AWS News Blog
Amazon Elasticsearch Service support for Elasticsearch 5.1

|
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
The Amazon Elasticsearch Service is a fully managed service that provides easier deployment, operation, and scale for the Elasticsearch open-source search and analytics engine. We are excited to announce that Amazon Elasticsearch Service now supports Elasticsearch 5.1 and Kibana 5.1.
Elasticsearch 5 comes with a ton of new features and enhancements that customers can now take advantage of in Amazon Elasticsearch service. Elements of the Elasticsearch 5 release are as follow:
- Indexing performance: Improved Indexing throughput with updates to lock implementation & async translog fsyncing
- Ingestion Pipelines: Incoming data can be sent to a pipeline that applies a series of ingestion processors, allowing transformation to the exact data you want to have in your search index. There are twenty processors included, from simple appending to complex regex applications
- Painless scripting: Amazon Elasticsearch Service supports Painless, a new secure and performant scripting language for Elasticsearch 5. You can use scripting to change the precedence of search results, delete index fields by query, modify search results to return specific fields, and more.
- New data structures: Lucene 6 data structures, new data types; half_float, text, keyword, and more complete support for dots-in-fieldnames
- Search and Aggregations: Refactored search API, BM25 relevance calculations, Instant Aggregations, improvements to histogram aggregations & terms aggregations, and rewritten percolator & completion suggester
- User experience: Strict settings and body & query string parameter validation, index management improvement, default deprecation logging, new shard allocation API, and new indices efficiency pattern for rollover & shrink APIs
- Java REST client: simple HTTP/REST Java client that works with Java 7 and handles retry on node failure, as well as, round-robin, sniffing, and logging of requests
- Other improvements: Lazy unicast hosts DNS lookup, automatic parallel tasking of reindex, update-by-query, delete-by-query, and search cancellation by task management API
The compelling new enhancements of Elasticsearch 5 are meant to make the service faster and easier to use while providing better security. Amazon Elasticsearch Service is a managed service designed to aid customers in building, developing and deploying solutions with Elasticsearch by providing the following capabilities:
- Multiple configurations of instance types
- Amazon EBS volumes for data storage
- Cluster stability improvement with dedicated master nodes
- Zone awareness – Cluster node allocation across two Availability Zones in the region
- Access Control & Security with AWS Identity and Access Management (IAM)
- Various geographical locations/regions for resources
- Amazon Elasticsearch domain snapshots for replication, backup and restore
- Integration with Amazon CloudWatch for monitoring Amazon Elasticsearch domain metrics
- Integration with AWS CloudTrail for configuration auditing
- Integration with other AWS Services like Kinesis Firehose and DynamoDB for loading of real-time streaming data into Amazon Elasticsearch Service
Amazon Elasticsearch Service allows dynamic changes with zero downtime. You can add instances, remove instances, change instance sizes, change storage configuration, and make other changes dynamically.
The best way to highlight some of the aforementioned capabilities is with an example.
During a presentation at the IT/Dev conference, I demonstrated how to build a serverless employee onboarding system using Express.js, AWS Lambda, Amazon DynamoDB, and Amazon S3. In the demo, the information collected was personnel data stored in DynamoDB about an employee going through a fictional onboarding process. Imagine if the collected employee data could be searched, queried, and analyzed as needed by the company’s HR department. We can easily augment the onboarding system to add these capabilities by enabling the employee table to use DynamoDB Streams to trigger Lambda and store the desired employee attributes in Amazon Elasticsearch Service.
The result is the following solution architecture:
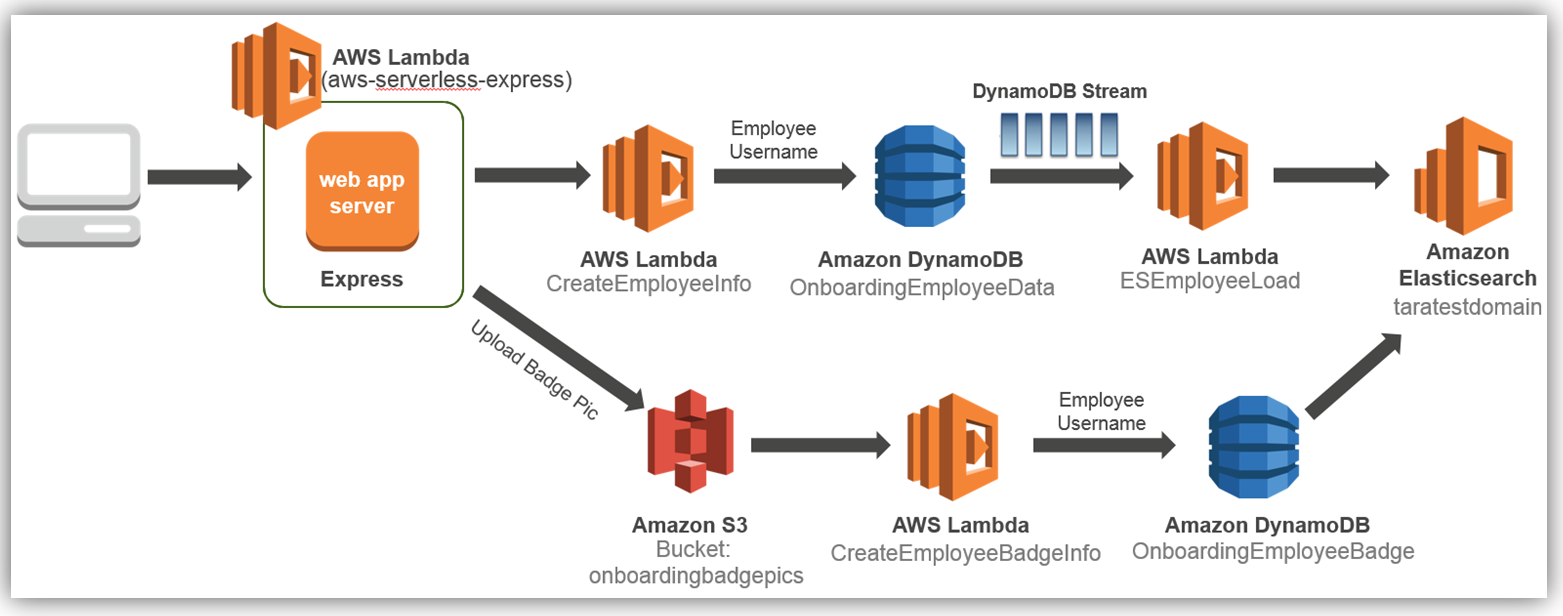
We will focus solely on how to dynamically store and index employee data to Amazon Elasticseach Service each time an employee record is entered and subsequently stored in the database.
To add this enhancement to the existing aforementioned onboarding solution, we will implement the solution as noted by the detailed cloud architecture diagram below:
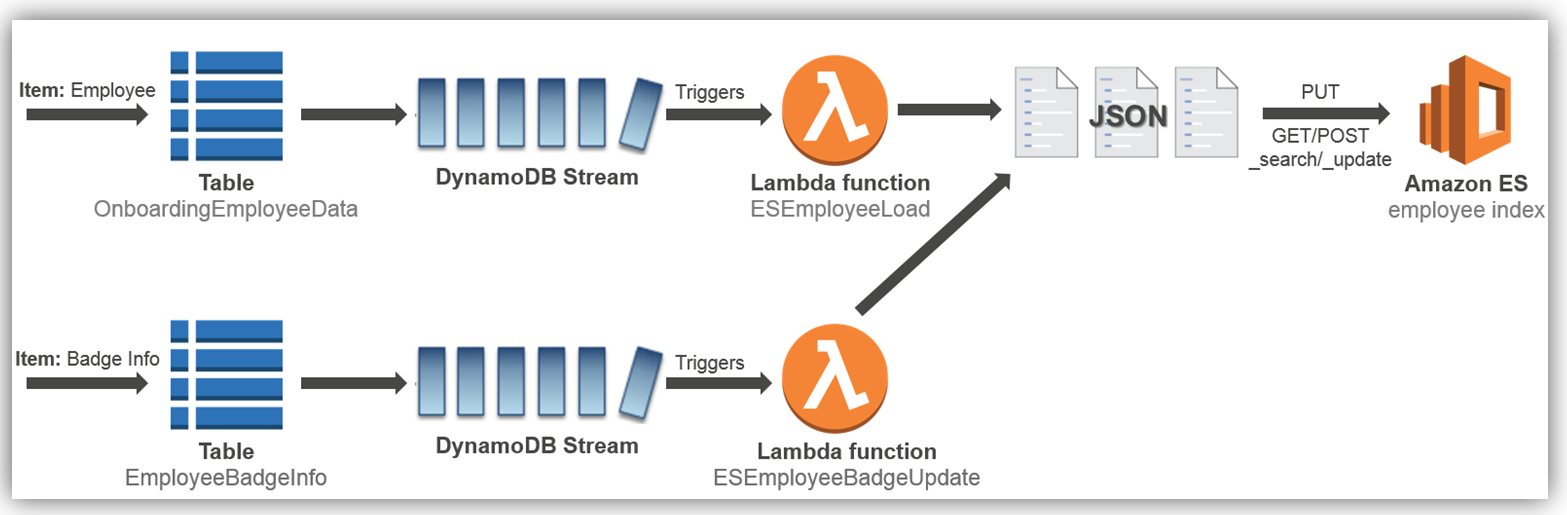
Let’s look at how to implement the employee load process to the Amazon Elasticsearch Service, which is the first process flow shown in the diagram above.
