AWS Big Data Blog
Stream Apache HBase edits for real-time analytics
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
Apache HBase is a non-relational database. To use the data, applications need to query the database to pull the data and changes from tables. In this post, we introduce a mechanism to stream Apache HBase edits into streaming services such as Apache Kafka or Amazon Kinesis Data Streams. In this approach, changes to data are pushed and queued into a streaming platform such as Kafka or Kinesis Data Streams for real-time processing, using a custom Apache HBase replication endpoint.
We start with a brief technical background on HBase replication and review a use case in which we store IoT sensor data into an HBase table and enrich rows using periodic batch jobs. We demonstrate how this solution enables you to enrich the records in real time and in a serverless way using AWS Lambda functions.
Common scenarios and use cases of this solution are as follows:
- Auditing data, triggers, and anomaly detection using Lambda
- Shipping WALEdits via Kinesis Data Streams to Amazon OpenSearch Service to index records asynchronously
- Triggers on Apache HBase bulk loads
- Processing streamed data using Apache Spark Streaming, Apache Flink, Amazon Kinesis Data Analytics, or Kinesis analytics
- HBase edits or change data capture (CDC) replication into other storage platforms, such as Amazon Simple Storage Service (Amazon S3), Amazon Relational Database Service (Amazon RDS), and Amazon DynamoDB
- Incremental HBase migration by replaying the edits from any point in time, based on configured retention in Kafka or Kinesis Data Streams
This post progresses into some common use cases you might encounter, along with their design options and solutions. We review and expand on these scenarios in separate sections, in addition to the considerations and limits in our application designs.
Introduction to HBase replication
At a very high level, the principle of HBase replication is based on replaying transactions from a source cluster to the destination cluster. This is done by replaying WALEdits or Write Ahead Log entries on the RegionServers of the source cluster into the destination cluster. To explain WALEdits, in HBase, all the mutations in data like PUT or DELETE are written to MemStore of their specific region and are appended to a WAL file as WALEdits or entries. Each WALEdit represents a transaction and can carry multiple write operations on a row. Because the MemStore is an in-memory entity, in case a region server fails, the lost data can be replayed and restored from the WAL files. Having a WAL is optional, and some operations may not require WALs or can request to bypass WALs for quicker writes. For example, records in a bulk load aren’t recorded in WAL.
HBase replication is based on transferring WALEdits to the destination cluster and replaying them so any operation that bypasses WAL isn’t replicated.
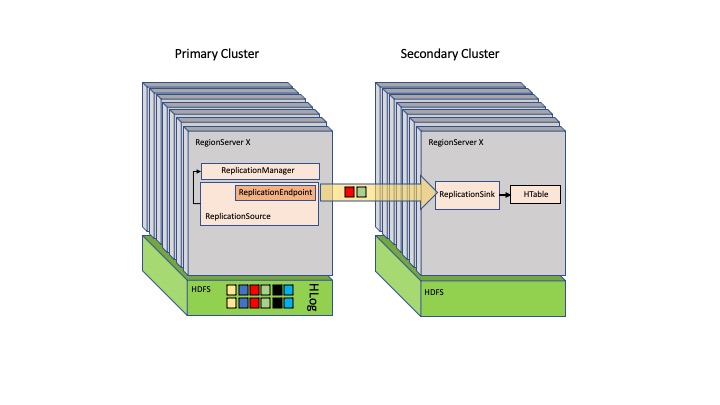
When setting up a replication in HBase, a ReplicationEndpoint implementation needs to be selected in the replication configuration when creating a peer, and on every RegionServer, an instance of ReplicationEndpoint runs as a thread. In HBase, a replication endpoint is pluggable for more flexibility in replication and shipping WALEdits to different versions of HBase. You can also use this to build replication endpoints for sending edits to different platforms and environments. For more information about setting up replication, see Cluster Replication.
HBase bulk load replication HBASE-13153
In HBase, bulk loading is a method to directly import HFiles or Store files into RegionServers. This avoids the normal write path and WALEdits. As a result, far less CPU and network resources are used when importing big portions of data into HBase tables.
You can also use HBase bulk loads to recover data when an error or outage causes the cluster to lose track of regions and Store files.
