AWS News Blog
Category: Amazon EC2

AWS Weekly Roundup: Kiro waitlist, EBS Volume Clones, EC2 Capacity Manager, and more (October 20, 2025)
I’ve been inspired by all the activities that tech communities around the world have been hosting and participating in throughout the year. Here in the southern hemisphere we’re starting to dream about our upcoming summer breaks and closing out on some of the activities we’ve initiated this year. The tech community in South Africa is […]
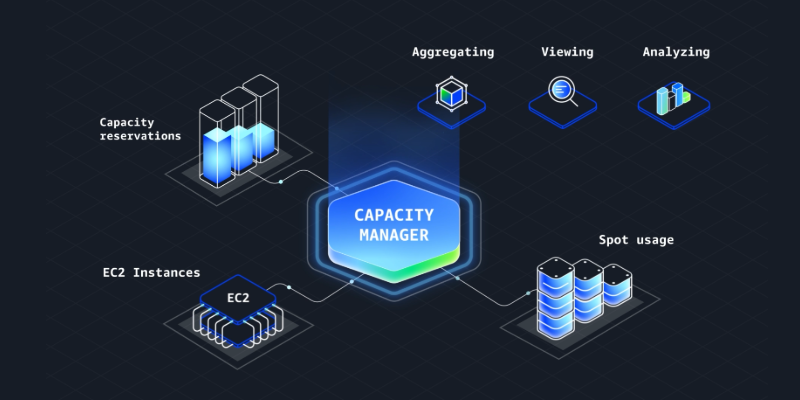
Monitor, analyze, and manage capacity usage from a single interface with Amazon EC2 Capacity Manager
Amazon EC2 Capacity Manager is a new centralized solution that consolidates capacity monitoring and management across all AWS accounts and regions, eliminating operational overhead and providing optimization opportunities for EC2 infrastructure at scale.
AWS Weekly Roundup: Amazon Quick Suite, EC2 C8i, C8i-flex, and M8a instances, and more (October 13, 2025)
This week I was at the inaugural AWS AI in Practice meetup from the AWS User Group UK. AI-assisted software development and agents were the focus of the evening! Next week I’ll be in Italy for Codemotion (Milan) and an AWS User Group meetup (Rome). My sessions there will be about AI agents and context […]

New general-purpose Amazon EC2 M8a instances are now available
Amazon EC2 has launched new M8a instances powered by 5th Generation AMD EPYC processors, offering up to 30% better performance and 19% better price performance compared to M7a instances, along with improved memory bandwidth, networking, and storage capabilities for various general-purpose workloads.

Introducing new compute-optimized Amazon EC2 C8i and C8i-flex instances
AWS launched compute-optimized C8i and C8i-flex EC2 instances powered by custom Intel Xeon 6 processors available only on AWS to offer up to 15% better price performance, 20% higher performance, and 2.5 times more memory throughput compared to previous generations.
Announcing Amazon ECS Managed Instances for containerized applications
Amazon ECS Managed Instances is a new compute option that eliminates infrastructure management overhead while giving you access to the broad suite of EC2 capabilities including the flexibility to select instance types, access reserved capacity, and advanced security and observability configurations.
AWS Weekly Roundup: Amazon EC2, Amazon Q Developer, IPv6 updates, and more (September 1, 2025)
My LinkedIn feed was absolutely packed this week with pictures from the AWS Heroes Summit event in Seattle. It was heartwarming to see so many familiar faces and new Heroes coming together. For those not familiar with the AWS Heroes program, it’s a global community recognition initiative that honors individuals who make outstanding contributions to […]
New general-purpose Amazon EC2 M8i and M8i-flex instances are now available
M8i and M8i-flex instances powered by Intel Xeon processors offer up to 15% better price performance, 20% higher performance, and 2.5 times more memory throughput compared to previous generations.