AWS Architecture Blog
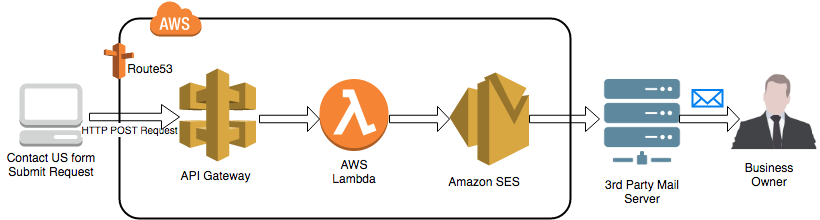
Create Dynamic Contact Forms for S3 Static Websites Using AWS Lambda, Amazon API Gateway, and Amazon SES
In the era of the cloud, hosting a static website is cheaper, faster and simpler than traditional on premise hosting, where you always have to maintain a running server. Basically, no static website is truly static. I can promise you will find at least a “contact us” page in most static websites, which, by their […]

Announcing 7 New Exam Readiness Courses for AWS Certifications
We’re excited to announce the launch of seven Exam Readiness courses to help you prepare for AWS Certification. Built by AWS, these courses are designed to help you prepare for the Solutions Architect, Developer, DevOps Engineer, Big Data, and Advanced Networking exams. Specifically, the Exam Readiness: AWS Certified Solutions Architect – Associate course has been […]

A serverless solution for invoking AWS Lambda at a sub-minute frequency
If you’ve used Amazon CloudWatch Events to schedule the invocation of a Lambda function at regular intervals, you may have noticed that the highest frequency possible is one invocation per minute. However, in some cases, you may need to invoke Lambda more often than that. In this blog post, I’ll cover invoking a Lambda function every […]
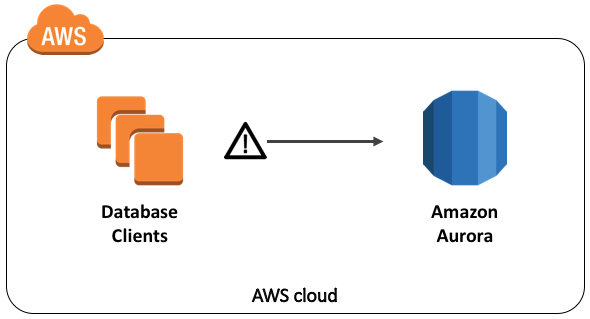
Amazon Aurora MySQL DBA Handbook – Connection Management
Amazon Aurora MySQL (Aurora MySQL) is a managed relational database engine, wire-compatible with MySQL 5.6. Most of the drivers, connectors, and tools that you currently use with MySQL can be used with Aurora MySQL with little or no change. Aurora MySQL database (DB) clusters provide advanced features such as: One primary instance that supports read […]
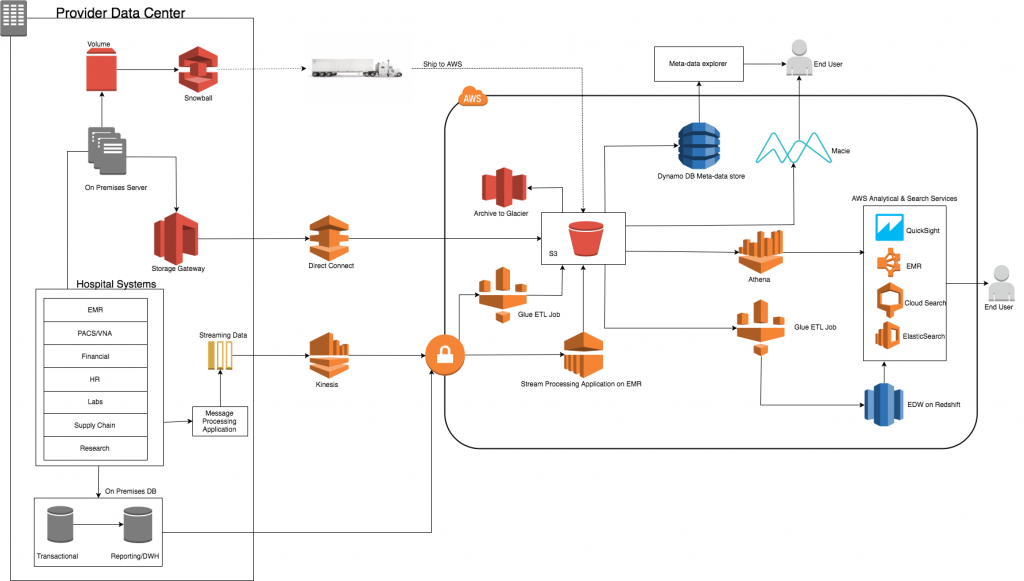
Store, Protect, Optimize Your Healthcare Data with AWS: Part 1
This blog post was co-authored by Ujjwal Ratan, a senior AI/ML solutions architect on the global life sciences team. Healthcare data is generated at an ever-increasing rate and is predicted to reach 35 zettabytes by 2020. Being able to cost-effectively and securely manage this data whether for patient care, research or legal reasons is increasingly […]
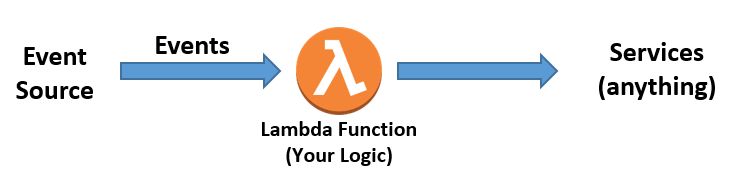
Serverless Architectures with AWS Lambda: Overview and Best Practices
For some organizations, the idea of “going serverless” can be daunting. But with an understanding of best practices – and the right tools — many serverless applications can be fully functional with only a few lines of code and little else. Examples of fully-serverless-application use cases include: Web or mobile backends – Create fully-serverless, mobile […]

Announcing the new AWS Certified Security – Specialty exam
Good news for cloud security experts: following our most popular beta exam ever, the AWS Certified Security – Specialty exam is here. This new exam allows experienced cloud security professionals to demonstrate and validate their knowledge of how to secure the AWS platform. About the exam The security exam covers incident response, logging and monitoring, […]
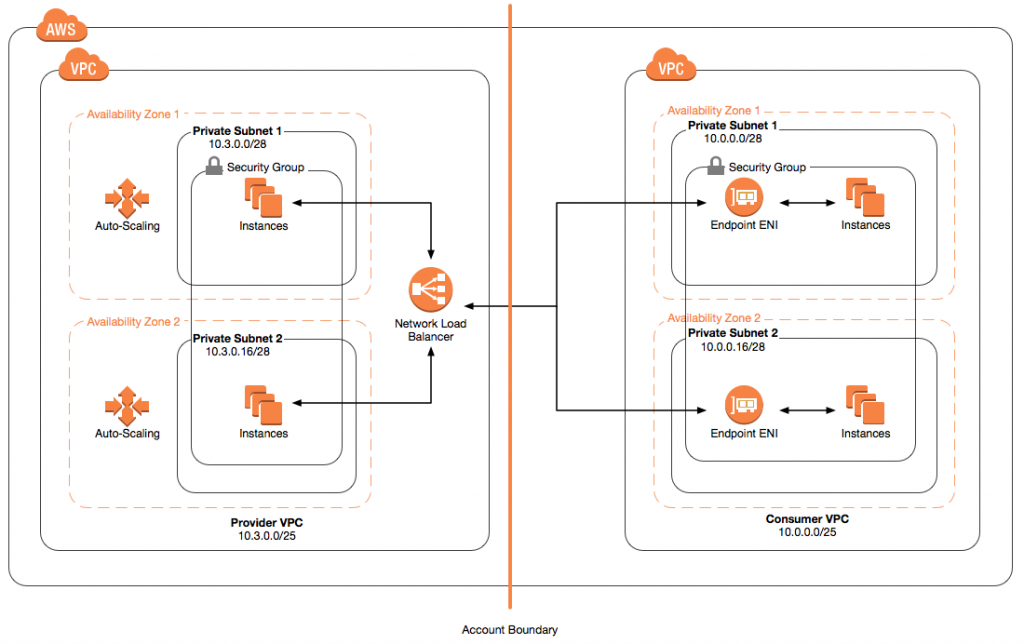
Building SaaS Services for AWS Customers with PrivateLink
With the advent of AWS PrivateLink, you can provide services to AWS customers directly in their Virtual Private Networks by offering cross-account SaaS solutions on private IP addresses rather than over the Internet. Traffic that flows to the services you provide does so over private AWS networking rather than over the Internet, offering security and […]

RDS for Oracle: Extending Outbound Network Access to use SSL/TLS
In December 2016, we launched the Outbound Network Access functionality for Amazon RDS for Oracle, enabling customers to use their RDS for Oracle database instances to communicate with external web endpoints using the utl_http and utl tcp packages, and sending emails through utl_smtp. We extended the functionality by adding the option of using custom DNS […]
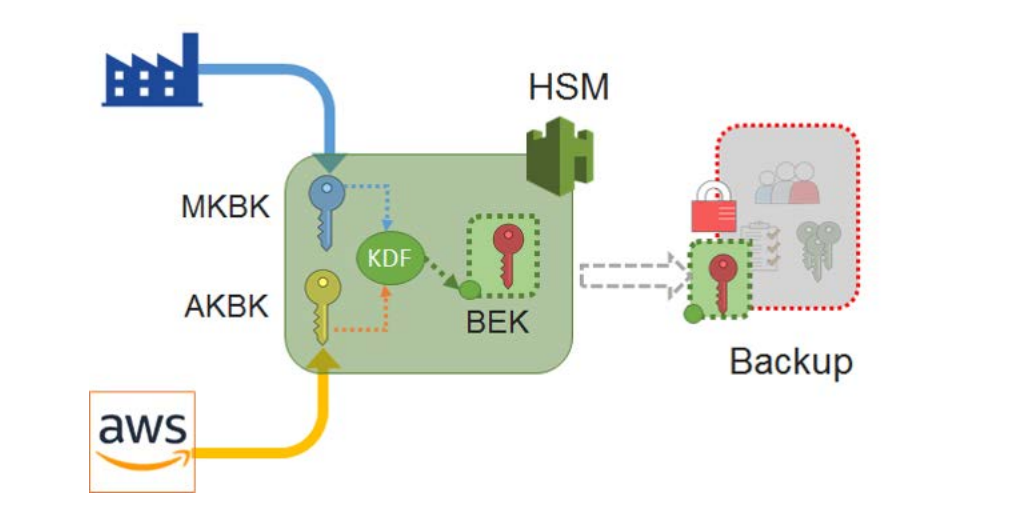
Security of Cloud HSMBackups
Today, our customers use AWS CloudHSM to meet corporate, contractual and regulatory compliance requirements for data security by using dedicated Hardware Security Module (HSM) instances within the AWS cloud. CloudHSM delivers all the benefits of traditional HSMs including secure generation, storage, and management of cryptographic keys used for data encryption that are controlled and accessible […]