AWS Partner Network (APN) Blog
Deploy Accelerated ML Models to Amazon Elastic Kubernetes Service Using OctoML CLI
By Sameer Farooqui, Product Marketing Manager – OctoML
By Meenakshisundaram Thandavarayan, AI/ML Specialist – AWS
 |
| OctoML |
 |
Machine learning (ML) today is heterogeneous—from model frameworks and model architectures, to the silicon they run on and deployment scenarios.
Deploying ML models as a packaged container with hardware-optimized acceleration, without compromising accuracy and while being financially feasible, can be challenging. As machine learning models become the brains of modern applications, developers need a simpler way to deploy trained ML models to live endpoints for inference.
Launched at Amazon re:MARS 2022, OctoML CLI is a command line interface (CLI) that enables developers to package trained deep learning models into Docker containers and deploy them to Amazon Elastic Kubernetes Service (Amazon EKS).
The OctoML CLI also connects to the OctoML SaaS platform to accelerate the model using a variety of acceleration libraries, including Apache TVM, ONNX Runtime, NVIDIA’s TensorRT, and Intel’s OpenVINO. The result is a containerized model with the lowest possible latency and highest throughput that reduces ML inferencing costs substantially.
In this post, we will look at how an ML engineer can take a trained model, optimize and containerize the model using OctoML CLI, and deploy it to Amazon EKS.
OctoML is an AWS Partner founded in 2019 in Seattle by the creators of Apache TVM, a deep learning compiler, to help companies deploy accelerated machine learning models on varied hardware to production.
Solution Overview
MLOps engineers are responsible for model deployment and operationalization. This requires them to navigate a traditional software engineering environment to wrap their business application around and a distinctly different MLOps pipeline for optimizing and packaging the model. This doubles the complexity of your operations work as you have to learn and manage different stacks.
With the OctoML CLI, you can treat your ML models as software functions. Using one platform for both software applications and ML models, your team can realize the same benefits developers report of adopting containers: faster deployments, cloud portability, developer productivity, and cost savings.
As shown in Figure 1, OctoML CLI can be run two ways: a local deployment workflow for development and prototyping on your local machine or an accelerated cloud workflow for production deployments to Amazon EKS.

Figure 1 – OctoML CLI.
Along with Docker, another key technology that powers the OctoML container is NVIDIA’s Triton Inference Server—an open-source software for running inference on models created in any framework, on GPU or CPU hardware, in the cloud, or on edge devices. Triton allows remote clients to request inference for gRPC and HTTP/REST protocols through Python, Java, and C++ client libraries.
Triton lets users avoid lock-in to a specific framework, providing a consistent inference interface for client applications, regardless of training framework or target hardware. This allows data science teams to choose their own tools without worrying about how their models will be deployed.
Solution Architecture
The typical machine learning workflow involves data preparation, model training, model acceleration, model deployment and finally, model monitoring. Using Amazon SageMaker Data Wrangler, you can simplify the process of data preparation and feature engineering, and complete each step of the data preparation workflow, including data selection, cleansing, exploration, and visualization, from a single visual interface. With Amazon SageMaker you can build, train, and deploy with fully managed infrastructure, tools, and workflows.
Once a model architecture is built and trained, you’re ready to accelerate and package it with the OctoML platform. The OctoML CLI packages the accelerated model into a Docker container and pushes it to Amazon Elastic Container Registry (Amazon ECR). Now, you can deploy the container to Amazon EKS.

Figure 2 – Solution architecture.
Together, the OctoML CLI and Amazon EKS provide a fast-track workflow to quickly get your deep learning models accelerated, containerized, and running in production in the cloud.
Local Deployment to Docker Desktop
With a trained model in hand, the OctoML CLI packages your model into a container with a live inference server in minutes using three OctoML CLI subcommands:
- octoml init
- octoml package
- octoml deploy
Once you’ve downloaded the OctoML CLI on to your local machine, start OctoML by running octoml init in your command line prompt. This initializes your OctoML environment by creating a YAML configuration file (octoml.yaml) in the same directory as the OctoML CLI binary. The configuration file has metadata information, such as the location of your model (both local paths and URLs are supported). For automated deployments, this YAML file can be programmatically created.

Figure 3 – octoml init command.
Next, start Docker Desktop on your local machine. You can verify Docker is running with docker info or docker ps command in your command line.
Now, run octoml package to build a Docker container image with your model, as shown in Figure 4.

Figure 4 – octoml package command.
The octoml package command can take several minutes to run. The first time this command is invoked, a base container image will be downloaded and cached locally. Subsequent package runs will complete much faster as they’ll re-use the base container to assemble the new container.