Amazon Elasticsearch Service: Domain Creation
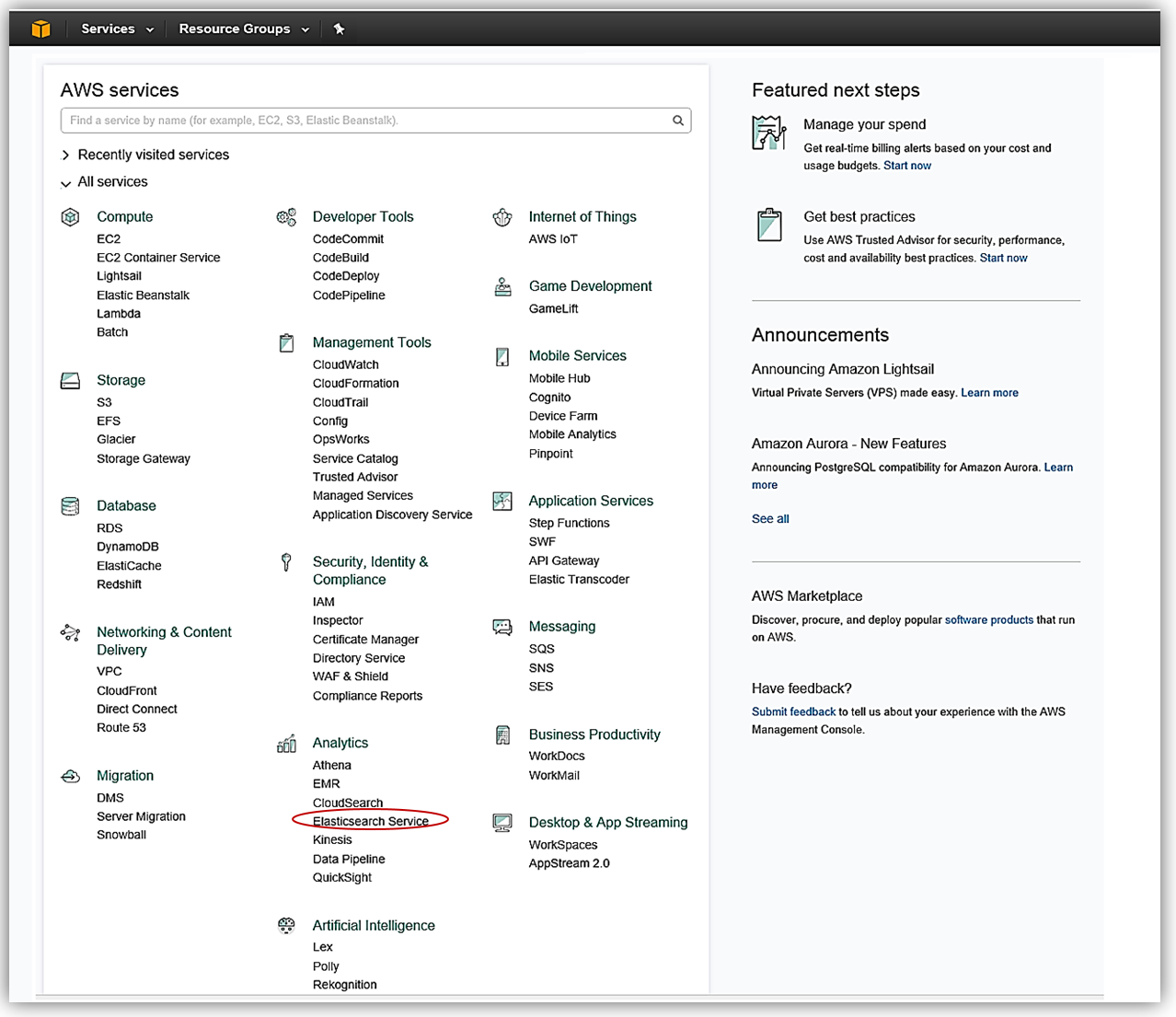
Let’s now visit the AWS Console to check out Amazon Elasticsearch Service with Elasticsearch 5 in action. As you probably guessed, from the AWS Console home, we select Elasticsearch Service under the Analytics group.
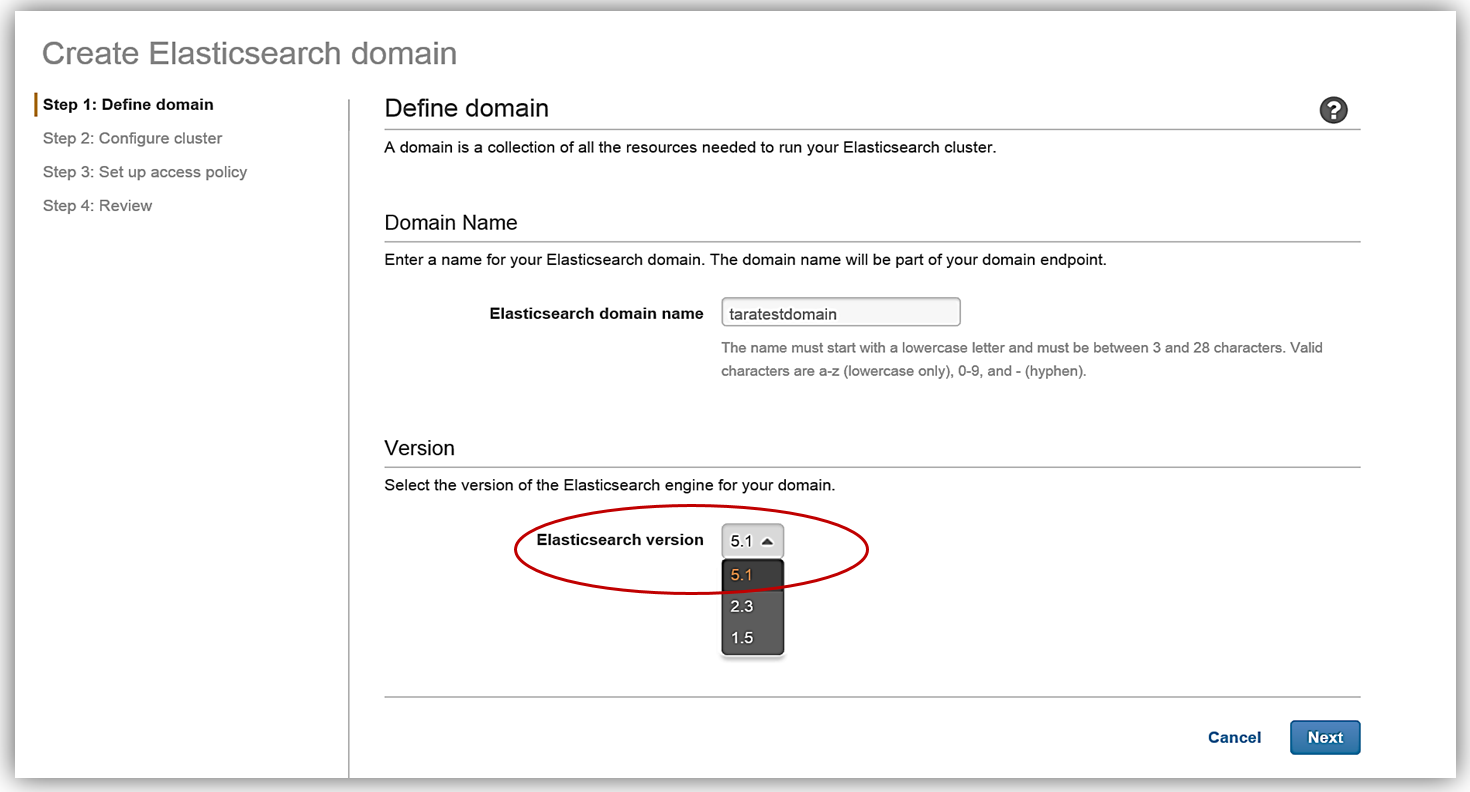
The first step in creating an Elasticsearch solution is to create a domain. You will notice that now when creating an Amazon Elasticsearch Service domain, you now have the option to choose the Elasticsearch 5.1 version. Since we are discussing the launch of the support of Elasticsearch 5, we will, of course, choose the 5.1 Elasticsearch engine version when creating our domain in the Amazon Elasticsearch Service.
After clicking Next, we will now setup our Elasticsearch domain by configuring our instance and storage settings. The instance type and the number of instances for your cluster should be determined based upon your application’s availability, network volume, and data needs. A recommended best practice is to choose two or more instances in order to avoid possible data inconsistencies or split brain failure conditions with Elasticsearch. Therefore, I will choose two instances/data nodes for my cluster and set up EBS as my storage device.
