Com'era questo contenuto?
Automatizzazione dell'elaborazione di dati non strutturati con Amazon SageMaker
di Nikhil Dinesh, Head of Startup Business Development, regione DACH, AWS, e Sayon Saha, Machine Learning Specialist Solutions Architect, AWS
I dati non strutturati come immagini, video e testo che appaiono negli elenchi di prodotti di e-commerce hanno un impatto significativo sul tasso di conversione. Uno studio di ricerca condotto da eBay ha rilevato che le immagini di grandi dimensioni possono aumentare la conversione del 15,3%, con altri fattori come il numero di foto e le condizioni dell'articolo che svolgono un ruolo significativo. I marketplace e i venditori devono ottimizzare la conversione sulla base di una serie indefinita di fattori determinati dai team di marketing. L'utilizzo del data science e del machine learning (ML) per risolvere questo problema non è una novità: AWS ha creato diversi servizi per facilitare gli aspetti non differenziati del machine learning, come Amazon Rekognition (per immagini e video), Amazon Comprehend (per testi), Amazon SageMaker (per lo sviluppo e l'implementazione di modelli) e Amazon SageMaker GroundTruth (per l'annotazione dei dati).
super.AI, una startup con sede a Berlino, ritiene che ci sia una grande opportunità nel riunire tutti questi tasselli nel modo giusto e con la giusta esperienza utente verso ciò che chiamano elaborazione di dati non strutturati (UDP) in vari settori. Secondo Gartner, l'80% dei dati in un'azienda classica non è strutturato. La piattaforma di super.AI estrae informazioni utilizzabili da dati non strutturati, consentendo alle aziende di automatizzare processi aziendali complessi. Secondo Brad Cordova, imprenditore seriale nel settore dell'intelligenza artificiale e fondatore/CEO di super.AI: "I clienti nell'ambito di e-commerce, servizi TIC (testing, ispezione e certificazione), assicurazioni, sanità, produzione e agricoltura utilizzano la piattaforma super.AI per automatizzare casi d'uso complessi come la valutazione della qualità dell'offerta dei prodotti, l'ispezione visiva, il rilevamento dei danni ai veicoli e la valutazione della resa dei raccolti. I nostri clienti stanno ottenendo un ROI importante grazie a tempi e costi ridotti, meno errori e una maggiore soddisfazione dei clienti".
Questo articolo ti mostrerà dove rientrano l'importazione dei dati, la pre-etichettatura, la pipeline dell'apprendimento attivo e l'etichettatura assistita in tempo reale nell'architettura super.AI su AWS, seguito da una discussione sugli obiettivi, i rischi e dove vediamo opportunità di miglioramento.
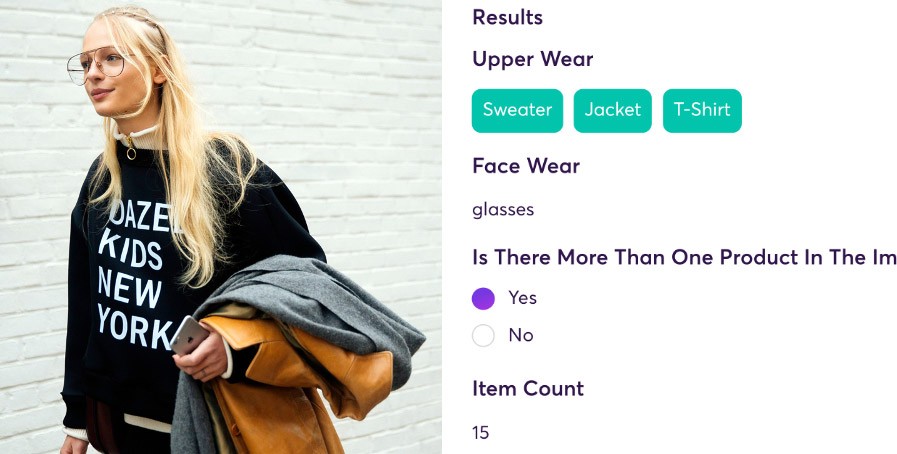

Piattaforma per l'elaborazione dei dati non strutturati di super.AI
La piattaforma super.AI aiuta i clienti a trasformare i processi che coinvolgono dati non strutturati come immagini, video, testi, documenti e audio e ad automatizzarli utilizzando un connubio tra intelligenza artificiale, software e umani. Questa demo sulla classificazione delle immagini dei prodotti di super.AI mostra come la classificazione delle immagini dei prodotti super.AI sia in grado di aiutare i rivenditori ad aumentare le conversioni sul sito web.
