Cassandra และ HBase แตกต่างกันอย่างไร
Cassandra และ HBase แตกต่างกันอย่างไร?
Apache Cassandra และ HBase เป็นฐานข้อมูล NoSQL สองแบบที่เก็บข้อมูลในรูปแบบที่ไม่ใช่ตาราง ทั้งสองการจัดเก็บข้อมูลเป็นแหล่งเก็บมูลค่าหลักบน Big Data เพื่อจัดการปริมาณข้อมูลขนาดใหญ่ได้อย่างแม่นยำและมีประสิทธิภาพ อย่างไรก็ตามพวกเขามีความแตกต่างทางสถาปัตยกรรมที่เหมาะกับการใช้งานที่แตกต่างกันได้ดียิ่งขึ้น ตัวอย่างเช่น Cassandra จะให้ประสิทธิภาพการอ่านและเขียนที่รวดเร็ว และ HBase ให้มีความสอดคล้องกันของข้อมูลมากขึ้น HBase ก็มีประสิทธิภาพมากในการจัดการชุดข้อมูลขนาดใหญ่และกระจัดกระจาย องค์กรต่าง ๆ ใช้ Cassandra และ HBase สำหรับการใช้งาน Big Data ที่แตกต่างกัน
ข้อคล้ายคลึงระหว่าง Cassandra และ HBase
Cassandra และ HBase เป็นฐานข้อมูล NoSQL สองฐานข้อมูลที่สามารถจัดเก็ บ ประมวลผล และดึงข้อมูลหลายพันล้านชุด ฐานข้อมูลทั้งสองมีข้อที่เหมือนกันในด้านดังต่อไปนี้
แอปพลิเคชั่น Big Data
คุณสามารถจัดเก็บข้อมูลที่ไร้โครงสร้างและไม่สัมพันธ์กันในจำนวนมากๆ ได้ด้วยทั้ง Cassandra และ HBase ระบบเหล่านี้แตกต่างจากระบบฐานข้อมูลแบบดั้งเดิมซึ่งจัดเก็บข้อมูลในแถวคอลัมน์ที่ไม่ซับซ้อน คุณสามารถใช้ Cassandra และ HBase เพื่อจัดเก็บรูปภาพ เสียง วิดีโอ และประเภทของข้อมูลไร้โครงสร้างอื่นๆ เพื่อการประมวลผลขนาดใหญ่ได้
โอเพนซอร์ส
มูลนิธิ Apache Software เป็นผู้เผยแพร่และจัดการ Cassandra และ HBase ในฐานะโครงการโอเพนซอร์ส HBase ได้รับการพัฒนาจากแนวคิดที่นำเสนอโดย Google BigTable และเปิดตัวต่อสาธารณะโดย Apache ในปี 2008 Cassandra เป็นโครงการริเริ่มที่สร้างขึ้นเพื่อใช้แก้ปัญหาในการค้นกล่องข้อความขาเข้าของ Facebook ซึ่งใช้คุณสมบัติเฉพาะของ BigTable และคุณสมบัติอื่นๆ จาก Amazon Dynamo
ความสามารถในการปรับขนาด
คุณสามารถปรับขนาด HBase ให้ตอบสนองต่ออุปสงค์ข้อมูลที่เพิ่มขึ้นได้โดยเพิ่มเซิร์ฟเวอร์ Region เพิ่มเติมลงไปยังคลัสเตอร์ HBase ระบบฐานข้อมูลแบบ NoSQL สามารถกระจายโหนดข้อมูลไปยัง Region ใหม่ได้เมื่อเกินความจุที่กำหนด คลัสเตอร์ของ Cassandra ยังสามารถรองรับโหนดหลายโหนดเพื่อปรับขนาดความสามารถในการจัดการข้อมูลได้อีกด้วย คุณสามารถกระจายข้อมูลได้อย่างเท่าเทียมกัน และป้องกันปัญหาคอขวดในการรับส่งข้อมูลได้อย่างมีประสิทธิภาพด้วยการเพิ่มจำนวนโหนด
การกู้คืนข้อมูล
