AWS Big Data Blog
Build your data pipeline in your AWS modern data platform using AWS Lake Formation, AWS Glue, and dbt Core
dbt has established itself as one of the most popular tools in the modern data stack, and is aiming to bring analytics engineering to everyone. The dbt tool makes it easy to develop and implement complex data processing pipelines, with mostly SQL, and it provides developers with a simple interface to create, test, document, evolve, and deploy their workflows. For more information, see docs.getdbt.com.
dbt primarily targets cloud data warehouses such as Amazon Redshift or Snowflake. Now, you can use dbt against AWS data lakes, thanks to the following two services:
- AWS Glue Interactive Sessions, a serverless Apache Spark runtime environment managed by AWS Glue with on-demand access and a 1-minute billing minimum
- AWS Lake Formation, a service that makes it easy to quickly set up a secure data lake
In this post, you’ll learn how to deploy a data pipeline in your modern data platform using the dbt-glue adapter built by the AWS Professional Services team in collaboration with dbtlabs.
With this new open-source, battle-tested dbt AWS Glue adapter, developers can now use dbt for their data lakes, paying for just the compute they need, with no need to shuffle data around. They still have access to everything that makes dbt great, including the local developer experience, documentation, tests, incremental data processing, Git integration, CI/CD, and more.
dbt-glue is a dbt Cloud trusted adapter. Trusted adapters in dbt Cloud undergo additional processes that covers development, documentation, user experience, and maintenance requirements.
Solution overview
The following diagram shows the architecture of the solution.
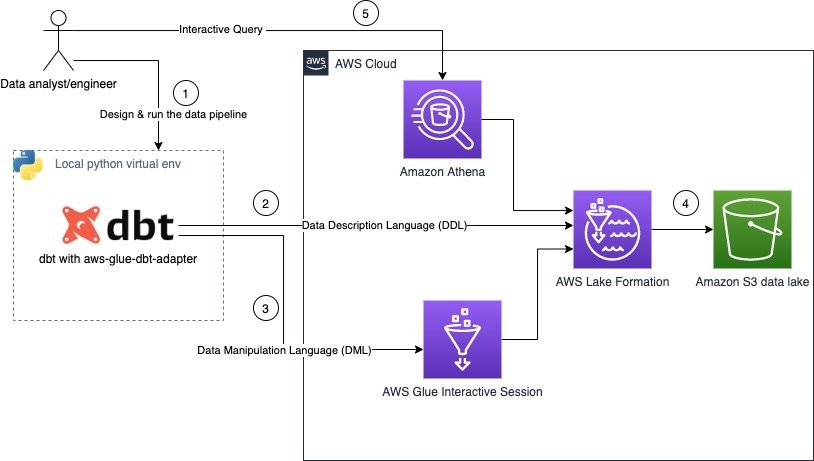
The steps in this workflow are as follows:
- The data team configures a local Python virtual environment and creates a data pipeline with dbt.
- The
dbt-glueadapter uses Lake Formation to perform all structure manipulation, like creation of database, tables. or views. - The
dbt-glueadapter uses AWS Glue interactive sessions as the backend for processing your data. - All data is stored in Amazon Simple Storage Service (Amazon S3) as Parquet open file format.
- The data team can now query all data stored in the data lake using Amazon Athena.
Walkthrough overview
For this post, you run a data pipeline that creates indicators based on NYC taxi data by following these steps:
- Deploy the provided AWS CloudFormation stack in Region
us-east-1. - Configure your Amazon CloudShell environment.
- Install dbt, the dbt CLI, and the dbt adaptor.
- Use CloudShell to clone the project and configure it to use your account’s configuration.
- Run dbt to implement the data pipeline.
- Query the data with Athena.
For our use case, we use the data from the New York City Taxi Records dataset. This dataset is available in the Registry of Open Data on AWS (RODA), which is a repository containing public datasets from AWS resources.
The CloudFormation template creates the nyctaxi database in your AWS Glue Data Catalog and a table (records) that points to the public dataset. You don’t need to host the data in your account.
Prerequisites
The CloudFormation template used by this project configures the AWS Identity and Access Management (IAM) role GlueInteractiveSessionRole with all the mandatory permissions.
For more details on permissions for AWS Glue interactive sessions, refer to Securing AWS Glue interactive sessions with IAM.
Deploy resources with AWS CloudFormation
The CloudFormation stack deploys all the required infrastructure:
- An IAM role with all the mandatory permissions to run an AWS Glue interactive session and the
dbt-glueadapter. - An AWS Glue database and table to store the metadata related to the NYC taxi records dataset
- An S3 bucket to use as output and store the processed data
- An Athena configuration (a workgroup and S3 bucket to store the output) to explore the dataset
- An AWS Lambda function as an AWS CloudFormation custom resource that updates all the partitions in the AWS Glue table
To create these resources, choose Launch Stack and follow the instructions:
![]()
Configure the CloudShell environment
To start working with the shell, complete the following steps:
- Sign in to the AWS Management Console and launch CloudShell using either one of the following two methods:
- Choose the CloudShell icon on the console navigation bar.
- Enter
cloudshellin the Find Services box and then choose the CloudShell option.

