Wie war dieser Inhalt?
Automatisieren der Verarbeitung unstrukturierter Daten mit Amazon SageMaker
von Nikhil Dinesh, Head of Startup Business Development, DACH-Region, AWS, und Sayon Saha, Machine Learning Specialist Solutions Architect, AWS
Unstrukturierte Daten wie Bilder, Videos und Text, die in E-Commerce-Produktangeboten erscheinen, haben erhebliche Auswirkungen auf die Konversionsrate. Eine Studie von eBay Research ergab, dass übergroße Bilder die Konversionsrate um 15,3 % steigern können, wobei andere Faktoren wie die Anzahl der Fotos und der Zustand der Artikel eine wichtige Rolle spielen. Marktplätze und Verkäufer müssen die Konversionsrate auf der Grundlage einer Reihe von unbefristeten Faktoren optimieren, die von den Marketingteams festgelegt werden. Der Einsatz von Datenwissenschaft und Machine Learning (ML) zur Lösung dieses Problems ist nicht neu: AWS hat mehrere Services entwickelt, die bei den undifferenzierten Aspekten von ML helfen, wie Amazon Rekognition (für Bilder und Videos), Amazon Comprehend (für Text), Amazon SageMaker (für Modellentwicklung und Bereitstellung) und Amazon SageMaker GroundTruth (für Datenannotation).
Super.AI, ein in Berlin ansässiges Startup, ist der Ansicht, dass es eine große Chance gibt, diese Bausteine auf die richtige Weise und mit der richtigen Benutzererfahrung für das, was sie als unstrukturierte Datenverarbeitung (UDP) bezeichnen, in verschiedenen Branchen zusammenzufügen. Laut Gartner sind 80 % der Daten in einem typischen Unternehmen unstrukturiert. Die Plattform von Super.AI extrahiert umsetzbare Informationen aus unstrukturierten Daten und ermöglicht es Unternehmen, komplexe Geschäftsprozesse zu automatisieren. Brad Cordova, mehrfacher KI-Unternehmer und Gründer/CEO von super.AI: „Kunden aus den Bereichen E-Commerce, TIC (Testing, Inspection, and Certification) Services, Versicherungen, Gesundheitswesen, Fertigung und Landwirtschaft nutzen die Plattform super.AI, um komplexe Anwendungsfälle wie die Qualitätsbewertung von Produktlisten, visuelle Inspektion, Erkennung von Fahrzeugschäden und Bewertung von Ernteerträgen zu automatisieren. Unsere Kunden erzielen einen erheblichen ROI durch reduzierten Zeit- und Kostenaufwand, weniger Fehler und eine höhere Kundenzufriedenheit.“
In diesem Artikel erfahren Sie, wo Datenerfassung, Vorbeschriftung, die aktive Lernpipeline und das unterstützte Labeling in Echtzeit in der Architektur von super.AI auf AWS liegen. Anschließend werden die Ziele, Risiken und Verbesserungsmöglichkeiten erörtert.
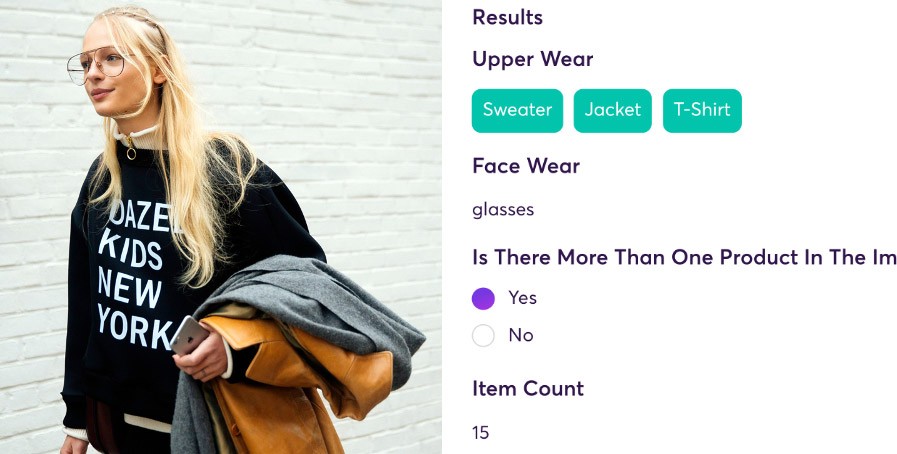

Die Plattform für die Verarbeitung unstrukturierter Daten von super.AI
Die Plattform super.AI hilft Kunden dabei, Prozesse mit unstrukturierten Daten wie Bildern, Videos, Text, Dokumenten und Audio zu transformieren und sie mithilfe einer Kombination aus KI, Software und Menschen zu automatisieren. Diese Demo zur Kategorisierung von Produktbildern von super.AI zeigt, wie die Kategorisierung von Produktbildern mit super.AI Einzelhändlern dabei helfen kann, die Konversation auf der Website zu erhöhen.
