AWS Big Data Blog
How Isentia improves customer experience by modernizing their real-time media monitoring and intelligence platform with Amazon Kinesis Data Analytics for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
This is a blog post co-written by Karl Platz at Isentia. In their own words, “Isentia is the leading media monitoring, intelligence and insights solution provider in Asia Pacific, helping top-performing communication teams make sense of the world’s conversations in real-time.”
Isentia is a publicly listed (ASX:ISD) media monitoring and intelligence company that provides software as a service (SaaS) tools used by thousands of users each day across eight countries in Australia and Southeast Asia. They process data in multiple languages from sources including websites, radio, print, broadcast, blogs, social media, and many others. Their customers range from very large, such as government departments, to small PR agencies. Customers access the Mediaportal platform to view the content of interest to them, generate reports on content across a range of dimensions, and use the analytics capability to delve deeper into topics of interest.
In this post, we discuss how Isentia updated their data processing pipeline with Amazon Kinesis Data Analytics for Apache Flink to replace the previous Apache Storm based pipeline.
Isentia’s SaaS platform has grown over the years, using several popular open-source technologies like Node.js, Python, Elasticsearch, Kubernetes, and Apache Storm for real-time analytics and data enrichment. The challenge for Isentia was two-fold:
- Maintaining a stream processing pipeline with Apache Storm in a self-managed environment was taking a lot of time and effort. There is less community support for Apache Storm, and the team was busy maintaining complex infrastructure instead of focusing on releasing new features on the platform.
- The ever-growing volume of media items particularly from social media and websites was pushing the limits of what the platform was designed to handle. It was time to look for alternatives.
Overview of the old architecture
Isentia has different data processing pipelines for different media item types. For example, one data processing pipeline for processing broadcast media, and another for processing social media items. Broadly, all data processing pipelines have ingestion, enrichment, store and search, and serving layers. In this post, we focus on the enrichment layer, where we used Apache Storm to transform and enrich items before they are published to the store and search layer.
Design goals
Let’s look at the requirements for the enrichment layer solution.
First, the solution had to be a managed offering, which frees up the team to focus on product features and experiment by quickly spinning up another instance of an application or a pipeline. Out-of-the-box integrations with Elasticsearch and several AWS services could help keep maintenance low.
Secondly, we were looking for a solution with greater scalability and observability, so we could ingest and process variable data volumes while gauging the health of the pipelines, see metrics on data volumes processed, and alert or automatically respond when deviations from expected behavior and performance occur. The existing solution wasn’t elastic; it was running overprovisioned and relied on queueing when out of capacity.
Functionally, the new solution had to have at least once processing semantics, so none of the media items ingested get lost in case of a failure. Both parallel processing and sequential processing had to be supported. For example, sentiment and keywords or relevance enrichment steps can be run in parallel, but in the case of video or audio items, transcribing to text has to happen first.
Overview of the new architecture
We chose Apache Flink as a replacement for Apache Storm, due to its out-of-the-box capabilities such as result guarantee, maintaining a large state for stateful stream processing, and complex data processing at very high throughput with low latency. However, Apache Flink is a complex distributed framework, cluster scaling is complex and costly, patch management and software version updates are operationally challenging, and we have a small team to manage our overall infrastructure.
Considering all those challenges, we identified that Kinesis Data Analytics for Apache Flink can satisfy our requirements, and we decided to use this service for our complex real-time processing. We worked closely with AWS Solutions Architects and the Amazon Kinesis Data Analytics service team and found the following:
- Kinesis Data Analytics is a serverless service. It takes care of host degradations, Availability Zone availability, and other infrastructure-related issues by performing automatic migration.
- Each Kinesis Data Analytics application using Apache Flink runs in a single-tenant Apache Flink cluster. The Apache Flink cluster is run with the JobMananger in high availability mode using Zookeeper across multiple Availability Zones. This means we don’t need to spend time maintaining and patching the infrastructure. The serverless nature of the service means there is no downtime associated with a maintenance window.
- The service can scale automatically to match the volume and throughput of incoming data.