Apprendimento attivo e pre-etichettatura
I clienti di super.AI hanno richiesto un meccanismo di etichettatura più efficiente e altamente accurato. Pertanto, di recente è stata distribuita una nuova funzionalità chiamata Apprendimento attivo e Pre-etichettatura, in cui la pipeline pre-elabora i punti dati utilizzando un modello ML in esecuzione su SageMaker. Questa soluzione dà priorità all'etichettatura dei punti dati più utili per il modello. Il modello ML viene eseguito su tutti i punti dati caricati per generare un output, ad esempio un punteggio di affidabilità, utilizzato per fornire i punti dati in modo prioritario. Le pre-etichette vengono generate ove possibile e fornite all'etichettatore umano per la revisione o la modifica.
La pipeline viene quindi dimensionata in base alla domanda. I clienti possono caricare dati tramite API (o interfaccia utente) e applicare più modelli per l'apprendimento attivo e la pre-etichettatura. I clienti possono scegliere tra una selezione di modelli forniti da super.AI o fornire il proprio modello. super.AI utilizza il punteggio di affidabilità generato dal modello ML per dare priorità ai punti dati e offrirli in modo più efficiente. Se necessario, gli etichettatori umani possono utilizzare le pre-etichette generate dal sistema per etichettare accuratamente i dati a mano.
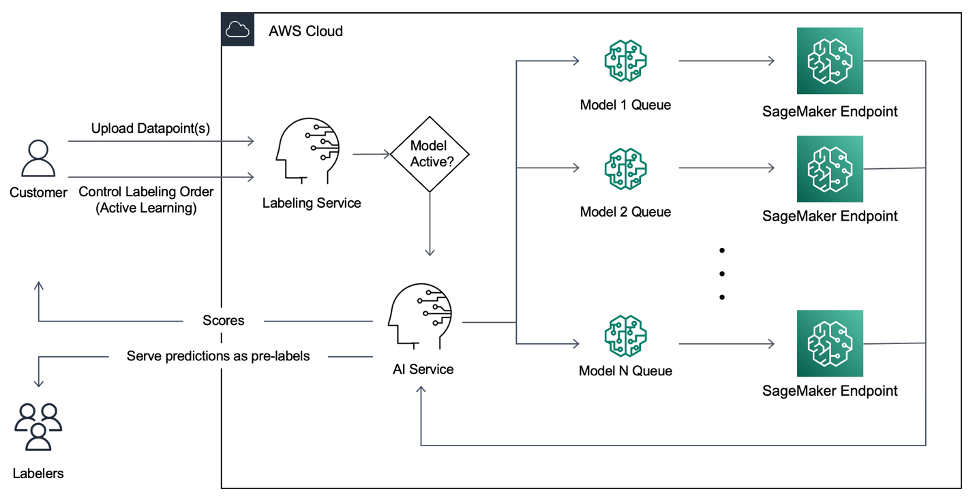
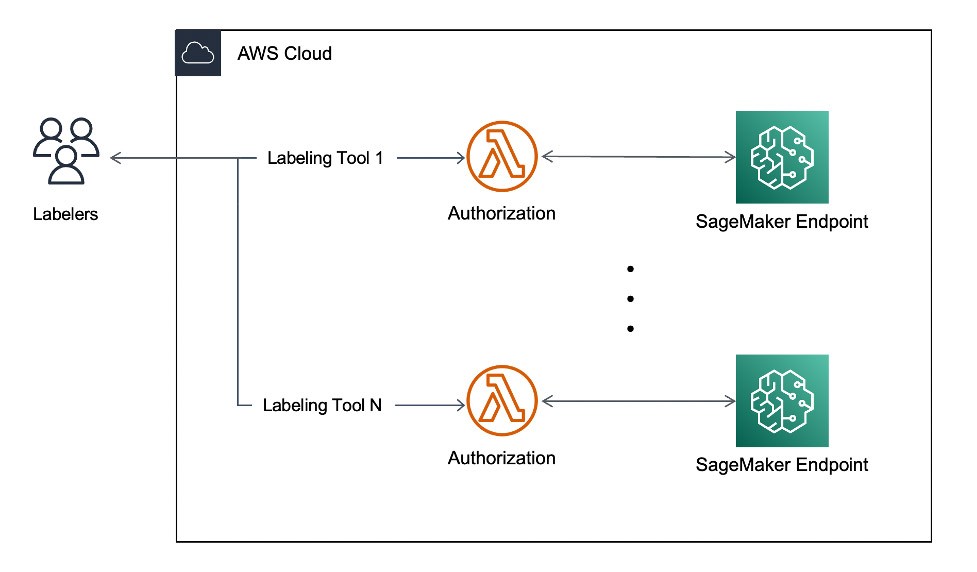
Etichettatura assistita in tempo reale
La piattaforma utilizza un'architettura serverless con SageMaker. I clienti devono disporre di questo servizio in tempo reale per etichettare le proprie immagini. Lo strumento utilizza AWS Lambda in abbinamento a Amazon SageMaker Endpoints per servire richieste simultanee in tempo reale con tempi di risposta inferiori a 10 secondi. Puoi approfondire l'applicazione di etichettatura delle immagini di super.AI dalla documentazione online.