โหนดข้อมูลในทั้ง Cassandra และ HBase ต่างทนต่อความผิดพลาด ใน Cassandra แต่ละโหนดจะรองรับการจำลองข้อมูล ระบบจะสั่งกระบวนการเขียนไปยังทุกโหนดที่มอบหมายไปยังข้อมูลที่เฉพาะเจาะจงโดยอัตโนมัติ HBase มีกระบวนการทำสำเนาข้อมูลที่คล้ายคลึงกัน โดยทำสำเนาแบบอัตโนมัติบน Hadoop Distributed File System (HDFS) ที่ระบบนี้ทำงานอยู่ HDFS จะสร้างและเก็บรักษาสำเนาข้อมูลไว้บนเซิร์ฟเวอร์ต่างๆ ฐานข้อมูล NoSQL ทั้งสองแบบต่างทำสำเนาโหนดข้อมูลบนเครือข่ายทางกายภาพที่แตกต่างกัน โดยอิงตามปัจจัยการจำลองเพื่อลดความเสี่ยงของการล้มเหลวทั้งเครือข่าย
เขียนเส้นทาง
ทั้ง Cassandra และ HBase ต่างจัดระเบียบข้อมูลเป็นคอลัมน์ ขณะจัดเก็บข้อมูล ฐานข้อมูลแต่ละฐานจะมองหากลุ่มประเภทคอลัมน์ที่เหมาะสมซึ่งเก็บข้อมูลที่เกี่ยวข้องเอาไว้ด้วยกัน ฐานข้อมูลทั้งสองแบบต่างเขียนข้อมูลลงในข้อมูลบันทึกขณะฐานข้อมูลกำลังผนวกหรือจัดเก็บข้อมูลลงในคอลัมน์
ความแตกต่างทางสถาปัตยกรรมระหว่าง Cassandra และ HBase
Cassandra และ HBase ทำงานด้วยลักษณะเฉพาะที่แตกต่างกันตามทฤษฎีบทของ CAP ทฤษฎีบทของ CAP ระบุไว้ว่าระบบกระจายสามารถมีลักษณะสองลักษณะดังต่อไปนี้ได้ทุกเมื่อ:
- ความสอดคล้อง
- ความพร้อมใช้งาน
- ความทนทานต่อพาร์ติชัน
เนื่องจากความทนทานต่อพาร์ติชันเป็นสิ่งจำเป็นยิ่งสำหรับฐานข้อมูลที่จัดเก็บชุดข้อมูลขนาดใหญ่ Cassandra และ HBase จึงมีข้อแตกต่างกันในด้านความพร้อมใช้งานและความสม่ำเสมอ Cassandra มีความพร้อมใช้งานและความทนทานต่อพาร์ติชันสูงเนื่องจากระบบมีการจัดเรียงโหนดแบบ Peer to Peer HBase มีความพร้อมใช้งานและความทนทานต่อพาร์ติชันเพราะใช้ HBase หลักเพียงตัวเดียวจำลองข้อมูลไปยังทุกโหนด
ต่อไปเราจะอธิบายความแตกต่างทางสถาปัตยกรรมเพิ่มเติมว่าด้วยวิธีการที่ฐานข้อมูลทั้งสองแบบจัดการคำขอข้อมูล
โมเดลข้อมูล
ทั้ง Cassandra และ HBase ต่างจัดระเบียบข้อมูลเป็นกลุ่ม แถว และคอลัมน์เหมือน ทว่าแต่ละฐานข้อมูลมีการจัดระเบียบด้วยเค้าโครงที่แตกต่างกัน ใน Cassandra คอลัมน์ของข้อมูลที่เกี่ยวข้องจะถูกเก็บไว้ในแถวภายใต้หมวดหมู่ที่กว้างกว่าที่เรียกว่าค ีย์สเปซ ยกตัวอย่างเช่น ฐานข้อมูล Cassandra อาจมีคีย์สเปซ กลุ่มประเภทคอลัมน์ และการจัดเรียงเซลล์ดังแบบต่อไปนี้:
- คีย์สเปซ: CustomerOrders
- กลุ่มประเภทคอลัมน์: Client
- ID, FirstName, LastName
- กลุ่มประเภทคอลัมน์: Orders
- ID, Item, Price
- กลุ่มประเภทคอลัมน์: Client
กลุ่มประเภทคอลัมน์ Client จะอยู่ในพาร์ติชันที่เหนือกว่ากลุ่มประเภทคอลัมน์ Orders ในการใช้งานจริง คีย์สเปซจะซ้อนทับกลุ่มประเภทคอลัมน์หลายๆ กลุ่มเอาไว้ด้วยกัน
