المدوَّنة العربية
نماذج فهم الفيديو من TwelveLabs متاحة الآن في Amazon Bedrock
في وقت سابق من هذا العام، أعلنا عن قدوم نماذج فهم الفيديو من TwelveLabs إلى Amazon Bedrock. واليوم، يسرنا الإعلان عن إتاحة هذه النماذج للاستخدام، حيث تقدم قدرات متقدمة في البحث داخل مقاطع الفيديو وتصنيف المشاهد وتلخيصها واستخراج الرؤى بدقة وموثوقية عالية.
قدمت TwelveLabs نموذجين متميزين: نموذج Marengo، المتخصص في مهام البحث والتصنيف، ونموذج Pegasus، القادر على إنشاء نص استناداً إلى محتوى الفيديو. تم تدريب هذه النماذج على Amazon SageMaker HyperPod لتقديم تحليل فيديو متقدم يشمل إنشاء ملخصات نصية وبيانات وصفية وتحسينات إبداعية.
مع نماذج TwelveLabs في Amazon Bedrock، يمكنكم البحث عن لحظات محددة في الفيديو باستخدام اللغة الطبيعية، مثل “أرني الهدف الأول في المباراة” أو “ابحث عن المشهد الذي يلتقي فيه الشخصيات الرئيسية لأول مرة”. كما يمكنكم بناء تطبيقات لفهم محتوى الفيديو من خلال إنشاء محتوى نصي وصفي مثل العناوين والمواضيع والهاشتاغات والملخصات والفصول أو النقاط البارزة، واكتشاف رؤى وروابط جديدة دون الحاجة إلى تصنيفات مسبقة.
على سبيل المثال، يمكنكم تحليل ملاحظات العملاء المصورة لاكتشاف المواضيع المتكررة أو فهم أنماط استخدام المنتج التي لم تكن واضحة من قبل. وسواء كان لديكم مئات أو آلاف الساعات من محتوى الفيديو، يمكنكم الآن تحويل مكتبتكم بأكملها إلى مورد معرفي قابل للبحث مع الحفاظ على معايير الأمان والأداء المؤسسي.
دعونا نستعرض مقاطع فيديو Marengo و Pegasus التي نشرتها TwelveLabs.
تتيح هذه النماذج تحويل سير عمل الفيديو في مختلف القطاعات. فيمكن لمنتجي ومحرري الوسائط تحديد مواقع مشاهد أو حوارات معينة فوراً، مما يتيح لهم التركيز على سرد القصص بدلاً من قضاء الوقت في البحث عن اللقطات. كما تستطيع فرق التسويق تبسيط عملية إنتاج الإعلانات من خلال تخصيص المحتوى بسرعة لمختلف الجماهير، بينما تستفيد فرق الأمن من هذه التقنية في التعرف الاستباقي على المخاطر المحتملة عبر تحليل تدفقات الفيديو المتعددة.
بدء العمل مع نماذج TwelveLabs في Amazon Bedrock
للبدء باستخدام نماذج TwelveLabs، توجه إلى وحدة تحكم Amazon Bedrock واختر Model access من القائمة اليسرى. لاستخدام أحدث نماذج TwelveLabs، اطلب الوصول إلى Marengo Embed 2.7 و Pegasus 1.2 ضمن قسم TwelveLabs.