Because bulk loads skip WAL creation, all new records aren’t replicated to the secondary cluster. In HBASE-13153, which is an enhancement, a bulk load is represented as a bulk load event, carrying the location of the imported files. You can activate this by setting hbase.replication.bulkload.enabled to true and setting hbase.replication.cluster.id to a unique value as a prerequisite.
Custom streaming replication endpoint
We can use HBase’s pluggable endpoints to stream records into platforms such as Kinesis Data Streams or Kafka. Transferred records can be consumed by Lambda functions, processed by a Spark Streaming application or Apache Flink on Amazon EMR, Kinesis Data Analytics, or any other big data platform.
In this post, we demonstrate an implementation of a custom replication endpoint that allows replicating WALEdits in Kinesis Data Streams or Kafka topics.
In our example, we built upon the BaseReplicationEndpoint abstract class, inheriting the ReplicationEndpoint interface.
The main method to implement and override is the replicate method. This method replicates a set of items it receives every time it’s called and blocks until all those records are replicated to the destination.
For our implementation and configuration options, see our GitHub repository.
Use case: Enrich records in real time
We now use the custom streaming replication endpoint implementation to stream HBase edits to Kinesis Data Streams.
The provided AWS CloudFormation template demonstrates how we can set up an EMR cluster with replication to either Kinesis Data Streams or Apache Kafka and consume the replicated records, using a Lambda function to enrich data asynchronously, in real time. In our sample project, we launch an EMR cluster with an HBase database. A sample IoT traffic generator application runs as a step in the cluster and puts records, containing a registration number and an instantaneous speed, into a local HBase table. Records are replicated in real time into a Kinesis stream or Kafka topic based on the selected option at launch, using our custom HBase replication endpoint. When the step starts putting the records into the stream, a Lambda function is provisioned and starts digesting records from the beginning of the stream and catches up with the stream. The function calculates a score per record, based on a formula on variation from minimum and maximum speed limits in the use case, and persists the result as a score qualifier into a different column family, out of replication scope in the source table, by running HBase puts on RowKey.
The following diagram illustrates this architecture.
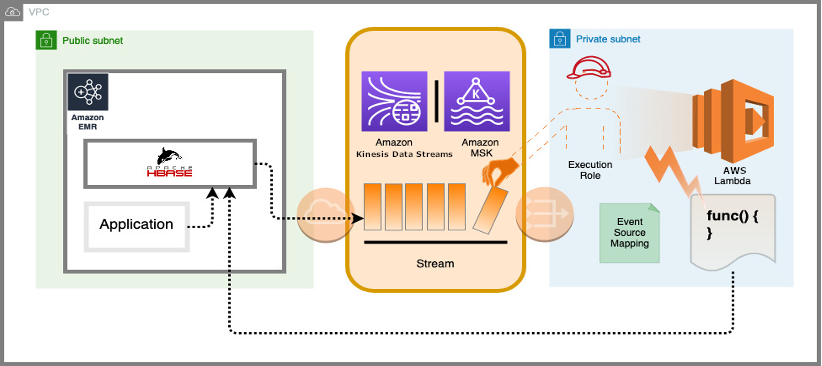
To launch our sample environment, you can use our template on GitHub.
The template creates a VPC, public and private subnets, Lambda functions to consume records and prepare the environment, an EMR cluster with HBase, and a Kinesis data stream or an Amazon Managed Streaming for Apache Kafka (Amazon MSK) cluster depending on the selected parameters when launching the stack.
Architectural design patterns
Traditionally, Apache HBase tables are considered as data stores, where consumers get or scan the records from tables. It’s very common in modern databases to react to database logs or CDC for real-time use cases and triggers. With our streaming HBase replication endpoint, we can project table changes into message delivery systems like Kinesis Data Streams or Apache Kafka.
We can trigger Lambda functions to consume messages and records from Apache Kafka or Kinesis Data Streams to consume the records in a serverless design or the wider Amazon Kinesis ecosystems such as Kinesis Data Analytics or Amazon Kinesis Data Firehose for delivery into Amazon S3. You could also pipe in Amazon OpenSearch Service.
A wide range of consumer ecosystems, such as Apache Spark, AWS Glue, and Apache Flink, is available to consume from Kafka and Kinesis Data Streams.
Let’s review few other common use cases.