สถาปัตยกรรม HBase มีเค้าโครงที่คล้ายคลึงกับฐานข้อมูลแบบเชิงสัมพันธ์แบบดั้งเดิม HBase จะใช้คีย์ลำดับแถวในตารางแทนที่จะเป็น ID สำหรับแต่ละกลุ่มประเภทคอลัมน์ จากนั้นระบบจะจัดเรียงคอลัมน์ที่อยู่ในกลุ่มประเภทคอลัมน์เดียวกันที่อยู่ถัดจากกันเพื่อให้สามารถดึงข้อมูลได้ง่าย ตัวอย่างมีดังนี้
- Table; CustomerOrders
- คีย์แถว, กลุ่มประเภทคอลัมน์: Client {First Name, LastName}, กลุ่มประเภทคอลัมน์: Order {Item, Price}
อ่านเกี่ยวกับฐานข้อมูลแบบเชิงสัมพันธ์
ส่วนประกอบสำคัญ
Cassandra ใช้เทคนิคที่เรียกว่าแฮชที่ สอดคล้องกัน เพื่อให้แต่ละโหนดสามารถค้นหาข้อมูลเฉพาะได้อย่างรวดเร็วในเครือข่ายเพียร์ทูเพียร์ ส่วนประกอบสำคัญของเทคนิคดังกล่าวประกอบด้วย Memtable, Commit Log และตาราง SS ซึ่งส่วนประกอบดังกล่าวจะประกอบรวมกันเป็นเส้นทางการเขียนสำหรับโหนด ศูนย์ข้อมูล และคลัสเตอร์ในสถาปัตยกรรม Cassandra
HBase จะอยู่บนสุดของ HDFS โดยใช้ HBase หลักเซิร์ฟเวอร์ Region และ Zookeeper เพื่อจัดการข้อมูล
Cassandra ให้บริการการจัดการข้อมูลและการจัดเก็บข้อมูลอย่างอิสระจากกัน ส่วน HBase จำเป็นต้องมีระบบภายนอกสำหรับพื้นที่เก็บข้อมูล
การออกแบบหลัก
Cassandra ทำงานบนสถาปัตยกรรมแบบ Active-Active ซึ่งแต่ละโหนดจะตอบสนองต่อการเขียนและคำขอต่างๆ แม้ว่าโหนดจะไม่ได้จัดเก็บข้อมูลที่ร้องขอ แต่โหนดจะดึงข้อมูลดังกล่าวจากโหนดอื่นด้วยวิธีการสื่อสารแบบ Peer-to-Peer ที่เรียกว่าโปรโตคอลแบบ Gossip
HBase ใช้การตั้งค่าแบบหลัก-รอง โดย HBase หลักจะมีอำนาจควบคุมเหนือเซิร์ฟเวอร์ Region ของโหนดอื่น สถาปัตยกรรม HBase จะมีจุดบกพร่องเพียงจุดเดียวหากไม่มีสำเนาของ HBase primary คุณสามารถทำสำเนาโหนด HBase หลักได้หลายโหนด แต่จะมีเพียงโหนดเดียวเท่านั้นที่รับผิดชอบเซิร์ฟเวอร์ Region ทั้งหมด
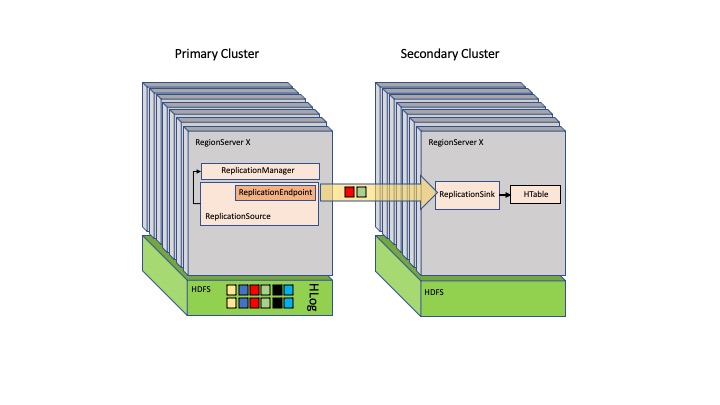
ภาพต่อไปนี้แสดงการตั้งค่าแบบหลัก-รองของ HBase
ภาษาการสืบค้น
Cassandra จะเปิดใช้งานการจัดการข้อมูลในฐานข้อมูลด้วย ภาษาการสืบค้นของ Cassandra (Cassandra Query Language: CQL) คุณสามารถใช้ CQL เพื่อเพิ่ม ลบ หรือข้อมูลบันทึกด้วยคำสั่งเชิงพรรณนาซึ่งคล้ายคลึงกับ SQL ภาษาการสืบค้น HBase ประกอบด้วยคำสั่งเชลล์พื้นฐานซึ่งเรียนรู้ยากกว่า
ประสิทธิภาพ: Cassandra เทียบกับ HBase
ทั้ง Cassandra และ HBase ให้การเข้าถึงชุดข้อมูลขนาดใหญ่ด้วยความเร็วสูงสำหรับการวิเคราะห์ Big Data ฐานข้อมูลจะแสดงข้อแตกต่างด้านประสิทธิภาพในแง่มุมดังต่อไปนี้