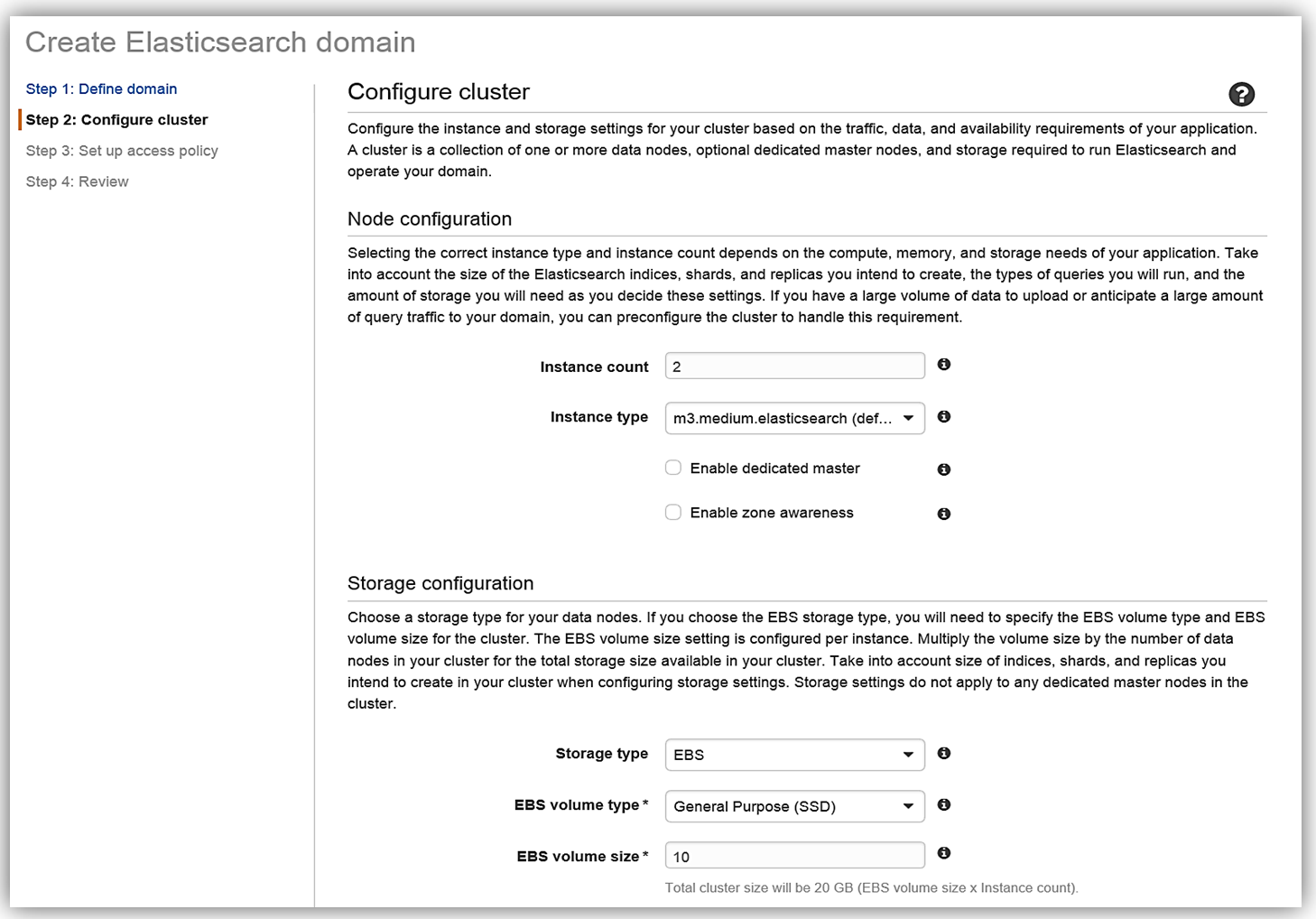
To understand how many instances you will need for your specific application, please review the blog post, Get Started with Amazon Elasticsearch Service: How Many Data Instances Do I Need, on the AWS Database blog.
All that is left for me is to set up the access policy and deploy the service. Once I create my service, the domain will be initialized and deployed.
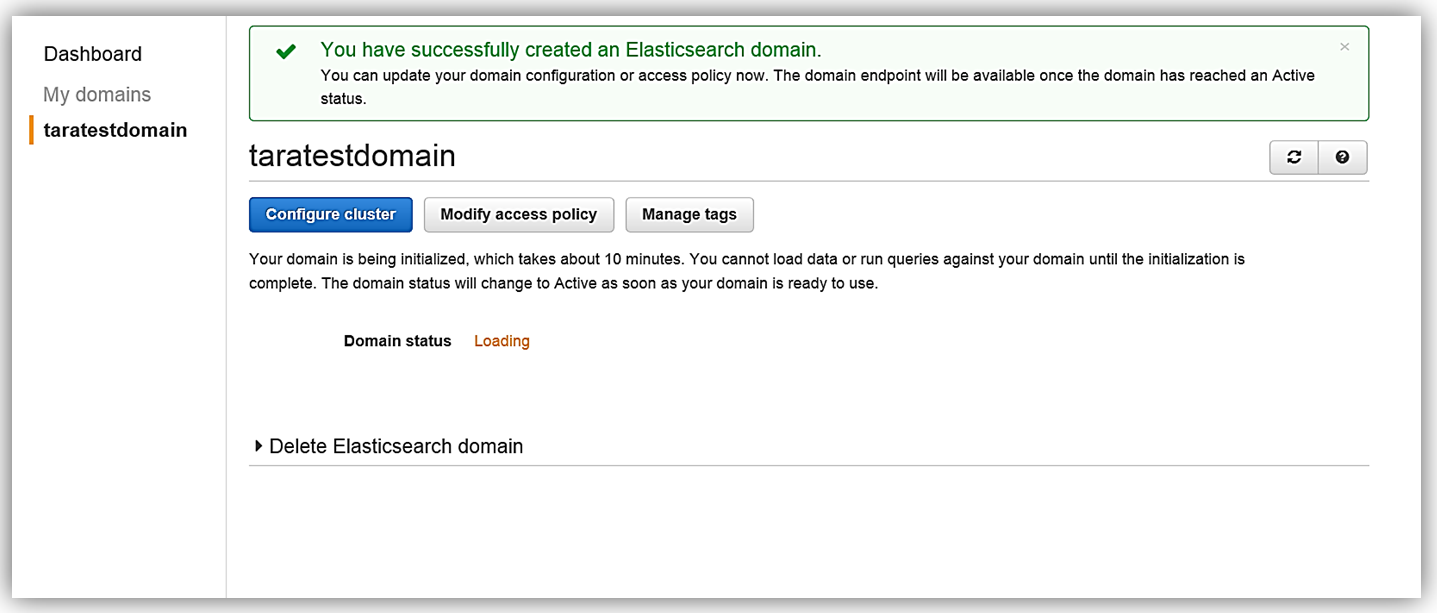
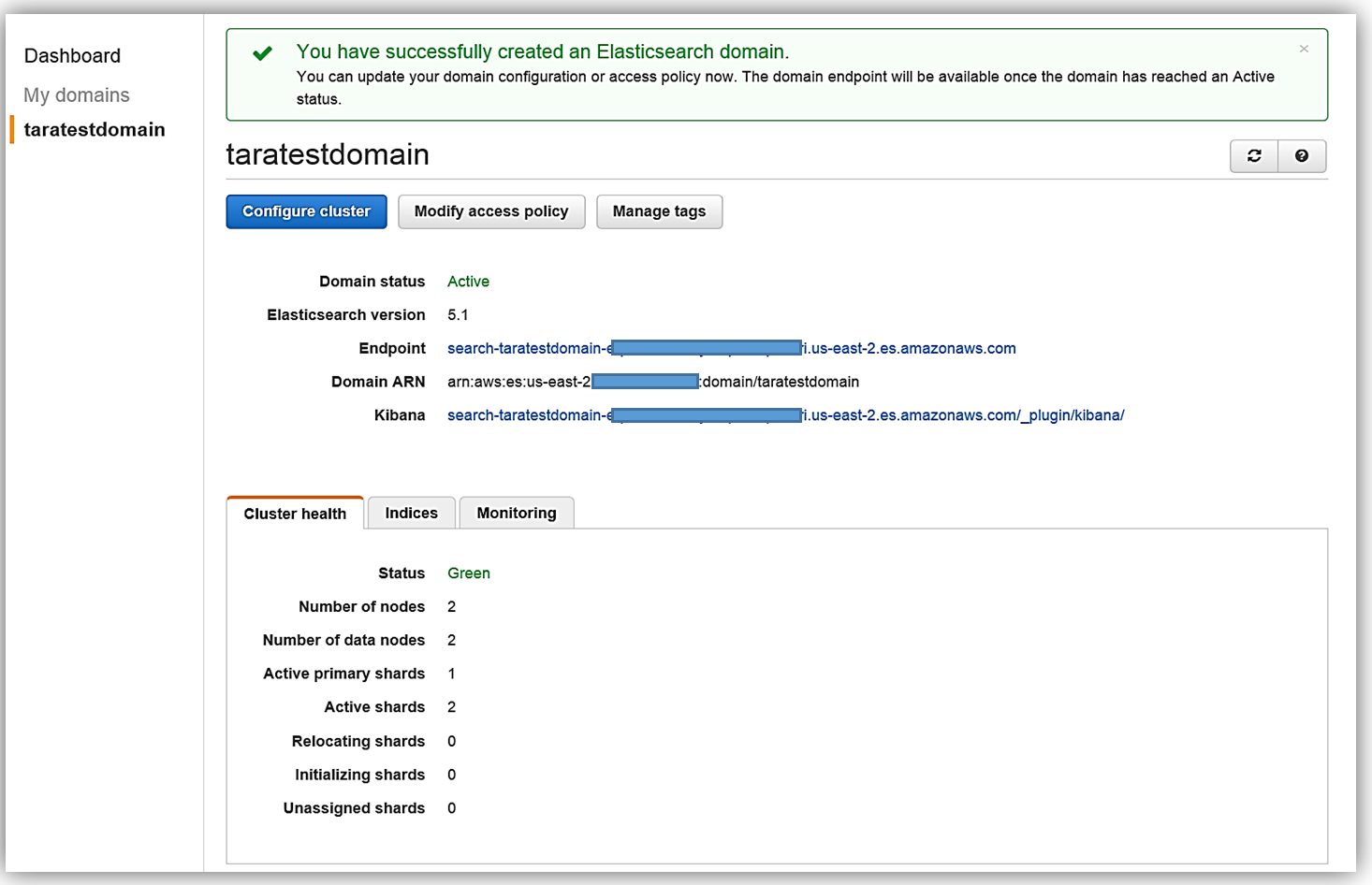
Now that I have my Elasticsearch service running, I now need a mechanism to populate it with data. I will implement a dynamic data load process of the employee data to Amazon Elasticsearch Service using DynamoDB Streams.
