AWS News Blog
AWS Clean Rooms launches privacy-enhancing synthetic dataset generation for ML model training

|
Today, we’re announcing privacy-enhancing synthetic dataset generation for AWS Clean Rooms, a new capability that organizations and their partners can use to generate privacy-enhancing synthetic datasets from their collective data to train regression and classification machine learning (ML) models. You can use this feature to generate synthetic training datasets that preserve the statistical patterns of the original data, without the model having access to original records, opening new opportunities for model training that were previously not possible due to privacy concerns.
When building ML models, data scientists and analysts typically face a fundamental tension between data utility and privacy protection. Access to high-quality, granular data is essential for training accurate models that can recognize trends, personalize experiences, and drive business outcomes. However, using granular data such as user-level event data from multiple parties raises significant privacy concerns and compliance challenges. Organizations want to answer questions like, “What characteristics indicate a high-probability customer conversion?”, but training on the individual-level signals often conflicts with privacy policies and regulatory requirements.
Privacy-enhancing synthetic dataset generation for custom ML
To address this challenge, we’re introducing privacy-enhancing synthetic dataset generation in AWS Clean Rooms ML, which organizations can use to create synthetic versions of sensitive datasets that can be more securely used for ML model training. This capability uses advanced ML techniques to generate new datasets that maintain the statistical properties of the original data while de-identifying subjects from the original source data.
Traditional anonymization techniques such as masking still carry the risk of re-identifying individuals in a dataset—knowing attributes about a person such as zip code and date of birth can be sufficient to identify them with census data. Privacy-enhancing synthetic dataset generation addresses this risk through a fundamentally different approach. The system trains a model that learns the essential statistical patterns of the original dataset, then generates synthetic records by sampling values from the original dataset and using the model to predict the predicted value column. Rather than merely copying or perturbing the original data, the system uses a model capacity reduction technique to mitigate the risk that the model will memorize information about individuals in the training data. The resulting synthetic dataset has the same schema and statistical characteristics as the original data, making it suitable for training classification and regression models. This approach quantifiably reduces the risk of re-identification.
Organizations using this capability have control over the privacy parameters, including the amount of noise applied and the level of protection against membership inference attacks, where an adversary attempts to determine whether a specific individual’s data was included in the training set. After generating the synthetic dataset, AWS Clean Rooms provides detailed metrics to help customers and their compliance teams understand the quality of the synthetic dataset across two critical dimensions: fidelity to the original data and privacy preservation. The fidelity score uses KL-divergence to measure how similar the synthetic data is to the original dataset, and the privacy score quantifies how likely the dataset is protected from membership inference attacks.
Working with synthetic data in AWS Clean Rooms
Getting started with privacy-enhancing synthetic dataset generation follows the established AWS Clean Rooms ML custom models workflow, with new steps to specify privacy requirements and review quality metrics. Organizations begin by creating configured tables with analysis rules using their preferred data sources, then join or create a collaboration with their partners and associate their tables with that collaboration.
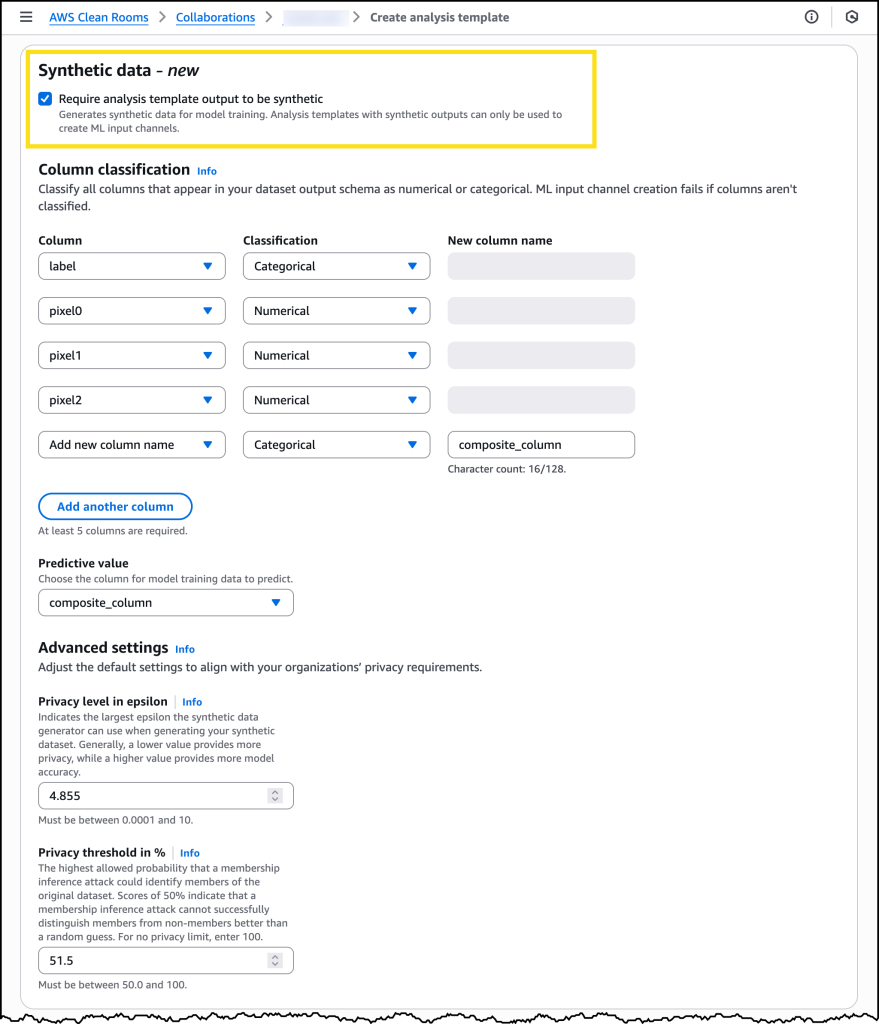
The new capability introduces an enhanced analysis template where data owners define not only the SQL query that creates the dataset but also specify that the resulting dataset must be synthetic. Within this template, organizations classify columns to indicate which column the ML model will predict and which columns contain categorical versus numerical values. Critically, the template also includes privacy thresholds that the generated synthetic data must meet to be made available for training. These include an epsilon value that specifies how much noise must be present in the synthetic data to protect against re-identification, and a minimum protection score against membership inference attacks. Setting these thresholds appropriately requires understanding your organization’s specific privacy and compliance requirements, and we recommend engaging with your legal and compliance teams during this process.