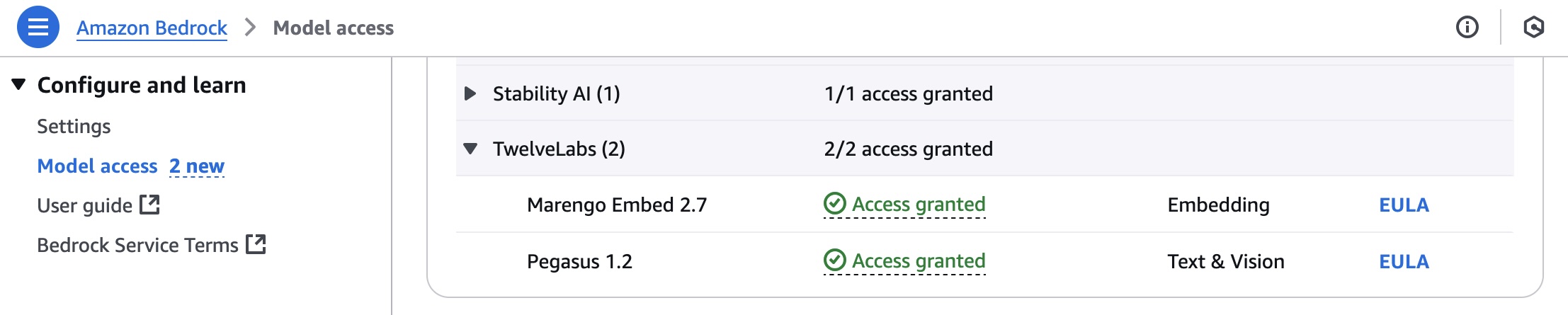
لاستخدام نماذج TwelveLabs في Amazon Bedrock، اختر Chat/Text playground ضمن Test في في القائمة اليسرى. ثم اختر Select model، حدد TwelveLabs كفئة و Pegasus كنموذج، وأخيرا حدد Apply.
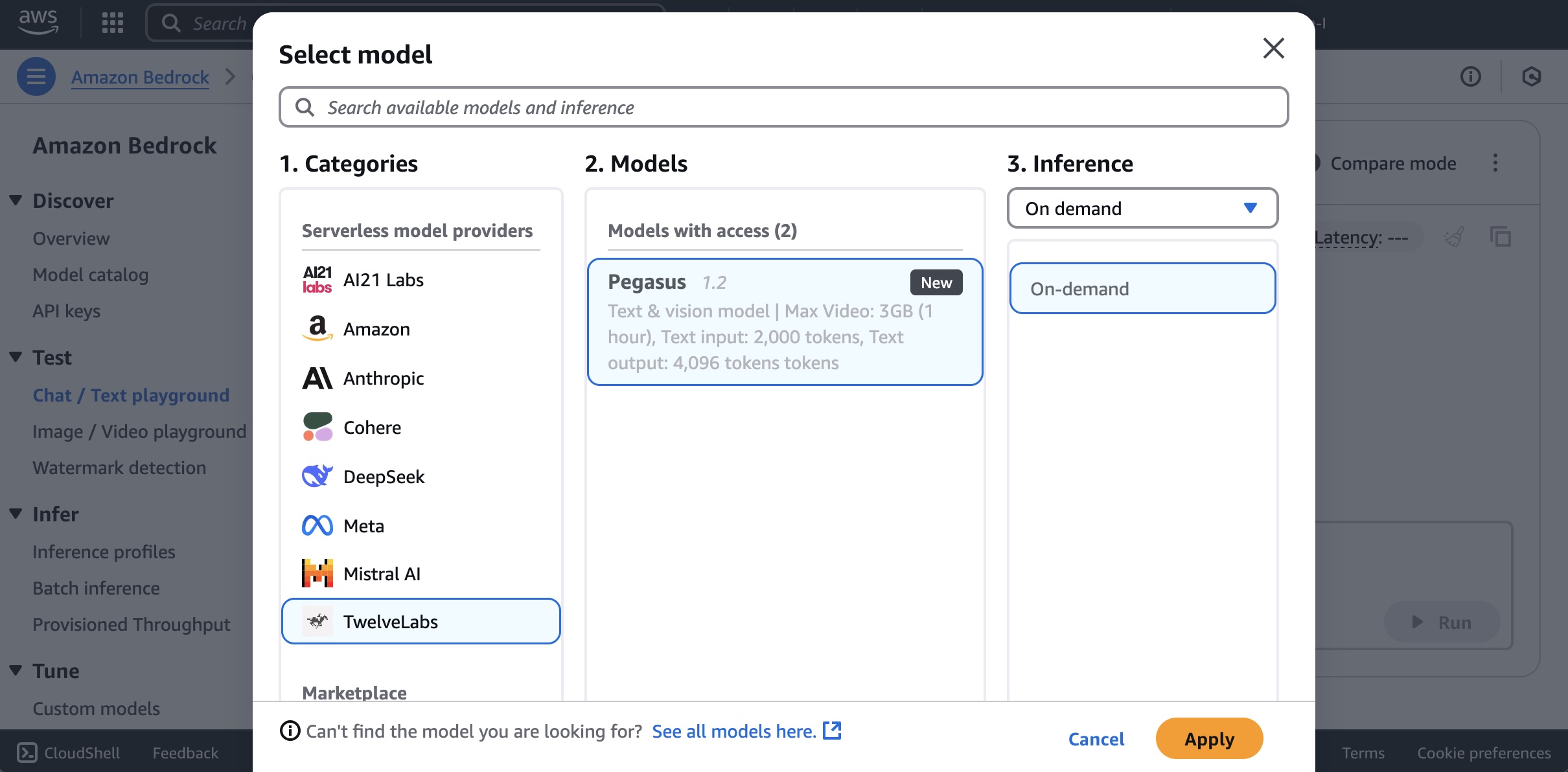
للبحث في الفيديو أو إنشاء نص وصفي له، عليك أولاً تحميل الفيديو إلى حاوية Amazon Simple Storage Service (Amazon S3) أو إدخال بيانات الفيديو بتنسيق Base64.