Amazon DynamoDB: Table and Streams
Before I head to the DynamoDB console, I will quickly cover the basics.
Amazon DynamoDB is a scalable, distributed NoSQL database service. DynamoDB Streams provide an ordered, time-based sequence of every CRUD operation to the items in a DynamoDB table. Each stream record has information about the primary attribute modification for an individual item in the table. Streams execute asynchronously and can write stream records in practically real time. Additionally, a stream can be enabled when a table is created or can be enabled and modified on an existing table. You can learn more about DynamoDB Streams in the DynamoDB developer guide.
Now we will head to the DynamoDB console and view the OnboardingEmployeeData table.
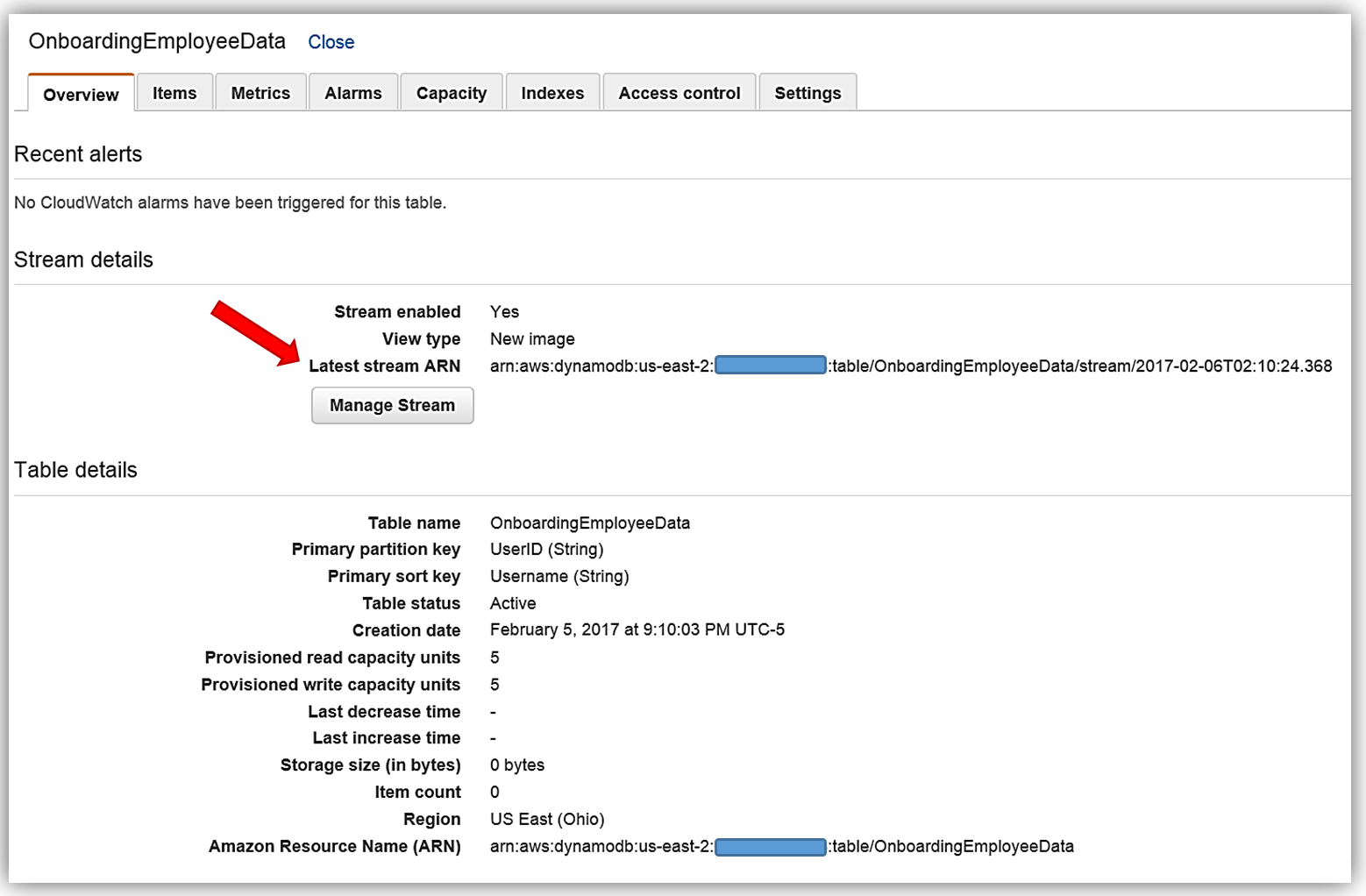
This table has a primary partition key, UserID, that is a string data type and a primary sort key, Username, which is also of a string data type. We will use the UserID as the document ID in Elasticsearch. You will also notice that on this table, streams are enabled and the stream view type is New image. A stream that is set to a New image view type will have stream records that display the entire item record after it has been updated. You also have the option to have the stream present records that provide data items before modification, provide only the items’ key attributes, or provide old and new item information. If you opt to use the AWS CLI to create your DynamoDB table, the key information to capture is the Latest Stream ARN shown underneath the Stream Details section. A DynamoDB stream has a unique ARN identifier that is outside of the ARN of the DynamoDB table. The stream ARN will be needed to create the IAM policy for access permissions between the stream and the Lambda function.

IAM Policy
The first thing that is essential for any service implementation is getting the correct permissions in place. Therefore, I will first go to the IAM console to create a role and a policy for my Lambda function that will provide permissions for DynamoDB and Elasticsearch.
First, I will create a policy based upon an existing managed policy for Lambda execution with DynamoDB Streams.
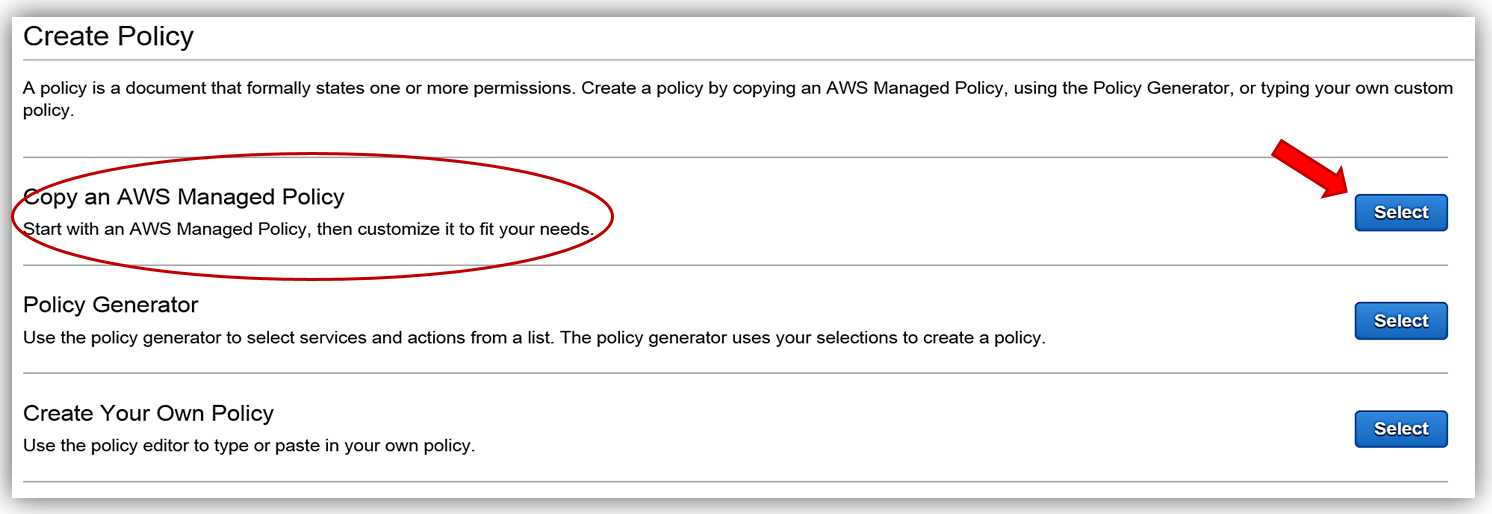
This will take us to the Review Policy screen, which will have the selected managed policy details. I’ll name this policy, Onboarding-LambdaDynamoDB-toElasticsearch, and then customize the policy for my solution. The first thing you should notice is that the current policy allows access to all streams, however, the best practice would be to have this policy only access the specific DynamoDB Stream by adding the Latest Stream ARN. Hence, I will alter the policy and add the ARN for the DynamoDB table, OnboardingEmployeeData, and validate the policy. The altered policy is as shown below.