- Amazon CloudWatch offers native logging and monitoring for a Flink application, which you can set up to different levels of verbosity (ERROR, WARN, INFO, or DEBUG) to help identify issues quickly in the application development phase.
- Having access to the Apache Flink Dashboard gives greater visibility into our applications and provides advanced monitoring capabilities.
Functionally, Kinesis Data Analytics for Apache Flink provides a choice of at least once or exactly once processing semantics, the ability to process items synchronously and asynchronously, and the ability to run aggregation and analytics on the stream.
The following diagram illustrates the architecture of our solution.
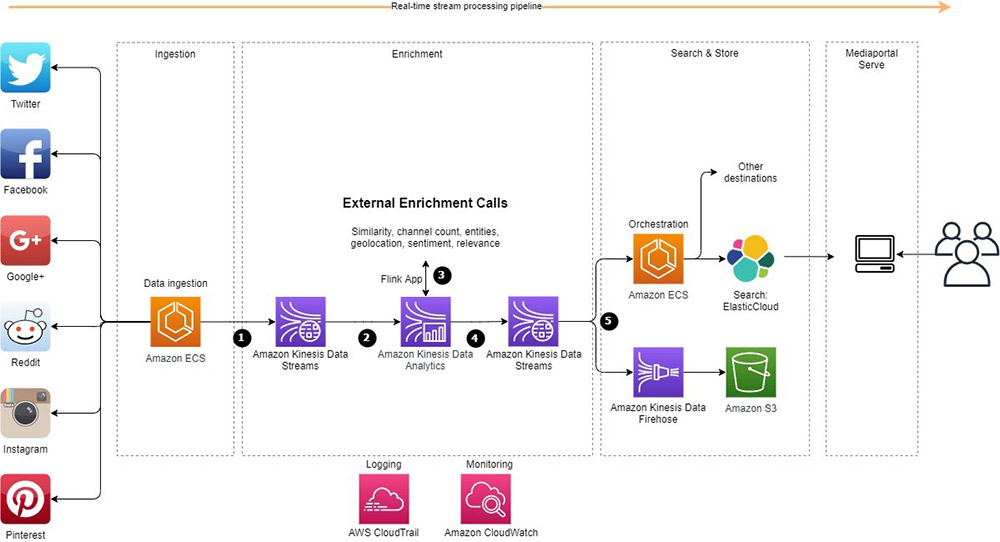
We came up with a use case to implement our first real-time data processing pipeline with Kinesis Data Analytics for Apache Flink to replace our Apache Storm based pipeline. Let’s explain a bit more about the architecture we implemented:
- We have incoming data from different social media sources. An application hosted in Amazon Elastic Container Service (Amazon ECS) collects the social media data, enriches it, and sends it to Amazon Kinesis Data Streams.
- An Apache Flink application hosted in Kinesis Data Analytics consumes the data from the data stream in real time.
- The Flink application makes some external calls and enriches each item with sentiment, geolocation, relevance, and several other dimensions.
- The output containing the enriched items and aggregations is written into another Kinesis data stream for distribution into a variety of data stores for consumptions.
- An application hosted in Amazon ECS reads from the data stream, does some additional enrichment, and sends it to Elasticsearch for consumption via an internet-facing application. Also, an Amazon Kinesis Data Firehose delivery stream consumes data from the output data stream and sends the data to our Amazon Simple Storage Service (Amazon S3) data lake.
Lessons learned
Migrating our core data processing dependency from Apache Storm was a great experience. It took about 2 weeks to port code from Apache Storm to Apache Flink and a few additional weeks to test and iterate it, but not everything went according to the plan. A considerable amount of time was spent doing load testing, identifying bottlenecks, and performance tuning to learn the new platform’s behavior and the configuration that would work best for us while aligning with best practices of Kinesis Data Analytics. Checking the Flink Dashboard and monitoring the following metrics was crucial during our development time:
- millisBehindLatest – How far behind the consumer is, expressed in milliseconds. 0 indicates the record processing is caught up.
