AWS Partner Network (APN) Blog
Generative AI using TiDB and Amazon Bedrock
By: Henrique Leandro, Head of Global Solutions Architect – PingCAP
By: Akshata Raghunatha, Partner Solutions Architect – AWS
By: Satish Subramanian, Manager, Partner Solutions Architect – AWS
| PingCAP |
 |
The shift from conversational chatbots to autonomous, goal-driven systems is changing how we think about application architecture. Instead of predictable, human-paced interactions, we’re beginning to design for software that acts continuously — planning, evaluating, revising, and executing without waiting for a user to choose “Submit.”
In this blog post, we explore how TiDB Cloud, an AWS Partner Network (APN) Partner, addresses the unique data layer challenges introduced by autonomous AI agents. We look at how TiDB Cloud’s distributed architecture, powered by TiDB Cloud’s serverless compute-storage separation model, supports these emerging patterns on AWS — particularly when paired with Amazon Bedrock for reasoning and embedding workloads using the TiDB console.
The challenge: when the user isn’t human
In these systems, the database is no longer responding to occasional human queries. Instead, it responds to agents that generate SQL automatically and create temporary schemas. These agents expect immediate access to both transactional records and contextual history.
Autonomous agents don’t behave like customers signing in during business hours. They work in loops — planning, executing, evaluating results, and trying again. A single instruction such as “optimize supply chain logistics” can unfold into thousands of internal operations. Agents can create temporary tables to isolate experiments, branch schemas to test alternative strategies, and persist large volumes of intermediate reasoning state.
For platform leaders, the question isn’t whether agents will increase load — it’s how to support unpredictable, burst-heavy workloads without losing control of cost or operational stability. Architectures built around fixed capacity and manual tuning start to feel misaligned when the user is a machine (AI agent) operating continuously.
From a data perspective, that behavior surfaces several practical challenges:
- Metadata management becomes non-trivial. If agents routinely create and discard schemas, the underlying database must handle that churn without degrading performance.
- Concurrency patterns become less predictable. Workloads can move from idle to highly parallel in seconds, especially if multiple agents begin exploring variations simultaneously.
- Cost becomes tightly coupled to elasticity. When compute must remain provisioned as a contingency, idle time becomes expensive. In autonomous systems, unused capacity isn’t only inefficient — it directly affects economic viability.
TiDB Cloud: a data layer designed for elastic systems
TiDB Cloud approaches these challenges with a distributed architecture that separates compute from storage. In this model, data persists in Amazon Simple Storage Service (Amazon S3) while compute resources scale independently. This separation changes the economics and behavior of the database layer.
Independent scaling of storage and compute
Because storage and compute are decoupled, compute resources can scale dynamically. They scale up during periods of heavy agent activity and scale down when workloads subside. Data remains durable in object storage, while stateless processing nodes are allocated as needed.
For agent-driven systems, this model aligns infrastructure costs more closely with actual usage. When activity slows, compute doesn’t need to remain fully provisioned. When activity spikes, additional capacity can be introduced without re-architecting the system.
Branching as a first-class capability
Agents often need isolated environments to test ideas. If an agent restructures a schema or rewrites a data model, that experimentation should be done in a way that doesn’t jeopardize production.
TiDB Cloud supports serverless branching using copy-on-write techniques. A branch can be created quickly, allowing an agent or a developer to explore a hypothesis in isolation. After the task is complete, that branch can be discarded, or reset to sync with the latest parent state.
This brings database workflows closer to the way teams already treat application code: versioned, testable, and disposable when necessary.
Unifying transactional and hybrid search workloads
Autonomous agents rarely ask just one kind of question. Within a single reasoning chain, an agent may draw on transactional memory for state, retrieve related context through hybrid search, match against domain-specific keywords, and reference analytical summaries of recent data. Each of these is a different access pattern, and traditionally each has required a different system.
Instead of stitching together separate engines for vector search, full-text search, real-time analytics, and relational queries, TiDB Cloud integrates row-based storage for transactions, columnar storage for real-time analytics, and native vector and full-text search for hybrid retrieval.