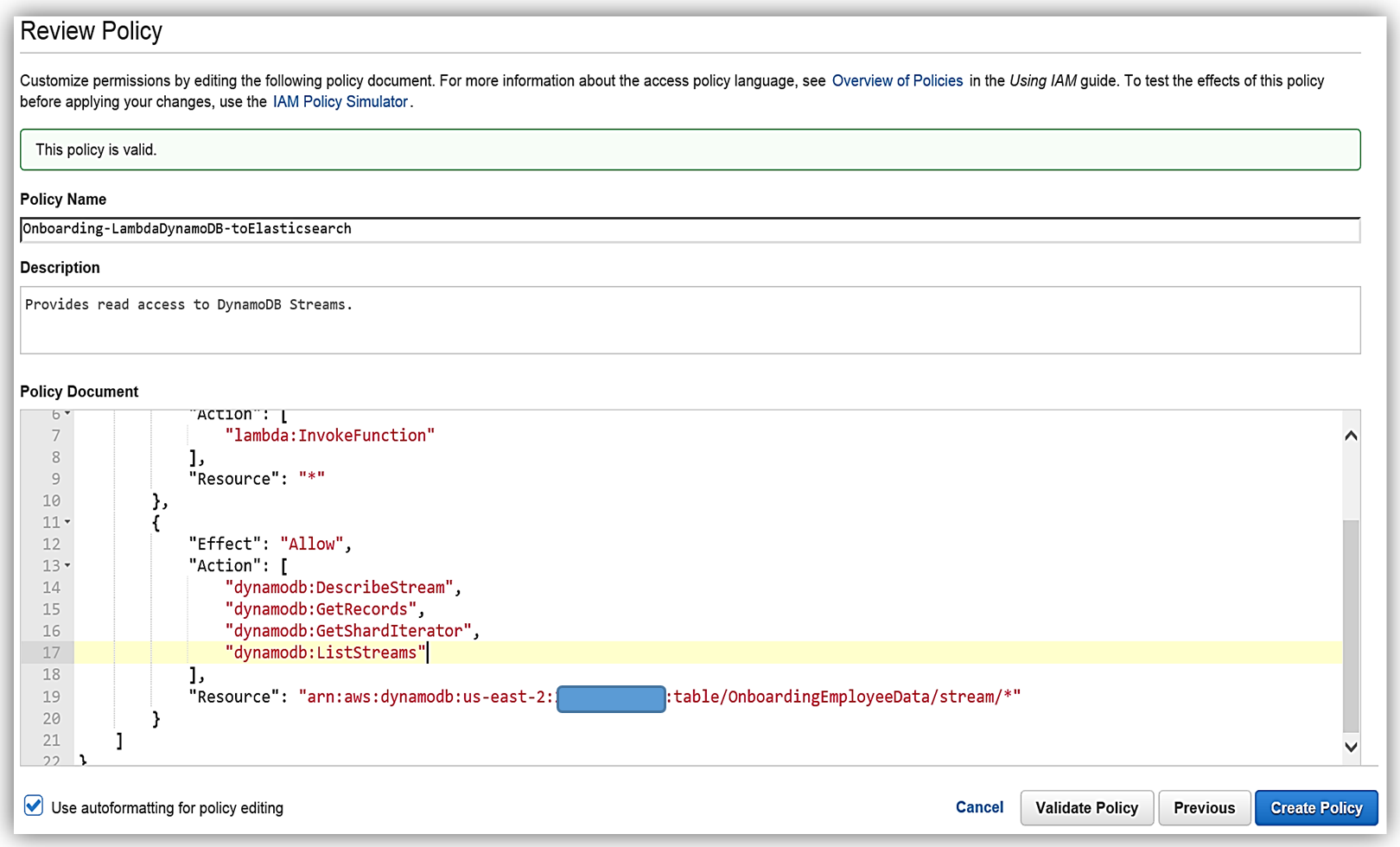
The only thing left is to add the Amazon Elasticsearch Service permissions in the policy. The core policy for Amazon Elasticsearch Service access permissions is as shown below:

I will use this policy and add the specific Elasticsearch domain ARN as the Resource for the policy. This ensures that I have a policy that enforces the Least Privilege security best practice for policies. With the Amazon Elasticsearch Service domain added as shown, I can validate and save the policy.
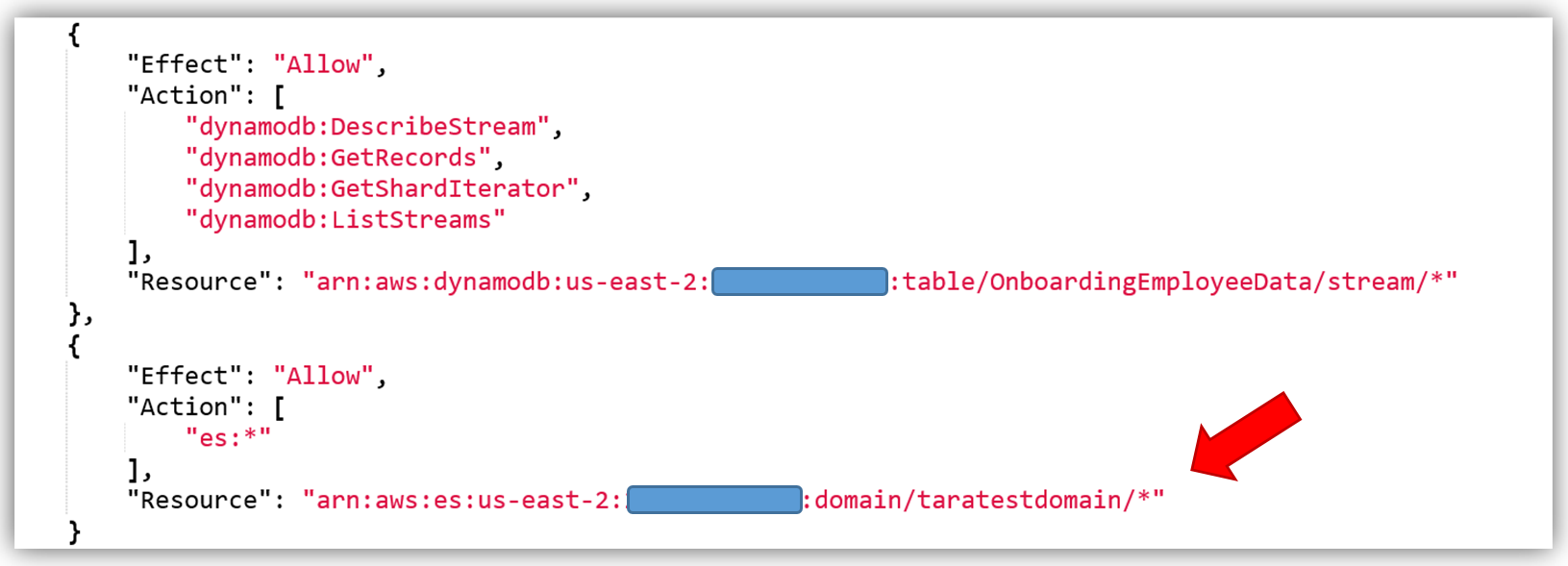
The best way to create a custom policy is to use the IAM Policy Simulator or view the examples of the AWS service permissions from the service documentation. You can also find some examples of policies for a subset of AWS Services here. Remember you should only add the ES permissions that are needed using the Least Privilege security best practice, the policy shown above is used only as an example.
We will create the role for our Lambda function to use to grant access and attach the aforementioned policy to the role.
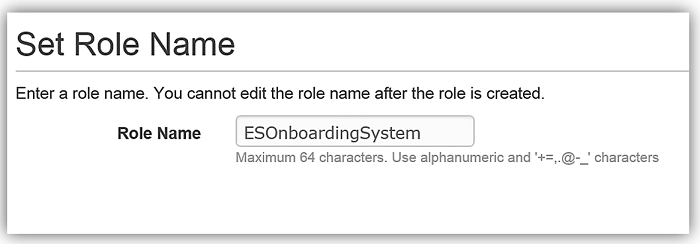
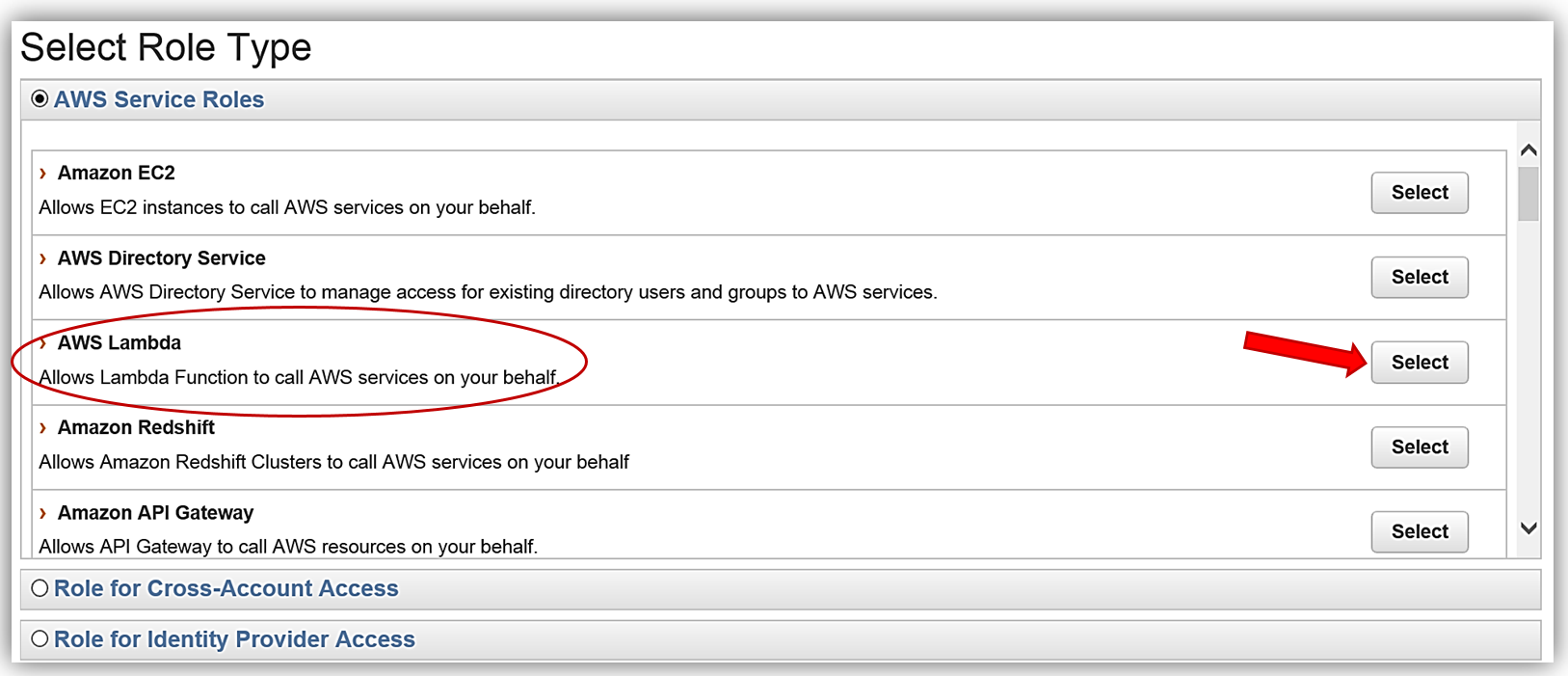
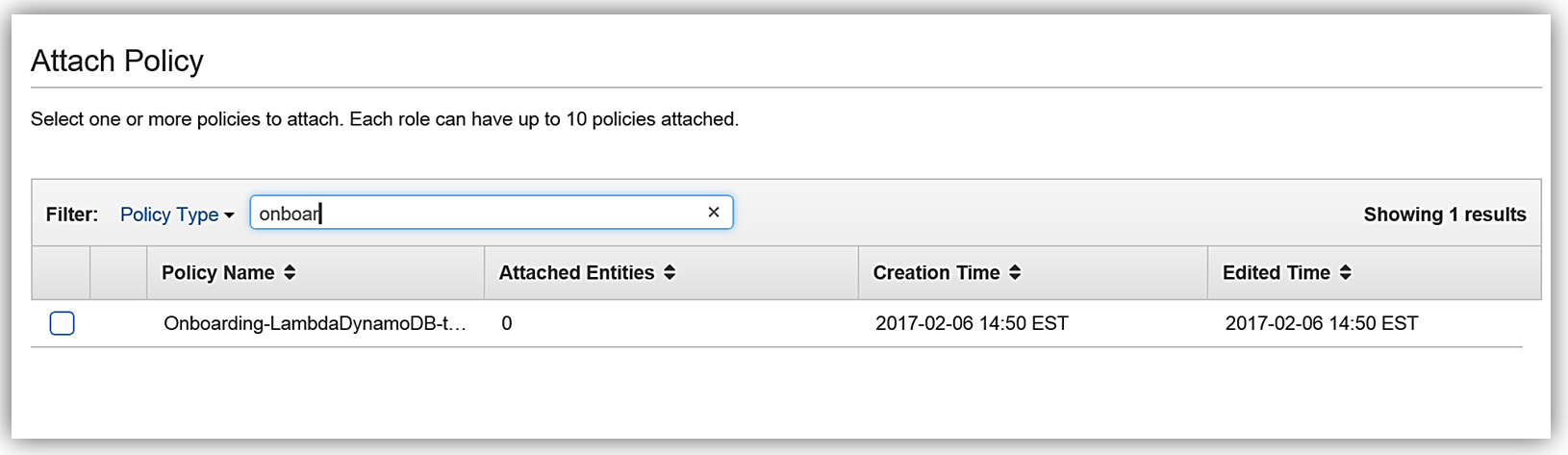
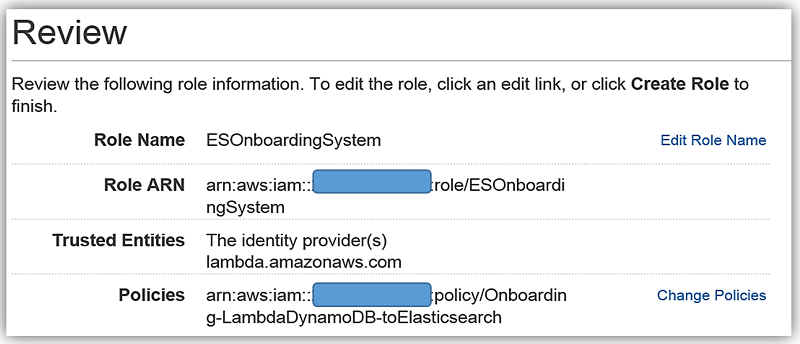
AWS Lambda: DynamoDB triggered Lambda function
