이 콘텐츠는 어떠셨나요?
콘텐츠 언어
현재 모든 콘텐츠가 번역되지는 않습니다.
- 학습
- How Snorkel AI achieved over 40% cost savings by scaling machine learning workloads using Amazon EKS
How Snorkel AI achieved over 40% cost savings by scaling machine learning workloads using Amazon EKS
Machine learning (ML) startups are often heavy compute users, because they train large models using high-end GPUs and deploy them at scale for inference. AWS Startups partners with startups from inception to IPO, and has helped thousands of founders and artificial intelligence (AI) innovators build their businesses on Amazon Elastic Kubernetes Service (Amazon EKS). Amazon EKS is a popular choice to build and host ML models because it provides the flexibility of Kubernetes with the security and resiliency of being an AWS managed service that is optimized for building highly available containerized workloads.
Snorkel AI is one such company that benefits from Amazon EKS. Snorkel AI equips Fortune 500 companies, federal agencies, and AI innovators to build, adapt, and distill foundation models (FMs) and large language models (LLMs) to perform with high accuracy on domain-specific datasets. Using Snorkel’s data-centric approach toward AI development, organizations have built production-ready AI services for use cases, including insurance claims processing, financial spreading, clinical trial analytics, and accelerating proactive well management for offshore drilling.
Over the past several months, the Snorkel team has been hard at work addressing the unique challenges of designing efficient infrastructure to support ML development workloads without increasing infrastructure bills, lowering developer velocity, or impairing user experience. Their ultimate objective was to reduce the cluster compute expenditure for Snorkel Flow, their end-to-end ML platform, by more than 40%.
An overview of Snorkel Flow
Snorkel's Snorkel Flow AI data development platform enables data teams to rapidly build AI applications by employing an iterative loop of programmatic labeling, quick model training, and error analysis. Each project starts when users create a small number of labeling functions.
Labeling functions employ simple heuristics, external databases, legacy models, or even calls to large language models to apply labels to swaths of unlabeled data based on encoded expert intuition. The platform's weak supervision algorithm combines these rule-based functions to determine the most likely label for each record. Users then train a simple model based on these probabilistic data points and assess the impact of each labeling function. In the analysis phase, users investigate slices of the data where the model underperforms. Then they build or modify labeling functions, train another quick model, and continue the loop. When users are satisfied with the quality of their labels, they build a final model on an architecture from the model zoo—ranging from logistic regression to FMs—and export it for deployment.
Due to the nature of this workflow, Snorkel Flow's infrastructure experiences varied periods of high compute usage. Operating costs naturally increased as the customer base and ML product capabilities of Snorkel Flow scaled. To achieve efficient growth, Snorkel aimed to understand how to enhance margins while operating state-of-the-art ML software. Snorkel implemented the following practices to achieve more than 40% reduction in cluster compute costs.
Solutions for cloud cost optimization
Software-as-a-service (SaaS) startups often have opportunities to optimize their cloud spending. It is essential to understand the unique factors that drive these costs.
For Snorkel, there were two significant factors:
- ML development workloads often require specialized and expensive hardware, such as GPUs. Typically, these workloads are “bursty” in nature.
- Fortune 500 companies and large federal agencies use Snorkel, including major financial institutions with sophisticated IT departments that have specific deployment and data privacy requirements, by using a containerized platform.
Snorkel’s team is keen on creating systems that allow efficient scaling without a linear increase in infrastructure costs. Consequently, Snorkel developed a comprehensive autoscaling solution tailored for their ML workloads on Amazon EKS to address cloud expense concerns. This solution not only expedited workloads that require burst compute but also achieved their cost reduction goals.
In addition to the autoscaling solution, key strategies that contributed to the over 40% reduction in cloud expenses include:
- Collaborating with engineering leaders and the AWS team to adopt Savings Plans through cloud configuration optimizations.
- Right-sizing resources by monitoring node utilization with Prometheus and consulting backend engineers to gauge platform component needs.
- Switching to cost-effective virtual machine (VM) types on Amazon EKS and utilizing multi-GPU Amazon Elastic Compute Cloud (Amazon EC2) instances for enhanced price performance.
- Instituting internal process modifications where engineers collaborated with customer-facing teams to minimize idle compute.
