AWS Architecture Blog
Glenn’s Take on re:Invent 2017 – Part 3
Glenn Gore here, Chief Architect for AWS. I was in Las Vegas last week — with 43K others — for re:Invent 2017. I checked in to the Architecture blog here and here with my take on what was interesting about some of the bigger announcements from a cloud-architecture perspective.
In the excitement of so many new services being launched, we sometimes overlook feature updates that, while perhaps not as exciting as Amazon DeepLens, have significant impact on how you architect and develop solutions on AWS.
Amazon DynamoDB is used by more than 100,000 customers around the world, handling over a trillion requests every day. From the start, DynamoDB has offered high availability by natively spanning multiple Availability Zones within an AWS Region. As more customers started building and deploying truly-global applications, there was a need to replicate a DynamoDB table to multiple AWS Regions, allowing for read/write operations to occur in any region where the table was replicated. This update is important for providing a globally-consistent view of information — as users may transition from one region to another — or for providing additional levels of availability, allowing for failover between AWS Regions without loss of information.
There are some interesting concurrency-design aspects you need to be aware of and ensure you can handle correctly. For example, we support the “last writer wins” reconciliation where eventual consistency is being used and an application updates the same item in different AWS Regions at the same time. If you require strongly-consistent read/writes then you must perform all of your read/writes in the same AWS Region. The details behind this can be found in the DynamoDB documentation. Providing a globally-distributed, replicated DynamoDB table simplifies many different use cases and allows for the logic of replication, which may have been pushed up into the application layers to be simplified back down into the data layer.
The other big update for DynamoDB is that you can now back up your DynamoDB table on demand with no impact to performance. One of the features I really like is that when you trigger a backup, it is available instantly, regardless of the size of the table. Behind the scenes, we use snapshots and change logs to ensure a consistent backup. While backup is instant, restoring the table could take some time depending on its size and ranges — from minutes to hours for very large tables.
This feature is super important for those of you who work in regulated industries that often have strict requirements around data retention and backups of data, which sometimes limited the use of DynamoDB or required complex workarounds to implement some sort of backup feature in the past. This often incurred significant, additional costs due to increased read transactions on their DynamoDB tables.
Amazon Simple Storage Service (Amazon S3) was our first-released AWS service over 11 years ago, and it proved the simplicity and scalability of true API-driven architectures in the cloud. Today, Amazon S3 stores trillions of objects, with transactional requests per second reaching into the millions! Dealing with data as objects opened up an incredibly diverse array of use cases ranging from libraries of static images, game binary downloads, and application log data, to massive data lakes used for big data analytics and business intelligence. With Amazon S3, when you accessed your data in an object, you effectively had to write/read the object as a whole or use the range feature to retrieve a part of the object — if possible — in your individual use case.
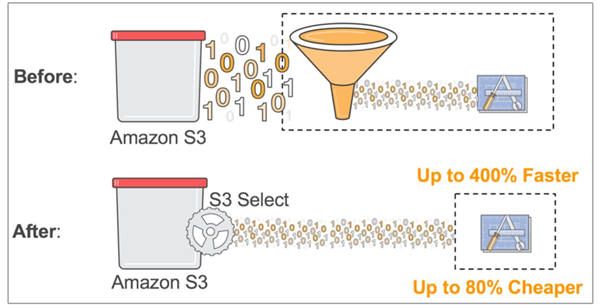
Now, with Amazon S3 Select, an SQL-like query language is used that can work with delimited text and JSON files, as well as work with GZIP compressed files. We don’t support encryption during the preview of Amazon S3 Select.
Amazon S3 Select provides two major benefits:
- Faster access
- Lower running costs
Serverless Lambda functions, where every millisecond matters when you are being charged, will benefit greatly from Amazon S3 Select as data retrieval and processing of your Lambda function will experience significant speedups and cost reductions. For example, we have seen 2x speed improvement and 80% cost reduction with the Serverless MapReduce code.
Other AWS services such as Amazon Athena, Amazon Redshift, and Amazon EMR will support Amazon S3 Select as well as partner offerings including Cloudera and Hortonworks. If you are using Amazon Glacier for longer-term data archival, you will be able to use Amazon Glacier Select to retrieve a subset of your content from within Amazon Glacier.
As the volume of data that can be stored within Amazon S3 and Amazon Glacier continues to scale on a daily basis, we will continue to innovate and develop improved and optimized services that will allow you to work with these magnificently-large data sets while reducing your costs (retrieval and processing). I believe this will also allow you to simplify the transformation and storage of incoming data into Amazon S3 in basic, semi-structured formats as a single copy vs. some of the duplication and reformatting of data sometimes required to do upfront optimizations for downstream processing. Amazon S3 Select largely removes the need for this upfront optimization and instead allows you to store data once and process it based on your individual Amazon S3 Select query per application or transaction need.
Thanks for reading!