AWS News Blog
The New AWS Data Pipeline

|
Update (May 2023) – AWS Data Pipeline service is in maintenance mode and no new features or region expansions are planned. To learn more and to find out how to migrate your existing workloads, please read Migrating workloads from AWS Data Pipeline.
Data. Information. Big Data. Business Intelligence. It’s all the rage these days. Companies of all sizes are realizing that managing data is a lot more complicated and time consuming than in the past, despite the fact that the cost of the underlying storage continues to decline.
Buried deep within this mountain of data is the “captive intelligence” that you could be using to expand and improve your business. Your need to move, sort, filter, reformat, analyze, and report on this data in order to make use of it. To make matters more challenging, you need to do this quickly (so that you can respond in real time) and you need to do it repetitively (you might need fresh reports every hour, day, or week).
Data Issues and Challenges
Here are some of the issues that we are hearing about from our customers when we ask them about their data processing challenges:
Increasing Size – There’s simply a lot of raw and processed data floating around these days. There are log files, data collected from sensors, transaction histories, public data sets, and lots more.
Variety of Formats – There are so many ways to store data: CSV files, Apache logs, flat files, rows in a relational database, tuples in a NoSQL database, XML, JSON to name a few.
Disparate Storage – There are all sorts of systems out there. You’ve got your own data warehouse (or Amazon Redshift), Amazon S3, Relational Database Service (RDS) database instances running MySQL, Oracle, or Windows Server, DynamoDB, other database servers running on Amazon EC2 instances or on-premises, and so forth.
Distributed, Scalable Processing – There are lots of ways to process the data: On-Demand or Spot EC2 instances, an Elastic MapReduce cluster, or physical hardware. Or some combination of any and all of the above just to make it challenging!
Hello, AWS Data Pipeline
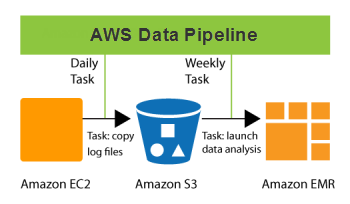 Our new AWS Data Pipeline product will help you to deal with all of these issues in a scalable fashion. You can now automate the movement and processing of any amount of data using data-driven workflows and built-in dependency checking.
Our new AWS Data Pipeline product will help you to deal with all of these issues in a scalable fashion. You can now automate the movement and processing of any amount of data using data-driven workflows and built-in dependency checking.
Let’s start by taking a look at the basic concepts:
A Pipeline is composed of a set of data sources, preconditions, destinations, processing steps, and an operational schedule, all defined in a Pipeline Definition.
The definition specifies where the data comes from, what to do with it, and where to store it. You can create a Pipeline Definition in the AWS Management Console or externally, in text form.
Once you define and activate a pipeline, it will run according to a regular schedule. You could, for example, arrange to copy log files from a cluster of Amazon EC2 instances to an S3 bucket every day, and then launch a massively parallel data analysis job on an Elastic MapReduce cluster once a week. All internal and external data references (e.g. file names and S3 URLs) in the Pipeline Definition can be computed on the fly so you can use convenient naming conventions like raw_log_YYYY_MM_DD.txt for your input, intermediate, and output files.
Your Pipeline Definition can include a precondition. Think of a precondition as an assertion that must hold in order for processing to begin. For example, you could use a precondition to assert that an input file is present.
AWS Data Pipeline will take care of all of the details for you. It will wait until any preconditions are satisfied and will then schedule and manage the tasks per the Pipeline Definition. For example, you can wait until a particular input file is present.
Processing tasks can run on EC2 instances, Elastic MapReduce clusters, or physical hardware. AWS Data Pipeline can launch and manage EC2 instances and EMR clusters as needed. To take advantage of long-running EC2 instances and physical hardware, we also provide an open source tool called the Task Runner. Each running instance of a Task Runner polls the AWS Data Pipeline in pursuit of jobs of a specific type and executes them as they become available.
When a pipeline completes, a message will be sent to the Amazon SNS topic of your choice. You can also arrange to send messages when a processing step fails to complete after a specified number of retries or if it takes longer than a configurable amount of time to complete.
From the Console
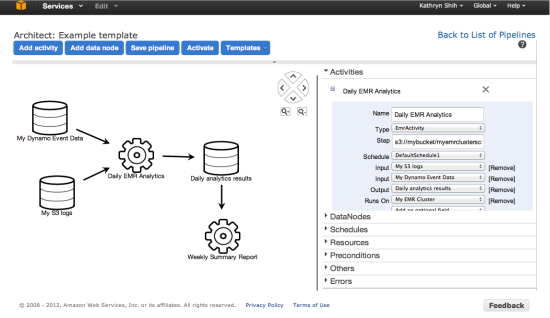
You will be able to design, monitor, and manage your pipelines from within the AWS Management Console:
API and Command Line Access
In addition to the AWS Management Console access, you will also be able to access the AWS Data Pipeline through a set of APIs and from the command line.
You can create a Pipeline Definition in a text file in JSON format; here’s a snippet that will copy data from one Amazon S3 location to another:
“name” : “S3ToS3Copy” ,
“type” : “CopyActivity” ,
“schedule” : { “ref” : “CopyPeriod” } ,
“input” : { “ref” : “InputData” } ,
“output” : { “ref” : “OutputData” }
}
Coming Soon
The AWS Data Pipeline is currrently in a limited private beta. If you are interested in participating, please contact AWS sales.
Stay tuned to the blog for more information on the upcoming public beta.
— Jeff;