AWS Big Data Blog
Get sub-second query response times with Amazon Redshift result caching
Customers tell us that their data warehouse and business intelligence users want extremely fast response times so that they can make equally fast decisions. They also tell us that their users often repeat the same queries over and over again, even when the data has not changed. Repeat queries consume compute resources each time they are executed, which slows down performance for all queries.
In this post, we take a look at query result caching in Amazon Redshift. Result caching does exactly what its name implies—it caches the results of a query. When the same query comes in against the same data, the prior results are retrieved from the cache and returned immediately, instead of rerunning the same query. Result caching reduces system use, making more resources available for other workloads. It delivers faster response times for users, improves throughput for all queries, and increases concurrency.
Result caching options
There are two main ways that you can implement data warehouse result caching. The first method is to save subsets of the data tables and cache query results outside the data warehouse. This method requires additional logic and memory outside the data warehouse. You must take great care to ensure that the cache is invalidated and a query is rerun when table data is modified.
The second method is to cache the results of a query inside the data warehouse and return the cached result for future repeat queries. This method delivers higher performance because it is faster to cache data and serve it from within the cluster.
Amazon Redshift uses the second method to cache query results within the cluster to achieve higher query throughput. Amazon Redshift result caching automatically responds to data and workload changes, transparently serving multiple BI applications and SQL tools. It is available by default for all Amazon Redshift customers for no additional charge.
Since Amazon Redshift introduced result caching, the feature has saved customers thousands of hours of execution time on a daily basis. “With Amazon Redshift result caching, 20 percent of our queries now complete in less than one second,” said Greg Rokita, Executive Director of Technology, Edmunds, at the AWS Summit in San Francisco. “Our cluster reliance on disk has decreased, and consequently the cluster is able to better serve the rest of our queries. Best of all, we didn’t have to change anything to get this speed-up with Redshift, which supports our mission-critical workloads.”
How does it work?
When a query is executed in Amazon Redshift, both the query and the results are cached in memory. As future queries come in, they are normalized and compared to the queries in the cache to determine whether there are repeat queries. In this comparison, Amazon Redshift also determines whether the underlying data has changed in any way. Any data modification language (DML) or data definition language (DDL) on a table or function invalidates only the cache entries that refer to it. Examples of such statements include INSERT, DELETE, UPDATE, COPY, and TRUNCATE. Amazon Redshift manages the cache memory to evict old entries, ensuring that optimal memory use is maintained for the cache itself.
Result caching is fully managed by Amazon Redshift, and it requires no changes in your application code. Amazon Redshift automatically selects the optimal configuration based on the specific condition of your cluster, and no tuning is required for you to get the most effective configuration.
When Amazon Redshift determines that a query is eligible to reuse prior query cached results, it bypasses query planning, the workload manager (WLM), and the query execution engine altogether. Cached result rows are returned to the client application immediately with sub-second performance. This method frees up cluster resources for ETL (extract, transform, and load) and other workloads that need the compute resources.
Design and usage
The following diagram illustrates the architecture of Amazon Redshift result caching.
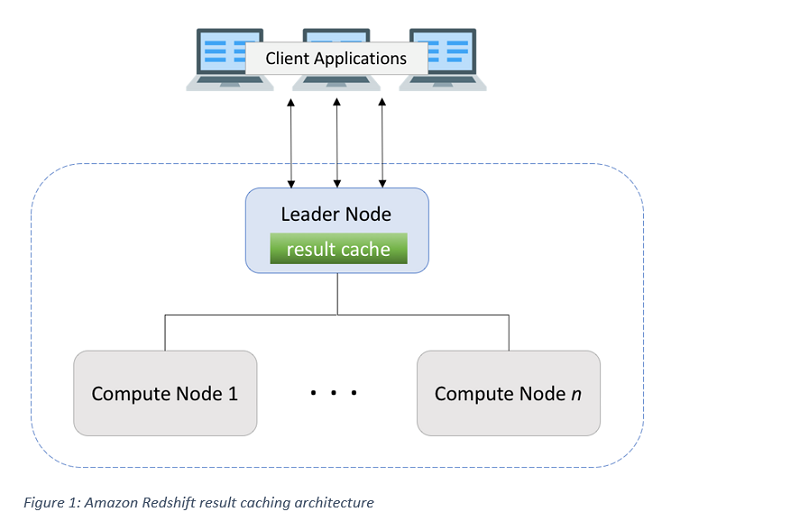
The query result cache resides in the memory of the leader node and is shared across different user sessions to the same database. The feature is transparent, so it works by default without the need for user configurations. Result caching complies with Amazon Redshift multi-version concurrency control (MVCC). It acquires the proper locks on the table objects and manages the lifecycle of the cache entries when multiple user sessions read/write a table object at the same time. In addition, access control of the cached results is managed so that a user must have the required permission of the objects used in the query to retrieve result rows from the cache.
