AWS Big Data Blog
Category: Application Integration

A guide to capacity planning for Airflow worker pool in Amazon MWAA
In our previous post, A guide to Airflow worker pool optimization in Amazon MWAA, we explored when adding workers to your Amazon Managed Workflows for Apache Airflow (Amazon MWAA) environment actually solves performance issues, and when it doesn’t. We walked through patterns like high CPU utilization and long queue times where scaling may be appropriate, […]

Automated tag-based DAG permission management in Amazon MWAA
In this post, we show you how to use Apache Airflow tags to systematically manage DAG permissions, reducing operational burden while maintaining robust security controls that complement infrastructure-level security measures.
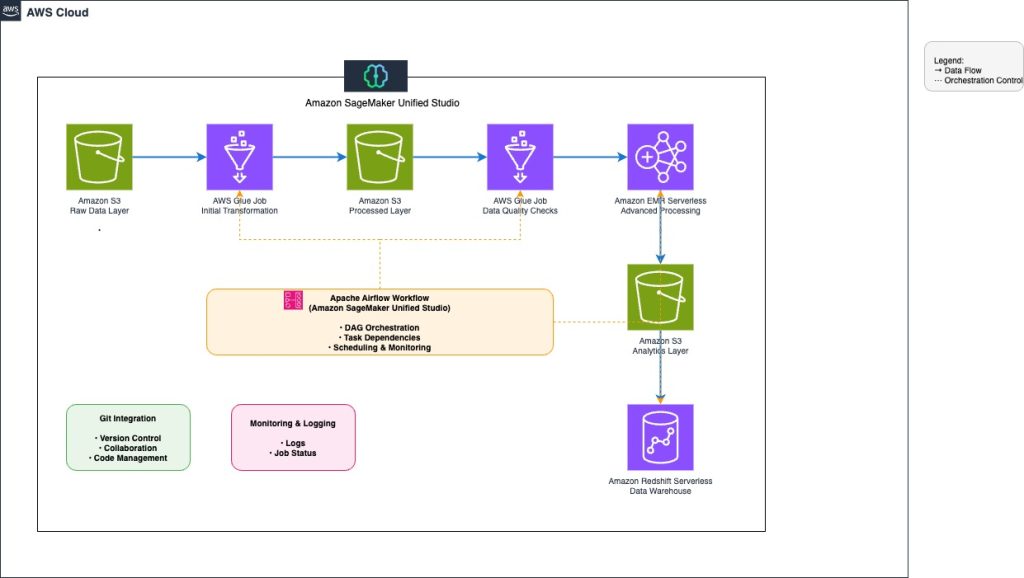
Orchestrate end-to-end scalable ETL pipeline with Amazon SageMaker workflows
This post explores how to build and manage a comprehensive extract, transform, and load (ETL) pipeline using SageMaker Unified Studio workflows through a code-based approach. We demonstrate how to use a single, integrated interface to handle all aspects of data processing, from preparation to orchestration, by using AWS services including Amazon EMR, AWS Glue, Amazon Redshift, and Amazon MWAA. This solution streamlines the data pipeline through a single UI.
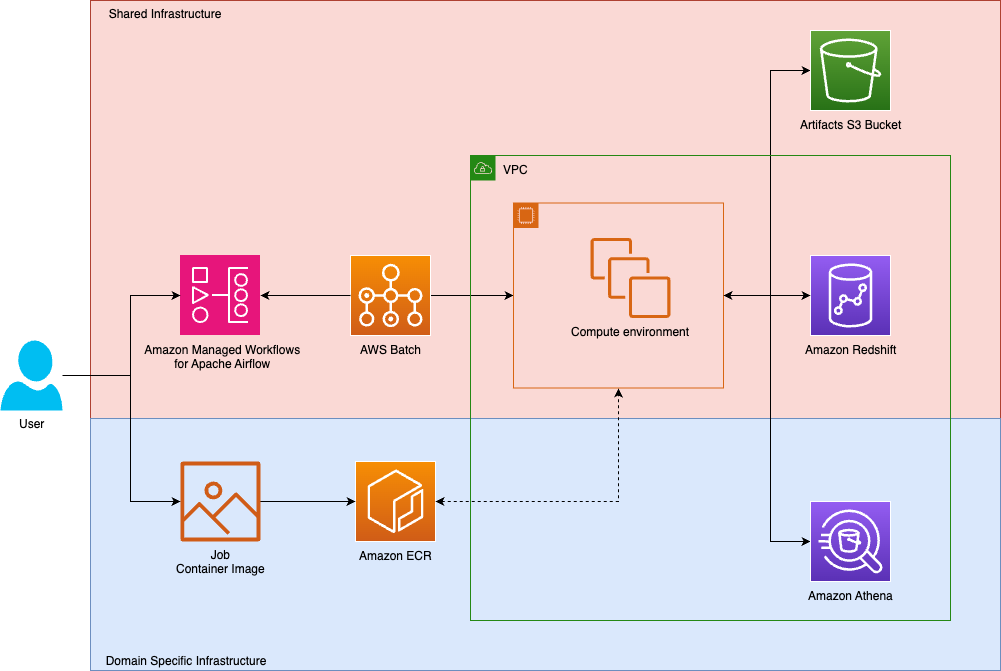
How Tipico democratized data transformations using Amazon Managed Workflows for Apache Airflow and AWS Batch
Tipico is the number one name in sports betting in Germany. Every day, we connect millions of fans to the thrill of sport, combining technology, passion, and trust to deliver fast, secure, and exciting betting, both online and in more than a thousand retail shops across Germany. We also bring this experience to Austria, where we proudly operate a strong sports betting business. In this post, we show how Tipico built a unified data transformation platform using Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and AWS Batch.

