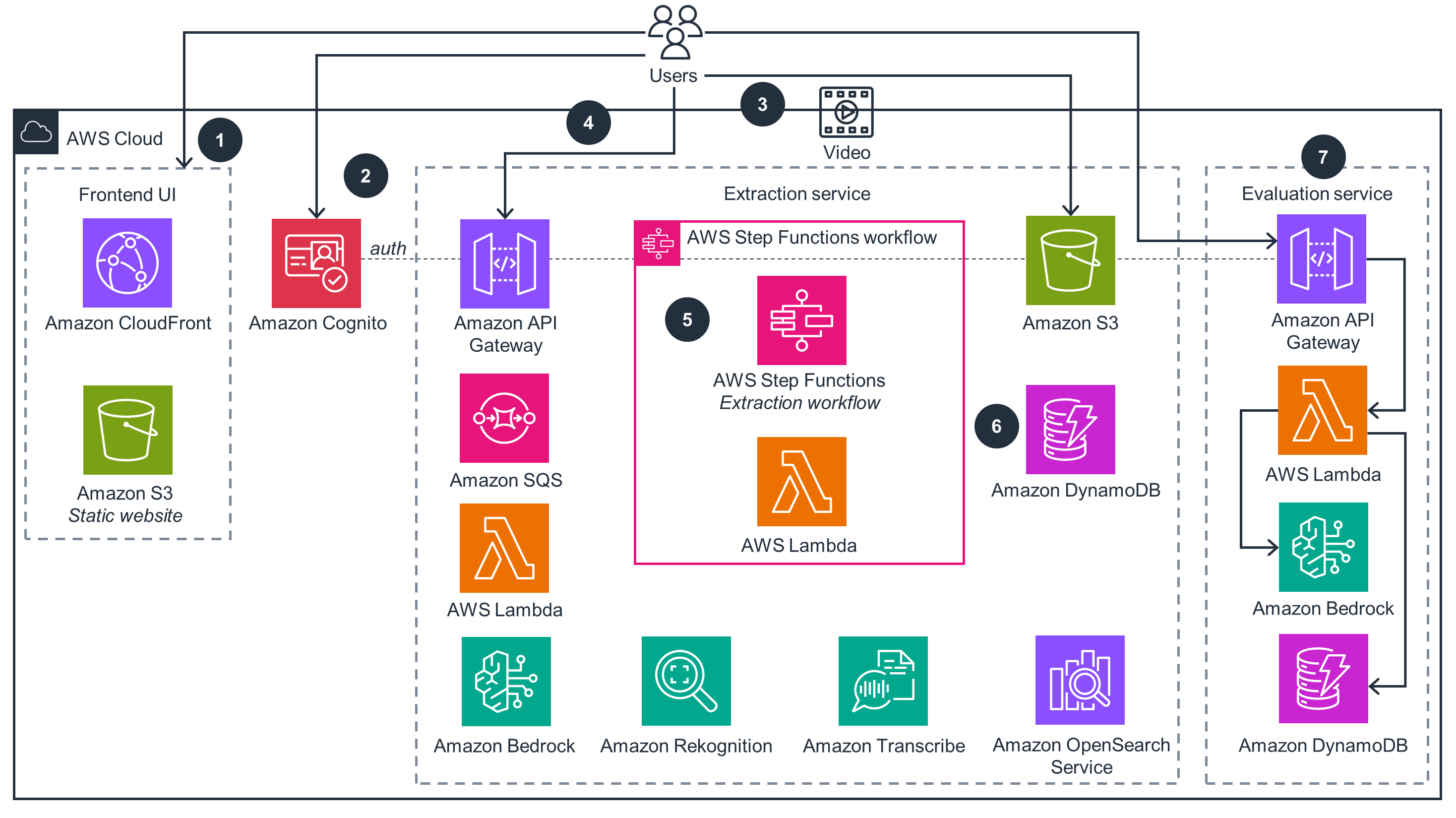
Extraction of generic metadata
This architecture diagram shows how to use generative AI to extract generic metadata from videos and demonstrates a dynamic policy evaluation analysis.
