AWS News Blog
Step Functions Distributed Map – A Serverless Solution for Large-Scale Parallel Data Processing

|
I am excited to announce the availability of a distributed map for AWS Step Functions. This flow extends support for orchestrating large-scale parallel workloads such as the on-demand processing of semi-structured data.
Step Function’s map state executes the same processing steps for multiple entries in a dataset. The existing map state is limited to 40 parallel iterations at a time. This limit makes it challenging to scale data processing workloads to process thousands of items (or even more) in parallel. In order to achieve higher parallel processing prior to today, you had to implement complex workarounds to the existing map state component.
The new distributed map state allows you to write Step Functions to coordinate large-scale parallel workloads within your serverless applications. You can now iterate over millions of objects such as logs, images, or .csv files stored in Amazon Simple Storage Service (Amazon S3). The new distributed map state can launch up to ten thousand parallel workflows to process data.
You can process data by composing any service API supported by Step Functions, but typically, you will invoke Lambda functions to process the data with code written in your favorite programming language.
Step Functions distributed map supports a maximum concurrency of up to 10,000 executions in parallel, which is well above the concurrency supported by many other AWS services. You can use the maximum concurrency feature of the distributed map to ensure that you do not exceed the concurrency of a downstream service. There are two factors to consider when working with other services. First, the maximum concurrency supported by the service for your account. Second, the burst and ramping rates, which determine how quickly you can achieve the maximum concurrency.
Let’s use Lambda as an example. Your functions’ concurrency is the number of instances that serve requests at a given time. The default maximum concurrency quota for Lambda is 1,000 per AWS Region. You can ask for an increase at any time. For an initial burst of traffic, your functions’ cumulative concurrency in a Region can reach an initial level of between 500 and 3000, which varies per Region. The burst concurrency quota applies to all your functions in the Region.
When using a distributed map, be sure to verify the quota on downstream services. Limit the distributed map maximum concurrency during your development, and plan for service quota increases accordingly.
To compare the new distributed map with the original map state flow, I created this table.
| Original map state flow | New distributed map flow | |
| Sub workflows |
|
|
| Parallel branches | Map iterations run in parallel, with an effective maximum concurrency of around 40 at a time. | Can pass millions of items to multiple child executions, with concurrency of up to 10,000 executions at a time. |
| Input source | Accepts only a JSON array as input. | Accepts input as Amazon S3 object list, JSON arrays or files, csv files, or Amazon S3 inventory. |
| Payload | 256 KB | Each iteration receives a reference to a file (Amazon S3) or a single record from a file (state input). Actual file processing capability is limited by Lambda storage and memory. |
| Execution history | 25,000 events | Each iteration of the map state is a child execution, with up to 25,000 events each (express mode has no limit on execution history). |
Sub-workflows within a distributed map work with both Standard workflows and the low-latency, short-duration Express Workflows.
This new capability is optimized to work with S3. I can configure the bucket and prefix where my data are stored directly from the distributed map configuration. The distributed map stops reading after 100 million items and supports JSON or csv files of up to 10GB.
When processing large files, think about downstream service capabilities. Let’s take Lambda again as an example. Each input—a file on S3, for example—must fit within the Lambda function execution environment in terms of temporary storage and memory. To make it easier to handle large files, Lambda Powertools for Python introduced a new streaming feature to fetch, transform, and process S3 objects with minimal memory footprint. This allows your Lambda functions to handle files larger than the size of their execution environment. To learn more about this new capability, check the Lambda Powertools documentation.
Let’s See It in Action
For this demo, I will create a workflow that processes one thousand dog images stored on S3. The images are already stored on S3.
➜ ~ aws s3 ls awsnewsblog-distributed-map/images/
2022-11-08 15:03:36 27034 n02085620_10074.jpg
2022-11-08 15:03:36 34458 n02085620_10131.jpg
2022-11-08 15:03:36 12883 n02085620_10621.jpg
2022-11-08 15:03:36 34910 n02085620_1073.jpg
...
➜ ~ aws s3 ls awsnewsblog-distributed-map/images/ | wc -l
1000The workflow and the S3 bucket must be in the same Region.
To get started, I navigate to the Step Functions page of the AWS Management Console and select Create state machine. On the next page, I choose to design my workflow using the visual editor. The distributed map works with Standard workflows, and I keep the default selection as-is. I select Next to enter the visual editor.