In Docker Desktop, choose Images on disk (as shown in Figure 5) to view your built inference container.
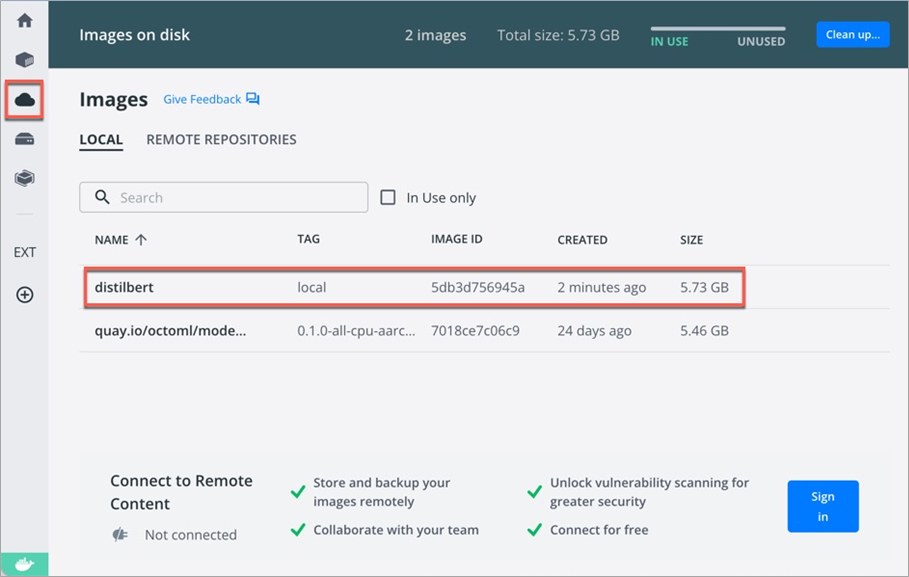
Figure 5 – Docker hub.
Finally, run octoml deploy to deploy the container to Docker Desktop and start the Triton Inference Server on it.
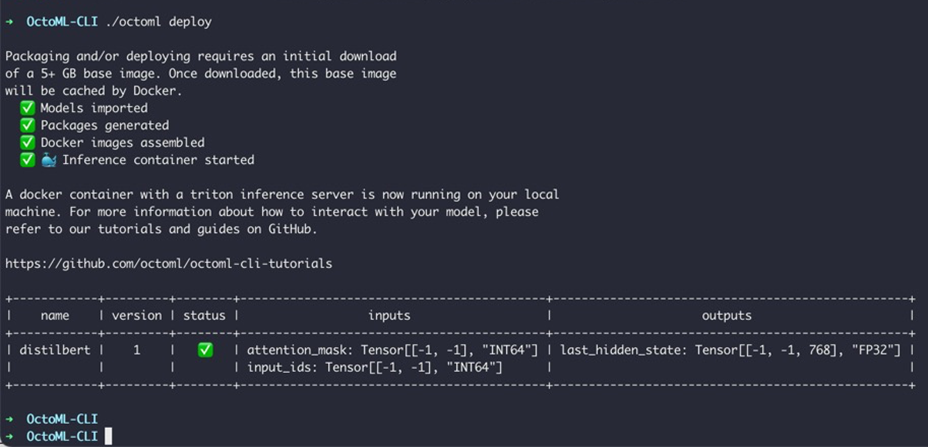
Figure 6 – octoml deploy command deploys the container to Docker Desktop locally.
In Docker Desktop, choose Containers to view the running container.
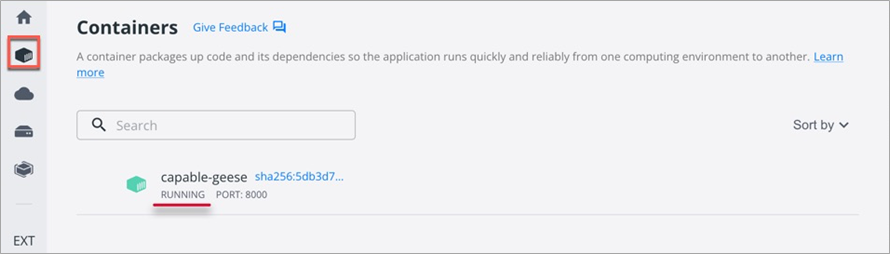
Figure 7 – Deploying locally.
Now, you’re ready to develop your business application locally using the live inference container. Your client code can use a Triton Client library in Python, Java, or C++. The inference endpoint is compatible with gRPC, HTTP/REST, and HTTPS protocols.
The following are sample commands to get started with inference. First, verify that the inference server is in READY state:
OctoML-CLI curl -s -X POST localhost:8000/v2/repository/index | jq ‘.’