This reduces architectural fragmentation and keeps state consistent across access patterns. The result is a database that acts as durable memory for the agent – searchable across modalities and transactionally accurate.
Reference architecture: TiDB Cloud and Amazon Bedrock
In practice, the integration works as follows:
- Applications call Amazon Bedrock embedding models to convert documents and queries into vector representations.
- TiDB stores those embeddings in native vector columns alongside the transactional data.
- An orchestration layer, typically implemented using AWS Lambda, Amazon Elastic Container Service, or frameworks like LangChain, coordinates the workflow, retrieving relevant context using vector similarity search in TiDB.
- The orchestration layer passes the retrieved context to an Amazon Bedrock text generation model, then writes the agent’s resulting decisions back to TiDB as structured transactions.
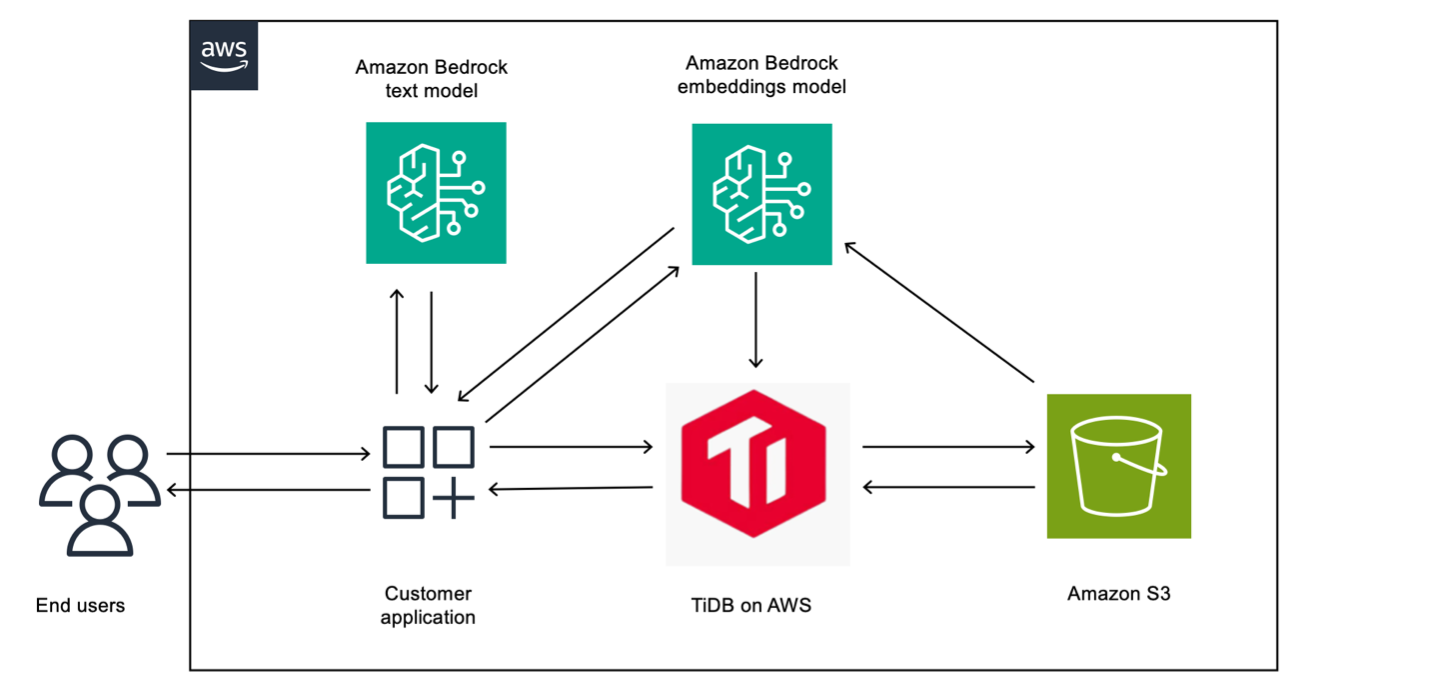
Figure 1 – Reference architecture for TiDB Cloud and Amazon Bedrock.