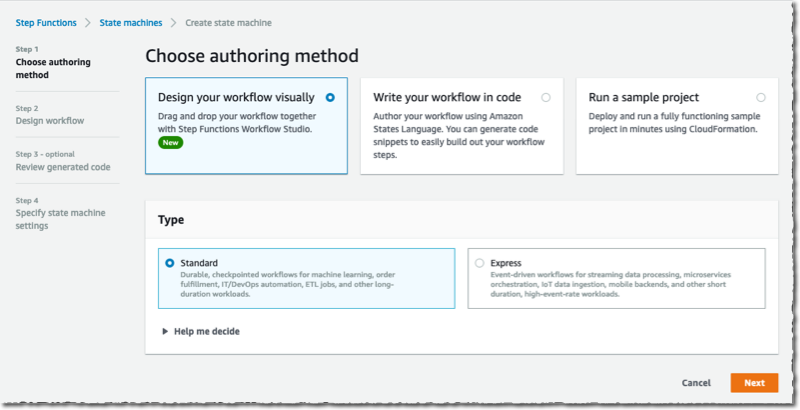 In the visual editor, I search and select the Map component on the left-side pane, and I drag it to the workflow area. On the right side, I configure the component. I choose Distributed as Processing mode and Amazon S3 as Item Source.
In the visual editor, I search and select the Map component on the left-side pane, and I drag it to the workflow area. On the right side, I configure the component. I choose Distributed as Processing mode and Amazon S3 as Item Source.
Distributed maps are natively integrated with S3. I enter the name of the bucket (awsnewsblog-distributed-map) and the prefix (images) where my images are stored.
 On the Runtime Settings section, I choose Express for Child workflow type. I also may decide to restrict the Concurrency limit. It helps to ensure we operate within the concurrency quotas of the downstream services (Lambda in this demo) for a particular account or Region.
On the Runtime Settings section, I choose Express for Child workflow type. I also may decide to restrict the Concurrency limit. It helps to ensure we operate within the concurrency quotas of the downstream services (Lambda in this demo) for a particular account or Region.
By default, the output of my sub-workflows will be aggregated as state output, up to 256KB. To process larger outputs, I may choose to Export map state results to Amazon S3.

Finally, I define what to do for each file. In this demo, I want to invoke a Lambda function for each file in the S3 bucket. The function exists already. I search for and select the Lambda invocation action on the left-side pane. I drag it to the distributed map component. Then, I use the right-side configuration panel to select the actual Lambda function to invoke: AWSNewsBlogDistributedMap in this example.
When I am done, I select Next. I select Next again on the Review generated code page (not shown here).
On the Specify state machine settings page, I enter a Name for my state machine and the IAM Permissions to run. Then, I select Create state machine.
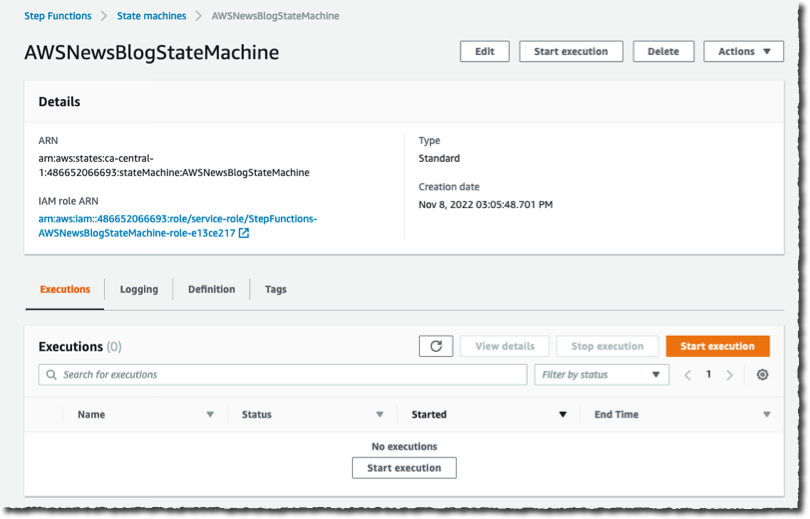
 Now I am ready to start the execution. On the State machine page, I select the new workflow and select Start execution. I can optionally enter a JSON document to pass to the workflow. In this demo, the workflow does not handle the input data. I leave it as-is, and I select Start execution.
Now I am ready to start the execution. On the State machine page, I select the new workflow and select Start execution. I can optionally enter a JSON document to pass to the workflow. In this demo, the workflow does not handle the input data. I leave it as-is, and I select Start execution.
 |
 |
During the execution of the workflow, I can monitor the progress. I observe the number of iterations, and the number of items successfully processed or in error.
 I can drill down on one specific execution to see the details.
I can drill down on one specific execution to see the details.
