AWS Big Data Blog
Use Apache Flink on Amazon EMR
Craig Foster is a Big Data Engineer with Amazon EMR
Apache Flink is a parallel data processing engine that customers are using to build real time, big data applications. Flink enables you to perform transformations on many different data sources, such as Amazon Kinesis Streams or the Apache Cassandra database. It provides both batch and streaming APIs. Also, Flink has some SQL support for these stream and batch datasets. Most of Flink’s API actions are very similar to the transformations on distributed object collections found in Apache Hadoop or Apache Spark. Flink’s API is categorized into DataSets and DataStreams. DataSets are transformations on sets or collections of distributed data, while DataStreams are transformations on streaming data like those found in Amazon Kinesis.
Flink is a pure data streaming runtime engine, which means that it employs pipeline parallelism to perform operations on results of previous data transforms in real time. This means that multiple operations are performed concurrently. The Flink runtime handles exchanging data between these transformation pipelines. Also, while you may write a batch application, the same Flink streaming dataflow runtime implements it.
The Flink runtime consists of two different types of daemons: JobManagers, which are responsible for coordinating scheduling, checkpoint, and recovery functions, and TaskManagers, which are the worker processes that execute tasks and transfer data between streams in an application. Each application has one JobManager and at least one TaskManager.
You can scale the number of TaskManagers but also control parallelism further by using something called a “task slot.” In Flink-on-YARN, the JobManagers are co-located with the YARN ApplicationMaster, while each TaskManager is located in separate YARN containers allocated for the application.
Today we are making it even easier to run Flink on AWS as it is now natively supported in Amazon EMR 5.1.0. EMR supports running Flink-on-YARN so you can create either a long-running cluster that accepts multiple jobs or a short-running Flink session in a transient cluster that helps reduce your costs by only charging you for the time that you use.
You can also configure a cluster with Flink installed using the EMR configuration API with configuration classifications for logging and configuration parameters.
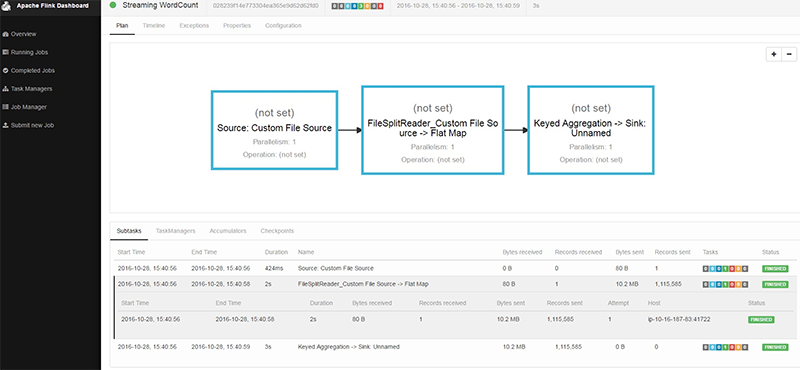
You can start using Flink on EMR today directly from the EMR console or using the CLI invocation below.
aws emr create-cluster --release-label emr-5.1.0 \
--applications Name=Flink \
--region us-east-1 \
--log-uri s3://myLogUri \
--instance-type m3.xlarge \
--instance-count 1 \
--service-role EMR_DefaultRole \
--ec2-attributes KeyName=YourKeyName,InstanceProfile=EMR_EC2_DefaultRole
To learn more about Apache Flink, see the Apache Flink documentation and to learn more about Flink on EMR, see the Flink topic in the Amazon EMR Release Guide.
Related
Use Spark 2.0, Hive 2.1 on Tez, and the latest from the Hadoop ecosystem on Amazon EMR release 5.0