AWS Lambda is the core of Amazon Web Services serverless computing offering. With Lambda, you can write and run code using supported languages for almost any type of application or backend service. Lambda will trigger your code in response to events from AWS services or from HTTP requests. Lambda will dynamically scale based upon workload and you only pay for your code execution.
We will have DynamoDB streams trigger a Lambda function that will create an index and send data to Elasticsearch. Another option for this is to use the Logstash plugin for DynamoDB. However, since several of the Logstash processors are now included in Elasticsearch 5.1 core and with the improved performance optimizations, I will opt to use Lambda to process my DynamoDB stream and load data to Amazon Elasticsearch Service.
Now let us head over to the AWS Lambda console and create the lambda function for loading employee data to Amazon Elasticsearch Service.
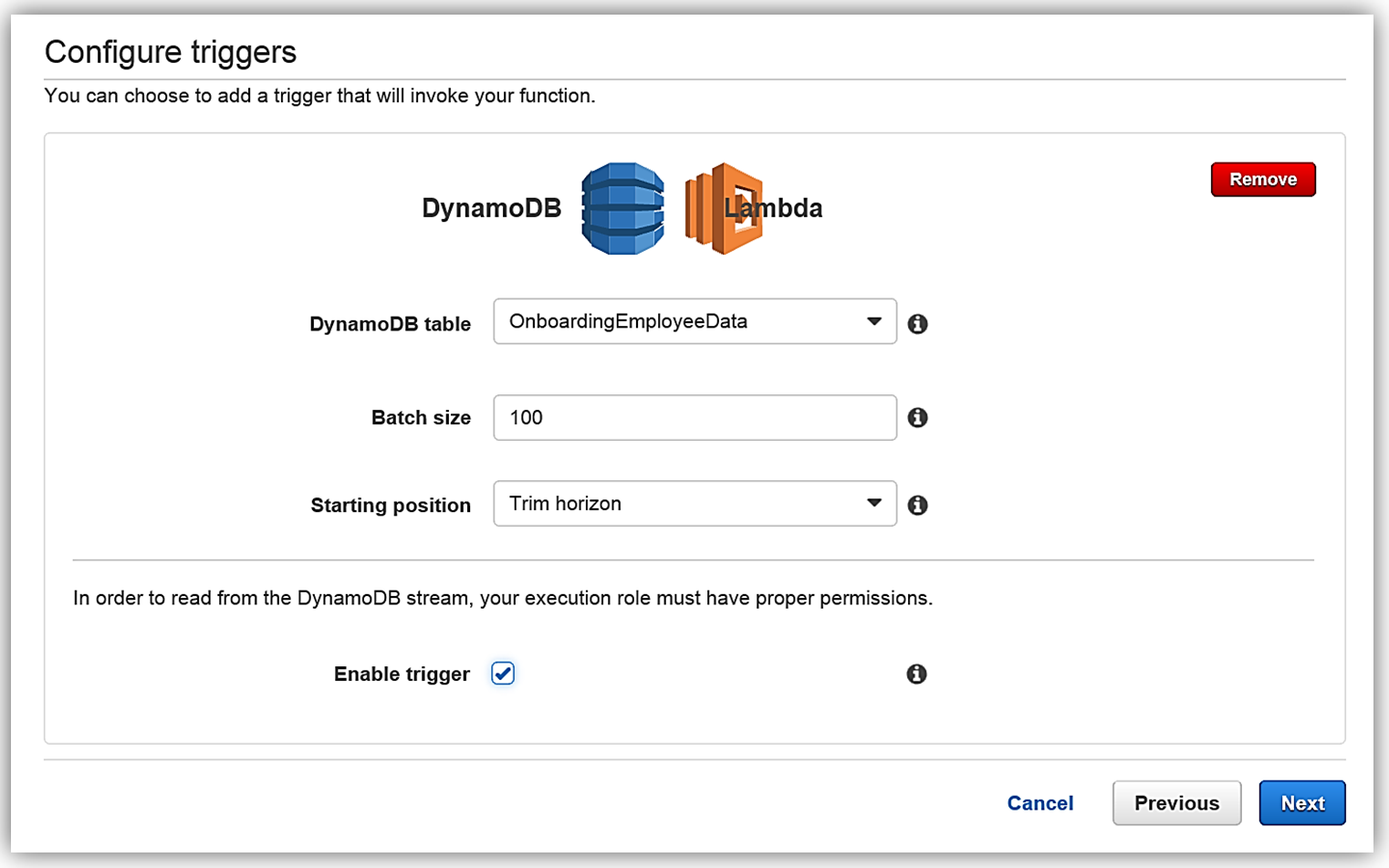
Once in the console, I will create a new Lambda function by selecting the Blank Function blueprint that will take me to the Configure Trigger page. Once on the trigger page, I will select DynamoDB as the AWS service which will trigger Lambda, and I provide the following trigger related options:
- Table: OnboardingEmployeeData
- Batch size: 100 (default)
- Starting position: Trim Horizon
I hit Next button, and I am on the Configure Function screen. The name of my function will be ESEmployeeLoad and I will write this function in Node.4.3.