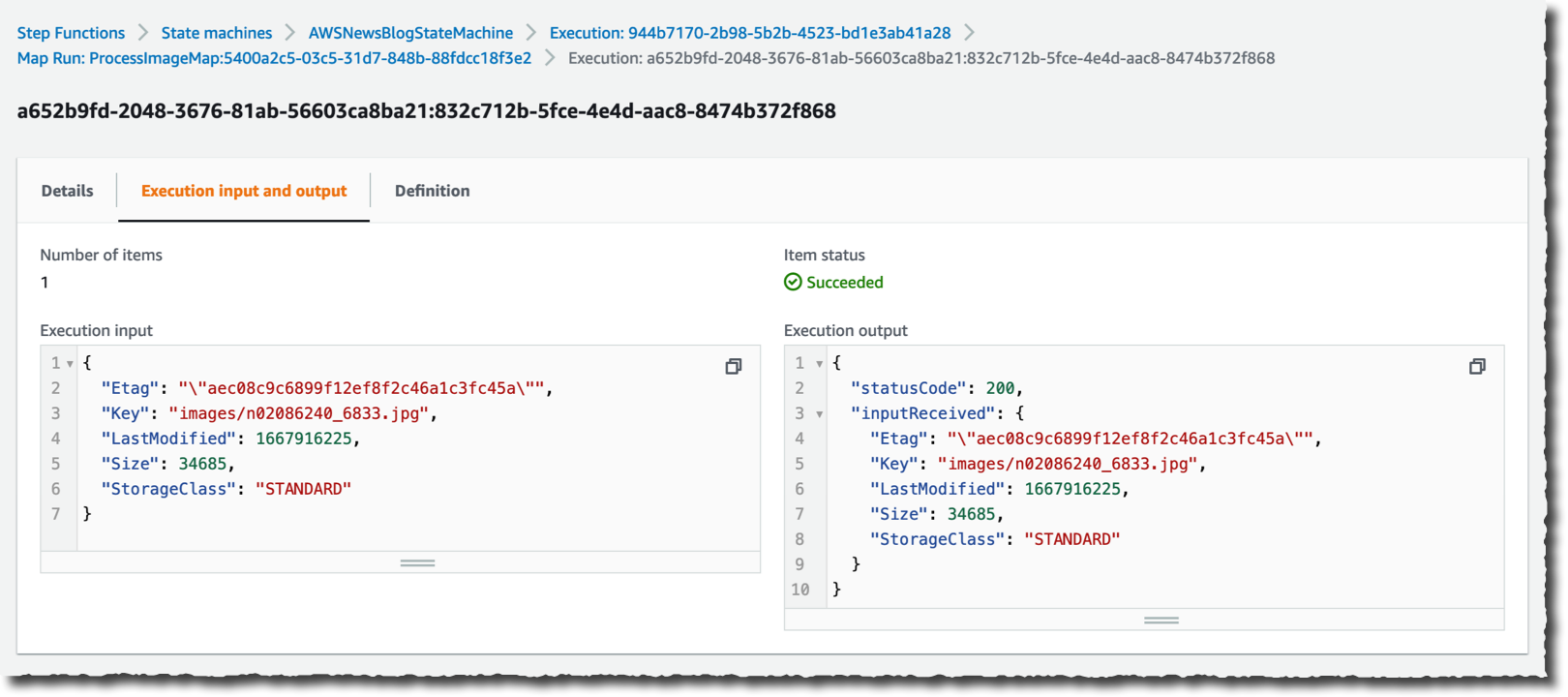
With just a few clicks, I created a large-scale and heavily parallel workflow able to handle a very large quantity of data.
Which AWS Service Should I Use
As often happens on AWS, you might observe an overlap between this new capability and existing services such as AWS Glue, Amazon EMR, or Amazon S3 Batch Operations. Let’s try to differentiate the use cases.
In my mental model, data scientists and data engineers use AWS Glue and EMR to process large amounts of data. On the other hand, application developers will use Step Functions to add serverless data processing into their applications. Step Functions is able to scale from zero quickly, which makes it a good fit for interactive workloads where customers may be waiting for the results. Finally, system administrators and IT operation teams are likely to use Amazon S3 Batch Operations for single-step IT automation operations such as copying, tagging, or changing permissions on billions of S3 objects.
Pricing and Availability
AWS Step Functions’ distributed map is generally available in the following ten AWS Regions: US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Singapore, Sydney, Tokyo), Canada (Central), and Europe (Frankfurt, Ireland, Stockholm).
The pricing model for the existing inline map state does not change. For the new distributed map state, we charge one state transition per iteration. Pricing varies between Regions, and it starts at $0.025 per 1,000 state transitions. When you process your data using express workflows, you are also charged based on the number of requests for your workflow and its duration. Again, prices vary between Regions, but they start at $1.00 per 1 million requests and $0.06 per GB-hour (prorated to 100ms).
For the same amount of iterations, you will observe a cost reduction when using the combination of the distributed map and standard workflows compared to the existing inline map. When you use express workflows, expect the costs to stay the same for more value with the distributed map.
I am really excited to discover what you will build using this new capability and how it will unlock innovation. Go start to build highly parallel serverless data processing workflows today!
— seb