เวลาแฝง
ความหน่วง คือช่องว่างระหว่างการส่งคำสั่งไปยังระบบฐานข้อมูลและการจัดเก็บหรือดึงข้อมูล โดยทั่วไปแล้ว HBase จะมีเวลาแฝงต่ำลงเมื่อจำนวนการอ่านและเขียนข้อมูลเพิ่มขึ้น แต่สำหรับ Cassandra จะกลับกัน โดยมีเวลาแฝงมากขึ้นเนื่องจากระบบต้องดึงข้อมูลมากขึ้น
อัตราการโอนถ่ายข้อมูล
ปริมาณงาน วัดจำนวนการอ่านหรือเขียนการทำงานที่ฐานข้อมูลจัดการทุกวินาที HBase จะคงอัตราการโอนถ่ายข้อมูลอย่างสม่ำเสมออยู่ที่ 100,000—200,000 ครั้งต่อวินาที แต่จะมีอัตราที่เพิ่มขึ้นหลังดำเนินงาน 250,000 ครั้ง ส่วนอัตราการโอนถ่ายข้อมูลของ Cassandra จะเพิ่มขึ้นเมื่อมีการเขียนหรืออ่านข้อมูลเพิ่มขึ้น
ประสิทธิภาพการอ่าน
การดำเนินงานอ่านใน Cassandra ประกอบไปด้วยการค้นหาตำแหน่งที่แน่นอนของข้อมูลที่เก็บไว้ในตารางพาร์ติชัน หากการค้นหาเกี่ยวข้องกับคีย์รองหรือตารางที่ไม่ใช่พาร์ติชัน Cassandra จะใช้เวลานานขึ้นเพื่อค้นหาทุกโหนดในคลัสเตอร์ อีกทั้งจะเกิดความไม่สอดคล้องของข้อมูลเกิดขึ้นเมื่อโหนดหลายโหนดมีข้อมูลเดียวกันที่ต่างเวอร์ชันกัน
HBase มีประสิทธิภาพการอ่านที่ดีกว่า Cassandra เนื่องจากระบบจะเขียนข้อมูลทั้งหมดไปยังเซิร์ฟเวอร์เพียงเซิร์ฟเวอร์เดียว การอ่านข้อมูลใน HBase ต่างจาก Cassandra ตรงที่ไม่จำเป็นต้องใช้ระบบฐานข้อมูลเพื่อค้นหาในตารางพาร์ติชัน ระบบ HDFS ที่ HBase ใช้ในการจัดเก็บข้อมูลมีตัวกรองแบบบลูมและแคชแบบบล็อก ซึ่งช่วยเพิ่มความเร็วในการดึงข้อมูล
ประสิทธิภาพการเขียน
Cassandra ดำเนินงานเขียนเสร็จเร็วกว่า HBase คุณสามารถเขียนข้อมูลลงในข้อมูลบันทึกและแคชได้พร้อมกันด้วย Cassandra HBase ไม่รองรับการเขียนพร้อมกัน แต่แอปพลิเคชันไคลเอ็นต์ HBase จะสั่งการผ่าน Zookeeper เพื่อเริ่มกระบวนการเขียน โดย HBase หลักจะเป็นตัวให้ที่อยู่สำหรับจัดเก็บข้อมูล ขั้นตอนเพิ่มเติมของ HBase นี้ทำให้กระบวนการเขียนข้อมูลช้าลง
ความแตกต่างที่สำคัญอื่นๆ ระหว่าง Cassandra กับ HBase
คุณสามารถใช้ได้ทั้ง Cassandra และ HBase เพื่อสร้างแอปพลิเคชันวิทยาศาสตร์ข้อมูล แต่ข้อแตกต่างเล็กน้อยสามารถส่งผลต่อการตัดสินใจเลือกแอปพลิเคชันหนึ่งแทนอีกแอปหนึ่งได้
การรักษาความปลอดภัย
คุณสามารถควบคุมการเข้าถึงในระดับแถวของข้อมูลบันทึกได้ด้วย Cassandra ระบบยังมีการเข้ารหัส SSL เพื่อปกป้องการแลกเปลี่ยนข้อมูลระหว่างโหนดอีกด้วย HBase นั้นต่างกับ Cassandra ตรงที่มีการเข้ารหัสในระดับเซลล์ และคุณสมบัติการเข้ารหัสและการรับรองความถูกต้องเป็นการเพิ่มเติม