Index HBase rows
Apache HBase rows are retrievable by RowKey. Writing a row into HBase with the same RowKey overwrites or creates a new version of the row. To retrieve a row, it needs to be fetched by the RowKey or a range of rows needs to be scanned if the RowKey is unknown.
In some use cases, scanning the table for a specific qualifier or value is expensive if we index our rows in another parallel system like Elasticsearch asynchronously. Applications can use the index to find the RowKey. Without this solution, a periodic job has to scan the table and write them into an indexing service like Elasticsearch to hydrate the index, or the producing application has to write in both HBase and Elasticsearch directly, which adds overhead to the producer.
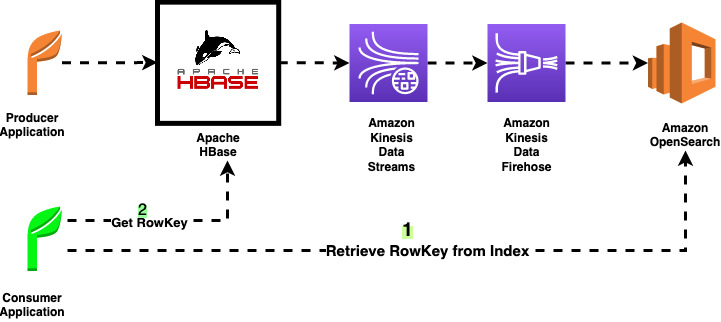
Enrich and audit data
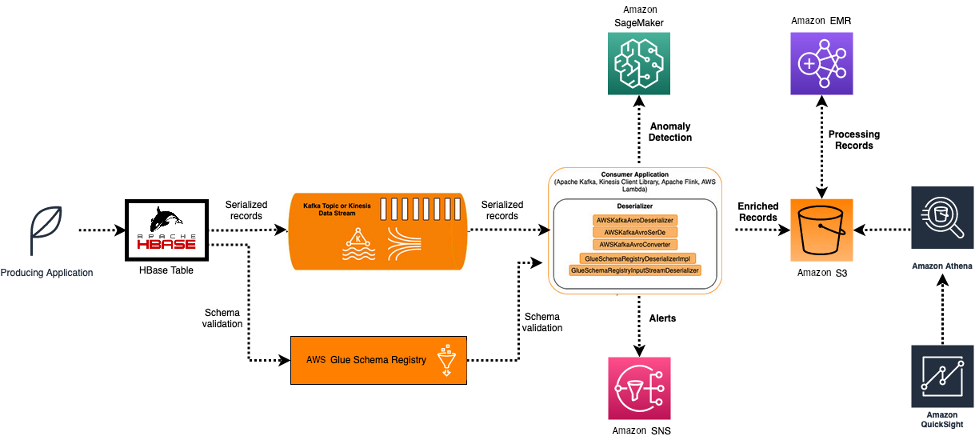
A very common use case for HBase streaming endpoints is enriching data and storing the enriched records in a data store, such as Amazon S3 or RDS databases. In this scenario, a custom HBase replication endpoint streams the records into a message distribution system such as Apache Kafka or Kinesis Data Streams. Records can be serialized, using the AWS Glue Schema Registry for schema validation. A consumer on the other end of the stream reads the records, enriches them, and validates against a machine learning model in Amazon SageMaker for anomaly detection. The consumer persists the records in Amazon S3 and potentially triggers an alert using Amazon Simple Notification Service (Amazon SNS). Stored data on Amazon S3 can be further digested on Amazon EMR, or we can create a dashboard on Amazon QuickSight, interfacing Amazon Athena for queries.
The following diagram illustrates our architecture.
Store and archive data lineage
Apache HBase comes with the snapshot feature. You can freeze the state of tables into snapshots and export them to any distributed file system like HDFS or Amazon S3. Recovering snapshots restores the entire table to the snapshot point.
Apache HBase also supports versioning at the row level. You can configure column families to keep row versions, and the default versioning is based on timestamps.
However, when using this approach to stream records into Kafka or Kinesis Data Streams, records are retained inside the stream, and you can partially replay a period. Recovering snapshots only recovers up to the snapshot point and the future records aren’t present.