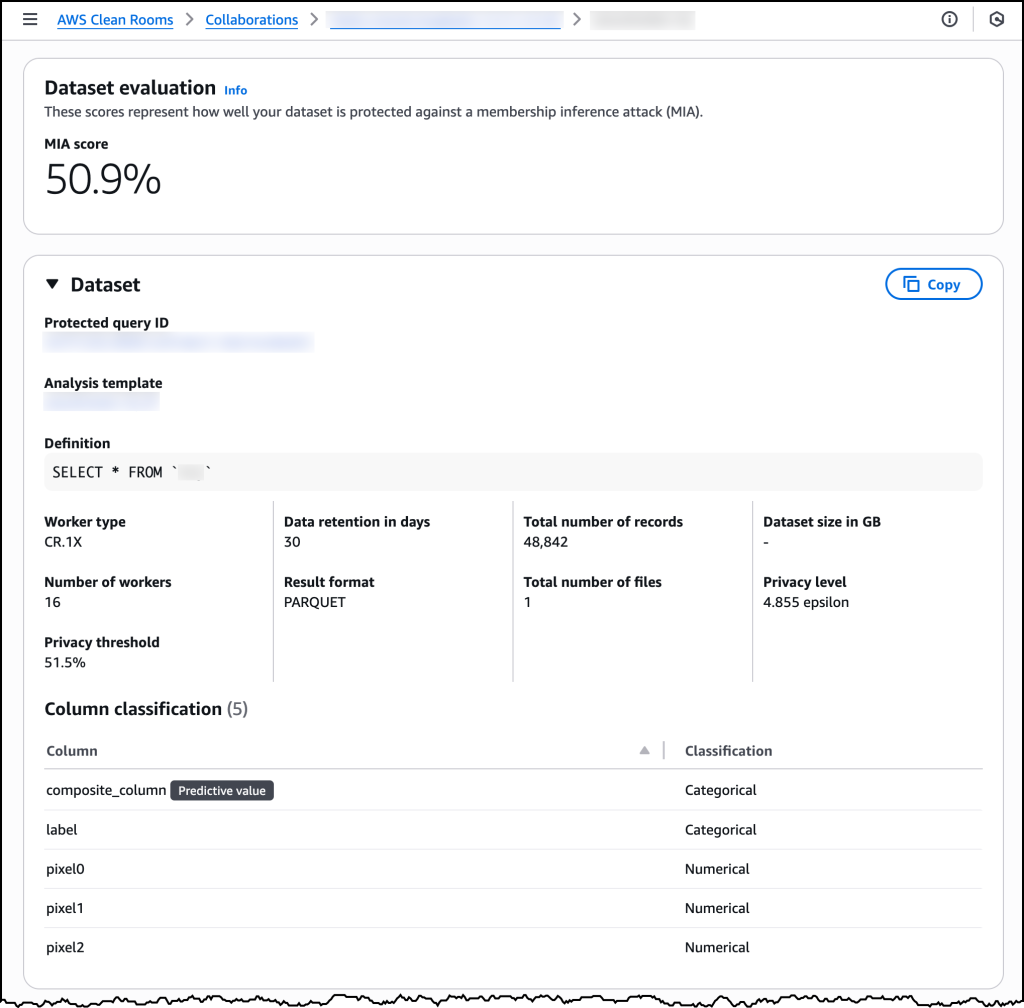
After all data owners review and approve the analysis template, a collaboration member creates a machine learning input channel that references the template. AWS Clean Rooms then begins the synthetic dataset generation process, which typically completes within a few hours depending on the size and complexity of the dataset. If the generated synthetic dataset meets the required privacy thresholds defined in the analysis template, a synthetic machine learning input channel becomes available along with detailed quality metrics. Data scientists can review the actual protection score achieved against a simulated membership inference attack.