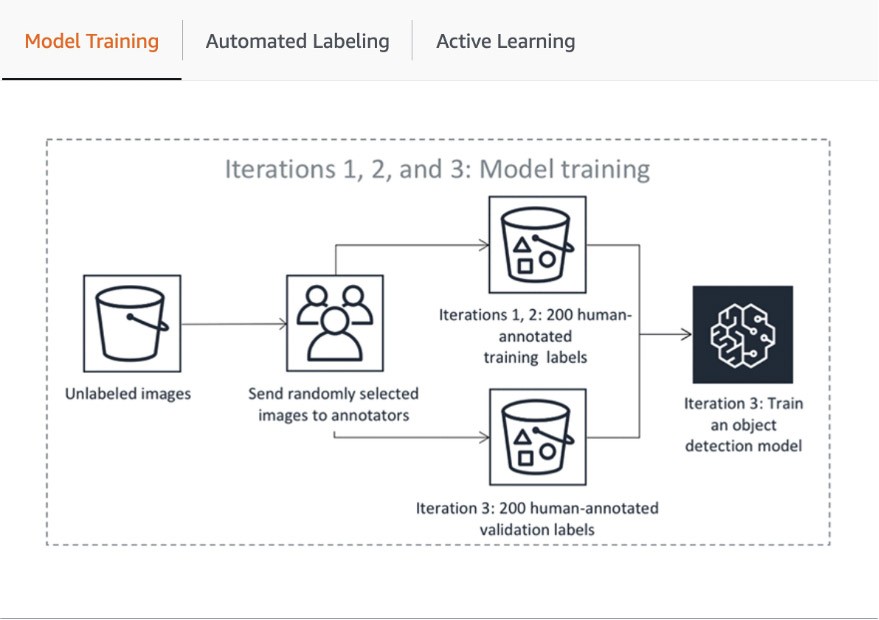
Creare una pipeline di apprendimento attivo con Amazon SageMaker GroundTruth
SageMaker Ground Truth è un servizio gestito di etichettatura dei dati per creare set di dati ML su larga scala etichettati con precisione con diverse opzioni per la forza lavoro. Insieme ai vari flussi di lavoro di etichettatura dei dati integrati e personalizzati per testi, immagini, video e nuvole di punti 3D, consente di creare una pipeline automatizzata di etichettatura dei dati con apprendimento attivo annotando automaticamente gli oggetti con modelli ML pertinenti e assegnando oggetti con minore affidabilità all'annotazione umana.
La prima fase della pipeline include l'invio da parte di SageMaker Ground Truth di un campione casuale di set di dati per l'annotazione umana per istruire e convalidare il modello utilizzato per l'etichettatura automatica. Il punteggio di affidabilità e la metrica di qualità degli output del modello istruito nei dati di convalida vengono confrontati con la soglia per decidere le etichette di qualità per annotare il resto del set di dati. A seconda che il punteggio di affidabilità soddisfi la soglia desiderata, un oggetto viene considerato etichettato automaticamente o inviato alla forza lavoro umana per l'annotazione. Queste annotazioni, a loro volta, vengono utilizzate per aggiornare e migliorare il modello di etichettatura automatica. Questa pipeline di apprendimento attivo continua a elaborare fino a quando il set di dati richiesto non viene completamente etichettato o viene soddisfatta un'altra condizione di interruzione (scopri di più in questo articolo per automatizzare l'etichettatura dei dati). Il processo di apprendimento attivo viene illustrato nel seguente diagramma:
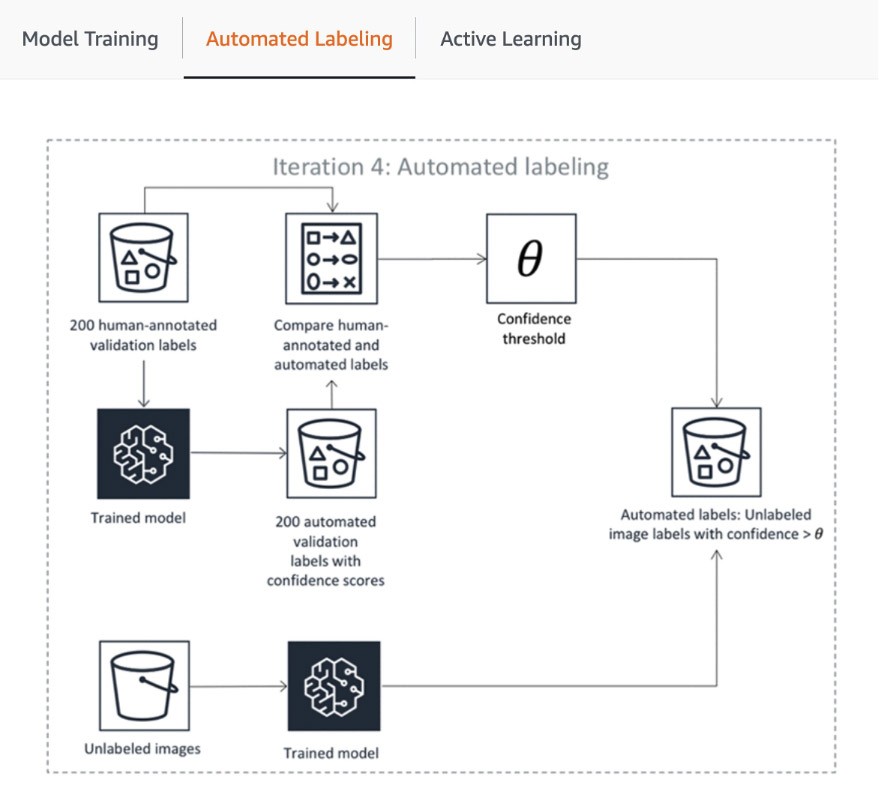
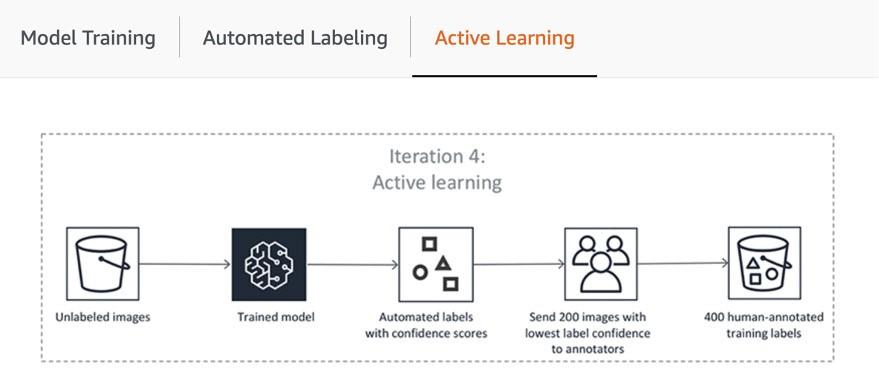