- KPU – The number of Kinesis Processing Units (KPUs) that dynamically change when autoscaling is enabled. Enabling autoscaling helped us handle spikes on our stream processing pipeline.
We also took the following actions:
- Kinesis Data Analytics does CPU-based autoscaling by adding more task managers in the Flink cluster to handle spikes, but our processing was heavily bound by network I/O, so we had to parallelize our tasks by changing the ParallelismPerKPU setting instead of changing the application parallelism settings, which is a CPU-based scaling mechanism.
- Flink doesn’t allow checkpoint intervals less than 10 milliseconds, and our application kept failing during the development time. Updating the application checkpoint interval greater than 10 milliseconds helped us solve that issue.
- We rewrote the external API calls made at the enrichment layer as asynchronous calls to take full advantage of parallelism and improve performance. We also made the application fault-tolerant by adding a mechanism to save failed items to Amazon S3 for reprocessing.
- During the development phase, we were logging everything from our Flink application to CloudWatch. We started observing slowness on data processing due to that. Delivering log events via CloudWatch can be treated as an additional application output stream and lead to back-pressure, which puts stress on available system resources. A legacy logging mechanism was removed and the Flink logging level was set from DEBUG back to INFO to improve performance.
- The new pipeline was deployed using AWS CloudFormation templates and run by Bitbucket Pipelines using rolling updates.
Outcomes and benefits
By moving to Kinesis Data Analytics for Apache Flink, Isentia saved time and money that was previously invested in operating a self-managed Apache Storm platform. We now use the out-of-the-box patching, high availability, security, logging, and monitoring that comes with Kinesis Data Analytics for Apache Flink, as well as native integrations with several AWS services. All of these used to be non-trivial tasks that required deep technical Apache Storm skills from the team, and are now handled by automation. This speeds up experiments and shortens the development cycle. Cost, which we didn’t talk much about, now matches the demand, because Kinesis Data Analytics elastically scales up and down with the load (averaging 26 million records per day) and the consumption-based pricing model eliminates the need to pay for idle resources.
As a result, product and development teams can focus on Isentia’s customers and deliver requested features faster. Our roadmap has a stronger focus on customer outcomes and user experience since the removal of items to operate and scale the environments.
Looking ahead
There are a few things that are easily accessible to Isentia on Kinesis Data Analytics for Apache Flink.
One of them is the ability to bring in analytics over a longer window. The retention period of items in Kinesis Data Streams recently increased to 365 days, meaning we can produce monthly analysis without needing additional scaffolding of storing, aggregating, and analyzing items processed that month.
Next, because Kinesis Data Firehose natively integrates with Kinesis Data Streams and Amazon S3, we can use it to store large volumes of data at low cost and have it available for future analytics and ML use cases, which are currently on the longer-term product roadmap.
About the Authors
 Karl Platz is a Chief Architect at Isentia with a focus on cloud technologies and was driving Mediaportal evolution for the last 7 years.
Karl Platz is a Chief Architect at Isentia with a focus on cloud technologies and was driving Mediaportal evolution for the last 7 years.
 Maria Sokolova is a Solutions Architect at Amazon Web Services. She helps enterprise customers modernize legacy systems and accelerates critical projects by providing technical expertise and transformations guidance where they needed the most.
Maria Sokolova is a Solutions Architect at Amazon Web Services. She helps enterprise customers modernize legacy systems and accelerates critical projects by providing technical expertise and transformations guidance where they needed the most.
 Masudur Rahaman Sayem is a Specialist Solution Architect for Analytics at AWS. He works with AWS customers to provide guidance and technical assistance on data and analytics projects, helping them improve the value of their solutions when using AWS. He is passionate about distributed systems. He also likes to read, especially classic comic books.
Masudur Rahaman Sayem is a Specialist Solution Architect for Analytics at AWS. He works with AWS customers to provide guidance and technical assistance on data and analytics projects, helping them improve the value of their solutions when using AWS. He is passionate about distributed systems. He also likes to read, especially classic comic books.