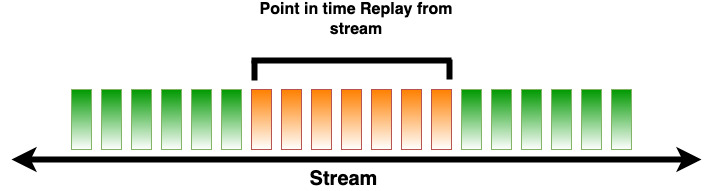
In Kinesis Data Streams, by default records of a stream are accessible for up to 24 hours from the time they are added to the stream. This limit can be increased to up to 7 days by enabling extended data retention, or up to 365 days by enabling long-term data retention. See Quotas and Limits for more information.
In Apache Kafka, record retention has virtually no limits based on available resources and disk space configured on the Kafka cluster, and can be configured by setting log.retention.
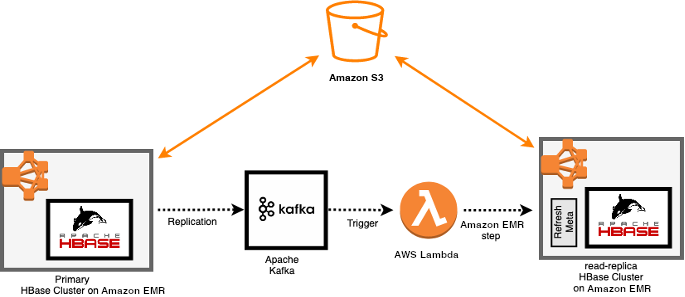
Trigger on HBase bulk load
The HBase bulk load feature uses a MapReduce job to output table data in HBase’s internal data format, and then directly loads the generated Store files into the running cluster. Using bulk load uses less CPU and network resources than loading via the HBase API, as HBase bulk load bypasses WALs in the write path and the records aren’t seen by replication. However, since HBASE-13153, you can configure HBase to replicate a meta record as an indication of a bulk load event.
A Lambda function processing replicated WALEdits can listen to this event to trigger actions, such as automatically refreshing a read replica HBase cluster on Amazon S3 whenever a bulk load happens. The following diagram illustrates this workflow.
Considerations for replication into Kinesis Data Streams
Kinesis Data Streams is a massively scalable and durable real-time data streaming service. Kinesis Data Streams can continuously capture gigabytes of data per second from hundreds of thousands of sources with very low latency. Kinesis is fully managed and runs your streaming applications without requiring you to manage any infrastructure. It’s durable, because records are synchronously replicated across three Availability Zones, and you can increase data retention to 365 days.
When considering Kinesis Data Streams for any solution, it’s important to consider service limits. For instance, as of this writing, the maximum size of the data payload of a record before base64-encoding is up to 1 MB, so we must make sure the records or serialized WALEdits remain within the Kinesis record size limit. To be more efficient, you can enable the hbase.replication.compression-enabled attribute to GZIP compress the records before sending them to the configured stream sink.
Kinesis Data Streams retains the order of the records within the shards as they arrive, and records can be read or processed in the same order. However, in this sample custom replication endpoint, a random partition key is used so that the records are evenly distributed between the shards. We can also use a hash function to generate a partition key when putting records into the stream, for example based on the Region ID so that all the WALEdits from the same Region land in the same shard and consumers can assume Region locality per shards.
For delivering records in KinesisSinkImplemetation, we use the Amazon Kinesis Producer Library (KPL) to put records into Kinesis data streams. The KPL simplifies producer application development; we can achieve high write throughput to a Kinesis data stream. We can use the KPL in either synchronous or asynchronous use cases. We suggest using the higher performance of the asynchronous interface unless there is a specific reason to use synchronous behavior. KPL is very configurable and has retry logic built in. You can also perform record aggregation for maximum throughput. In KinesisSinkImplemetation, by default records are asynchronously replicated to the stream. We can change to synchronous mode by setting hbase.replication.kinesis.syncputs to true. We can enable record aggregation by setting hbase.replication.kinesis.aggregation-enabled to true.
The KPL can incur an additional processing delay because it buffers records before sending them to the stream based on a user-configurable attribute of RecordMaxBufferedTime. Larger values of RecordMaxBufferedTime results in higher packing efficiencies and better performance. However, applications that can’t tolerate this additional delay may need to use the AWS SDK directly.