سنستخدم مقطع فيديو توضيحي تم إنشاؤه باستخدام Amazon Nova Reel استجابةً للموجه: “A cute raccoon playing guitar underwater” “راكون لطيف يعزف على الغيتار تحت الماء.”
ثم أدخل القيم الخاصة بالفيديو الذي تم تحميله لكل من Video S3 URI وS3 Bucket Owner، ثم قم بتشغيل الموجه الخاص بك: “Tell me about the video by timeline” “أخبرني عن الفيديو حسب الجدول الزمني”.
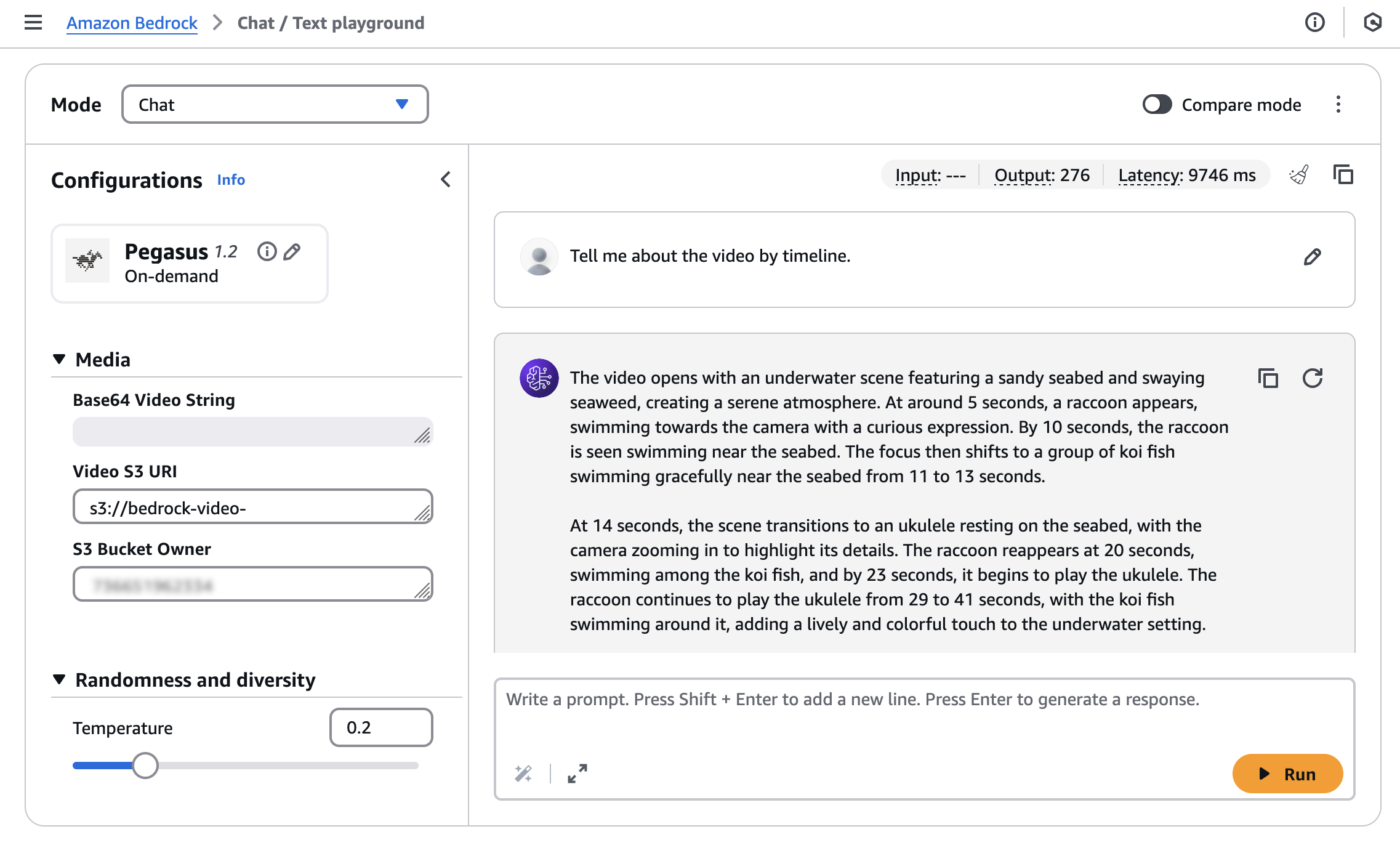
ستحصل على استجابة من النموذج كالتالي:
The video opens with an underwater scene featuring a sandy seabed and swaying seaweed, creating a serene atmosphere. At around 5 seconds, a raccoon appears, swimming towards the camera with a curious expression. By 10 seconds, the raccoon is seen swimming near the seabed. The focus then shifts to a group of koi fish swimming gracefully near the seabed from 11 to 13 seconds.
At 14 seconds, the scene transitions to an ukulele resting on the seabed, with the camera zooming in to highlight its details. The raccoon reappears at 20 seconds, swimming among the koi fish, and by 23 seconds, it begins to play the ukulele. The raccoon continues to play the ukulele from 29 to 41 seconds, with the koi fish swimming around it, adding a lively and colorful touch to the underwater setting.