Sebbene molti clienti AWS utilizzino soltanto i suoi modelli ML integrati, SageMaker Ground Truth ti consente di portarne uno tuo se hai un caso d'uso personalizzato. Per maggiori informazioni consulta il blog "Porta il tuo modello per i flussi di lavoro di etichettatura di Amazon SageMaker con apprendimento attivo".
La tecnica di apprendimento attivo rende il processo di etichettatura dei dati molto più veloce identificando il sottoinsieme di dati che gli etichettatori devono etichettare. Inoltre, riduce notevolmente il costo della forza lavoro mantenendo elevata la precisione delle annotazioni. Nel blog "Raccolta dati meno impegnativa con Amazon Sagemaker Ground Truth ed etichettatura automatica dei dati" trovi un esempio di caso d'uso relativo al processo di rilevamento oggetti con etichettatura automatica dei dati.
Conclusioni
Negli ultimi anni, l'automazione robotica dei processi (RPA) è stata una delle categorie di software in più rapida crescita mentre le aziende si impegnano per ottenere la trasformazione digitale. Tuttavia, l'80% dei dati aziendali non è strutturato ed è inaccessibile per l'automazione. Le soluzioni emergenti di elaborazione dei dati non strutturati di aziende come super.AI che sfruttano i servizi di ML di AWS stanno aiutando le aziende a espandere notevolmente l'ambito dell'automazione estraendo informazioni utilizzabili da dati non strutturati: immagini, video, audio, documenti e testi. Tali piattaforme possono affrontare un'ampia gamma di casi d'uso, dall'ispezione visiva alla valutazione della qualità dell'offerta dei prodotti online con un intervento umano minimo. I primi adattatori di tali piattaforme stanno acquisendo un vantaggio competitivo che riduce i costi, riduce gli errori e offre un'esperienza cliente differenziata.

AWS Editorial Team
Il team Content Marketing di Startup AWS collabora con startup di varie dimensioni e in ogni settore, al fine di sviluppare contenuti eccezionali che siano informativi, coinvolgenti e autentici fonti di ispirazione.
Com'era questo contenuto?