AWS Big Data Blog

Cut costs and simplify operations with writable warm storage in Amazon OpenSearch Service
In this post, I show you how writable warm storage removes the costly migration cycle. You can reduce your infrastructure costs by up to 48 percent and update historical data in seconds instead of hours. I walk through a real-world cost comparison and performance benchmarks, and help you decide when to use writable warm versus UltraWarm.

Introducing Apache Spark Connect support in AWS Glue interactive sessions
Apache Spark Connect bridges the gap between these two worlds: you develop in local Python, but execute on AWS Glue against actual data. Today, AWS Glue interactive sessions support Spark Connect natively. You can connect from any environment that supports the PySpark remote() API, including VS Code, PyCharm, Amazon SageMaker Unified Studio notebooks, and standalone Python applications. You don’t need to install specialized kernels or manage cluster infrastructure.
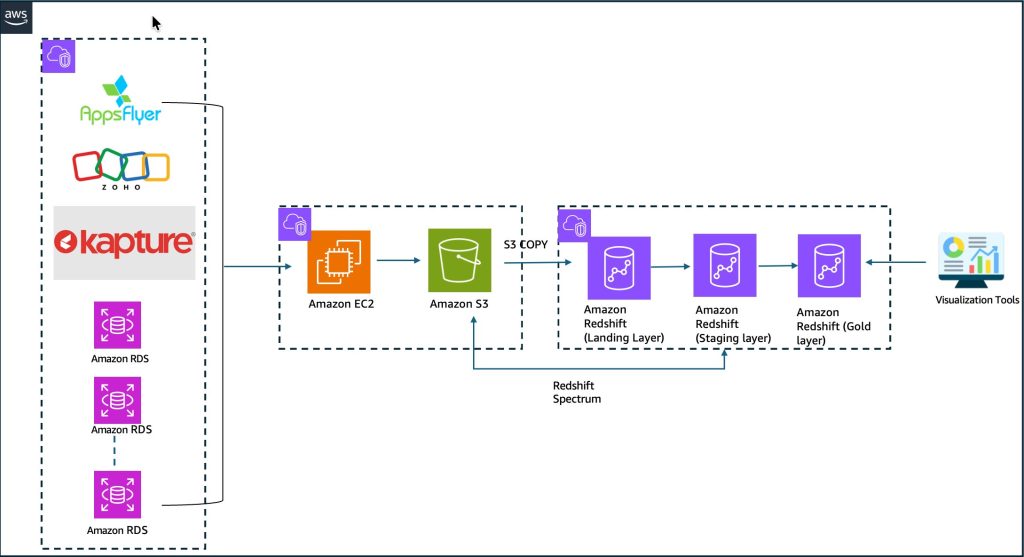
How BigBasket uses the Iceberg based lakehouse architecture on AWS to power lightning-fast grocery delivery across India
In this post, we demonstrate how BigBasket implemented the lakehouse architecture on AWS, including their architecture decisions, implementation approach, and the measurable business results you can expect from a similar modernization. Whether you’re facing scalability challenges or planning your own lakehouse implementation, this blueprint provides actionable insights you can adapt for your organization.

Accelerating log analytics at scale with AWS Glue and Apache Iceberg materialized views
In this post, you learn how to build an application log pipeline for production use with Amazon CloudWatch Logs, AWS Lambda, Amazon Data Firehose, AWS Glue, and Apache Iceberg materialized tables. You then use materialized views to accelerate query performance. This solution helps you achieve faster query response times on large-scale log data without requiring you to manage continuous data lake refresh.

Serverless analytics pipelines using the Apache Spark engine in Amazon Athena
This post shows how developers, data engineers, and analysts can connect to a secure Spark Connect endpoint in Athena with Apache Spark. You can use your preferred tools, such as Jupyter notebooks, VS Code, or dbt with Apache Airflow, without managing cluster lifecycle or scaling.

Deploy modern data platforms in minutes with MDAA
In this post, we explore how MDAA transforms data architecture development from months of manual coding to production-ready deployment through configuration-driven infrastructure and embedded governance, examine a real customer transformation, and provide a clear implementation pathway for your own data modernization journey.

Amazon Redshift RG: Faster and lower cost, Graviton-powered
In this post, we describe the innovations that make RG instances so much faster. We also share benchmark results showing that RG delivers up to 4.2x better price-performance than other leading data warehouses.

Run log analytics for a fraction of the cost with the new engine for Amazon OpenSearch Service
We’re introducing a purpose-built log analytics engine for Amazon OpenSearch Service. This new engine delivers up to 4x price performance, 2x faster data ingestion, up to 2x faster analytical queries, and up to 70 percent lower storage costs. You get all of this without sacrificing search capabilities on the same data. In this post, you learn how to take advantage of these benefits, see how to get started, and review benchmark results at billion-document scale.

AI-powered performance recommendations for Amazon Redshift
In this post, you learn how to build an AI-powered solution that collects the telemetry, pre-computes performance signals, correlates them with CloudWatch, and uses Amazon Bedrock to generate prioritized recommendations.

Scale analytics with Amazon Redshift multi-warehouse enhancements
In this post, we introduce new capabilities of Amazon Redshift that enhance our multi-warehouse and scaling capabilities: remote materialized view (MV) operations, remote table DDL support, and concurrency scaling enhancements for zero-ETL and S3 event integration. These features help you build more scalable, performant decentralized analytics architectures on Amazon Redshift.