Aktives Lernen und Vorbeschriftungen
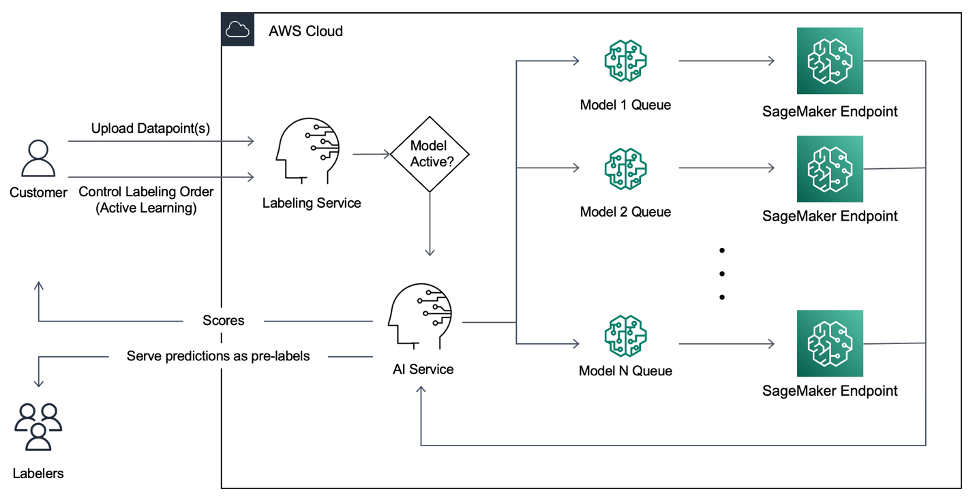
Die Kunden von super.AI wünschten sich einen effizienteren, hochgenaueren Labeling-Mechanismus. Deshalb haben sie kürzlich eine neue Funktion namens „Aktives Lernen“ and Vorbeschriftung veröffentlicht, bei der die Pipeline Datenpunkte mithilfe eines ML-Modells, das auf SageMaker läuft, Vorverarbeitungen durchführt. Diese Lösung priorisiert die Kennzeichnung von Datenpunkten, die für das Modell am nützlichsten sind. Das ML-Modell wird über alle hochgeladenen Datenpunkte ausgeführt, um eine Ausgabe zu generieren, z. B. eine Zuversichtlichkeitsbewertung die verwendet wird, um die Datenpunkte priorisiert bereitzustellen. Vorbeschriftungen werden nach Möglichkeit generiert und dem menschlichen Beschrifter zur Überprüfung oder Bearbeitung zur Verfügung gestellt.
Die Pipeline skaliert dann mit der Nachfrage. Kunden können Daten über API (oder UI) hochladen und mehrere Modelle für aktives Lernen und das Labeling anwenden. Kunden können aus einer Auswahl von Modellen wählen, die von super.AI bereitgestellt werden, oder ihr eigenes Modell mitbringen. Super.AI verwendet die vom ML-Modell generierte Zuversichtlichkeitsbewertung, um die Datenpunkte zu priorisieren und sie effizienter zu bedienen. Bei Bedarf können menschliche Beschrifter vom System generierte Vorbeschriftungen verwenden, um die Daten von Hand genau zu kennzeichnen.