In this post, Snorkel shares the process for addressing these scaling challenges to help facilitate the design of better infrastructure for ML systems. If you're new to Kubernetes, read Snorkel's Introduction to Kubernetes post to learn more about the basics and their Machine learning on Kubernetes: wisdom learned at Snorkel post to learn more about their journey with Kubernetes thus far.
What Snorkel Flow looks like on AWS
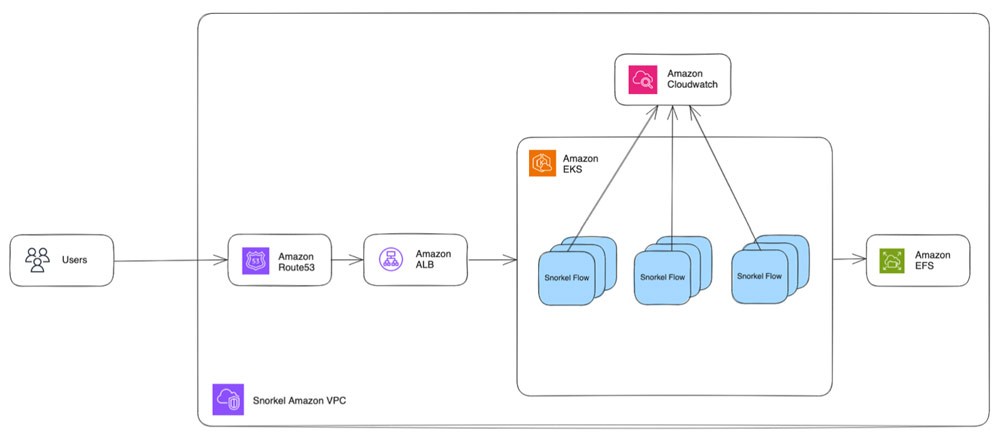
In practice, Snorkel Flow's interaction with AWS follows the sequence outlined as follows. As the Snorkel Flow platform relies heavily on containers, the migration to AWS was almost seamless.
- Users reach their Snorkel Flow instance via their web browser, which maps to a rule in Amazon Route 53.
- Route 53 forwards the request to an Application Load Balancer.
- The Application Load Balancer then forwards the request to Snorkel Flow pods running on a shared EKS cluster. Snorkel switched the EC2 instance type from m5 to m6a to optimize costs, resulting in a 10% compute savings with negligible performance impact based on cost per hour for the same CPU and RAM.
- Additionally, they upgraded from a single g4dn.8xlarge GPU instance to a g4dn.12xlarge multi-GPU instance, which allowed for serving 4x as many GPU pods.
- Each Snorkel Flow instance uses an Amazon Elastic File System (Amazon EFS) volume to store files on disk.
- A self-hosted Redis queue on a pod on the EC2 instance holds the incoming jobs, waiting for worker pods to pick them up.
- EKS metrics are pushed to Amazon CloudWatch, and custom scripts monitor the logs for cluster performance anomalies.
This architecture has yielded a stable and snappy experience for Snorkel Flow users.
Rethinking how to scale
Prior to the architecture described in Figure 1, early iterations of Snorkel’s infrastructure used fixed resources. Snorkel’s users shared that these bursty workloads could take too long to complete and therefore negatively impacted their experience.
Manual scaling of compute resources proved unscalable and error-prone, leading to cloud costs that stayed elevated even during periods of low usage. It was the worst of both worlds: low cloud cost efficiency and slower-than-needed performance.
To address these challenges, Snorkel implemented autoscaling at multiple levels in their infrastructure, as discussed in the following sections.
Designing scalable infrastructure with cost-efficiency in mind
The Kubernetes distribution of Snorkel Flow involves a set of deployments running in an EKS cluster that contains pods that run various components of the platform.
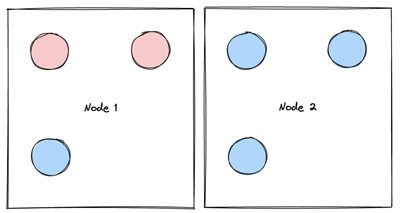
As shown in Figure 2, to address the unique challenges of working with bursty compute workloads, Snorkel’s team introduced a new concept for Kubernetes pods: semantically categorizing them as either “fixed” or “flexible.”
- Pods that are fixed cannot be safely moved from node to node, either because they will lose important in-memory state (such as in-progress compute jobs without checkpointing) or to minimize avoidable downtime for foundational platform components (for example, the orchestrator for the Ray cluster).