- Because
dbtand thedbt-glueadapter are compatible with Python versions 3.7, 3.8, and 3.9, check the version of Python: - Configure a Python virtual environment to isolate the package version and code dependencies:
- Configure the
aws-glue-sessionpackage:
Install dbt, the dbt CLI, and the dbt adaptor
The dbt CLI is a command-line interface for running dbt projects. It’s is free to use and available as an open source project. Install dbt and the dbt CLI with the following code:
For more information, refer to How to install dbt, What is dbt?, and Viewpoint.
Install the dbt adapter with the following code:
Clone the project
The dbt AWS Glue interactive session demo project contains an example of a data pipeline that produces metrics based on NYC taxi dataset. Clone the project with the following code:
This project comes with the following configuration example:
The following table summarizes the parameter options for the adaptor.
| Option | Description | Mandatory |
| project_name | The dbt project name. This must be the same as the one configured in the dbt project. | yes |
| type | The driver to use. | yes |
| query-comment | A string to inject as a comment in each query that dbt runs. | no |
| role_arn | The ARN of the interactive session role created as part of the CloudFormation template. | yes |
| region | The AWS Region were you run the data pipeline. | yes |
| workers | The number of workers of a defined workerType that are allocated when a job runs. | yes |
| worker_type | The type of predefined worker that is allocated when a job runs. Accepts a value of Standard, G.1X, or G.2X. | yes |
| schema | The schema used to organize data stored in Amazon S3. | yes |
| database | The database in Lake Formation. The database stores metadata tables in the Data Catalog. | yes |
| session_provisioning_timeout_in_seconds | The timeout in seconds for AWS Glue interactive session provisioning. | yes |
| location | The Amazon S3 location of your target data. | yes |
| idle_timeout | The AWS Glue session idle timeout in minutes. (The session stops after being idle for the specified amount of time.) | no |
| glue_version | The version of AWS Glue for this session to use. Currently, the only valid options are 2.0 and 3.0. The default value is 2.0. | no |
| security_configuration | The security configuration to use with this session. | no |
| connections | A comma-separated list of connections to use in the session. | no |
Run the dbt project
The objective of this sample project is to create the following four tables, which contain metrics based on the NYC taxi dataset:
- silver_nyctaxi_avg_metrics – Basic metrics based on NYC Taxi Open Data for the year 2016
- gold_nyctaxi_passengers_metrics – Metrics per passenger based on the silver metrics table
- gold_nyctaxi_distance_metrics – Metrics per distance based on the silver metrics table
- gold_nyctaxi_cost_metrics – Metrics per cost based on the silver metrics table
- To run the project dbt, you should be in the project folder:
- The project requires you to set environment variables in order to run on the AWS account:
- Make sure the profile is set up correctly from the command line:
- Run the models with the following code:
- Generate documentation for the project:
- View the documentation for the project:
Query data via Athena
This section demonstrates how to query the target table using Athena. To query the data, complete the following steps:
- On the Athena console, switch the workgroup to
athena-dbt-glue-aws-blog. - If the Workgroup athena-dbt-glue-aws-blog settings dialog box appears, choose Acknowledge.
- Use the following query to explore the metrics created by the dbt project:
The following screenshot shows the results of this query.

Clean Up
To clean up your environment, complete the following steps in CloudShell:
- Delete the database created by dbt:
- Delete all generated data:
- Delete the CloudFormation stack:
Summary
This post demonstrates how AWS managed services are key enablers and accelerators to build a modern data platform at scale or take advantage of an existing one.
With the introduction of dbt and aws-glue-dbt-adapter, data teams can access data stored in your modern data platform using SQL statements to extract value from data.
To report a bug or request a feature, please open an issue on GitHub. If you have any questions or suggestions, leave your feedback in the comment section. If you need further assistance to optimize your modern data platform, contact your AWS account team or a trusted AWS Partner.
About the Authors
 Benjamin Menuet is a Data Architect with AWS Professional Services. He helps customers develop big data and analytics solutions to accelerate their business outcomes. Outside of work, Benjamin is a trail runner and has finished some mythic races like the UTMB.
Benjamin Menuet is a Data Architect with AWS Professional Services. He helps customers develop big data and analytics solutions to accelerate their business outcomes. Outside of work, Benjamin is a trail runner and has finished some mythic races like the UTMB.
 Armando Segnini is a Data Architect with AWS Professional Services. He spends his time building scalable big data and analytics solutions for AWS Enterprise and Strategic customers. Armando also loves to travel with his family all around the world and take pictures of the places he visits.
Armando Segnini is a Data Architect with AWS Professional Services. He spends his time building scalable big data and analytics solutions for AWS Enterprise and Strategic customers. Armando also loves to travel with his family all around the world and take pictures of the places he visits.
 Moshir Mikael is a Senior Practice Manager with AWS Professional Services. He led development of large enterprise data platforms in EMEA and currently leading the Professional Services teams in EMEA for analytics.
Moshir Mikael is a Senior Practice Manager with AWS Professional Services. He led development of large enterprise data platforms in EMEA and currently leading the Professional Services teams in EMEA for analytics.
 Anouar Zaaber is a Senior Engagement Manager in AWS Professional Services. He leads internal AWS teams, external partners, and customer teams to deliver AWS cloud services that enable customers to realize their business outcomes.
Anouar Zaaber is a Senior Engagement Manager in AWS Professional Services. He leads internal AWS teams, external partners, and customer teams to deliver AWS cloud services that enable customers to realize their business outcomes.