Once satisfied with the quality metrics, organizations can proceed to train their ML models using the synthetic dataset within the AWS Clean Rooms collaboration. Depending on the use case, they can export the trained model weights or continue to run inference jobs within the collaboration itself.
Let’s try it out
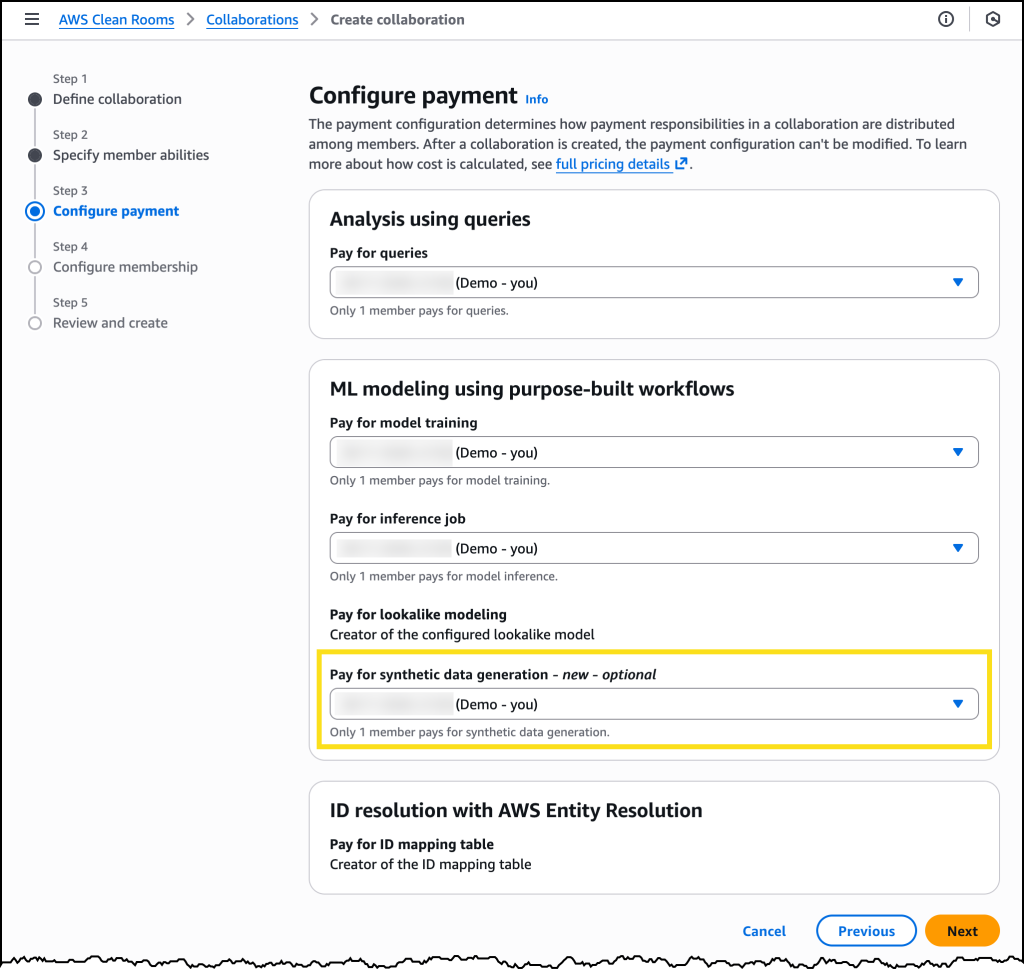
When creating a new AWS Clean Rooms collaboration, I can now set who pays for synthetic dataset generation.
After my Collaboration is configured, I can choose Require analysis template output to be synthetic when creating a new analysis template.
After my synthetic analysis template is ready, I can use it when running protected queries and view all the relevant ML input channel details.
Now available
You can start using privacy-enhancing synthetic dataset generation through AWS Clean Rooms today. The feature is available in all commercial AWS Regions where AWS Clean Rooms is available. Learn more about it in the AWS Clean Rooms documentation.
Privacy-enhancing synthetic dataset generation is billed separately based on usage. You pay only for the compute used to generate your synthetic dataset, charged as Synthetic Data Generation Units (SDGUs). The number of SDGUs varies based on the size and complexity of your original dataset. This fee can be configured as a payer setting, meaning any collaboration member can agree to pay the costs. For more information on pricing, refer to the AWS Clean Rooms pricing page.
The initial release supports training classification and regression models on tabular data. The synthetic datasets work with standard ML frameworks and can be integrated into existing model development pipelines without requiring changes to your workflows.
This capability represents a significant advancement in privacy-enhanced machine learning. Organizations can unlock the value of sensitive user-level data for model training while mitigating the risk that sensitive information about individual users could be leaked. Whether you’re optimizing advertising campaigns, personalizing insurance quotes, or enhancing fraud detection systems, privacy-enhancing synthetic dataset generation makes it possible to train more accurate models through data collaboration while respecting individual privacy.