AWS Big Data Blog

Migrate from Apache Solr to Amazon OpenSearch Serverless
In this post, you will learn why now is the time to take advantage of the ease of operations and native AI capabilities of OpenSearch Serverless, and migrate from Solr.

High-performance Remote Shuffle Service on Amazon EMR with Apache Celeborn
In this post, we show how Apache Celeborn resolves this trade-off for Amazon EMR on EKS and Amazon EMR on EC2, improving job reliability while unlocking additional cost savings.

Zero Copy access to Apache Iceberg tables in Amazon S3 from Salesforce Data 360 using the Iceberg REST endpoint from AWS Glue Data Catalog
In this post, we demonstrate how AWS and Salesforce customers can access their enterprise data lakes on AWS from Salesforce Data 360 using zero-copy file federation.

Patch perfect: Automating Amazon Redshift patch testing
In this post, we demonstrate an automated test suite that validates your Amazon Redshift cluster automatically after any patch, reboot, or modification. It uses standard drivers against real workload patterns to provide a verified gate between a patch landing and that patch reaching production.

Multi-cloud lakehouse architecture on AWS for Agentic AI, Part 1: Architecture and best practices
This post focuses on explaining the architecture approach to build the open lakehouse architecture on AWS, unifying the metadata catalog across providers for the AI agents to access. In addition, it highlights the architecture trade-offs and best practices.

How Razorpay Built Real-Time Anomaly Detection with Amazon MSK
In this post, we explore Razorpay’s anomaly detection and alerting platform (ADA) architecture using Amazon Managed Streaming for Apache Kafka (Amazon MSK) and other AWS services. According to Razorpay the system detects transaction anomalies in under 30 seconds, supports thousands of merchant-level alerts, and reduced monitoring costs by approximately 80 percent. The platform maintains 99.99 percent uptime for over 500 million transactions per month.

Cut costs and simplify operations with writable warm storage in Amazon OpenSearch Service
In this post, I show you how writable warm storage removes the costly migration cycle. You can reduce your infrastructure costs by up to 48 percent and update historical data in seconds instead of hours. I walk through a real-world cost comparison and performance benchmarks, and help you decide when to use writable warm versus UltraWarm.

Introducing Apache Spark Connect support in AWS Glue interactive sessions
Apache Spark Connect bridges the gap between these two worlds: you develop in local Python, but execute on AWS Glue against actual data. Today, AWS Glue interactive sessions support Spark Connect natively. You can connect from any environment that supports the PySpark remote() API, including VS Code, PyCharm, Amazon SageMaker Unified Studio notebooks, and standalone Python applications. You don’t need to install specialized kernels or manage cluster infrastructure.
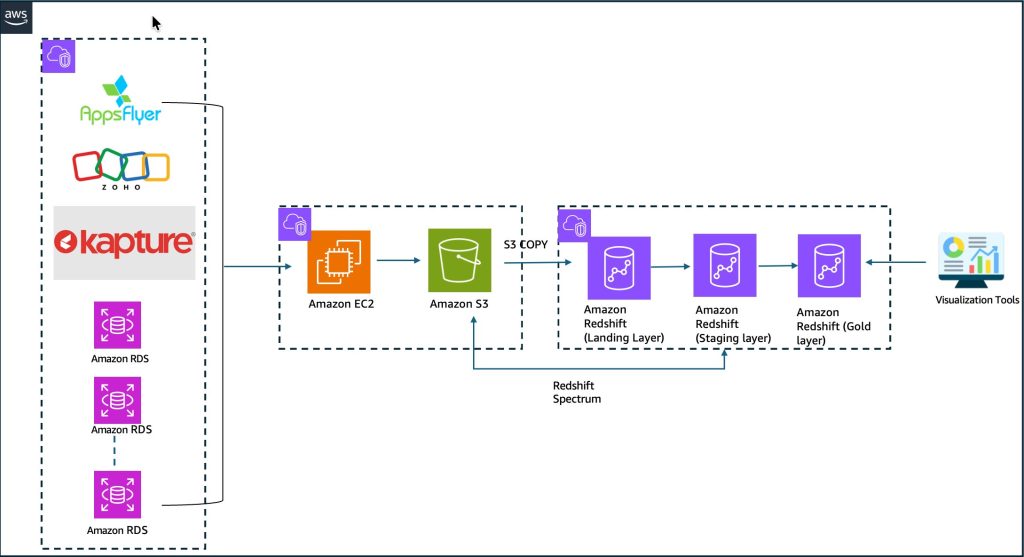
How BigBasket uses the Iceberg based lakehouse architecture on AWS to power lightning-fast grocery delivery across India
In this post, we demonstrate how BigBasket implemented the lakehouse architecture on AWS, including their architecture decisions, implementation approach, and the measurable business results you can expect from a similar modernization. Whether you’re facing scalability challenges or planning your own lakehouse implementation, this blueprint provides actionable insights you can adapt for your organization.

Accelerating log analytics at scale with AWS Glue and Apache Iceberg materialized views
In this post, you learn how to build an application log pipeline for production use with Amazon CloudWatch Logs, AWS Lambda, Amazon Data Firehose, AWS Glue, and Apache Iceberg materialized tables. You then use materialized views to accelerate query performance. This solution helps you achieve faster query response times on large-scale log data without requiring you to manage continuous data lake refresh.