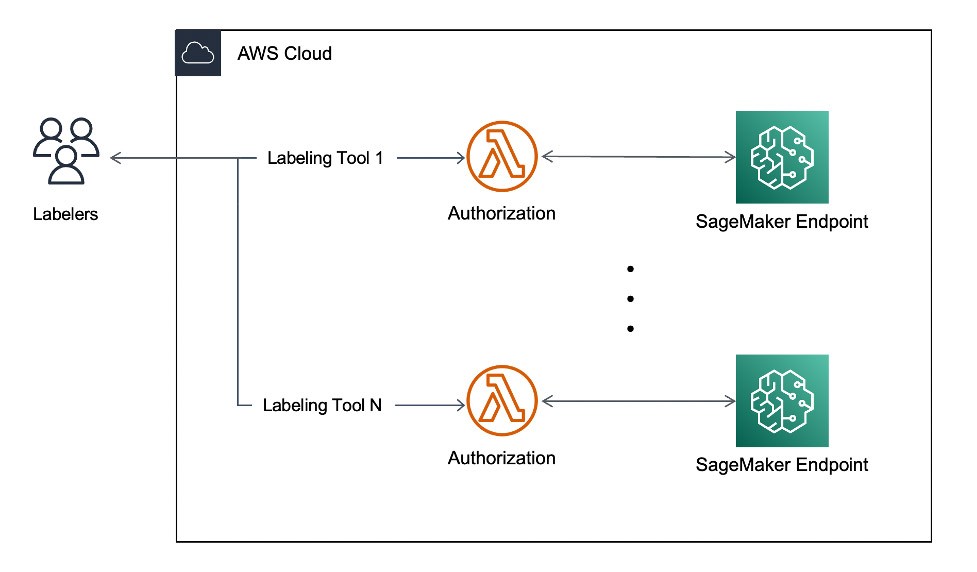
Unterstützte Labels in Echtzeit
Die Plattform nutzt eine Serverless-Architektur mit SageMaker. Die Kunden müssen diesen Service in Echtzeit haben, um ihre Bilder zu kennzeichnen. Das Tool nutzt AWS Lambda in Kombination mit Amazon-SageMaker-Endpunkten, um gleichzeitige Anfragen in Echtzeit mit einer Antwortzeit von unter 10 Sekunden zu bearbeiten. Sie können die Image-Tagging-Anwendung von super.AI in deren Online-Dokumentation erkunden.
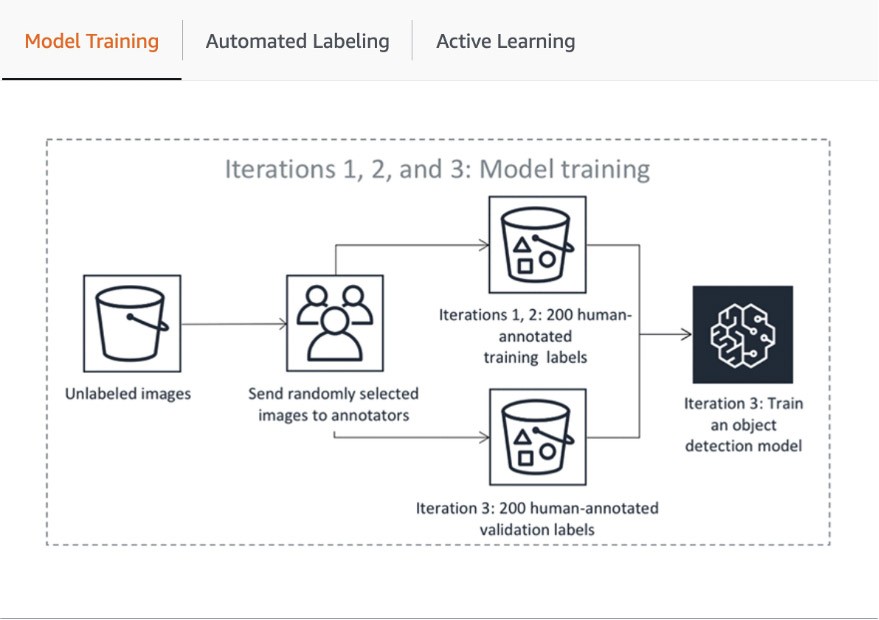
Aufbauen einer Pipeline des aktiven Lernens mit Amazon SageMaker GroundTruth
SageMaker Ground Truth ist ein verwalteter Daten-Labeling-Service zur Erstellung großer, genau beschrifteter ML-Datensätze mit verschiedenen Personaloptionen. Zusammen mit den verschiedenen integrierten und benutzerdefinierten Workflows zum Daten-Labeling für Text, Bild, Videos und 3D-Punktwolken können Sie damit eine automatisierte Daten-Labeling-Pipeline mit aktivem Lernen erstellen, indem Objekte automatisch mit relevanten ML-Modellen annotiert und Objekte zugewiesen werden, deren Sicherheit für menschliche Annotationen geringer ist.
