AWS Big Data Blog
Dynamically Scale Applications on Amazon EMR with Auto Scaling
Jonathan Fritz is a Senior Product Manager for Amazon EMR
Customers running Apache Spark, Presto, and the Apache Hadoop ecosystem take advantage of Amazon EMR’s elasticity to save costs by terminating clusters after workflows are complete and resizing clusters with low-cost Amazon EC2 Spot Instances. For instance, customers can create clusters for daily ETL or machine learning jobs and shut them down when they complete, or scale out a Presto cluster serving BI analysts during business hours for ad hoc, low-latency SQL on Amazon S3.
With new support for Auto Scaling in Amazon EMR releases 4.x and 5.x, customers can now add (scale out) and remove (scale in) nodes on a cluster more easily. Scaling actions are triggered automatically by Amazon CloudWatch metrics provided by EMR at 5 minute intervals, including several YARN metrics related to memory utilization, applications pending, and HDFS utilization.
In EMR release 5.1.0, we introduced two new metrics, YARNMemoryAvailablePercentage and ContainerPendingRatio, which serve as useful cluster utilization metrics for scalable, YARN-based frameworks like Apache Spark, Apache Tez, and Apache Hadoop MapReduce. Additionally, customers can use custom CloudWatch metrics in their Auto Scaling policies.
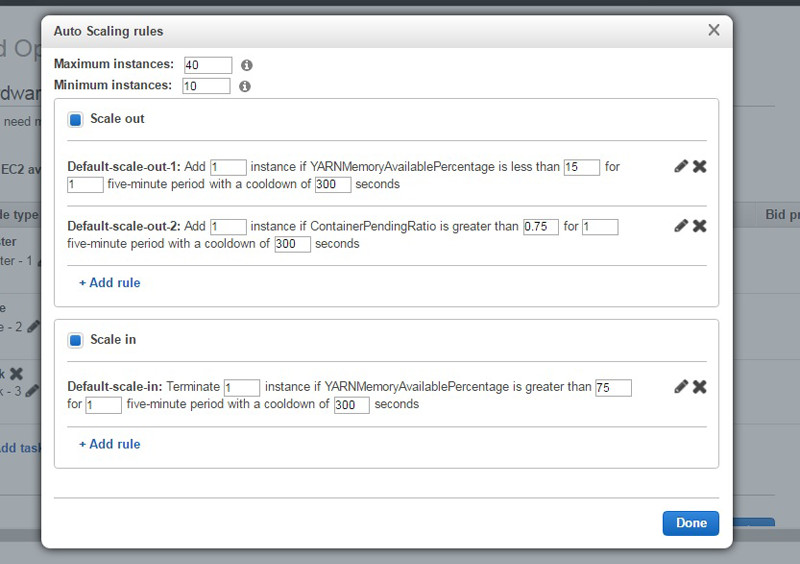
The following is an example Auto Scaling policy on an instance group that scales 1 instance at a time to a maximum of 40 instances or a minimum of 10 instances. The instance group scales out when the memory available in YARN is less than 15%, and scales in when this metric is greater than 75%: Also, the instance group scales out when the ratio of pending YARN containers over allocated YARN containers is 0.75.
Additionally, customers can now configure the scale-down behavior when nodes are terminated from their cluster on EMR 5.1.0. By default, EMR now terminates nodes only during a scale-in event at the instance hour boundary, regardless of when the request was submitted. Because EC2 charges per full hour regardless of when the instance is terminated, this behavior enables applications running on your cluster to use instances in a dynamically scaling environment more cost effectively.
Conversely, customers can set the previous default for EMR releases earlier than 5.1.0, which blacklists and drains tasks from nodes before terminating them, regardless of proximity to the instance hour boundary. With either behavior, EMR removes the least active nodes first and blocks termination if it could lead to HDFS corruption.
You can create or modify Auto Scaling polices using the EMR console, AWS CLI, or the AWS SDKs with the EMR API. To enable Auto Scaling, EMR also requires an additional IAM role to grant permission for Auto Scaling to add and terminate capacity. For more information, see Auto Scaling with Amazon EMR. If you have any questions or would like to share an interesting use case about Auto Scaling on EMR, please leave a comment below.
Related
Use Apache Flink on Amazon EMR