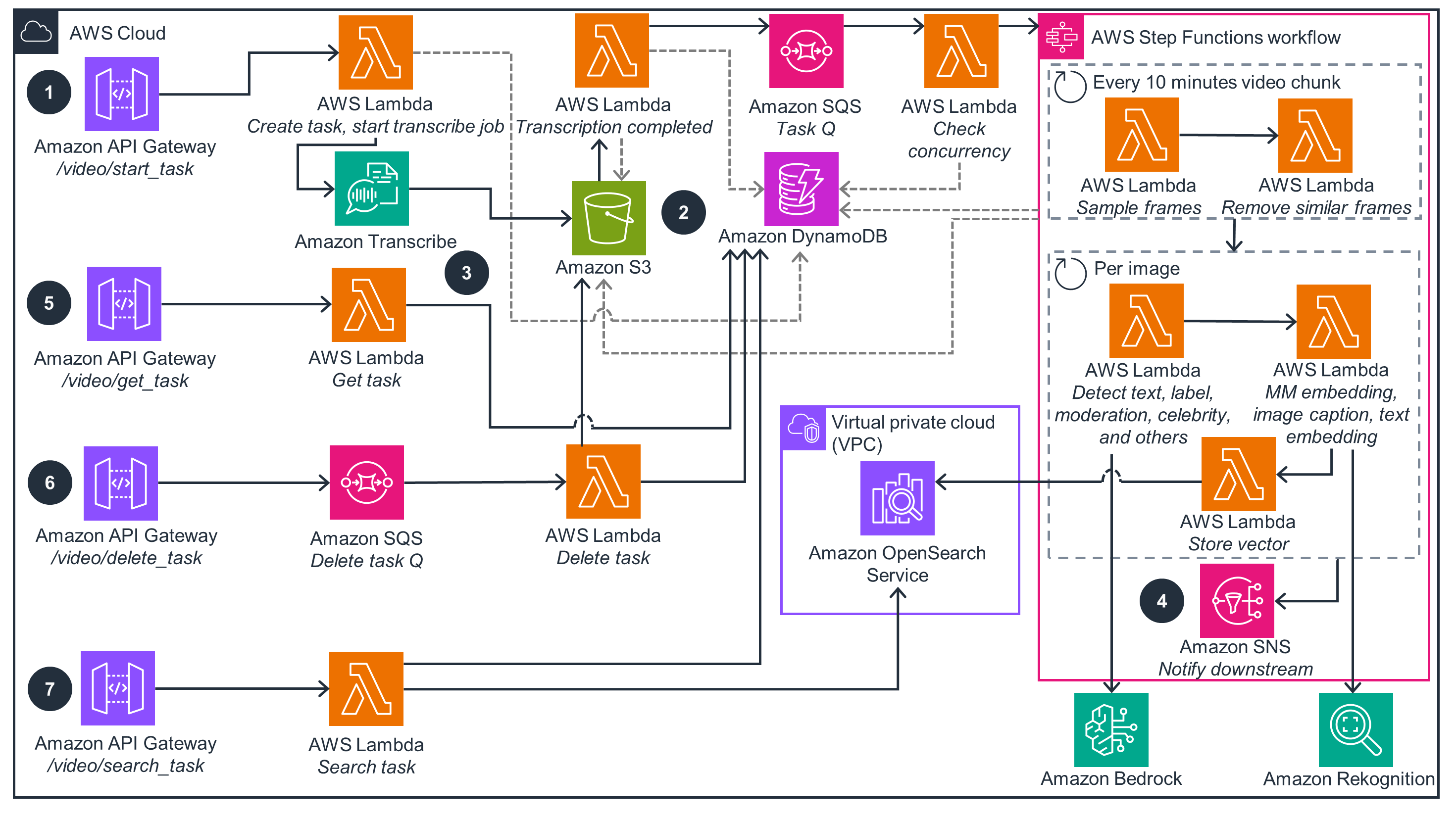
Restful APIs of the extraction service
This architecture diagram illustrates the key RESTful APIs of the extraction service, served through Amazon API Gateway. The UI uses APIs to retrieve data, allowing users to integrate the extraction service into existing workflows.
Deploy with confidence
Ready to deploy? Review the sample code on GitHub for detailed deployment instructions to deploy as-is or customize to fit your needs.
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
Amazon CloudWatch provides logging and insights for the services running in AWS Lambda and Step Functions. This Guidance pushes metrics to CloudWatch at various stages to provide observability into the infrastructure, such as Lambda functions, AI/ML services, and S3 buckets.
Read the Operational Excellence whitepaperThis Guidance implements least-privilege AWS Identity and Access Management policies and encrypts S3 data using AWS Key Management Service (AWS KMS) keys. User authentication is handled through Amazon Cognito using OAuth patterns for both web application login and API Gateway calls. The OpenSearch service cluster is deployed in an Amazon Virtual Private Cloud (Amazon VPC) private subnet, accessible only to authorized Lambda functions.
Read the Security whitepaperAmazon S3 provides robust data management through version control, deletion prevention, and cross-region replication capabilities. Serverless services like API Gateway, Lambda, Step Functions, and Amazon Simple Queue Service (Amazon SQS) offer built-in scalability and high availability. The OpenSearch Service deployment supports high availability through multiple Availability Zones, featuring redundant data nodes with replicated shards, helping ensure data persistence and recovery capabilities.
Read the Reliability whitepaperLambda and Step Functions enable efficient parallel processing through concurrent execution of functions and workflow steps. This parallel processing capability improves overall throughput and reduces execution time. The serverless architecture automatically handles the complexity of scaling workloads on AWS for optimal performance for media processing tasks.
Read the Performance Efficiency whitepaperAmazon S3 storage classes and lifecycle policies optimize video storage costs, while serverless and AI/ML services operate on a pay-as-you-go model, meaning you only pay for services used. The event-driven architecture helps ensure charges apply only for resources actually used, allowing you to configure and tailor your media workflows cost-effectively while using S3 lifecycle policies to to store and archive ingested contents, proxies, and metadata.
Read the Cost Optimization whitepaperAWS serverless services and AI/ML components allocate compute resources dynamically based on demand, eliminating over-provisioning and reducing resource waste. This approach minimizes energy consumption and compared to traditional on-premises servers, while maximizing the efficiency of AWS AI services to reduce the environmental impact of backend operations.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages