AWS News Blog
New — Introducing Support for Real-Time and Batch Inference in Amazon SageMaker Data Wrangler

|
To build machine learning models, machine learning engineers need to develop a data transformation pipeline to prepare the data. The process of designing this pipeline is time-consuming and requires a cross-team collaboration between machine learning engineers, data engineers, and data scientists to implement the data preparation pipeline into a production environment.
The main objective of Amazon SageMaker Data Wrangler is to make it easy to do data preparation and data processing workloads. With SageMaker Data Wrangler, customers can simplify the process of data preparation and all of the necessary steps of data preparation workflow on a single visual interface. SageMaker Data Wrangler reduces the time to rapidly prototype and deploy data processing workloads to production, so customers can easily integrate with MLOps production environments.
However, the transformations applied to the customer data for model training need to be applied to new data during real-time inference. Without support for SageMaker Data Wrangler in a real-time inference endpoint, customers need to write code to replicate the transformations from their flow in a preprocessing script.
Introducing Support for Real-Time and Batch Inference in Amazon SageMaker Data Wrangler
I’m pleased to share that you can now deploy data preparation flows from SageMaker Data Wrangler for real-time and batch inference. This feature allows you to reuse the data transformation flow which you created in SageMaker Data Wrangler as a step in Amazon SageMaker inference pipelines.
SageMaker Data Wrangler support for real-time and batch inference speeds up your production deployment because there is no need to repeat the implementation of the data transformation flow. You can now integrate SageMaker Data Wrangler with SageMaker inference. The same data transformation flows created with the easy-to-use, point-and-click interface of SageMaker Data Wrangler, containing operations such as Principal Component Analysis and one-hot encoding, will be used to process your data during inference. This means that you don’t have to rebuild the data pipeline for a real-time and batch inference application, and you can get to production faster.
Get Started with Real-Time and Batch Inference
Let’s see how to use the deployment supports of SageMaker Data Wrangler. In this scenario, I have a flow inside SageMaker Data Wrangler. What I need to do is to integrate this flow into real-time and batch inference using the SageMaker inference pipeline.
First, I will apply some transformations to the dataset to prepare it for training.
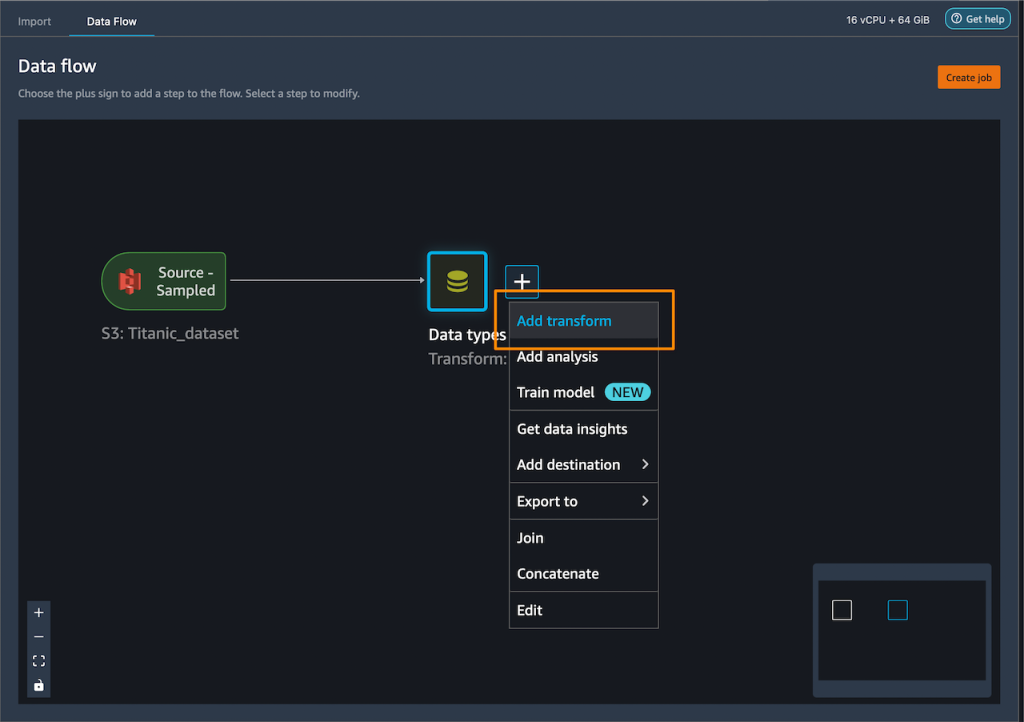
I add one-hot encoding on the categorical columns to create new features.
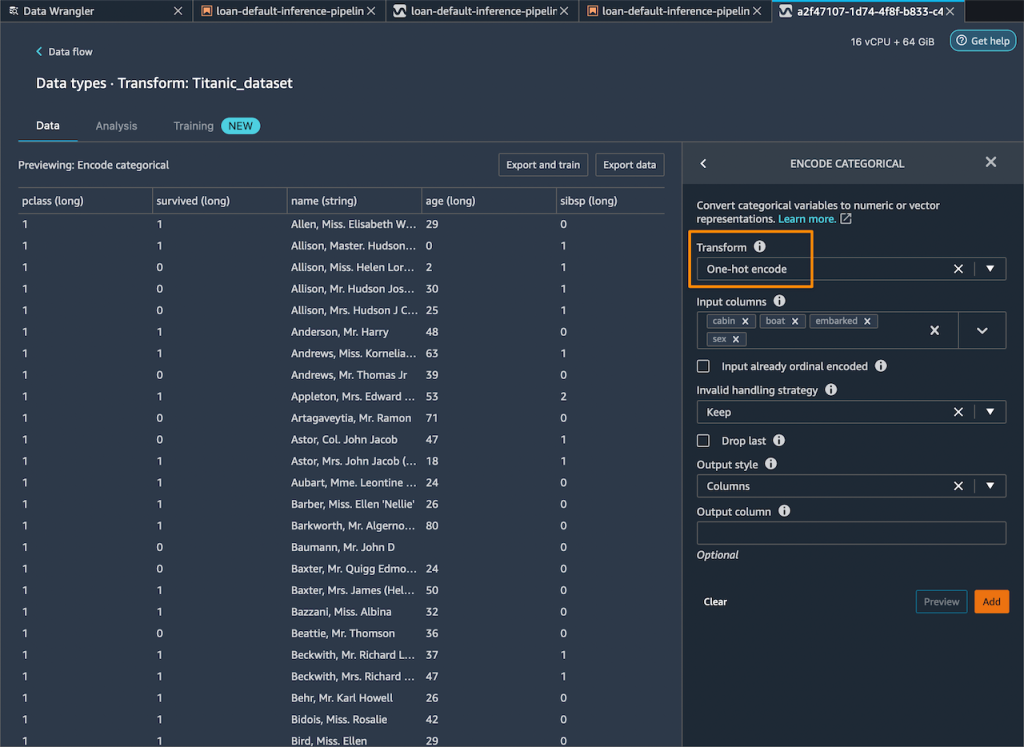
Then, I drop any remaining string columns that cannot be used during training.

My resulting flow now has these two transform steps in it.
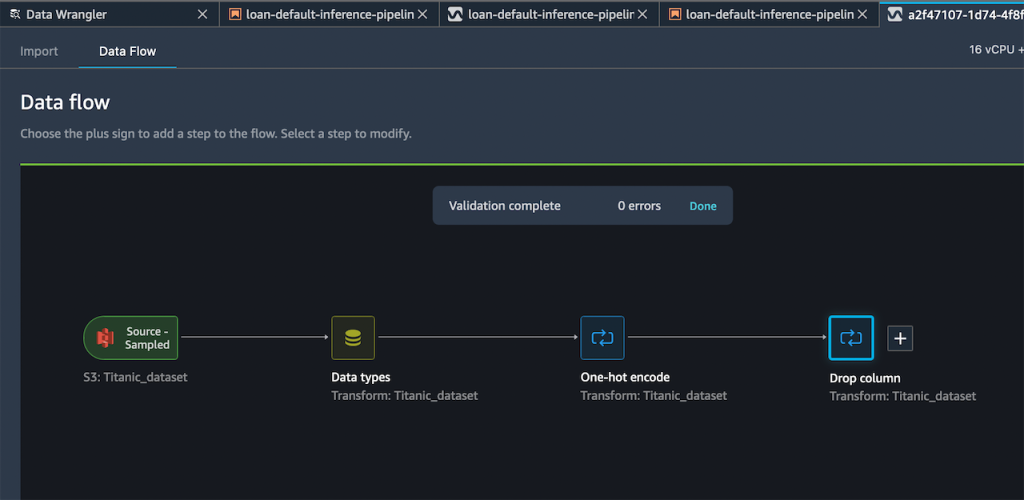
After I’m satisfied with the steps I have added, I can expand the Export to menu, and I have the option to export to SageMaker Inference Pipeline (via Jupyter Notebook).

I select Export to SageMaker Inference Pipeline, and SageMaker Data Wrangler will prepare a fully customized Jupyter notebook to integrate the SageMaker Data Wrangler flow with inference. This generated Jupyter notebook performs a few important actions. First, define data processing and model training steps in a SageMaker pipeline. The next step is to run the pipeline to process my data with Data Wrangler and use the processed data to train a model that will be used to generate real-time predictions. Then, deploy my Data Wrangler flow and trained model to a real-time endpoint as an inference pipeline. Last, invoke my endpoint to make a prediction.

This feature uses Amazon SageMaker Autopilot, which makes it easy for me to build ML models. I just need to provide the transformed dataset which is the output of the SageMaker Data Wrangler step and select the target column to predict. The rest will be handled by Amazon SageMaker Autopilot to explore various solutions to find the best model.

Using AutoML as a training step from SageMaker Autopilot is enabled by default in the notebook with the use_automl_step variable. When using the AutoML step, I need to define the value of target_attribute_name, which is the column of my data I want to predict during inference. Alternatively, I can set use_automl_step to False if I want to use the XGBoost algorithm to train a model instead.
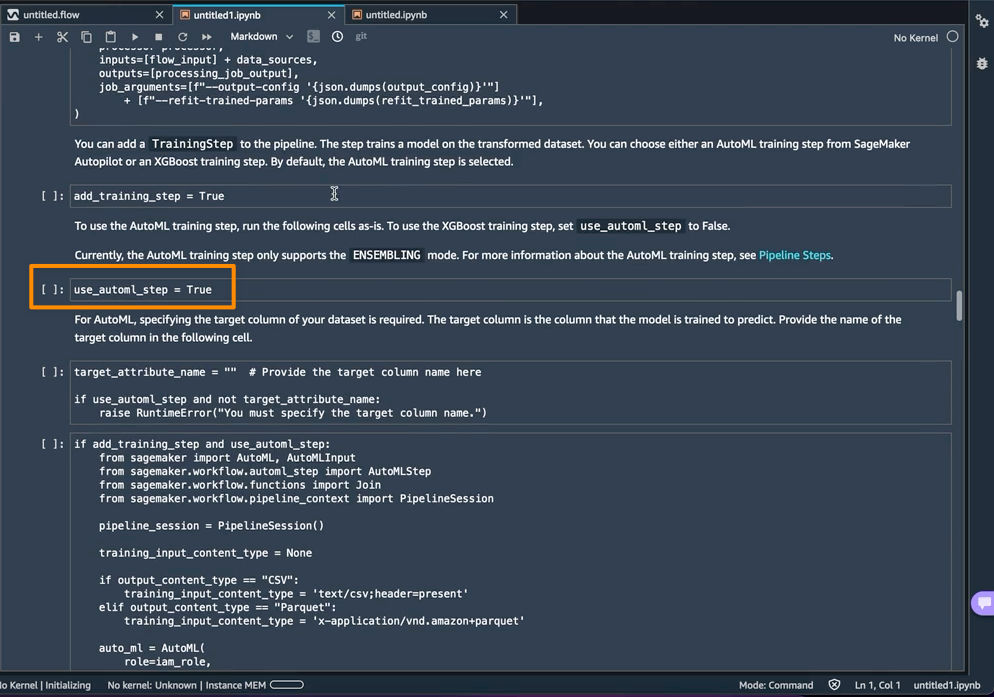
On the other hand, if I would like to instead use a model I trained outside of this notebook, then I can skip directly to the Create SageMaker Inference Pipeline section of the notebook. Here, I would need to set the value of the byo_model variable to True. I also need to provide the value of algo_model_uri, which is the Amazon Simple Storage Service (Amazon S3) URI where my model is located. When training a model with the notebook, these values will be auto-populated.
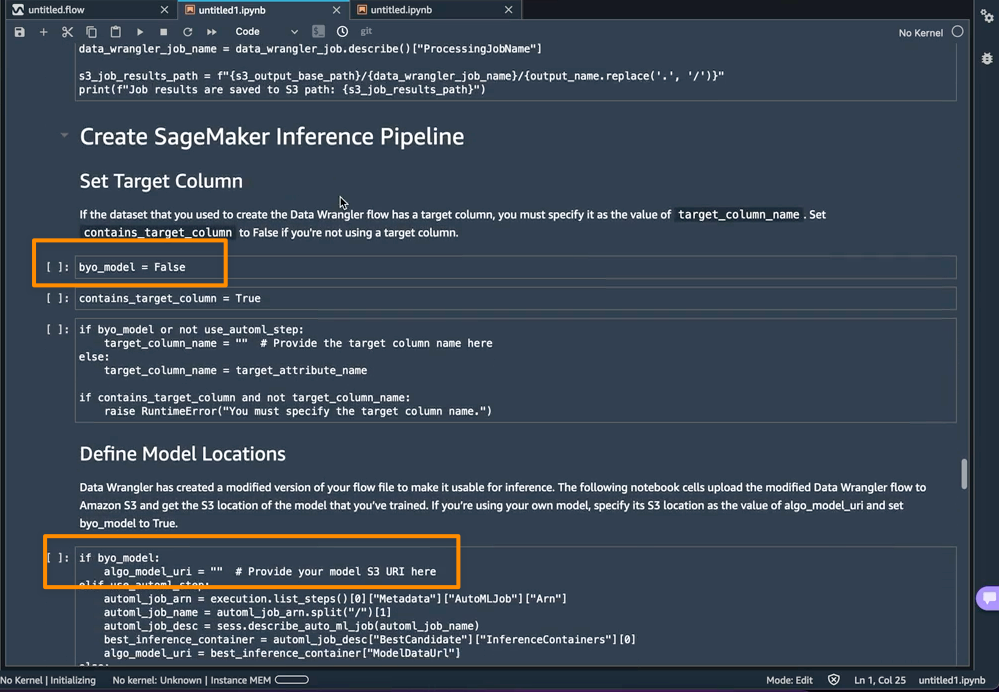
In addition, this feature also saves a tarball inside the data_wrangler_inference_flows folder on my SageMaker Studio instance. This file is a modified version of the SageMaker Data Wrangler flow, containing the data transformation steps to be applied at the time of inference. It will be uploaded to S3 from the notebook so that it can be used to create a SageMaker Data Wrangler preprocessing step in the inference pipeline.
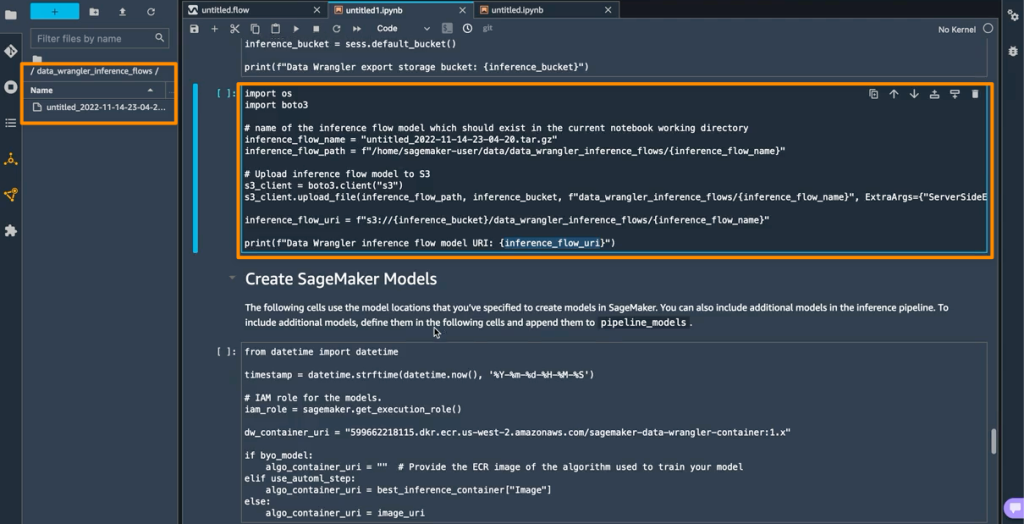
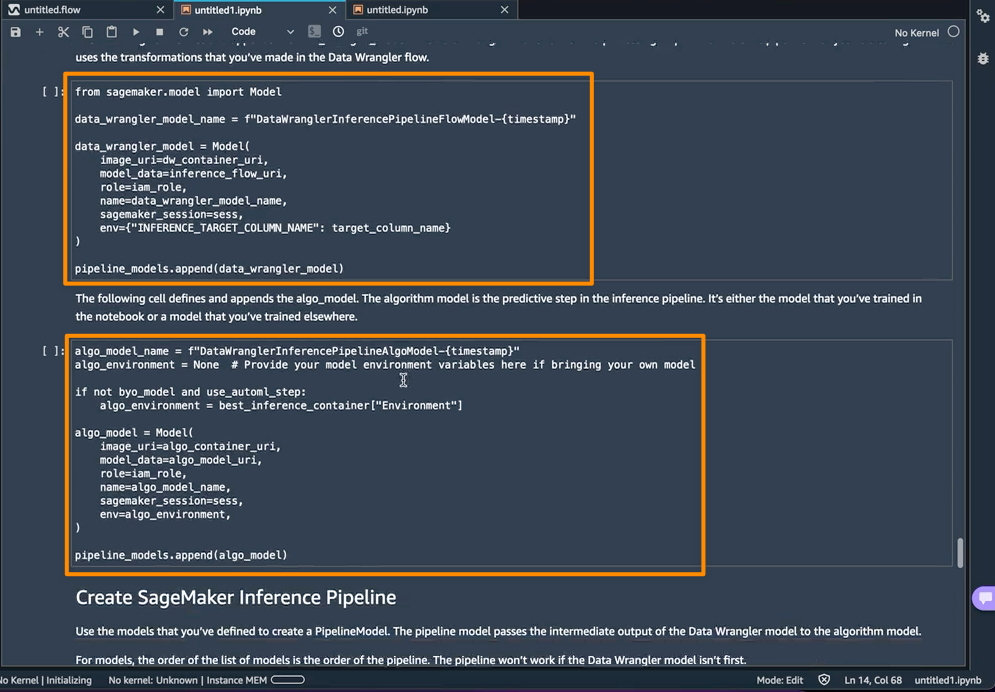
The next step is that this notebook will create two SageMaker model objects. The first object model is the SageMaker Data Wrangler model object with the variable data_wrangler_model, and the second is the model object for the algorithm, with the variable algo_model. Object data_wrangler_model will be used to provide input in the form of data that has been processed into algo_model for prediction.
The final step inside this notebook is to create a SageMaker inference pipeline model, and deploy it to an endpoint.
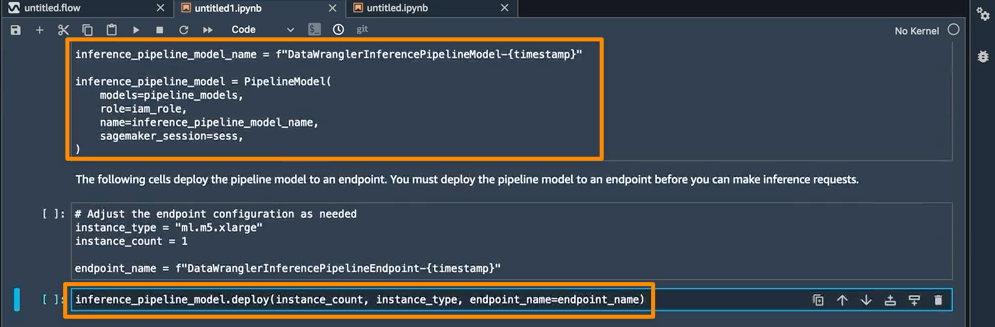
Once the deployment is complete, I will get an inference endpoint that I can use for prediction. With this feature, the inference pipeline uses the SageMaker Data Wrangler flow to transform the data from your inference request into a format that the trained model can use.
In the next section, I can run individual notebook cells in Make a Sample Inference Request. This is helpful if I need to do a quick check to see if the endpoint is working by invoking the endpoint with a single data point from my unprocessed data. Data Wrangler automatically places this data point into the notebook, so I don’t have to provide one manually.