Im ersten Schritt der Pipeline sendet SageMaker Ground Truth eine zufällige Probe von Datensätzen zur menschlichen Annotation, um das für das automatische Labeling verwendete Modell zu trainieren und zu validieren. Die Zuversichtlichkeitsbewertung und die Qualitätskennzahl des trainierten Modells in den Validierungsdaten werden mit dem Schwellenwert verglichen, der für die Entscheidung über die Qualitätslabels für die Annotation des restlichen Datensatzes erforderlich ist. Je nachdem, ob die Zuverläaasigkeitsbewertung den gewünschten Schwellenwert erreicht, wird ein Objekt entweder als automatisch beschriftet betrachtet oder zur Kommentierung an die Mitarbeiter gesendet. Diese Anmerkungen werden wiederum verwendet, um das Modell für die automatische Kennzeichnung zu aktualisieren und zu verbessern. Diese aktive Lernpipeline setzt die Verarbeitung fort, bis der erforderliche Datensatz vollständig beschriftet ist oder eine andere Stoppbedingung erfüllt ist (Weitere Informationen finden Sie in diesem Artikel zur Automatisierung des Daten-Labeling). Der Prozess des aktiven Lernens wird in der folgenden Abbildung veranschaulicht:
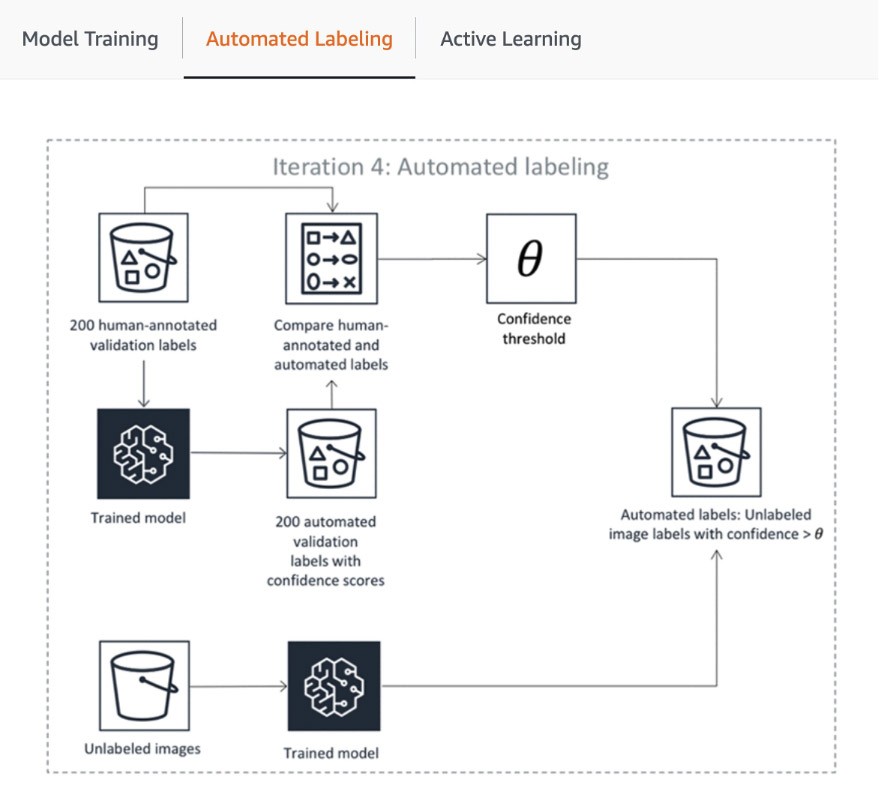
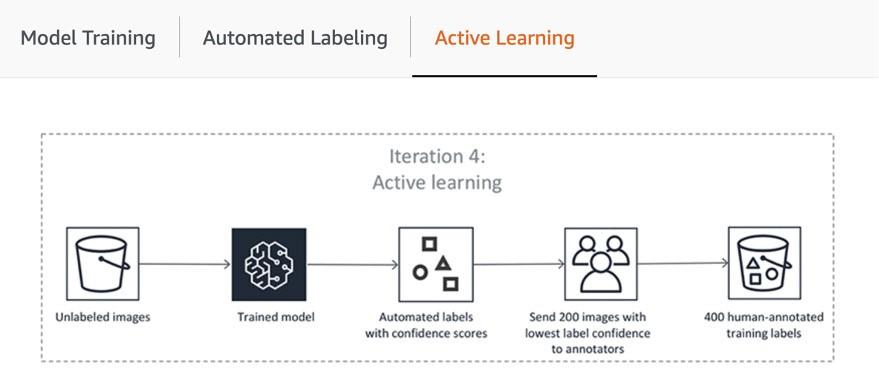
Während viele AWS-Kunden einfach die integrierten ML-Modelle verwenden, können Sie mit SageMaker Ground Truth Ihre eigenen Modelle mitbringen, wenn Sie einen benutzerdefinierten Anwendungsfall haben. Weitere Informationen dazu finden Sie im Blog „Bring Your Own Model for Amazon SageMaker Labeling Workflows with Active Learning“ (Bringen Sie Ihr eigenes Modell für Amazon-SageMaker-Labeling-Workflows mit aktivem Lernen).