Re-use the name output from the previous command to get statistics for the model.
OctoML-CLI curl -s localhost:8000/v2/models/distilbert/stats | jq ‘.’
Triton also provides metrics about GPU utilization and request statistics through its built-in Prometheus integration. This helps in monitoring the system metrics of your deployed model. Prometheus integration is outside the scope of this post.
Cloud Deployment to Amazon EKS
Once you’ve developed and tested your business application locally, you’re ready to deploy the app and model container to the cloud. However, cloud deployment poses the following two key challenges: Accelerating and optimizing the model for peak performance and getting the containerized model integrated into your Kubernetes cluster.
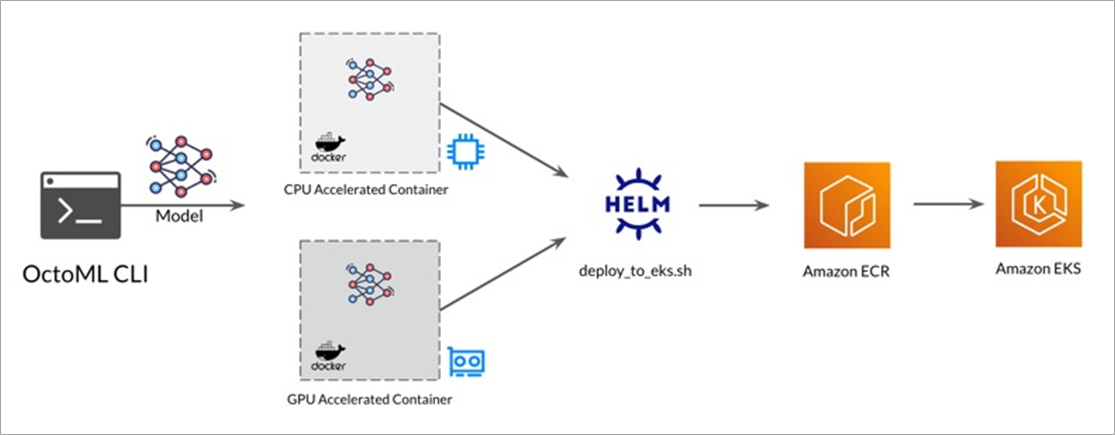
Figure 8 – Amazon EKS deployment.
For production deployments, optimizing model inference is an important step since it directly translates to application latency and can massively impact ML infrastructure costs. Without optimization, large, state-of-the-art deep learning models can become unusable as each inference request can approach hundreds of milliseconds, exceeding business SLAs. Furthermore, cost per inference can become so high that deep learning becomes cost-prohibitive.
Model optimization is a hardware-specific task, which can complicate the portability and abstraction that Docker and Kubernetes provide. Whereas most containers can be deployed without attention to the underlying hardware, optimized model containers perform best when deployed to hardware that they’ve been accelerated for.
The OctoML CLI offers an easy way to search through a wide range of hardware targets and produce Docker images optimized for those targets. To use these features, sign up for an OctoML account and generate an API token using the OctoML web UI.
On the OctoML CLI landing page, request your OctoML account. Then, log in to OctoML’s web UI, go to your account settings, and generate an API access token.

Figure 9 – Entering the OctoML API access token grants you access to OctoML’s model acceleration and deployment SaaS platform.
Because model acceleration is hardware specific, OctoML offers a variety of AWS instance types that your model can be accelerated for, as shown below in Figure 10.
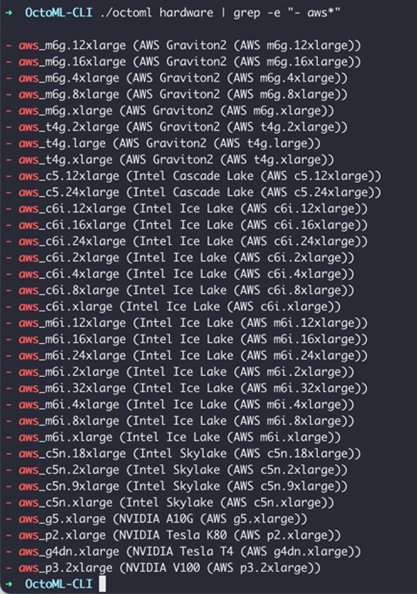
Figure 10 – OctoML supports a variety of AWS hardware platforms for model acceleration.
With your hardware target in mind, you are now ready to accelerate the model.