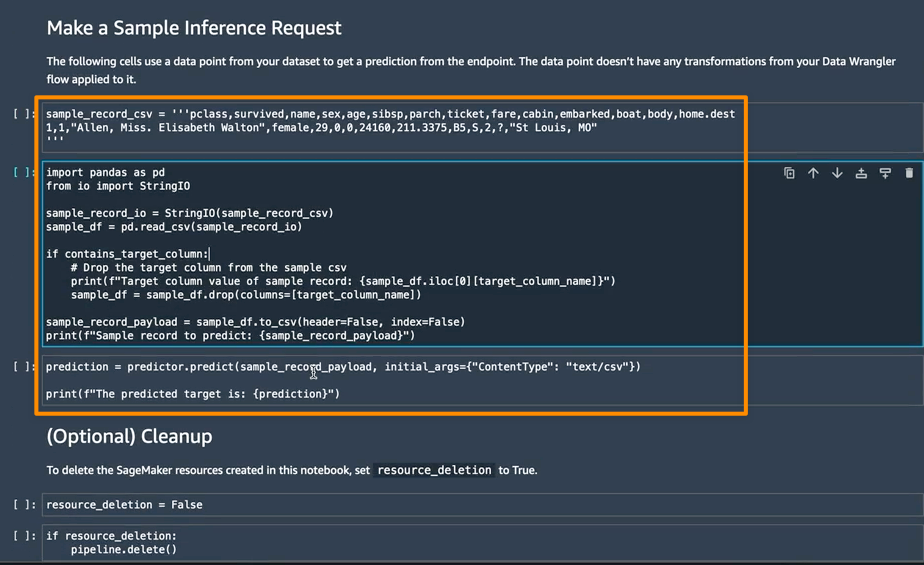
Things to Know
Enhanced Apache Spark configuration — In this release of SageMaker Data Wrangler, you can now easily configure how Apache Spark partitions the output of your SageMaker Data Wrangler jobs when saving data to Amazon S3. When adding a destination node, you can set the number of partitions, corresponding to the number of files that will be written to Amazon S3, and you can specify column names to partition by, to write records with different values of those columns to different subdirectories in Amazon S3. Moreover, you can also define the configuration in the provided notebook.

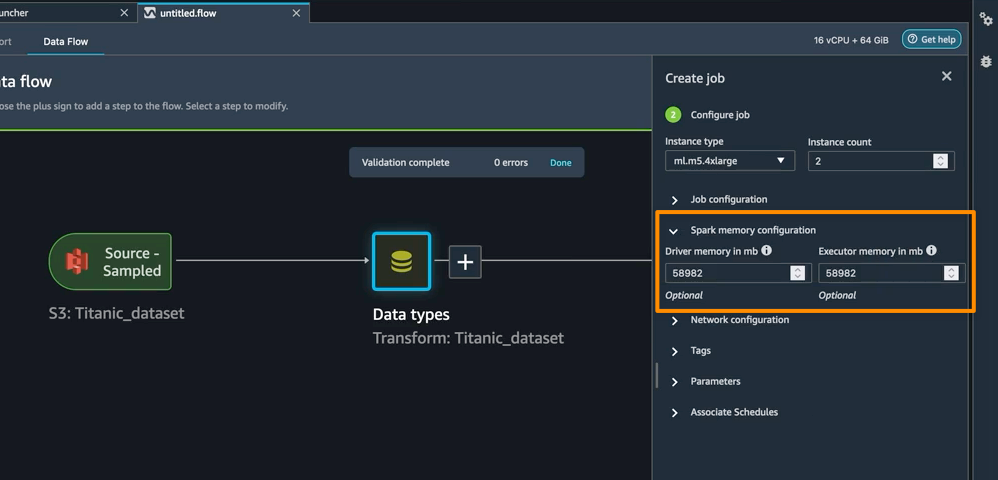
You can also define memory configurations for SageMaker Data Wrangler processing jobs as part of the Create job workflow. You will find similar configuration as part of your notebook.
Availability — SageMaker Data Wrangler supports for real-time and batch inference as well as enhanced Apache Spark configuration for data processing workloads are generally available in all AWS Regions that Data Wrangler currently supports.
To get started with Amazon SageMaker Data Wrangler supports for real-time and batch inference deployment, visit AWS documentation.
Happy building
— Donnie