Kinesis Data Streams and the Kinesis family are fully managed and easily integrate with the rest of the AWS ecosystem with minimum development effort with services such as the AWS Glue Schema Registry and Lambda. We recommend considering Kinesis Data Streams for low-latency, real-time use cases on AWS.
Considerations for replication into Apache Kafka
Apache Kafka is a high-throughput, scalable, and highly available open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
AWS offers Amazon MSK as a fully managed Kafka service. Amazon MSK provides the control plane operations and runs open-source versions of Apache Kafka. Existing applications, tooling, and plugins from partners and the Apache Kafka community are supported without requiring changes to application code.
You can configure this sample project for Apache Kafka brokers directly or just point towards an Amazon MSK ARN for replication.
Although there is virtually no limit on the size of the messages in Kafka, the default maximum message size is set to 1 MB by default, so we must make sure the records, or serialized WALEdits, remain within the maximum message size for topics.
The Kafka producer tries to batch records together whenever possible to limit the number of requests for more efficiency. This is configurable by setting batch.size, linger.ms, and delivery.timeout.ms.
In Kafka, topics are partitioned, and partitions are distributed between different Kafka brokers. This distributed placement allows for load balancing of consumers and producers. When a new event is published to a topic, it’s appended to one of the topic’s partitions. Events with the same event key are written to the same partition, and Kafka guarantees that any consumer of a given topic partition can always read that partition’s events in exactly the same order as they were written. KafkaSinkImplementation uses a random partition key to distribute the messages evenly between the partitions. This could be based on a heuristic function, for example based on Region ID, if the order of the WALEdits or record locality is important by the consumers.
Semantic guarantees
Like any streaming application, it’s important to consider semantic guarantee from the producer of messages, to acknowledge or fail the status of delivery of messages in the message queue and checkpointing on the consumer’s side. Based on our use cases, we need to consider the following:
- At most once delivery – Messages are never delivered more than once, and there is a chance of losing messages
- At least once delivery – Messages can be delivered more than once, with no loss of messages
- Exactly once delivery – Every message is delivered only once, and there is no loss of messages
After changes are persisted as WALs and in MemStore, the replicate method in ReplicationEnpoint is called to replicate a collection of WAL entries and returns a Boolean (true/false) value. If the returned value is true, the entries are considered successfully replicated by HBase and the replicate method is called for the next batch of WAL entries. Depending on configuration, both KPL and Kafka producers might buffer the records for longer if configured for asynchronous writes. Failures can cause loss of entries, retries, and duplicate delivery of records to the stream, which could be determinantal for synchronous or asynchronous message delivery.
If our operations aren’t idempotent, you can checkpoint or check for unique sequence numbers on the consumer side. For a simple HBase record replication, RowKey operations are idempotent and they carry a timestamp and sequence ID.
Summary
Replication of HBase WALEdits into streams is a powerful tool that you can use in multiple use cases and in combination with other AWS services. You can create practical solutions to further process records in real time, audit the data, detect anomalies, set triggers on ingested data, or archive data in streams to be replayed on other HBase databases or storage services from a point in time. This post outlined some common use cases and solutions, along with some best practices when implementing your custom HBase streaming replication endpoints.
Review, clone, and try our HBase replication endpoint implementation from our GitHub repository and launch our sample CloudFormation template.
We like to learn about your use cases. If you have questions or suggestions, please leave a comment.
About the Authors
 Amir Shenavandeh is a Senior Hadoop systems engineer and Amazon EMR subject matter expert at Amazon Web Services. He helps customers with architectural guidance and optimization. He leverages his experience to help people bring their ideas to life, focusing on distributed processing and big data architectures.
Amir Shenavandeh is a Senior Hadoop systems engineer and Amazon EMR subject matter expert at Amazon Web Services. He helps customers with architectural guidance and optimization. He leverages his experience to help people bring their ideas to life, focusing on distributed processing and big data architectures.
 Maryam Tavakoli is a Cloud Engineer and Amazon OpenSearch subject matter expert at Amazon Web Services. She helps customers with their Analytics and Streaming workload optimization and is passionate about solving complex problems with simplistic user experience that can empower customers to be more productive.
Maryam Tavakoli is a Cloud Engineer and Amazon OpenSearch subject matter expert at Amazon Web Services. She helps customers with their Analytics and Streaming workload optimization and is passionate about solving complex problems with simplistic user experience that can empower customers to be more productive.