AWS News Blog
AWS Data Pipeline – Now Ready for Use!

|
Update (May 2023) – AWS Data Pipeline service is in maintenance mode and no new features or region expansions are planned. To learn more and to find out how to migrate your existing workloads, please read Migrating workloads from AWS Data Pipeline.
The AWS Data Pipeline is now ready for use and you can sign up here.
As I described in my initial blog post, the AWS Data Pipeline gives you the power to automate the movement and processing of any amount of data using data-driven workflows and built-in dependency checking. You can access it from the command line, the APIs, or the AWS Management Console.
Today l’d like to show you how to use the AWS Management Console to create your own pipeline definition. Start by opening up the console and chosing Data Pipeline from the Services menu:

You’ll see the main page of the Data Pipeline console:
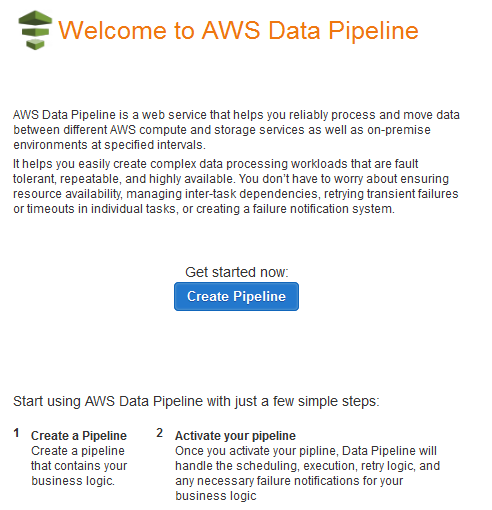
Click on Create Pipeline to get started, then fill in the form:
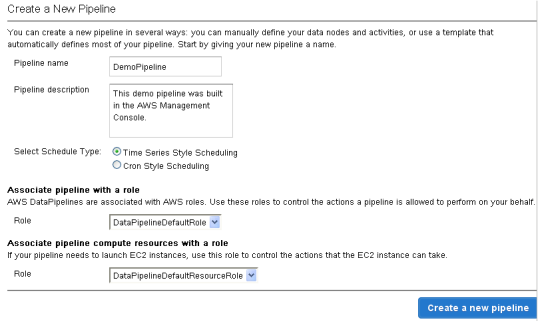
With that out of the way, you now have access to the actual Pipeline Editor:
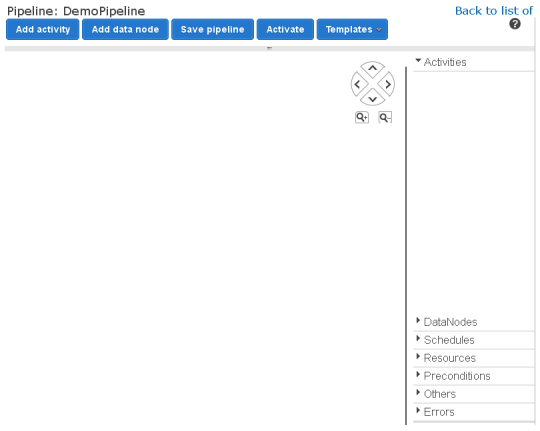
At this point you have two options. You can build the entire pipeline scratch or you can use one of the pre-defined templates as a starting point:
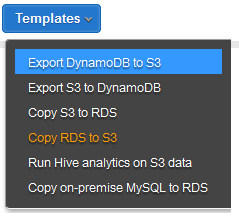
I’m going to use the first template, Export DynamoDB to S3. The pipeline is shown on the left side of the screen:
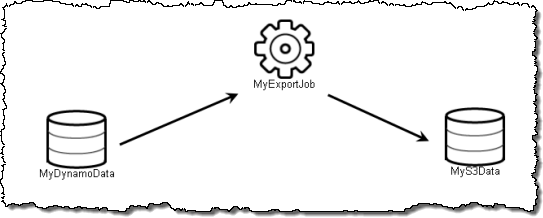
Clicking on an item to select it will show its attributes on the right side:
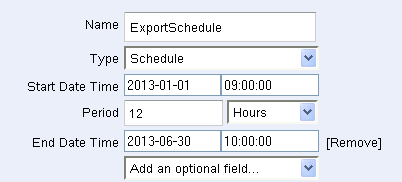
The ExportSchedule (an item of type Schedule) specifies how often the pipeline should be run, and over what time interval. Here I’ve specified that it should run every 12 hours for the first 6 months of 2013:
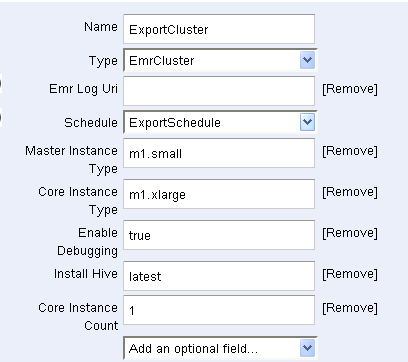
The ExportCluster (a Resource) specifies that an Elastic MapReduce cluster will be used to move the data:
MyDynamoData and MyS3Data specify the data source (a DynamoDB table) and the destination (an S3 bucket):
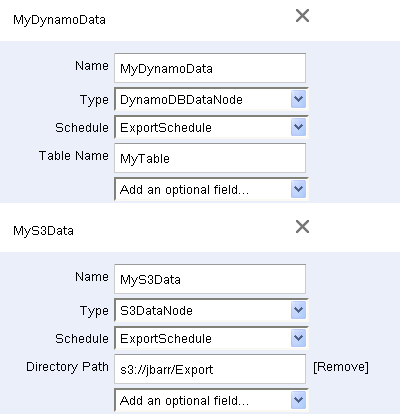
An Amazon SNS topic is used to provide notification of successes and failures (not shown):

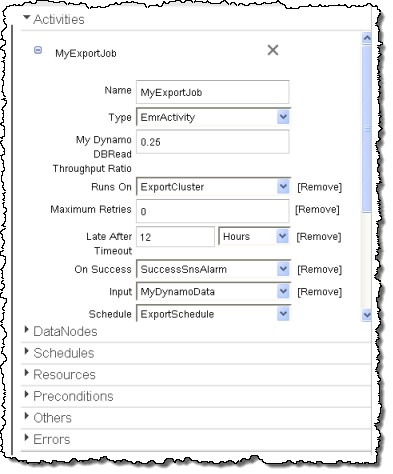
Finally, MyExportJob (an Activity) pulls it all together:
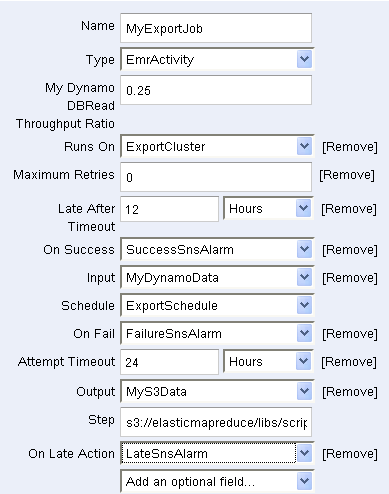
Once the pipeline is ready, it can be saved and then activated:

Here are some other resources to help you get started with the AWS Data Pipeline:
- AWS Data Pipeline Home Page
- AWS Data Pipeline Developer Guide
- AWS Data Pipeline API Reference
- AWS Data Pipeline FAQ
And there you have it! Give it a try and let me know what you think.
— Jeff;