Die Technik des aktiven Lernens beschleunigt den Prozess des Daten-Labeling erheblich, indem die Teilmenge der Daten identifiziert wird, die Ihre Beschrifter kennzeichnen sollten. Das reduziert auch die Personalkosten erheblich, indem die Genauigkeit der Anmerkungen hoch bleibt. Ein Beispiel für einen Anwendungsfall eines Objekterkennungsauftrags mit automatisiertem Daten-Labeling finden Sie im Blog „Kommentieren von Daten für weniger Geld mit Amazon SageMaker Ground Truth und automatisiertem Daten-Labeling“.
Zusammenfassung
In den letzten Jahren war robotergesteuerte Prozessautomatisierung (RPA) eine der am schnellsten wachsenden Softwarekategorien, da Unternehmen die digitale Transformation anstreben. 80 % der Unternehmensdaten sind jedoch unstrukturiert und können nicht automatisiert werden. Neue Lösungen für die Verarbeitung unstrukturierter Daten von Unternehmen wie super.AI, die AWS-ML-Services nutzen, helfen Unternehmen dabei, den Automatisierungsumfang erheblich zu erweitern, indem sie verwertbare Informationen aus unstrukturierten Daten (Bildern, Videos, Audio, Dokumenten und Text) extrahieren. Solche Plattformen können eine Vielzahl von Anwendungsfällen abdecken, von der visuellen Inspektion bis hin zur Qualitätsbewertung von Online-Produktangeboten mit minimalem menschlichem Eingreifen. Frühzeitige Anwender solcher Plattformen verschaffen sich einen Wettbewerbsvorteil, der die Kosten senkt, Fehler reduziert und ein differenziertes Kundenerlebnis bietet.

AWS Editorial Team
Das Content Marketing Team von AWS Startups arbeitet mit Startups aller Größen und Branchen zusammen, um außergewöhnliche Inhalte bereitzustellen, die informieren, unterhalten und inspirieren.
Wie war dieser Inhalt?