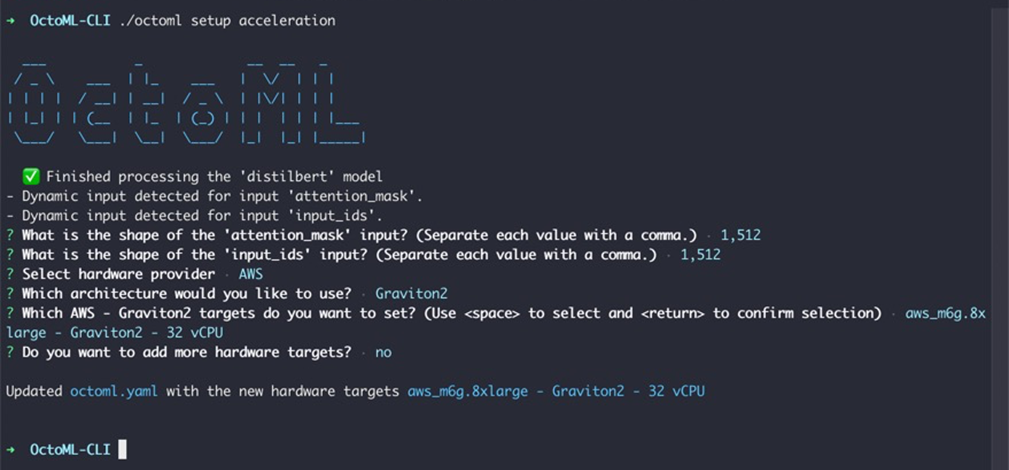
Figure 11 – octoml setup acceleration configures the model shape and hardware architecture for acceleration.
The package command to generate a Docker container has the following two options:
- -e for express acceleration mode, which creates an accelerated container within 20 minutes.
- -a for full acceleration mode, with potentially much better latency through a fuller exploration of the optimization space.
| Name | Express Acceleration Mode | Full Acceleration Mode |
| Time | 20 minutes | Several hours |
| Command | octoml package -e | octoml package -a |
| Purpose | Most performant package out of all optimizations attempted within 20 minutes | Most performant package out of full optimizations attempted over several hours |
Full acceleration can take several hours to run, so express acceleration mode is recommended for your initial setup. Note that both modes return accelerated models with reduced latency and internally use Apache TVM, ONNX-Runtime, and native training frameworks.
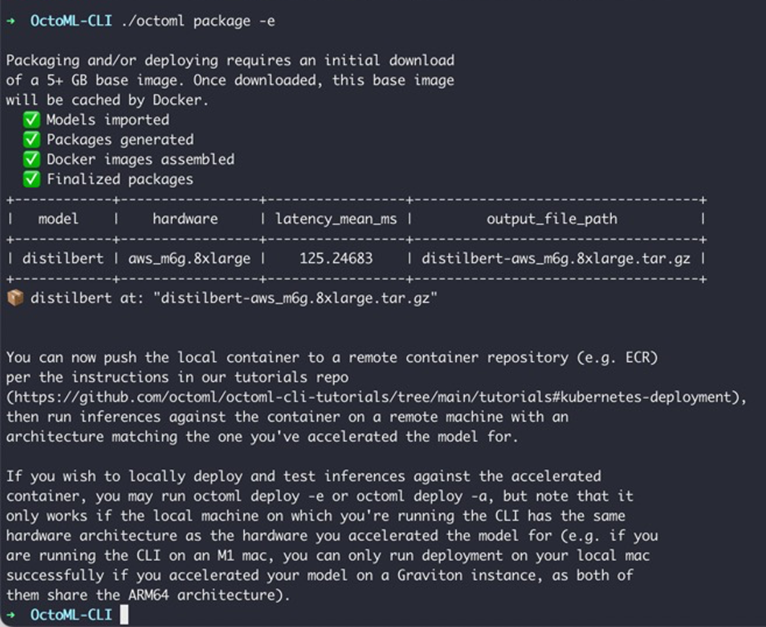
Figure 12 – octoml express mode packaging.
Now, you should see the .tar.gz container file in the directory where you ran the OctoML CLI. To deploy this container to Amazon EKS, use the deploy_to_eks.sh script and follow the instructions in the Kubernetes Deployment tutorial. The script uses kubectl and Helm charts to deploy the container, similar to other software applications.
Conclusion
In this post, we walked through how ML engineers can optimize the trained model, accelerate the model specific to a hardware target, and deploy and scale on Amazon EKS.
To get started optimizing and deploying your models with OctoML CLI refer to the step-by-step GitHub tutorials. For help developing next-generation applications using the OctoML CLI, send the team a message.
.
 .
.
OctoML – AWS Partner Spotlight
OctoML is an AWS Partner and SaaS solution that automates and optimizes trained ML models for seamless deployment on a myriad of AWS hardware targets, including NVIDIA GPUs, Intel and AMD CPUs, and AWS Graviton.