- Pods that are flexible can be safely moved to a new node. This distinction is meaningful in the context of autoscaling, because downscaling nodes involves moving pods away from underutilized nodes when they are terminated.
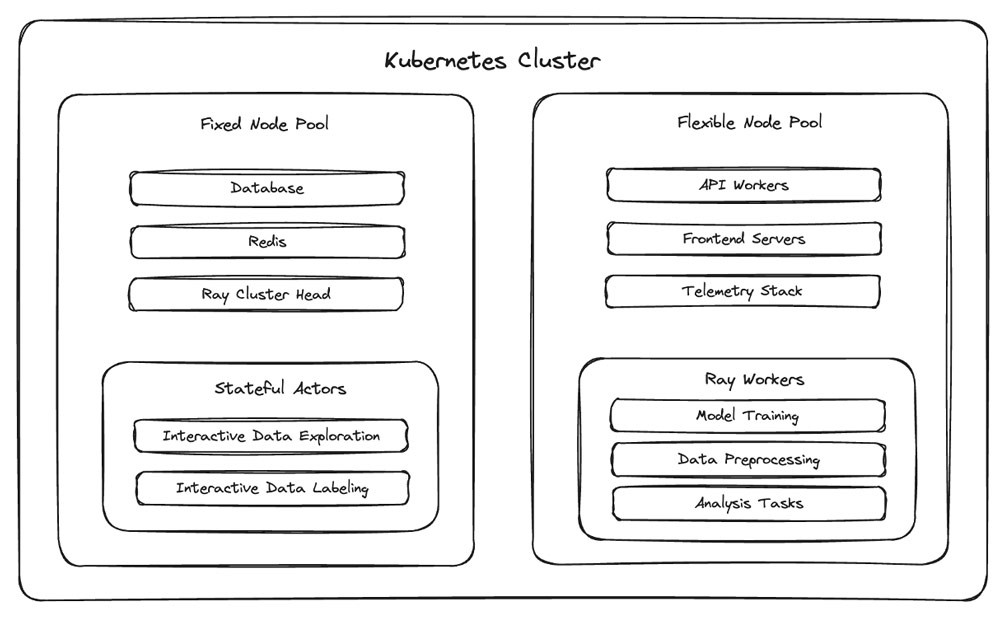
This fixed/flexible framework gives Snorkel a domain-specific means to enable automated cluster downscaling, which allows them to turn on the cluster autoscaler on Amazon EKS without their finance department messaging them every hour.
Snorkel’s initial approach was to deploy podDisruptionBudgets on the EKS cluster to prevent the cluster autoscaler from moving flexible pods during the day and from moving fixed pods at all. While effective, this approach left the Snorkel team unsatisfied because it downscaled far fewer nodes than what was theoretically optimal.
To address this, Snorkel layered on a pod scheduling optimization that isolated fixed pods to a small fixed group of nodes. It scheduled flexible and worker pods (which are considered to be fixed pods but are ephemeral due to worker node autoscaling) in the remaining flexible group of nodes.
These changes allowed Snorkel to efficiently downscale the flexible nodes at night, when it became safe to move around flexible pods and scale down the vast majority of worker pods.
Enabling efficient downscaling of the vast majority of the cluster’s nodes (i.e., the flexible nodes) allowed Snorkel to meet their target of reducing the cloud costs for hosting Snorkel Flow by over 40%.
More detail on Snorkel’s autoscaling solution
Snorkel divides the implementation of the solution described in the previous section into three sequential efforts:
- First, Snorkel implemented “worker autoscaling,” a custom Redis-based autoscaling service that allows their worker pods to scale up and down based on jobs in the workers’ queues.
- Second, they implemented “cluster autoscaling” by reconfiguring their Kubernetes deployments to allow the Kubernetes cluster autoscaler to scale nodes down, in addition to scaling nodes up.
- Third, Snorkel implemented “node downscaling optimizations” by grouping fixed pods into a small group of fixed nodes to prevent fixed pods from interfering with the downscaling of the remaining nodes.
Worker autoscaling
The Snorkel Flow platform abstracts compute into a paradigm where jobs wait in Redis queues and workers run as processes in worker pods.
Snorkel implemented a worker autoscaling solution (Figure 3) for worker pods by running a recurring function in Snorkel Flow’s backend API. Every few seconds, this function checks the Kubernetes cluster and Redis for both upscaling and downscaling eligibility.
