AWS Big Data Blog
Author: Amir Shenavandeh

Get a quick start with Apache Hudi, Apache Iceberg, and Delta Lake with Amazon EMR on EKS
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can keep your data as is in your object store or file-based storage without having to first structure the data. Additionally, you can run different types of analytics against your loosely formatted data […]
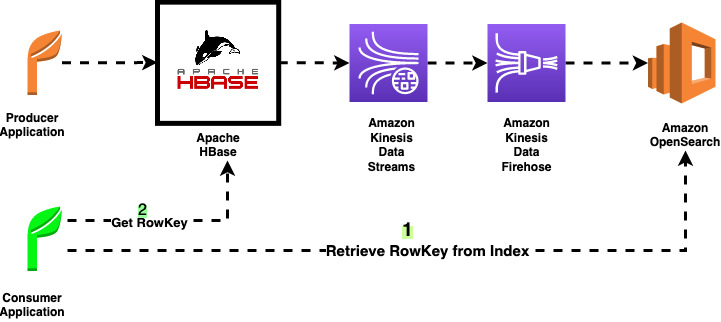
Stream Apache HBase edits for real-time analytics
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Apache HBase is a non-relational database. To use the data, applications need to query the database to pull the data and changes from tables. In this post, […]
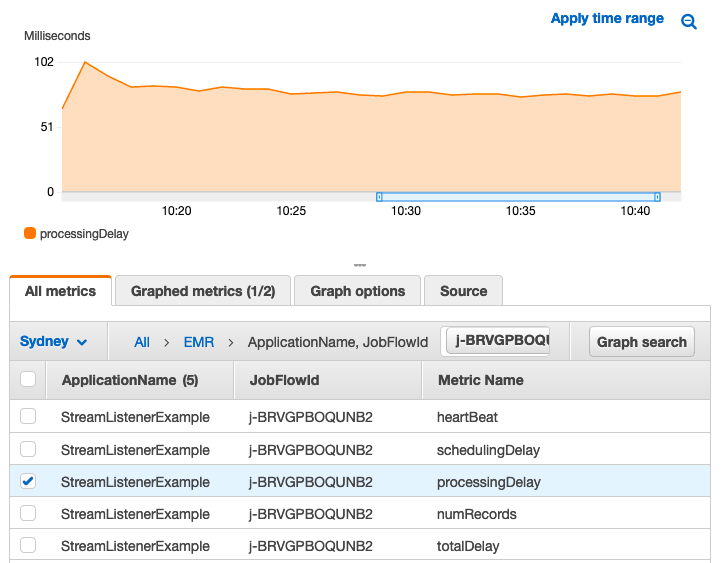
Monitor Spark streaming applications on Amazon EMR
This post demonstrates how to implement a simple SparkListener, monitor and observe Spark streaming applications, and set up some alerts. The post also shows how to use alerts to set up automatic scaling on Amazon EMR clusters, based on your CloudWatch custom metrics.