AWS analytics at re:Invent 2025: Unifying Data, AI, and governance at scale
re:Invent 2025 showcased the bold Amazon Web Services (AWS) vision for the future of analytics, one where data warehouses, data lakes, and AI development converge into a seamless, open, intelligent platform, with Apache Iceberg compatibility at its core. Across over 18 major announcements spanning three weeks, AWS demonstrated how organizations can break down data silos, […]
Building scalable AWS Lake Formation governed data lakes with dbt and Amazon Managed Workflows for Apache Airflow
Organizations often struggle with building scalable and maintainable data lakes—especially when handling complex data transformations, enforcing data quality, and monitoring compliance with established governance. Traditional approaches typically involve custom scripts and disparate tools, which can increase operational overhead and complicate access control. A scalable, integrated approach is needed to simplify these processes, improve data reliability, […]

Introducing Amazon MWAA Serverless
Today, AWS announced Amazon Managed Workflows for Apache Airflow (MWAA) Serverless. This is a new deployment option for MWAA that eliminates the operational overhead of managing Apache Airflow environments while optimizing costs through serverless scaling. In this post, we demonstrate how to use MWAA Serverless to build and deploy scalable workflow automation solutions.

Best practices for migrating from Apache Airflow 2.x to Apache Airflow 3.x on Amazon MWAA
Apache Airflow 3.x on Amazon MWAA introduces architectural improvements such as API-based task execution that provides enhanced security and isolation. This migration presents an opportunity to embrace next-generation workflow orchestration capabilities while providing business continuity. This post provides best practices and a streamlined approach to successfully navigate this critical migration, providing minimal disruption to your mission-critical data pipelines while maximizing the enhanced capabilities of Airflow 3.

Introducing Apache Airflow 3 on Amazon MWAA: New features and capabilities
AWS announced the general availability of Apache Airflow 3 on Amazon Managed Workflows for Apache Airflow (Amazon MWAA). This release transforms how organizations use Apache Airflow to orchestrate data pipelines and business processes in the cloud, bringing enhanced security, improved performance, and modern workflow orchestration capabilities to Amazon MWAA customers. This post explores the features of Airflow 3 on Amazon MWAA and outlines enhancements that improve your workflow orchestration capabilities

Use Apache Airflow workflows to orchestrate data processing on Amazon SageMaker Unified Studio
Orchestrating machine learning pipelines is complex, especially when data processing, training, and deployment span multiple services and tools. In this post, we walk through a hands-on, end-to-end example of developing, testing, and running a machine learning (ML) pipeline using workflow capabilities in Amazon SageMaker, accessed through the Amazon SageMaker Unified Studio experience. These workflows are powered by Amazon Managed Workflows for Apache Airflow.