If there are jobs waiting in one or more relevant Redis based queues, the function will ask the Kubernetes API to provision additional worker pods to process these jobs. If the Redis queue is empty and there are no running jobs in the job registry, it will ask the Kubernetes API to destroy the worker pods to free up reserved CPU and RAM resources.
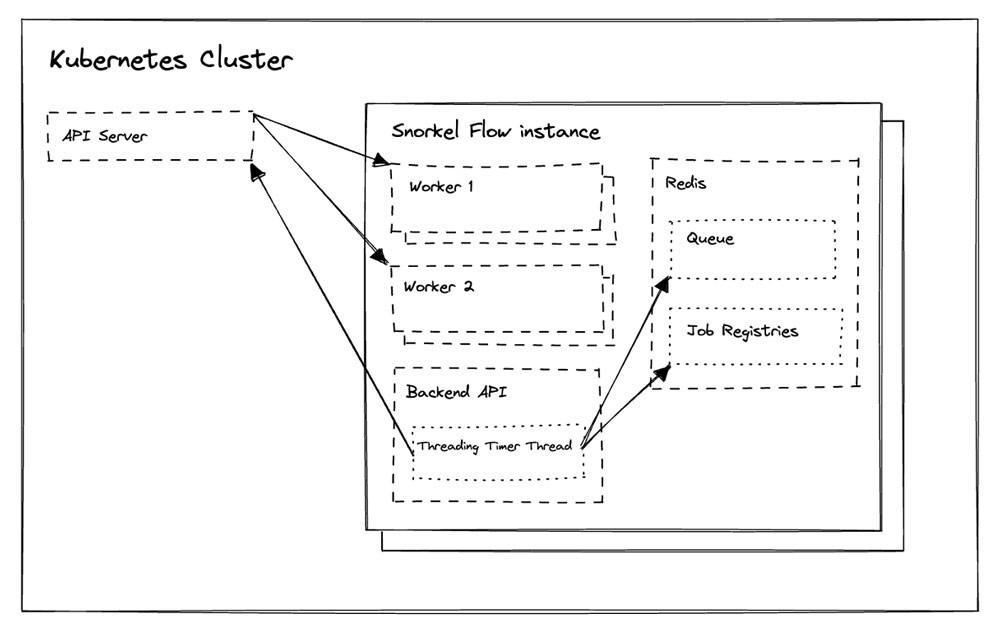
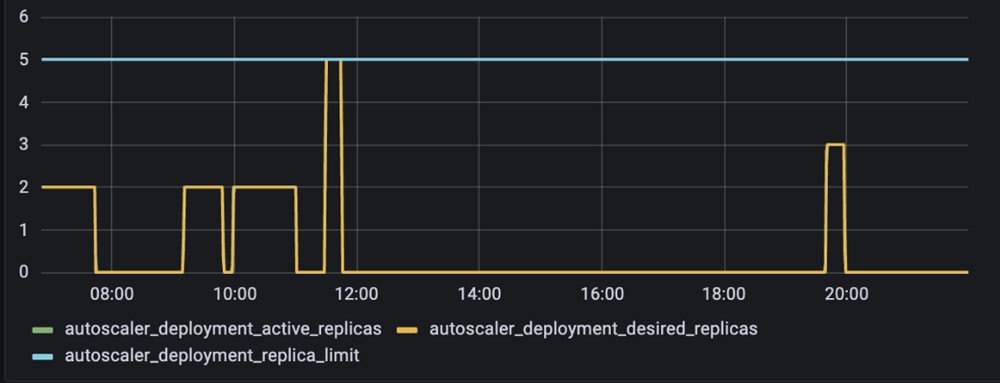
As shown in Figure 4, with this worker autoscaling implementation rolled out, Snorkel Flow’s worker pods became ephemeral, appearing in the cluster only when jobs needed to be processed.
