การผสาน Amazon Redshift สำหรับ Apache Spark
สร้างแอปพลิเคชัน Apache Spark ที่อ่านและเขียนข้อมูลจาก Amazon Redshift
ทำไมต้องใช้การผสาน Amazon Redshift สำหรับ Apache Spark

ประโยชน์ของ Amazon Redshift
-
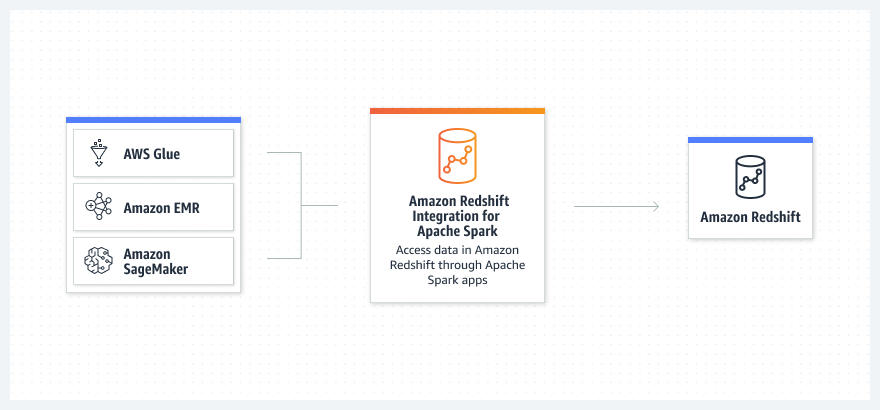
ขยายขอบเขตของแหล่งที่มาของข้อมูลที่คุณสามารถใช้ในแอปพลิเคชันการวิเคราะห์ข้อมูลและแมชชีนเลิร์นนิง (ML) ที่ทำงานใน Amazon EMR, AWS Glue หรือ SageMaker โดยการอ่านและเขียนข้อมูลไปยังคลังข้อมูลของคุณ
-
ปรับปรุงขั้นตอนที่ยุ่งยากและมักดำเนินการด้วยตนเองในการตั้งค่าตัวเชื่อมต่อที่ไม่ผ่านการรับรองและไดรเวอร์ JDBC ลดเวลาการเตรียมการสำหรับการวิเคราะห์และงาน ML
-
ใช้ความสามารถแบบพุชดาวน์หลายอย่าง เช่น ฟังก์ชันการเรียงลำดับ การรวม การจำกัด การรวม และสเกลาร์ เพื่อให้ย้ายเฉพาะข้อมูลที่เกี่ยวข้องจากคลังข้อมูล Amazon Redshift
วิธีทำงาน
กรณีการใช้งาน
-
สร้างแอปพลิเคชัน Apache Spark ใน Java, Scala และ Python ด้วย Apache Spark ตามบริการการวิเคราะห์ AWS
-
อ่านและเขียนข้อมูลไปยังและจาก Amazon Redshift ด้วย Amazon EMR, AWS Glue, SageMaker และการวิเคราะห์ AWS และบริการ ML
-
ใช้ Amazon EMR หรือ AWS Glue เพื่อรับโค้ดเฟรมข้อมูลจากงาน Apache Spark หรือโน้ตบุ๊กและเชื่อมต่อกับ Amazon Redshift
-
ปรับปรุงกระบวนการของคุณโดยไม่ต้องติดตั้งหรือทดสอบ เพิ่มการรักษาความปลอดภัย (ข้อมูลประจำตัวที่ใช้ IAM) และการปิดการทำงาน และรูปแบบไฟล์ Parquet เพื่อประสิทธิภาพ
ลูกค้า
Corey Johnson ผู้จัดการฝ่ายสถาปนิกข้อมูล - Huron Consulting
Huron คือบริษัทผู้ให้บริการมืออาชีพระดับโลกที่ทำงานร่วมกับลูกค้าเพื่อทำให้ทุกสิ่งเป็นไปได้โดยการสร้างกลยุทธ์ที่เหมาะสม ปรับเปลี่ยนการปฏิบัติงานให้เหมาะสม เร่งการเปลี่ยนผ่านสู่ระบบดิจิทัล และให้ธุรกิจและบุคลากรของธุรกิจมีอำนาจที่จะเป็นเจ้าของอนาคตตัวเอง
"เราให้อำนาจวิศวกรของเราในการสร้างไปป์ไลน์ข้อมูลและแอปพลิเคชันด้วย Apache Spark โดยใช้ Python และ Scala เราต้องการโซลูชันที่ปรับให้เหมาะกับลูกค้าซึ่งลดความซับซ้อนของการดำเนินงานและส่งมอบได้เร็วขึ้นและมีประสิทธิภาพมากขึ้นสำหรับลูกค้าของเรา และนั่นคือสิ่งที่เราได้รับจากการผสาน Amazon Redshift ใหม่สำหรับ Apache Spark"
Alcuin Weidus สถาปนิกข้อมูลใหญ่ระดับอาวุโส - GE Aerospace
