AWS News Blog
Category: Database
Pick the Right Tool for your IT Challenge
This guest post is by AWS Community Hero Markus Ostertag. As CEO of the Munich-based ad-tech company Team Internet AG, Markus is always trying to find the best ways to leverage the cloud, loves to work with cutting-edge technologies, and is a frequent speaker at AWS events and the AWS user group Munich that he […]
Learn about New AWS re:Invent Launches – December AWS Online Tech Talks
Join us in the next couple weeks to learn about some of the new service and feature launches from re:Invent 2018. Learn about features and benefits, watch live demos and ask questions! We’ll have AWS experts online to answer any questions you may have. Register today! Note – All sessions are free and in Pacific […]
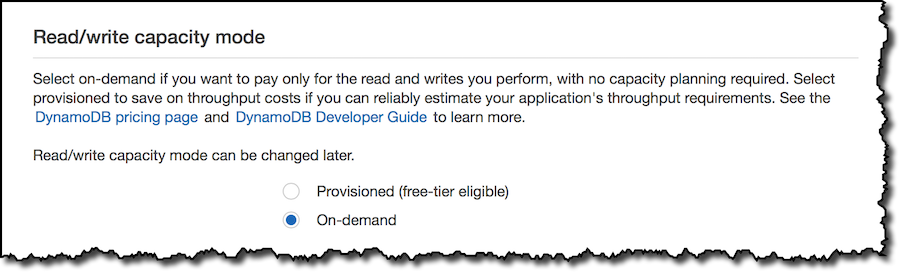
Amazon DynamoDB On-Demand – No Capacity Planning and Pay-Per-Request Pricing
January 31, 2025: Post updated to clarify the reduced on-demand pricing and workloads recommendations. Just a few years ago, creating a database that could support your business at any scale while providing consistent low latency was a daunting task. That changed for me in 2012 while reading Werner Vogels’ blog post announcing Amazon DynamoDB (it was […]
New – Amazon DynamoDB Transactions
May 20, 2024: As of September 2022, DynamoDB now supports 100 items per transactions. March 13, 2020: Post updated to clarify how to use transactions with global tables and the increase in the maximum number of items per transaction from 10 to 25. Over the years, customers have used Amazon DynamoDB for lots of different […]

New – Redis 5.0 Compatibility for Amazon ElastiCache
Earlier this year we announced Redis 4.0 compatibility for Amazon ElastiCache. In that post, Randall explained how ElastiCache for Redis clusters can scale to terabytes of memory and millions of reads and writes per second! Other recent improvements to Amazon ElastiCache for Redis include: Read Replica Scaling – Support for adding or removing read replica […]

Learn about AWS – November AWS Online Tech Talks
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. AWS Online Tech Talks are live, online presentations that cover a broad range of topics at varying technical levels. Join us this month to learn about AWS services and solutions. We’ll have experts online to help answer any questions you may […]

Amazon RDS Update – Console Update, RDS Recommendations, Performance Insights, M5 Instances, MySQL 8, MariaDB 10.3, and More
It is time for a quick Amazon RDS update. I’ve got lots of news to share: Console Update – The RDS Console has a fresh, new look. RDS Recommendations – You now get recommendations that will help you to configure your database instances per our best practices. Performance Insights for MySQL – You can peer […]

New – Parallel Query for Amazon Aurora
Amazon Aurora is a relational database that was designed to take full advantage of the abundance of networking, processing, and storage resources available in the cloud. While maintaining compatibility with MySQL and PostgreSQL on the user-visible side, Aurora makes use of a modern, purpose-built distributed storage system under the covers. Your data is striped across […]