From 42 to 49 seconds, the raccoon is shown playing the ukulele with the koi fish swimming around it. The video concludes with a screen displaying "Video generated with Amazon Novo Reel 1.1" and "Available in Amazon Bedrock" from 50 to 54 seconds, followed by the AWS logo from 55 to 57 seconds.
يبدأ الفيديو بمشهد تحت الماء يظهر فيه قاع بحر رملي وأعشاب بحرية متمايلة، مما يخلق أجواءً هادئة. عند الثانية الخامسة تقريباً، يظهر راكون يسبح نحو الكاميرا بتعبير فضولي. وفي الثانية العاشرة، نرى الراكون يسبح بالقرب من قاع البحر. ثم ينتقل التركيز إلى مجموعة من أسماك الكوي تسبح برشاقة قرب القاع من الثانية 11 إلى 13.
في الثانية 14، ينتقل المشهد إلى يوكوليلي مستقر على قاع البحر، مع تقريب الكاميرا لإظهار تفاصيله. يعود الراكون للظهور في الثانية 20، يسبح بين أسماك الكوي، وفي الثانية 23 يبدأ بالعزف على اليوكوليلي. يستمر الراكون في العزف من الثانية 29 إلى 41، بينما تسبح أسماك الكوي حوله، مما يضيف لمسة حيوية وملونة للمشهد تحت الماء.
من الثانية 42 إلى 49، يظهر الراكون وهو يعزف على اليوكوليلي مع استمرار أسماك الكوي في السباحة حوله. يختتم الفيديو بشاشة تعرض "تم إنشاء الفيديو باستخدام Amazon Novo Reel 1.1" و"متوفر في Amazon Bedrock" من الثانية 50 إلى 54، يليها شعار AWS من الثانية 55 إلى 57.
يمكن دمج نماذج TwelveLabs بسهولة في تطبيقاتك باستخدام واجهة برمجة تطبيقات المحادثة Amazon Bedrock، والتي توفر واجهة موحدة لتفاعلات الذكاء الاصطناعي التحادثي.
إليك مثالاً على كيفية استخدام AWS SDK for Python (Boto3) مع نموذج TwelveLabs Pegasus:
import boto3
import json
import base64
AWS_REGION = "us-west-2"
MODEL_ID = "us.twelvelabs.pegasus-1-2-v1:0" # OR "eu.twelvelabs.pegasus-1-2-v1:0" if it is doing cross region inference in europe
VIDEO_PATH = "sample.mp4"
def read_file(file_path: str) -> str:
"""Read a file and return as base64 encoded string."""
try:
with open(file_path, 'rb') as file:
file_content = file.read()
return base64.b64encode(file_content).decode('utf-8')
except Exception as e:
raise Exception(f"Error reading file {file_path}: {str(e)}")
bedrock_runtime = boto3.client(
service_name="bedrock-runtime",
region_name=AWS_REGION
)
request_body = {
"inputPrompt": "tell me about the video",
"mediaSource": {
"base64String": read_file(VIDEO_PATH)
}
}
response = bedrock_runtime.invoke_model(
modelId=MODEL_ID,
body=json.dumps(request_body),
contentType="application/json",
accept="application/json"
)
response_body = json.loads(response['body'].read())
print(json.dumps(response_body, indent=2))
يقوم نموذج TwelveLabs Marengo Embed 2.7 بإنشاء تضمينات متجهية (vector embeddings) من مدخلات الفيديو أو النص أو الصوت أو الصورة. يمكن استخدام هذه التضمينات للبحث عن التشابه والتجميع وغيرها من مهام التعلم الآلي. يدعم النموذج الاستدلال غير المتزامن من خلال واجهة برمجة تطبيقات Bedrock AsyncInvokeModel.
لاستخدام فيديو مع نموذج TwelveLabs Marengo Embed 2.7، يمكنك إرسال طلب بتنسيق JSON باستخدام واجهة برمجة التطبيقات AsyncInvokeModel كما يلي:
{
"modelId": "twelvelabs.marengo-embed-2-7-v1:0",
"modelInput": {
"inputType": "video",
"mediaSource": {
"s3Location": {
"uri": "s3://your-video-object-s3-path",
"bucketOwner": "your-video-object-s3-bucket-owner-account"
}
}
},
"outputDataConfig": {
"s3OutputDataConfig": {
"s3Uri": "s3://your-bucket-name"
}
}
}
ستحصل على استجابة يتم تسليمها إلى موقع S3 المحدد بالشكل التالي:
{
"embedding": [0.345, -0.678, 0.901, ...],
"embeddingOption": "visual-text",
"startSec": 0.0,
"endSec": 5.0
}
للمساعدة في البدء، يمكنكم الاطلاع على مجموعة واسعة من أمثلة الشيفرات البرمجية لحالات استخدام متعددة وبلغات برمجة مختلفة. لمزيد من المعلومات، زوروا صفحات الوثائق الخاصة بـ TwelveLabs Pegasus 1.2 و TwelveLabs Marengo Embed 2.7 في وثائق AWS.
متاح الآن
نماذج TwelveLabs متوفرة للاستخدام العام في Amazon Bedrock: نموذج Marengo في مناطق شرق الولايات المتحدة (فيرجينيا الشمالية)، وأوروبا (أيرلندا)، وآسيا والمحيط الهادئ (سيول)، بينما يتوفر نموذج Pegasus في منطقة غرب الولايات المتحدة (أوريغون)، وأوروبا (أيرلندا) مع إمكانية الوصول إليه عبر الاستدلال بين المناطق من مناطق الولايات المتحدة وأوروبا. للاطلاع على أحدث المعلومات حول توافر المناطق، يرجى مراجعة القائمة الكاملة للمناطق. لمزيد من التفاصيل، زوروا صفحة منتج TwelveLabs في Amazon Bedrock وصفحة تسعير Amazon Bedrock.
نشجعكم على تجربة نماذج TwelveLabs في وحدة تحكم Amazon Bedrock اليوم. نرحب بملاحظاتكم عبر AWS re:Post لـ Amazon Bedrock أو من خلال قنوات دعم AWS المعتادة الخاصة بكم.