AWS Big Data Blog
Author: Sergey Konoplev
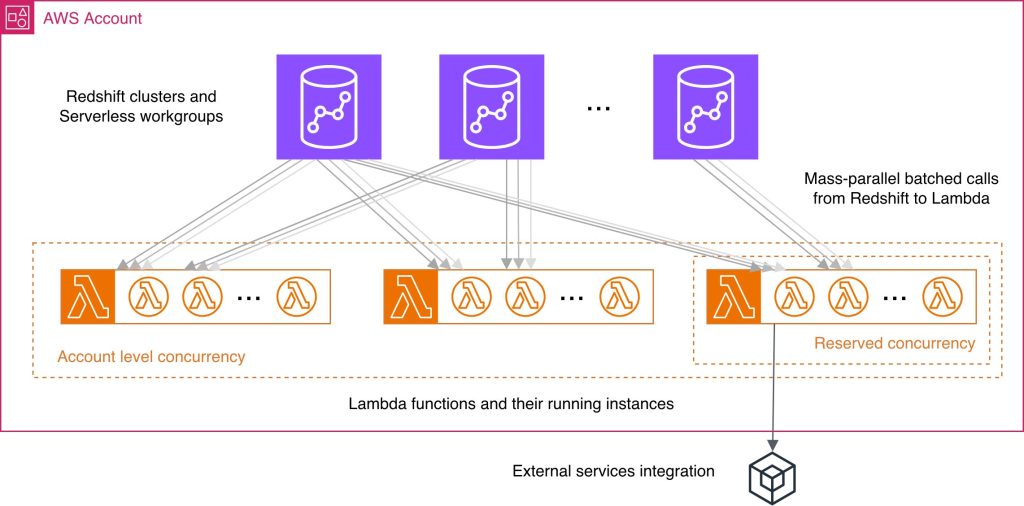
Best practices for Amazon Redshift Lambda User-Defined Functions
While working with Lambda User-Defined Functions (UDFs) in Amazon Redshift, knowing best practices may help you streamline the respective feature development and reduce common performance bottlenecks and unnecessary costs. You wonder what programming language could improve your UDF performance, how else can you use batch processing benefits, what concurrency management considerations might be applicable in your case? In this post, we answer these and other questions by providing a consolidated view of practices to improve your Lambda UDF efficiency. We explain how to choose a programming language, use existing libraries effectively, minimize payload sizes, manage return data, and batch processing. We discuss scalability and concurrency considerations at both the account and per-function levels. Finally, we examine the benefits and nuances of using external services with your Lambda UDFs.

Query and visualize Amazon Redshift operational metrics using the Amazon Redshift plugin for Grafana
Grafana is a rich interactive open-source tool by Grafana Labs for visualizing data across one or many data sources. It’s used in a variety of modern monitoring stacks, allowing you to have a common technical base and apply common monitoring practices across different systems. Amazon Managed Grafana is a fully managed, scalable, and secure Grafana-as-a-service […]