GE Aerospace เป็นผู้ให้บริการระดับโลกด้านเครื่องยนต์ไอพ่น ส่วนประกอบ และระบบสำหรับเครื่องบินพาณิชย์และอากาศยานทางการทหาร บริษัทได้ออกแบบ พัฒนา และผลิตเครื่องยนต์ไอพ่นตั้งแต่สงครามโลกครั้งที่ 1
“GE Aerospace ใช้การวิเคราะห์ของ AWS และ Amazon Redshift เพื่อเปิดใช้งานข้อมูลเชิงลึกทางธุรกิจที่สำคัญซึ่งขับเคลื่อนการตัดสินใจทางธุรกิจที่สำคัญ ด้วยการรองรับการคัดลอกอัตโนมัติจาก Amazon S3 เราสามารถสร้างไปป์ไลน์ข้อมูลที่ง่ายขึ้นเพื่อย้ายข้อมูลจาก Amazon S3 ไปยัง Amazon Redshift ได้ สิ่งนี้ช่วยเร่งความสามารถของทีมผลิตภัณฑ์ข้อมูลของเราในการเข้าถึงข้อมูลและให้ข้อมูลเชิงลึกแก่ผู้ใช้ปลายทาง เราจึงใช้เวลาได้มากขึ้นในการเพิ่มมูลค่าผ่านข้อมูลและใช้เวลาได้น้อยลงในการผสาน”
Neema Raphael ประธานเจ้าหน้าที่ฝ่ายข้อมูล - Goldman Sachs
Goldman Sachs Group, Inc. เป็นสถาบันทางการเงินชั้นนำระดับโลกที่ให้บริการทางการเงินที่หลากหลายในวาณิชธนกิจ หลักทรัพย์ การจัดการการลงทุน และการธนาคารเพื่อผู้บริโภคแก่ฐานลูกค้าขนาดใหญ่และหลากหลาย ซึ่งรวมถึงองค์กร สถาบันการเงิน รัฐบาล และบุคคลทั่วไป
"สิ่งที่เรามุ่งเน้นคือการให้บริการการเข้าถึงข้อมูลแบบบริการตนเองสำหรับผู้ใช้ทุกคนที่ Goldman Sach ด้วย Legend ซึ่งเป็นแพลตฟอร์มการจัดการข้อมูลแบบโอเพนซอร์สและการกำกับดูแล เราช่วยให้ผู้ใช้สามารถพัฒนาแอปพลิเคชันที่เน้นข้อมูลเป็นศูนย์กลางและรับข้อมูลเชิงลึกที่ขับเคลื่อนด้วยข้อมูลในขณะที่เราทำงานร่วมกันในอุตสาหกรรมบริการทางการเงินได้ และด้วยการผสาน Amazon Redshift สำหรับ Apache Spark ทีมแพลตฟอร์มข้อมูลของเราจะสามารถเข้าถึงข้อมูล Amazon Redshift ได้ด้วยขั้นตอนที่ต้องดำเนินการด้วยตนเองเพียงเล็กน้อย ทำให้สามารถใช้ ETL แบบไม่มีโค้ดได้ ซึ่งจะเพิ่มความสามารถของเราเพื่อให้วิศวกรสามารถมุ่งเน้นไปที่การปรับปรุงเวิร์กโฟลว์ให้สมบูรณ์แบบได้ง่ายขึ้นในระหว่างที่รวบรวมข้อมูลที่ครบถ้วนและทันเวลา เราคาดหวังว่าจะได้เห็นการปรับปรุงประสิทธิภาพของแอปพลิเคชันและการรักษาความปลอดภัยที่ดีขึ้น เนื่องจากผู้ใช้ของเราสามารถเข้าถึงข้อมูลล่าสุดใน Amazon Redshift ได้อย่างง่ายดาย”
วันนี้คุณพบสิ่งที่กำลังมองหาแล้วหรือยัง
การแจ้งให้เราทราบจะช่วยให้เราปรับปรุงคุณภาพของเนื้อหาในหน้าได้