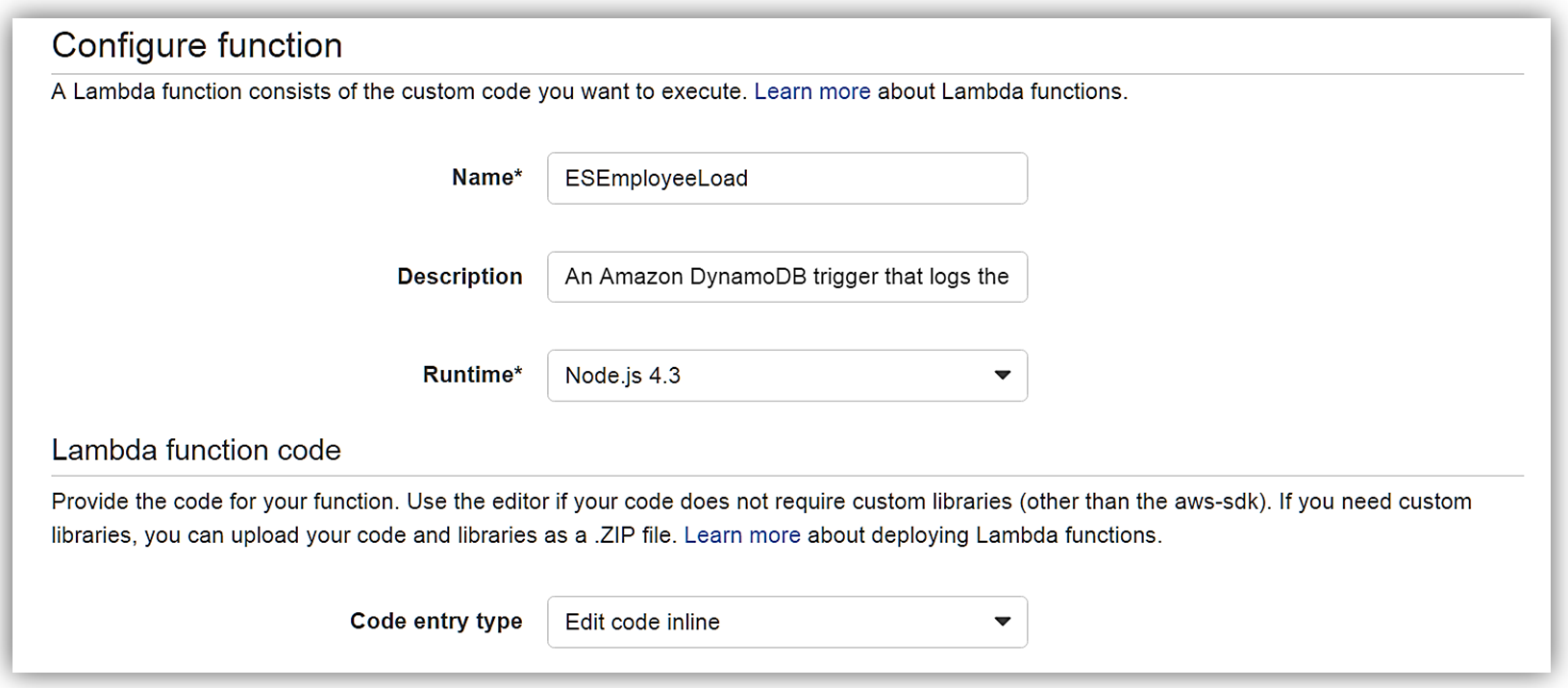
The Lambda function code is as follows:
var AWS = require('aws-sdk');
var path = require('path');
//Object for all the ElasticSearch Domain Info
var esDomain = {
region: process.env.RegionForES,
endpoint: process.env.EndpointForES,
index: process.env.IndexForES,
doctype: 'onboardingrecords'
};
//AWS Endpoint from created ES Domain Endpoint
var endpoint = new AWS.Endpoint(esDomain.endpoint);
//The AWS credentials are picked up from the environment.
var creds = new AWS.EnvironmentCredentials('AWS');
console.log('Loading function');
exports.handler = (event, context, callback) => {
//console.log('Received event:', JSON.stringify(event, null, 2));
console.log(JSON.stringify(esDomain));
event.Records.forEach((record) => {
console.log(record.eventID);
console.log(record.eventName);
console.log('DynamoDB Record: %j', record.dynamodb);
var dbRecord = JSON.stringify(record.dynamodb);
postToES(dbRecord, context, callback);
});
};
function postToES(doc, context, lambdaCallback) {
var req = new AWS.HttpRequest(endpoint);
req.method = 'POST';
req.path = path.join('/', esDomain.index, esDomain.doctype);
req.region = esDomain.region;
req.headers['presigned-expires'] = false;
req.headers['Host'] = endpoint.host;
req.body = doc;
var signer = new AWS.Signers.V4(req , 'es'); // es: service code
signer.addAuthorization(creds, new Date());
var send = new AWS.NodeHttpClient();
send.handleRequest(req, null, function(httpResp) {
var respBody = '';
httpResp.on('data', function (chunk) {
respBody += chunk;
});
httpResp.on('end', function (chunk) {
console.log('Response: ' + respBody);
lambdaCallback(null,'Lambda added document ' + doc);
});
}, function(err) {
console.log('Error: ' + err);
lambdaCallback('Lambda failed with error ' + err);
});
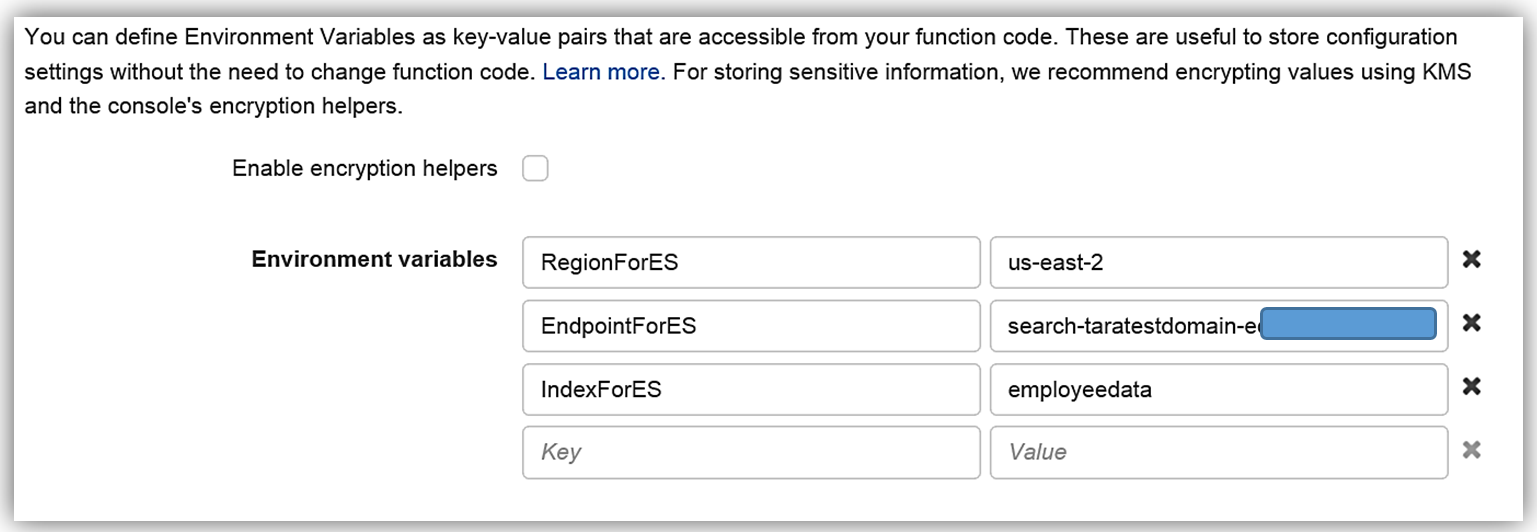
}The Lambda function Environment variables are:
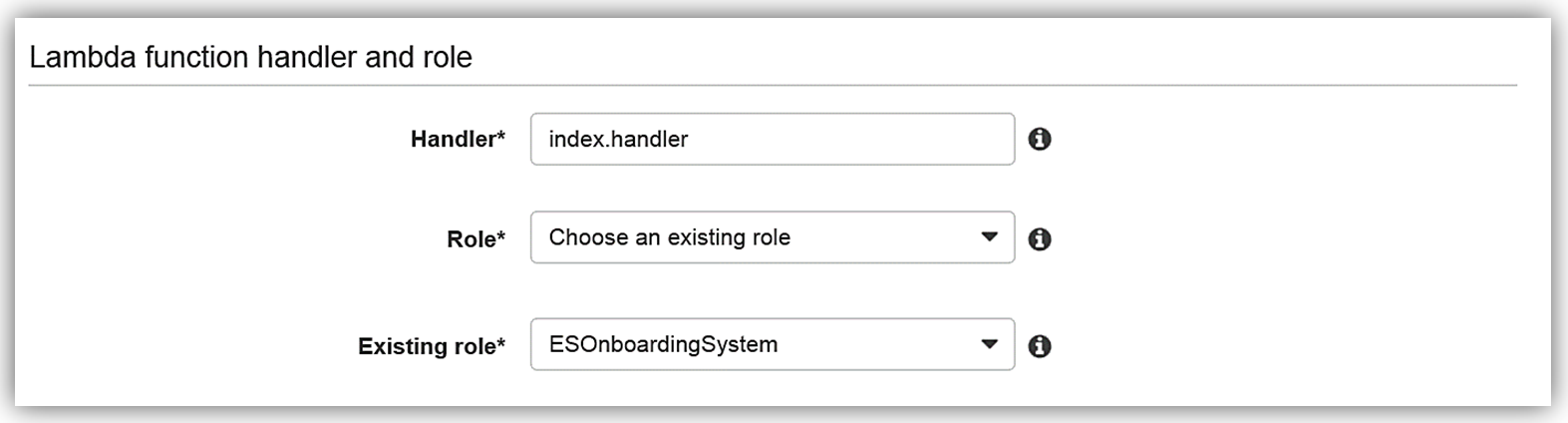
I will select an Existing role option and choose the ESOnboardingSystem IAM role I created earlier.