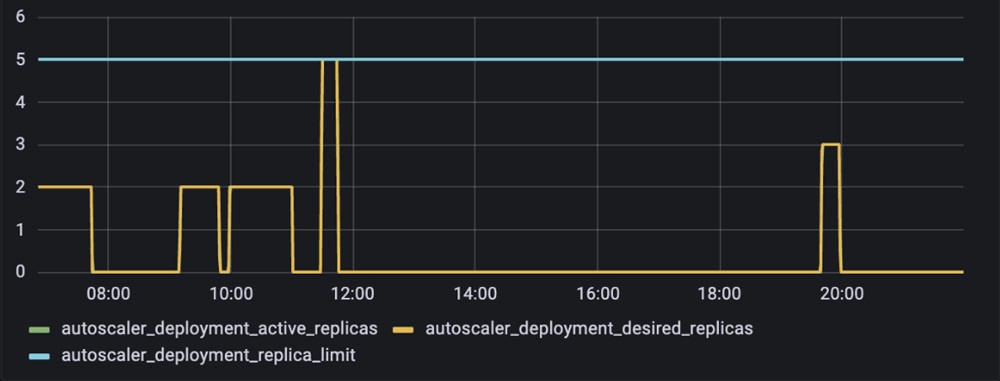
Cluster autoscaling
The PodDisruptionBudget resource protects certain pods against disruption (for example, voluntary restarts) by allowing for the specification of the maximum number of pod replicas that can be unavailable at any given time. As shown in Figure 5, setting this value explicitly to 0 for a deployment ensures that the cluster autoscaler will not downscale nodes running the deployment’s pods.
Implementing this resource on hosted Snorkel Flow instances safely allowed the cluster autoscaler to downscale underutilized nodes. However, the cost savings Snorkel realized were marginal—they were still unable to downscale the majority of their nodes because all Snorkel Flow pods were protected by an associated podDisruptionBudget.
Upon closer examination, Snorkel’s team realized that this protection does not need to exist all of the time. Workloads are bursty, and most user interaction with Snorkel Flow occurs during a customer’s business day, meaning it is safe to relax this protection outside of business hours. Similar to worker autoscaling, Snorkel implemented a recurring function that toggled podDisruptionBudgets “off” overnight for an instance’s flexible pods by setting the maximum number of unavailable pod replicas to 1, up from 0 (Figure 6). The previous worker autoscaling solution combined with the ClusterAutoscaler and PodDisruptionBudget feature was able to downscale many more underutilized worker nodes than before. Customers deploying Snorkel Flow in their cloud can configure this as needed.
Node downscaling optimizations
Even with these improvements, Snorkel saw that a majority of underutilized nodes were not being downscaled at all.
Upon further investigation, Snorkel realized that the issue stemmed from fixed and flexible pods occupying the same node. This was problematic because a fixed pod, pseudo-randomly assigned to a node containing flexible pods, would “pin” that node and prevent it from being downscaled, even when it is underutilized. This lack of control over the scheduling of fixed pods led to periods where the vast majority of the cluster’s nodes could not be downscaled, even though they represented far more compute power than needed at the time.
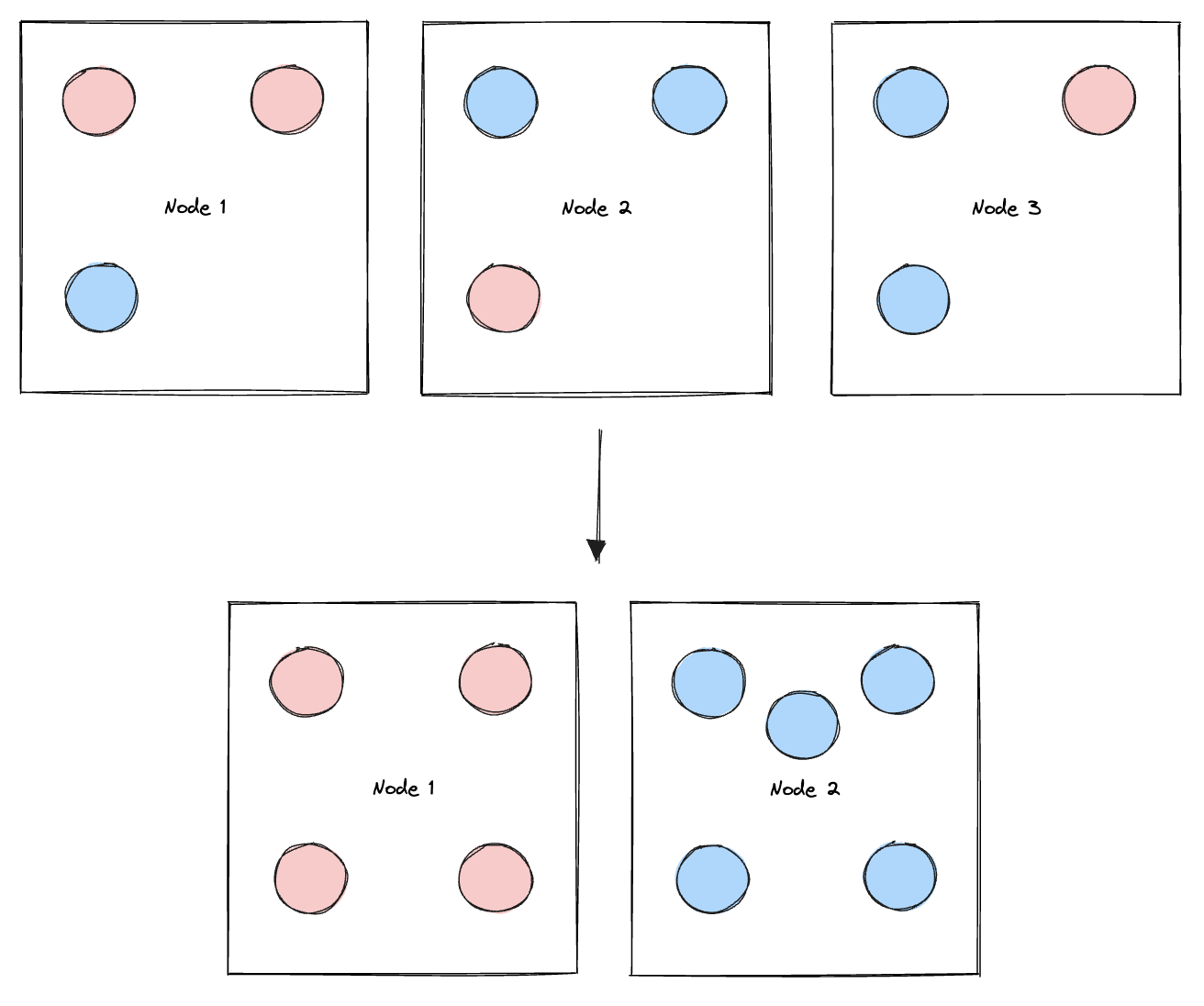