การแบ่งพาร์ทิชันข้อมูล
Cassandra รองรับการแบ่งพาร์ติชันตามลำดับ และสามารถสแกนข้อมูลบันทึกที่จัดเรียงตามลำดับโดยใช้คอลัมน์เป็นคีย์พาร์ติชันได้ แม้ว่าคุณสมบัตินี้อาจเป็นประโยชน์ แต่การแบ่งพาร์ติชันตามลำดับทำให้การ Load Balancing ซับซ้อนขึ้น เพราะเกิดการเขียนหลายครั้งในโหนดเดียว ตาราง HBase ไม่รองรับการแบ่งพาร์ติชันตามลำดับ
การสื่อสารของโหนด
ในสถาปัตยกรรมแบบ Cassandra โหนดซีดคือจุดสำคัญในการสื่อสารระหว่างคลัสเตอร์ โหนดเหล่านี้ใช้โปรโตคอลแบบกอสซิปเพื่อโอนย้ายข้อมูลระหว่างคลัสเตอร์ต่างๆ HBase จะใช้โหนด HBase หลักที่ใช้งานอยู่เพื่อประสานการสื่อสารระหว่างเซิร์ฟเวอร์ Region หลายเซิร์ฟเวอร์ โปรโตคอล Zookeeper จะเป็นตัวต่อรองการเคลื่อนย้ายของข้อมูลในสถาปัตยกรรมนี้
เมื่อใดที่ควรใช้ Cassandra เทียบกับ HBase
ฐานข้อมูลของ Cassandra และ HBase สามารถช่วยแอปพลิเคชัน Big Data ได้หลายประเภท ต่อไปเราจะแบ่งปันข้อมูลว่าฐานข้อมูลที่กระจายตัวใดจะทำงานได้ดีกว่ากันในสถานการณ์แบบต่างๆ
ความพร้อมใช้งานเทียบกับความสม่ำเสมอ
Cassandra เหมาะสำหรับกรณีการใช้งานที่ต้องเขียนข้อมูลบ่อยครั้ง แต่ไม่ได้มีการปรับให้เหมาะสมสำหรับการอัปเดตหรือลบข้อมูลบ่อยๆ ยกตัวอย่างเช่น องค์กรต่างๆ ใช้ Cassandra เพื่อสร้างระบบส่งข้อความ โซลูชันการประมวลผลข้อมูลแบบโต้ตอบ และพื้นที่เก็บข้อมูลเซ็นเซอร์แบบเรียลไทม์ HBase จะเหมาะสำหรับสำหรับแอปพลิเคชันที่ต้องการความสอดคล้องกันของข้อมูลและการประมวลผลที่บ่อยมากกว่า ยกตัวอย่างเช่น โซลูชันด้านการธนาคาร การดูแลสุขภาพ และโทรคมนาคม จะใช้งาน HBase เพื่อวิเคราะห์ข้อมูลที่มีจำนวนมาก
การตั้งค่าฐานข้อมูล
Cassandra ตั้งค่าได้ง่ายกว่า เพราะเป็นผลิตภัณฑ์สแตนด์อโลนที่มาพร้อมส่วนประกอบฐานข้อมูลที่จำเป็นทั้งหมด HBase ต่างจาก Cassandra ตรงที่ต้องอาศัยส่วนประกอบหลายอย่างของ Hadoop เช่น Zookeeper, HDFS primary และ HDFS DataNode เพื่อทำงาน การตั้งค่าอาจเป็นเรื่องง่าย แต่การที่ต้องรักษาภาวะพึ่งพาซึ่งกันและกันหลายภาวะอาจท้าทายสำหรับการใช้งานในชีวิตจริง หากคุณใช้โครงสร้างพื้นฐานของ Hadoop อยู่แล้ว คุณอาจพบว่าการโอนย้ายไปยัง HBase ง่ายกว่าการโอนย้ายไปยัง Cassandra
สรุปความแตกต่างระหว่าง Cassandra และ HBase
|
Cassandra |
HBase |
|
|
การออกแบบหลัก |
ใช้สถาปัตยกรรมแบบแอคทีฟ-แอคทีฟ โหนดทั้งหมดจะประมวลผลคำขอแบบอ่าน/เขียน |