Which queries are served from the result cache?
Read-only queries are eligible for caching with some exceptions. Query results are not cached in the following circumstances:
- When a query uses a function that must be evaluated each time it is run, such as getdate().
- When a query refers to system tables or views.
- When a query refers to external tables, that is, Amazon Redshift Spectrum tables.
- When a query runs only on the leader node, or the result is too large.
Suppose that your query contains functions like current_date and you want to take advantage of the result cache. You can consider rewriting the query by materializing the value of current_date (for example, in your JDBC application), using the query text, and refreshing it as needed.
To determine which executed queries served results from the cache, a new column source_query has been added to system view SVL_QLOG to record the source query ID when a query is executed from the cache. You can use the following example query to find out which queries used cached results:
For more information about result cache usage, see Result Caching in the Amazon Redshift documentation.
Summary
Amazon Redshift result caching helps ensure that no computing resources are wasted on repeat queries. It enables you to do more analytics in less time to support decision making and improve outcomes. In this post, we explained how Amazon Redshift result caching works and discussed the significant impact for Amazon Redshift customers. Result caching is enabled automatically, and we encourage you to see the difference it can make in your environment.
Additional Reading
If you found this post useful, be sure to check out Amazon Redshift Spectrum Extends Data Warehousing Out to Exabytes—No Loading Required, Collect Data Statistics Up to 5x Faster by Analyzing Only Predicate Columns with Amazon Redshift and Amazon Redshift – 2017 Recap.
About the Authors
 Entong Shen is a software engineer on the Amazon Redshift query processing team. He has been working on MPP databases for over 5 years and has focused on query optimization, statistics and SQL language features. In his spare time, he enjoys listening to music of all genres and working in his succulent garden.
Entong Shen is a software engineer on the Amazon Redshift query processing team. He has been working on MPP databases for over 5 years and has focused on query optimization, statistics and SQL language features. In his spare time, he enjoys listening to music of all genres and working in his succulent garden.
 Larry Heathcote is a Principal Product Marketing Manager at Amazon Web Services for data warehousing and analytics. Larry is passionate about seeing the results of data-driven insights on business outcomes. He enjoys family time, home projects, grilling out and the taste of classic barbeque.
Larry Heathcote is a Principal Product Marketing Manager at Amazon Web Services for data warehousing and analytics. Larry is passionate about seeing the results of data-driven insights on business outcomes. He enjoys family time, home projects, grilling out and the taste of classic barbeque.
 Maor Kleider is a Senior Product Manager for Amazon Redshift, a fast, simple and cost-effective data warehouse. Maor is passionate about collaborating with customers and partners, learning about their unique big data use cases and making their experience even better. In his spare time, Maor enjoys traveling and exploring new restaurants with his family.
Maor Kleider is a Senior Product Manager for Amazon Redshift, a fast, simple and cost-effective data warehouse. Maor is passionate about collaborating with customers and partners, learning about their unique big data use cases and making their experience even better. In his spare time, Maor enjoys traveling and exploring new restaurants with his family.
 Meng Tong is a Senior Software Engineer with Amazon Redshift Query Processing team. His work has been focused on query performance improvements across rewriter, optimizer and executor, Redshift Spectrum, and most recently Redshift Result Caching. His passion lies in discovering simple, elegant solutions for customer needs in big data systems. He is a big Rafael Nadal fan and enjoys watching and playing tennis in his spare time.
Meng Tong is a Senior Software Engineer with Amazon Redshift Query Processing team. His work has been focused on query performance improvements across rewriter, optimizer and executor, Redshift Spectrum, and most recently Redshift Result Caching. His passion lies in discovering simple, elegant solutions for customer needs in big data systems. He is a big Rafael Nadal fan and enjoys watching and playing tennis in his spare time.
 Naresh Chainani is a Senior Software Development Manager at Amazon Redshift where he leads the Query Processing team. Naresh is passionate about building high-performance databases to enable customers to gain timely insights and make critical business decisions. In his spare time, Naresh enjoys reading and playing tennis.
Naresh Chainani is a Senior Software Development Manager at Amazon Redshift where he leads the Query Processing team. Naresh is passionate about building high-performance databases to enable customers to gain timely insights and make critical business decisions. In his spare time, Naresh enjoys reading and playing tennis.