Upon completing my IAM role permissions for the Lambda function, I can review the Lambda function details and complete the creation of ESEmployeeLoad function.
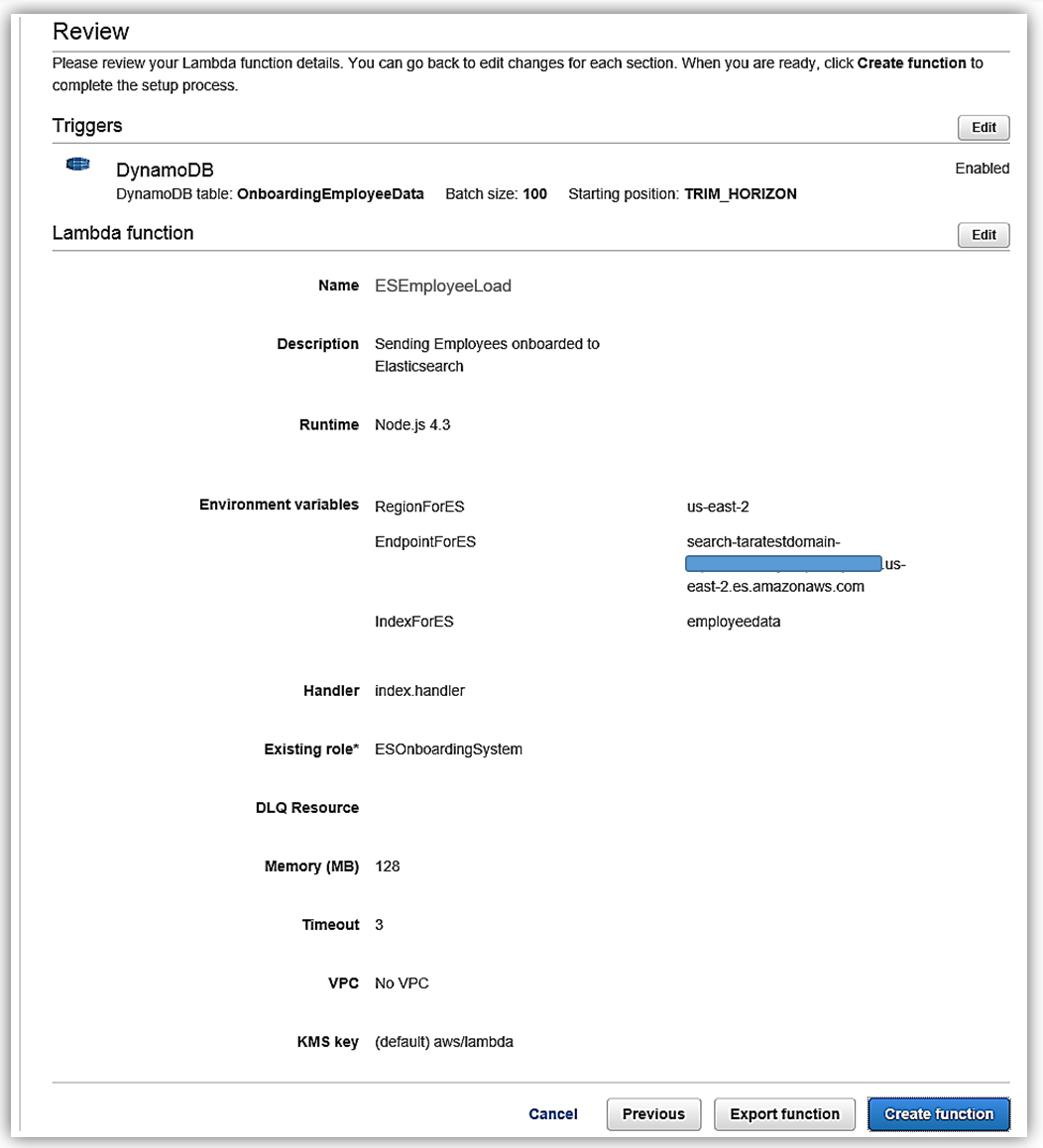
I have completed the process of building my Lambda function to talk to Elasticsearch, and now I test my function my simulating data changes to my database.
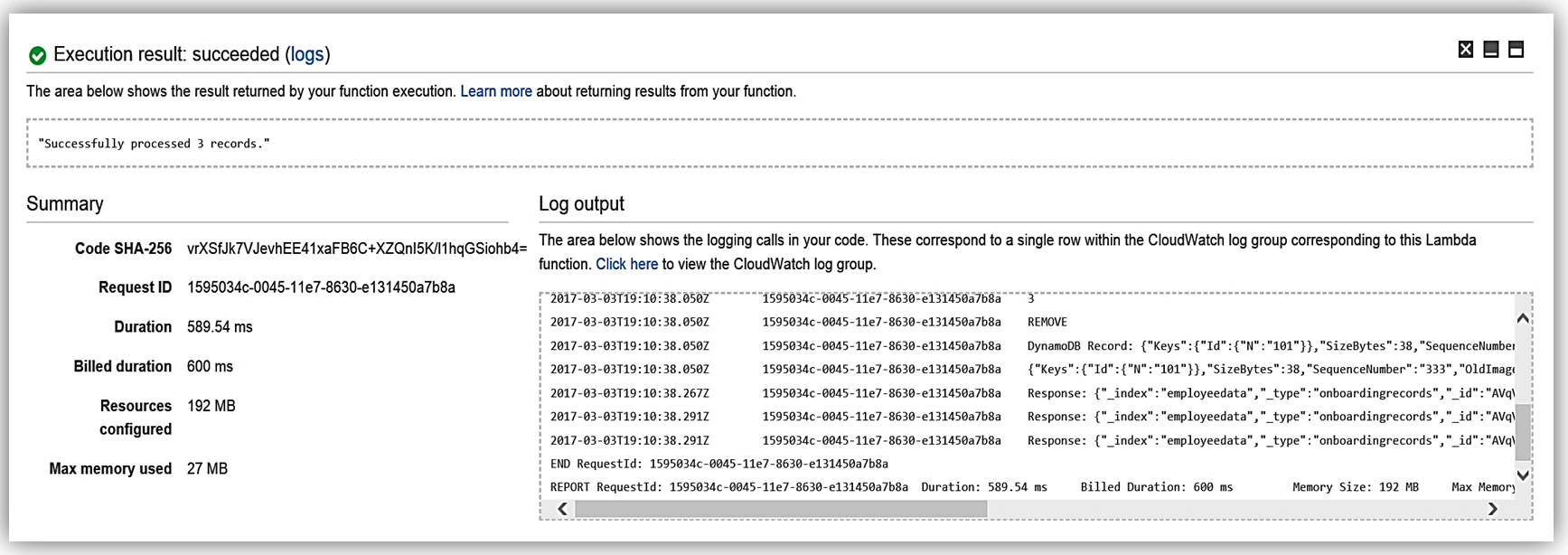
Now my function, ESEmployeeLoad, will execute upon changes to the data in my database from my onboarding system. Additionally, I can review the processing of the Lambda function to Elasticsearch by reviewing the CloudWatch logs.
Now I can alter my Lambda function to take advantage of the new features or go directly to Elasticsearch and utilize the new Ingest Mode. An example of this would be to implement a pipeline for my Employee record documents.

I can replicate this function for handling the badge updates to the employee record, and/or leverage other preprocessors against the employee data. For instance, if I wanted to do a search of data based upon a data parameter in the Elasticsearch document, I could use the Search API and get records from the dataset.


The possibilities are endless, and you can get as creative as your data needs dictate while maintaining great performance.
Amazon Elasticsearch Service: Kibana 5.1
All Amazon Elasticsearch Service domains using Elasticsearch 5.1 are bundled with Kibana 5.1, the latest version of the open-source visualization tool.
The companion visualization and analytics platform, Kibana, has also been enhanced in the Kibana 5.1 release. Kibana is used to view, search or and interact with Elasticsearch data with a myriad of different charts, tables, and maps. In addition, Kibana performs advanced data analysis of large volumes of the data. Key enhancements of the Kibana release are as follows:
- Visualization tool new design: Updated color scheme and maximization of screen real-estate
- Timelion: visualization tool with a time-based query DSL
- Console: formerly known as Sense is now part of the core, using the same configuration for free-form requests to Elasticsearch
- Scripted field language: ability use new Painless scripting language in the Elasticsearch cluster
- Tag Cloud Visualization: 5.1 adds a word base graphical view of data sized by importance
- More Charts: return of previously removed charts and addition of advanced view for X-Pack
- Profiler UI:1 provides an enhancement to profile API with tree view
- Rendering performance improvement: Discover performance fixes, decrease of CPU load
Summary
As you can see this release is expansive with many enhancements to assist customers in building Elasticsearch solutions. Amazon Elasticsearch Service now supports 15 new Elasticsearch APIs and 6 new plugins. Amazon Elasticsearch Service supports the following operations for Elasticsearch 5.1:

You can read more about the supported operations for Elasticsearch in the Amazon Elasticsearch Developer Guide, and you can get started by visiting the Amazon Elasticsearch Service website and/or sign into the AWS Management Console.
– Tara