Snorkel leveraged the podAffinities Kubernetes resource to address this, which enabled them to constrain which nodes a pod is eligible to run on based on the labels of other pods already running on any given node. They added labels to the pods to differentiate between fixed versus flexible pods, and added a podAntiAffinity stanza to their deployments configuration to ensure that fixed pods are not scheduled on nodes running flexible pods, and vice versa.
This implementation of podAffinities allowed Snorkel AI to split nodes into two functional groups: the fixed group of nodes containing fixed pods, which can never be safely moved between nodes (for example, Redis due to cache), and the flexible group of nodes containing “flexible” pods that are either ephemeral (such as worker pods) or safe to move outside of business hours (such as overnight).
Although it is possible with manual intervention during platform maintenance, Snorkel cannot automatically downscale the fixed nodes. This solution, however, allows them to automatically downscale the flexible nodes because they have now isolated the unmovable pods into the fixed nodes.
Conclusion
The Snorkel and AWS Startups teams hope that sharing this thought process and these solutions helps other startups to build better infrastructure for ML workloads, which are rapidly becoming more important as ML, large language models, and other FMs make their way into production for organizations all over the world.
Attending AWS re:Invent 2023? This deployment will be highlighted as part of Snorkel’s session Navigating the future of AI: Deploying generative models on Amazon EKS (session CON312). Be sure to check it out!
Many thanks to David Hao, Edmond Liu, and Alec Xiang for helping to make this technical vision a reality for Snorkel. Special thanks to the aforementioned as well as Matt Casey, Henry Ehrenberg, Anthony Bishopric, and the entire Snorkel infrastructure engineering team for their thoughtful feedback on this article.

Ganapathi Krishnamoorthi
Ganapathi Krishnamoorthi는 AWS의 선임 ML 솔루션스 아키텍트입니다. Ganapathi는 스타트업 및 엔터프라이즈 고객이 규모에 따라 클라우드 애플리케이션을 설계하고 배포할 수 있도록 규범적 지침을 제공합니다. 그는 기계 학습을 전문으로 하며 고객이 비즈니스 성과를 위해 AI/ML을 활용할 수 있도록 돕는 데 주력하고 있습니다. 일하지 않을 때는 야외 활동과 음악을 듣는 것을 즐깁니다.
이 콘텐츠는 어떠셨나요?