ใช้สถาปัตยกรรมขั้นต้นทุติยภูมิ HBase หลัก ควบคุมเซิร์ฟเวอร์ภูมิภาคหลายแห่ง |
|
ส่วนประกอบสำคัญ |
เมมเทเบิล ข้อมูลบันทึกการรับรอง และตาราง SS |
HBase หลัก เซิร์ฟเวอร์ภูมิภาค และ Zookeeper |
|
โมเดลข้อมูล |
จัดเก็บแถวของตระกูลคอลัมน์ที่เกี่ยวข้องในคีย์สเปซ |
ตระกูลคอลัมน์จัดเรียงแนวนอนด้วยคีย์แถวตามลำดับ |
|
ภาษาการสืบค้น |
ใช้ Cassandra Query Language |
ใช้คำสั่งเชลล์ |
|
เวลาแฝง |
เวลาแฝงที่สูงขึ้นพร้อมการดึงข้อมูลมากขึ้น |
เวลาแฝงที่ล่าช้าพร้อมการดำเนินการข้อมูลมากขึ้น |
|
อัตราการโอนถ่ายข้อมูล |
ปริมาณงานเพิ่มขึ้นพร้อมอัตราการโอนถ่ายข้อมูลมากขึ้น |
ปริมาณงานเพิ่มขึ้นหลังจากอัตราการโอนถ่ายข้อมูลมากขึ้น |
|
ประสิทธิภาพการอ่าน |
อ่านช้า หมายถึงตารางพาร์ติชันสำหรับตำแหน่งการอ่าน ความไม่สอดคล้องของข้อมูลอาจเกิดขึ้นได้ |
ประสิทธิภาพการอ่านและความสอดคล้องกันของข้อมูลที่ได้ดีขึ้น |
|
ประสิทธิภาพการเขียน |
ประสิทธิภาพการเขียนที่ได้ดีขึ้น เขียนลงข้อมูลบันทึกและแคชพร้อมกัน |
ขั้นตอนเพิ่มเติม ไปที่ Zookeeper และ HBase หลัก |
|
การรักษาความปลอดภัย |
ควบคุมการเข้าถึงได้ถึงระดับบทบาท |
ควบคุมการเข้าถึงได้ถึงระดับเซลล์ |
|
การแบ่งพาร์ทิชันข้อมูล |
รองรับการแบ่งพาร์ติชันตามลำดับ |
ไม่รองรับการแบ่งพาร์ติชันที่สั่งซื้อ |
|
การสื่อสารของโหนด |
ใช้โปรโตคอลซุบซิบ |
ใช้โปรโตคอล Zookeeper |
AWS จะช่วยเหลือข้อกำหนดของ Cassandra และ HBase ของคุณได้อย่างไร?
Amazon Web Services (AWS) ให้บริการฐานข้อมูลคลาวด์ที่ปรับขนาดได้ ซึ่งคุณสามารถใช้เพื่อใช้เทคโนโลยีวิทยาศาสตร์ข้อมูลได้อย่างมีประสิทธิภาพและราคาย่อมเยา คุณสามารถใช้บริการ AWS ต่อไปนี้แทนการจัดเตรียมโครงสร้างพื้นฐานด้วยตนเอง เพื่อสนับสนุนฐานข้อมูล Cassandra และ HBase ของคุณ:
- Amazon Keyspaces (สำหรับ Apache Cassandra) เป็นบริการฐานข้อมูลออนไลน์สำหรับการเรียก ใช้เวิร์กโหลดของ Cassandra ที่มีประสิทธิภาพสูง คุณสามารถปรับขนาดแอปพลิเคชันด้วย Amazon Keyspaces ในขณะที่ยังคงรักษาเวลาตอบสนองให้อยู่ในมิลลิวินาทีหลักเดียว
- ด้วย Amazon EMR คุณสามารถปรับ ใช้คลัสเตอร์ HBase สำหรับแอปพลิเคชันการประมวลผลข้อมูลขนาดใหญ่ การเรียกใช้ HBase บน EMR ช่วยเพิ่มความสามารถในการกู้คืนข้อมูลโดยการสำรองข้อมูลที่เก็บไว้ใน Amazon Simple Storage Service (Amazon S3)
เริ่มต้นด้วยการวิเคราะห์ข้อมูลขนาดใหญ่บน AWS โดย การสร้างบัญชี วันนี้
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages