AWS Partner Network (APN) Blog
Building Resilient and Reliable Systems on AWS with Gremlin’s Reliability Platform
By Kyle McMeekin, Head of Channel – Gremlin
By Shashiraj Jeripotula, Sr. Partner Solutions Architect – AWS
 |
| Gremlin |
 |
Resiliency is the ability of a system to recover from a failure induced by load, attacks, and/or general disruptions to the underlying infrastructure. This can range from services being entirely unavailable or degraded, to downtime. A resilient workload has the capability to recover when stressed by load, attacks, and failure of any component in the workload.
Within an organization, it’s common for these systems to reside across a broad spectrum of AWS technologies, ranging from virtual machines to Amazon Elastic Compute Cloud (Amazon EC2) to Amazon Elastic Kubernetes Service (Amazon EKS) environments.
Today, many organizations trust Amazon Web Services (AWS) to host their business’s applications and infrastructure. As these organizations continue to innovate, their applications and environments become increasingly complex—meanwhile, customers’ demands and expectations continue to rise. To meet these expectations, organizations must be proactive, putting reliability and resiliency at the forefront. This initiative, while appealing, can be challenging to implement.
Customers often ask themselves, can we build confidence that we have a full and clear understanding of a microservice-based applications’ key dependencies? Or what if a spike in traffic adds latency to mission-critical services? Will it impact the user experience? Is my application even accessible?
For a proactive approach to resiliency and reliability, consider chaos engineering—a process that lets you compare what you think will happen to what actually happens in your systems. Chaos engineering is based on the concept that by breaking things on purpose, you can learn how to build more resilient systems. By proactively testing how a system responds under stress, you can identify and fix failures before they happen.
Gremlin is an AWS DevOps Competency Partner that provides users a framework to safely, securely, and easily simulate real outages with an ever-growing library of attacks. As a leader in the chaos engineering space, Gremlin has helped hundreds of organizations establish a culture of resiliency, allowing them to increase uptime, prevent unplanned outages, modernize disaster recovery efforts, and more.
In this post, you’ll learn how to apply chaos engineering principles to your Amazon EKS environment to increase uptime, reduce incidents, and build more resilient applications, systems, and services. Gremlin supports a range of other Amazon technology and deployments.
Key Benefits of Chaos Engineering
- Ensure your businesses’ push towards the cloud is successful by having a proactive, safe, and secure way to apply chaos engineering practices, ultimately reducing unplanned downtime.
- For AWS customers following the AWS Well-Architected Framework, apply chaos engineering to your AWS environments to help build a culture of resiliency.
- Improve customer satisfaction by ensuring higher availability of your critical applications and services.
- Reduce the total amount of incidents your application encounters.
- Pinpoint critical areas of your applications and underlying services by applying chaos engineering tests. This helps reduce mean time to resolution and mean time to detect by using existing AWS capabilities, such as Amazon CloudWatch.
Solution Overview
Gremlin is a simple, safe, and secure service for performing chaos engineering experiments through a SaaS-based platform. This tutorial walks through how to install Gremlin on Amazon EKS with a demo environment and perform a chaos engineering experiment using a Gremlin shutdown attack.
It also walks through a microservice application running in Amazon EKS to ensure that the application is resilient to failures. These failures could include scenarios such as critical dependencies being unavailable, latency spiking on high-impact services, or validating auto-scaling.
 Figure 1 – How Gremlin works and gets deployed within your AWS environment.
Figure 1 – How Gremlin works and gets deployed within your AWS environment.
Prerequisites
Before you begin this tutorial, you’ll need the following:
- An AWS account
- AWS Command Line Interface (AWS CLI) configured on a local machine
- A Gremlin account
Walkthrough
This tutorial will walk you through the required steps to run an Amazon EKS cluster, deploy two applications, and then run a chaos engineering experiment using Gremlin.
Step 1: Verify Your Account AWS CLI Installation
To get started, verify that you have your AWS CLI configured to use eksctl to create the EKS cluster: aws --version
This should give you an output similar to:
aws-cli/1.16.150 Python/3.7.3 Darwin/18.5.0 botocore/1.12.140
If you need help, review the AWS CLI installation documentation.
Step 2: Create an EKS Cluster Using Eksctl
For the purpose of this tutorial, you will use Weave Work’s open source tool, eksctl, to create EKS clusters. On your local machine, install eksctl:
After installing eksctl, create a basic cluster: eksctl create cluster
This will create a cluster and the needed resources in us-west-2. It will auto-generate a cluster name, create 2 m5.large ec2 instances using the official AWS EKS Amazon Machine Image (AMI), and set up a dedicated virtual private cloud (VPC).
Step 3: Load up the Kubeconfig for the Cluster
Use the below command to ensure that eks cluster has been set up properly:
eksctl get clusters
The output should display the name of your cluster and the region similar to:

Figure 2 – Output and name of your cluster and region.
Now, grab the kubeconfig file from AWS using the AWS CLI and passing the cluster name and region (example below). The cluster name is “fabulous-mushroom-1527688624” and the region is “us-west-2”:
sudo aws eks --region us-west-2 update-kubeconfig --name fabulous-mushroom-1527688624
To verify the hosts that eksctl has set up, run the following command:
kubectl get nodes
Step 4: Create Your Free Gremlin Account
For the purpose of this walkthrough, sign up for a Gremlin account here. This is recommended even if you have an existing Gremlin account.
Figure 3 – Gremlin sign up page.
Retrieve Your Team ID and Secret Key
To install the Gremlin Kubernetes client, you will need a Gremlin Team ID and Secret Key. If you already have this, skip to the next section.
To retrieve your Gremlin Team ID and Secret Key, visit the Gremlin Teams page. Then, select your team’s name from the list.
Figure 4 – Select your Team in the Gremlin UI.
Next, select Configuration. Make a note of your Team ID.
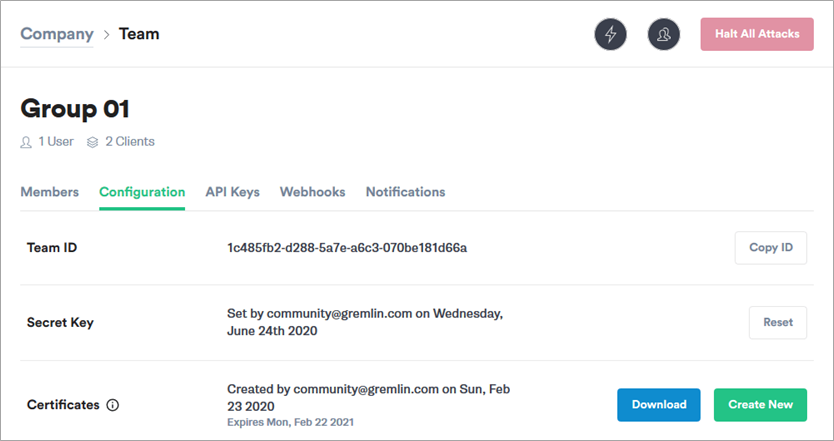
Figure 5 – Retrieve your Team ID and Secret Key.
If you don’t know your Secret Key, you’ll need to reset it. To do this, select Reset.
You should get a pop-up reminding you that any running clients using the current Secret Key will need to be configured with the new key. Select Continue.
Next, you’ll see a pop-up screen that will show you the new Secret Key (Figure 6). Make a note of it.
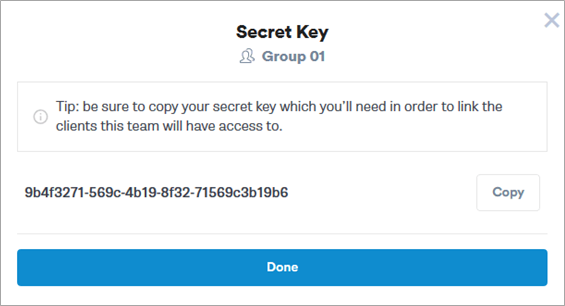
Figure 6 – Example of a Secret Key.
Install the Gremlin Client with Helm
The simplest way to install the Gremlin client on your Kubernetes cluster is to use Helm. If you do not already have Helm installed, review the Introduction to Helm doc. Once Helm is installed and configured, add the Gremlin repo and install the client.
Within your Terminal or Command Line, install the Gremlin Helm chart:
helm repo add gremlin https://helm.gremlin.com
Create a namespace for the Gremlin Kubernetes client:
kubectl create namespace gremlin
Next, run the helm command to install the Gremlin client. In this command, there are three placeholder variables that you will need to replace with real data.
Replace $GREMLIN_TEAM_ID with your Team ID and replace $GREMLIN_TEAM_SECRET with your Secret Key, retrieved in the previous section. Replace $GREMLIN_CLUSTER_ID with a name for the cluster.
If you are using Helm v3, run this command:
For older versions of Helm, use the --name option:
To verify that the installation was successful, run the following command: helm version
The output should show one chao pod and one gremlin pod for each node in your cluster. These should all be in the running state:
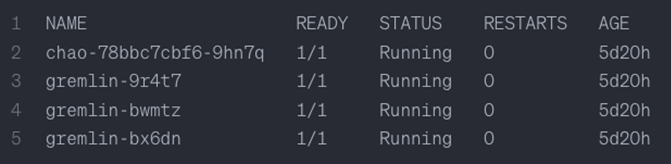
Figure 7 – Output showing one chao pod and one gremlin pod for each node in your cluster.
For more information, including configuration options, check out the Gremlin Helm Charts repository on GitHub.
The Gremlin client is also available for installation using kubectl. For more information on how to use this method, read the Installing Gremlin documentation.
Step 5: Deploy a Microservices Demo Application
For the purpose of this tutorial, the demo environment you are going to deploy on to the Amazon EKS cluster is the Hipster Shop: cloud-native microservices demo application.
On your local machine clone the following repo:
git clone https://github.com/GoogleCloudPlatform/microservices-demo.git
Then, change directories to the directory you just created:
cd microservices-demo
To deploy the application:
kubectl apply -f ./release/kubernetes-manifests.yaml
Wait until pods are in a ready state. To check the readiness run the following command:
kubectl get pods
Grab the ip address the frontend lives on:
kubectl get svc frontend-external -o wide
The output is the URL you’ll open on your web browser:
A7718c2117c2d11e98240024d0758e34-2062095095.us-west-2.elb.amazonaws.com
Now, open the URL on your browser. You’ll be presented with the Application Under Test (AUT) needed to run some experiments. This is a basic microservice-based application.
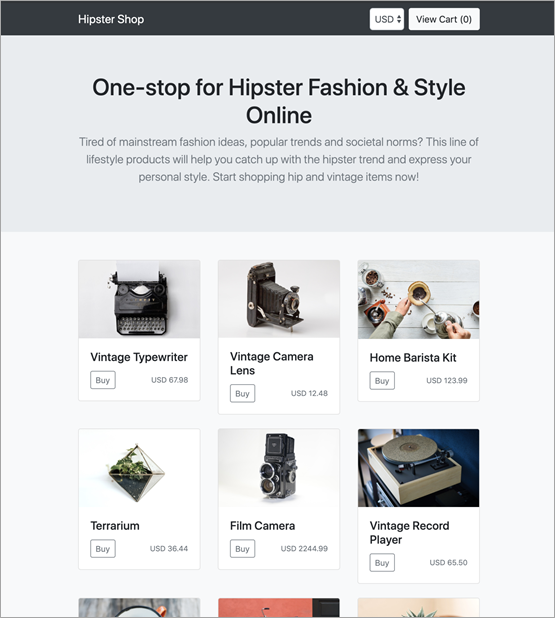
Figure 8 – Sample interface of the Hipster Shop.
Step 6: Run a Shutdown Container Attack Using Gremlin
Next, you will create the first chaos engineering experiment. We want to validate Amazon EKS reliability. With chaos engineering, it’s important to form some assumptions or hypothesis about the infrastructure and systems.
For this tutorial, the hypothesis is: “When shutting down my cart service container, I will not suffer downtime and Amazon EKS will give me a new one.”
Within Gremlin’s interface, choose Attacks, New. For the purpose of this tutorial, you will target a Kubernetes resource. Select Kubernetes.
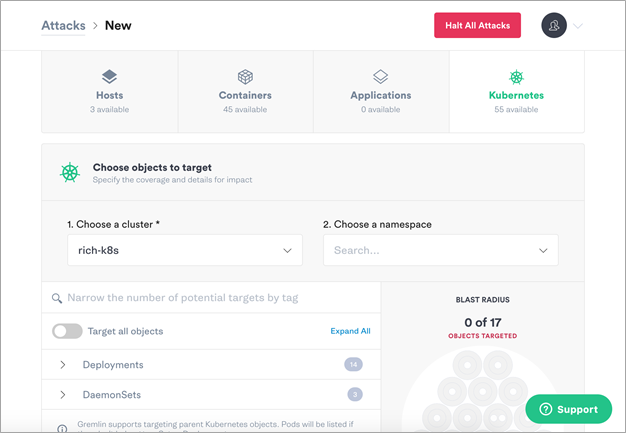
Figure 9 – This is what you should see in the Gremlin UI after selecting Kubernetes.
Next, shut down the cartservice containers. Gremlin has imported the objects from Kubernetes, as seen in the UI.
To find the container you want to target, expand Deployments and select cartservice.
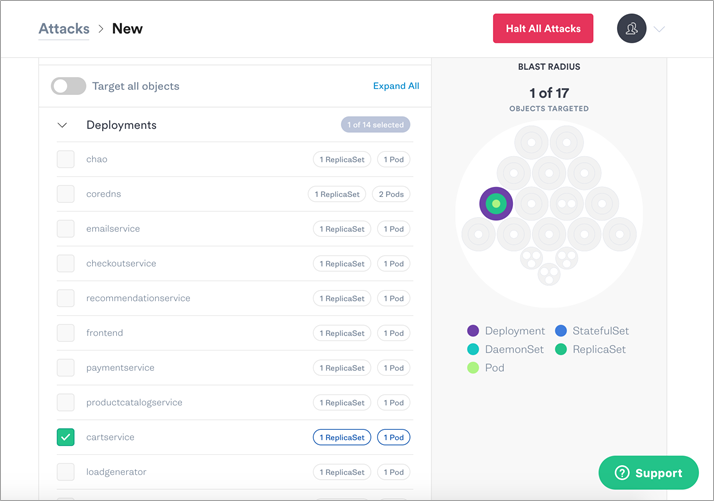
Figure 10 – Select the cartservice and see the impacted Blast Radius on the right.
Next, choose the gremlin. To do a state chaos engineering attack, select State and choose Shutdown.
Leave the delay set to one minute and turn off the reboot. Then, select Unleash Gremlin.
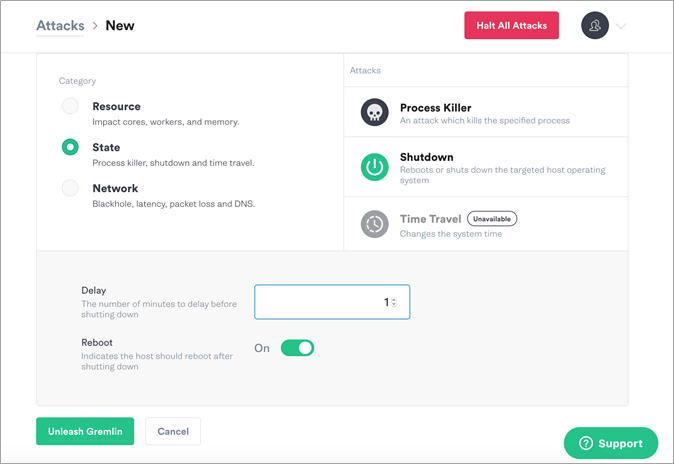
Figure 11 – Select the State category and Shutdown as the Attack type.
You can view the state of the pods with kubetctl: kubectl get pods
Also, make sure to check out the demo app to test user experience and see if your hypothesis is correct.
Results
The hypothesis, “When shutting down my cart service container, I will not suffer downtime and Amazon EKS will give me a new one.”, did not prove to be correct.
As a result, the Hipster Shop: cloud-native microservices demo application did not gracefully handle shutdown. Instead, it displayed a 500 internal server error.
To mitigate this issue, you would need to first investigate the error and look into the logs. For example, the error shows, “could not retrieve cart”. When you run ‘kubectl get pods’, you will see there is only one cartservice running and it has no redundancy.
For more information, see cartservice.yaml on the GitHub website. In this file, you can see that cart service uses redis but it does not use clustered redis.
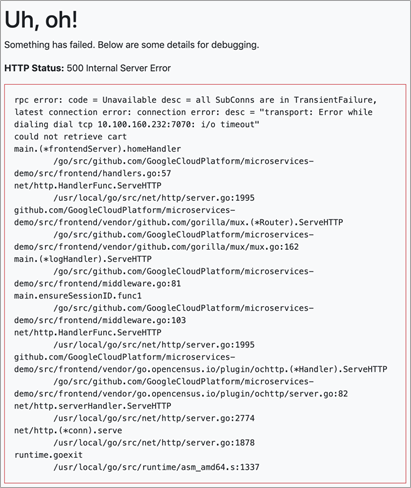
Figure 12 – The error message within the Application Under Test after the failure injection runs.
Conclusion
Congrats! You have set up an Amazon EKS cluster, deployed the Kubernetes dashboard, deployed a microservice demo application, installed the Gremlin agent with the Gremlin Helm chart, and ran your first chaos engineering attack to validate Kubernetes reliability.
Cleaning Up
Remember to delete any resources created in order to avoid additional costs.
Summary
In this post, we covered how AWS customers can leverage Gremlin to improve the resiliency and reliability of their applications. As more organizations move their applications into cloud environments, it’s paramount for businesses to proactively test against failures and common events that can result in unplanned downtime.
Leveraging the power of AWS stable environments and using Gremlin to add elements of resiliency to the applications running on them, allows organizations to meet the growing expectations of their customers. Chaos engineering can make your journey to the cloud less complex and help users be proactive about uncovering unforeseen issues that inevitably happen in ever-expanding complex environments.
If you have questions or need help with this demo environment, email support@gremlin.com.
Additionally, customers can take a self-guided hands-on workshop to perform chaos engineering experiment within their AWS environments. Learn more about the workshop here.
To see a demonstration of Gremlin’s platform, contact the team. For general information on chaos engineering, review these resources.
.
 .
.
Gremlin – AWS Partner Spotlight
Gremlin is an AWS DevOps ISV Competency Partner that provides users a framework to safely, securely, and easily simulate real outages with an ever-growing library of attacks.