AWS Big Data Blog
Author: Jonathan Fritz

Meet the Amazon EMR Team this Friday at a Tech Talk & Networking Event in Mountain View
Want to change the world with Big Data and Analytics? Come join us on the Amazon EMR team in Amazon Web Services! Meet the Amazon EMR team this Friday April 7th from 5:00 – 7:30 PM at Michael’s at Shoreline in Mountain View. We’ll feature short tech talks by EMR leadership who will talk about the past, […]
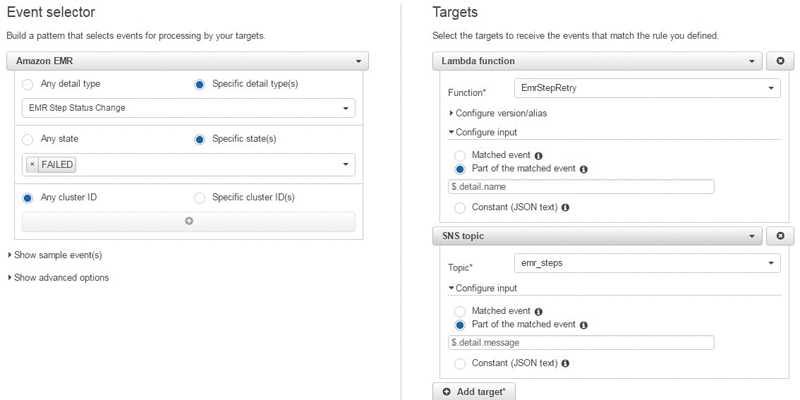
Respond to State Changes on Amazon EMR Clusters with Amazon CloudWatch Events
Jonathan Fritz is a Senior Product Manager for Amazon EMR Customers can take advantage of the Amazon EMR API to create and terminate EMR clusters, scale clusters using Auto Scaling or manual resizing, and submit and run Apache Spark, Apache Hive, or Apache Pig workloads. These decisions are often triggered from cluster state-related information. Previously, […]
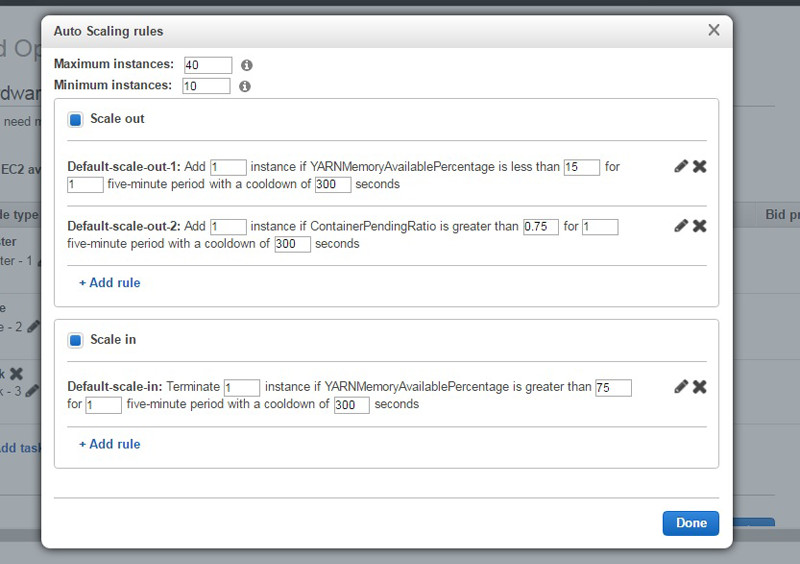
Dynamically Scale Applications on Amazon EMR with Auto Scaling
Jonathan Fritz is a Senior Product Manager for Amazon EMR Customers running Apache Spark, Presto, and the Apache Hadoop ecosystem take advantage of Amazon EMR’s elasticity to save costs by terminating clusters after workflows are complete and resizing clusters with low-cost Amazon EC2 Spot Instances. For instance, customers can create clusters for daily ETL or machine learning […]

Encrypt Data At-Rest and In-Flight on Amazon EMR with Security Configurations
ustomers running analytics, stream processing, machine learning, and ETL workloads on personally identifiable information, health information, and financial data have strict requirements for encryption of data at-rest and in-transit. The Apache Spark and Hadoop ecosystems lend themselves to these big data use cases, and customers have asked us to provide a quick and easy way to encrypt data at-rest and data in-transit between nodes in each execution framework.

Use Spark 2.0, Hive 2.1 on Tez, and the latest from the Hadoop ecosystem on Amazon EMR release 5.0
Jonathan Fritz is a Senior Product Manager for Amazon EMR We are excited to launch Amazon EMR release 5.0 today, giving customers the latest versions of 16 supported open-source applications in the big data ecosystem, including new major versions of Spark and Hive. Almost exactly a year ago, we shipped release 4.0, which brought significant […]

Supercharge SQL on Your Data in Apache HBase with Apache Phoenix
With today’s launch of Amazon EMR release 4.7, you can now create clusters with Apache Phoenix 4.7.0 for low-latency SQL and OLTP workloads. Phoenix uses Apache HBase as its backing store (HBase 1.2.1 is included on Amazon EMR release 4.7.0), using HBase scan operations and coprocessors for fast performance. Additionally, you can map Phoenix tables […]
Import Zeppelin notes from GitHub or JSON in Zeppelin 0.5.6 on Amazon EMR
Jonathan Fritz is a Senior Product Manager for Amazon EMR Many Amazon EMR customers use Zeppelin to create interactive notebooks to run workloads with Spark using Scala, Python, and SQL. These customers have found Amazon EMR to be a great platform for running Zeppelin because of strong integration with other AWS services and the ability […]
Videos now available for AWS re:Invent 2015 Big Data Analytics sessions
For those of you who were able to attend AWS re:Invent 2015 last week or watched sessions through our live stream, thanks for participating in the conference. We hope you left feeling inspired to tackle your big data projects with tools in the AWS ecosystem and partner solutions. Also, we were excited for our customers […]
Installing Apache Spark on an Amazon EMR Cluster
Jonathan Fritz is a Senior Product Manager for Amazon EMR ———————– Please note – Amazon EMR now officially supports Spark. For more information about Spark on EMR, visit the Spark on Amazon EMR page or read Intent Media’s guest post on the AWS Big Data Blog about Spark on EMR. ——–————— Over the last five […]
Ensuring Consistency When Using Amazon S3 and Amazon Elastic MapReduce for ETL Workflows
February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that […]