The architecture shown in the preceding figure consists of the following:
- Presentation layer – End users: application interface for user queries and responses.
- Application layer – Custom application: frontend and middleware orchestrating user interactions and API calls.
- AI/ML services layer – Models:
- Amazon Bedrock text model: foundation model for response generation.
- Amazon Bedrock embeddings model: converts documents and queries to vector embeddings.
- Vector database layer – TiDB: stores and retrieves vector embeddings for semantic search.
- Storage layer – Amazon S3: document repository for source data.
Together, these layers separate reasoning from persistence while maintaining a cohesive data model.
Use cases
TiDB Cloud on AWS supports a broad range of autonomous agent workloads — from real-time fraud detection to multi-tenant software-as-a-service (SaaS) operations — and can be configured using the TiDB console, shown in the following screenshot. The following example use cases illustrate how teams are combining TiDB’s unified HTAP architecture with Amazon Bedrock to build production-ready AI systems across industries.
Figure 2 – TiDB console.
Conversational analytics for ecommerce
An ecommerce platform uses TiDB Cloud on AWS to store product catalogs, inventory, and order data. An autonomous agent powered by Amazon Bedrock translates natural language queries — such as “which products are trending but running low on stock?” — into SQL executed against TiDB’s HTAP engine. The agent combines real-time transactional data with analytical aggregations in a single query, eliminating the need for a separate data warehouse.
Fraud detection in financial services
A fintech company stores transaction records in TiDB Cloud on AWS. An agent uses Amazon Bedrock for reasoning and TiDB’s vector search to match transaction embeddings against known fraud signatures. The agent queries millions of transactions in real time (using OLTP) while running analytical pattern detection (using OLAP) — all within a single distributed database.
Multi-tenant SaaS operations
A SaaS platform uses TiDB Cloud’s distributed SQL to serve thousands of tenants. An autonomous agent provisions new tenant databases, monitors usage patterns, and identifies churn signals — all through SQL operations using TiDB on AWS. The serverless branching capability allows the agent to test schema changes in isolation before applying them to production. This TiDB blog post highlights how TiDB empowered Atlassian’s Forge platform to support a massive, multi-tenant architecture with over 3 million tables — all within a single cluster.
Live operations in gaming
A gaming company stores player profiles, match history, and in-game economy data in TiDB Cloud on AWS. An agent analyzes player engagement, detects anomalous behavior patterns using vector similarity search, and recommends live event configurations — querying millions of concurrent player records without manual sharding.
GenAI experimentation without heavy setup
Agentic architectures are still evolving. Teams often need room to prototype and iterate before committing to production-scale designs.
TiDB Cloud on AWS provides a managed, serverless environment that teams can use to experiment with branching, vector search, and SQL-driven agents without standing up complex infrastructure. This simplifies validating workload assumptions and refining architectural decisions before scaling further. This TiDB blog post highlights how TiDB Cloud enabled extreme write throughput and low-latency state reconstruction that a monolithic database couldn’t sustain for a successful public launch with a more than 2 million transaction waitlist within weeks.
Conclusion
The question isn’t whether autonomous agents will transform your architecture — it’s whether your database will be ready when they do. The teams building tomorrow’s AI systems are choosing infrastructure today.
By running TiDB Cloud on AWS and integrating with Amazon Bedrock, organizations can design a database layer that supports transactional accuracy, hybrid retrieval, real-time analytics, and rapid experimentation within a unified architecture. Instead of working around database constraints, architects can focus on shaping how autonomous systems behave, and how they evolve. Unlike architectures that require separate databases for transactions, analytics, and hybrid search, TiDB Cloud unifies these capabilities while maintaining the elasticity and cost efficiency autonomous systems demand.
Ready to build your agentic architecture? Explore TiDB Cloud on AWS Marketplace or contact PingCAP to discuss your specific use case.

PingCAP – AWS Partner Spotlight
PingCAP is an AWS Advanced Technology Partner that provides TiDB Cloud, a fully managed distributed SQL database designed for hybrid transactional and analytical processing (HTAP) workloads.