AWS Big Data Blog
Meet Amazon Redshift RG – AWS Graviton-based instances with an integrated data lake query engine delivering up to 2.4x better performance at 30% lower price than RA3
On May 12, 2026, we announced the general availability of Amazon Redshift RG instances, powered by AWS Graviton processors. RG instances are up to 2.2x as fast for data warehouse workloads and up to 2.4x as fast for data lake workloads, all at 30% lower price per vCPU compared to RA3 instances. RG instances support all data lake formats supported by RA3 and eliminate Amazon Redshift Spectrum’s per-TB scanning charges. RG instances feature a custom-built integrated vectorized query engine, making them a more performant and cost-effective foundation for unified analytics.
We are launching with two instance sizes: rg.xlarge and rg.4xlarge, with additional sizes coming later this year.
Why we built this
RG instances bring the power of AWS Graviton processors to Amazon Redshift Provisioned clusters for the first time, paired with a purpose-built vectorized query engine. By combining Graviton’s superior price-performance with the latest Amazon Redshift innovations, RG instances deliver a step-change improvement across two dimensions: significantly lower cost and meaningfully faster performance for both warehouse and data lake workloads using Apache Iceberg and Apache Parquet. We built RG to help you avoid choosing between performance and economics. Graviton costs less to operate, and we’re passing that benefit to you while simultaneously raising the performance bar. Equally important, we designed RG to maintain full feature parity with RA3, so you can modernize your existing clusters without rearchitecting workloads or sacrificing capabilities you depend on today.
This combination is also increasingly critical for agentic artificial intelligence (AI) workloads. AI agents operating at scale generate a new class of analytics demand: high volumes of unique, unpredictable queries that require fast, low-latency responses to keep agents productive. Traditional price-performance ratios make running these workloads at scale cost-prohibitive. RG instances address this head-on. Lower per-vCPU pricing makes sustained high-query volumes economically viable, while improved query performance makes sure agents get answers fast enough to remain effective. Together, this provides the foundation for AI-driven analytics at the scale and economics that agentic workloads demand.
What’s new
RG instances: Better performance, lower cost
RG instances run on AWS Graviton, Amazon’s custom-designed cloud processor built from the ground up to deliver superior price-performance and energy efficiency. This translates directly into RG instances offering more compute cores, higher memory bandwidth, and lower inter-process communication latency compared to RA3, with performance improvements across warehouse, data lake, and mixed workloads.
Graviton costs less to operate, and we’re passing that benefit directly to you. RG instances are priced at a 30% lower cost per vCPU compared to RA3. Reserved Instance pricing follows the same model, making RG Reserved Instances equally 30% less costly than RA3. For pricing details, visit the Amazon Redshift pricing page.
Performance results
RG instances deliver faster, more efficient analytics across your most demanding warehouse and data lake workloads, whether you’re querying structured data in Amazon Redshift Managed Storage (RMS), running analytics over Iceberg tables in Amazon Simple Storage Service (Amazon S3), or processing Parquet files at scale. Iceberg workloads see the most significant gains, delivering up to 2.4x faster query execution. Parquet workloads deliver up to 1.5x faster query execution, and RMS-based data warehouse workloads deliver up to 2.2x faster query execution. All performance improvements are measured using industry-standard TPC-DS and TPC-H benchmarks at 10 TB scale on rg.4xlarge instances.
When combined with RG’s 30% lower per-vCPU pricing compared to RA3, these performance gains translate to even greater price-performance improvements, delivering more analytics value for every dollar spent.
Built-in data lake query engine – no more Spectrum charges
With RA3, data lake queries were offloaded to a separate fleet of nodes called Amazon Redshift Spectrum, scanning data externally and returning results back to the cluster. This architecture introduced network overhead, added latency, and imposed a $5/TB scanning charge on every query. RG instances change this fundamentally with a custom-built vectorized data lake engine running directly inside the cluster, eliminating Spectrum scanning charges.
The purpose-built vectorized engine includes a highly optimized scan layer that implements the latest data pruning techniques, a purpose-built I/O subsystem, and a range of optimizations that use Graviton’s processing capabilities to make scanning Iceberg and Parquet data highly efficient. Beyond raw scan performance, the engine introduces JIT ANALYZE, a capability that automatically collects and uses statistics for data lake tables during query execution. This eliminates the need for manual statistics collection. The system uses intelligent heuristics to identify queries that will benefit from statistics, maintains lightweight sketch data structures, and builds high-quality table-level and column-level statistics, all transparently. Having up-to-date statistics on data lake tables can deliver orders-of-magnitude improvements in query performance, and with JIT ANALYZE, you get this benefit automatically without operational overhead.
What customers are saying
Sean Lynch, Vice President, Data and Architecture, Southwest Airlines:
“Amazon Redshift RG instances have the potential to deliver meaningful business impact for Southwest Airlines. Based on initial testing in our development environment, our data warehouse workloads run 50-60% faster, and data lake analytics are 45% faster, enabling teams to get insights sooner, respond to operational conditions faster, and make data-driven decisions with less latency. These early results are encouraging, and we are excited to validate and scale these improvements in production. All of this comes without per-terabyte Spectrum scanning charges, delivering 30% lower cost than RA3 at a time when fuel prices continue to pressure industry margins.”
Akshay Srinivasan, Data Engineer, tombola:
“The new Graviton-based Amazon Redshift RG instances delivered 1.8x-2x faster write throughput and up to 2.2x faster read speeds compared to RA3 across a diverse set of batch and analytical jobs, enabling us to process 40% more within the same window. Compressed ETL cycles, accelerated time-to-insight, and decision-making no longer bottlenecked by the pipeline. Together, these translated directly into fresher data reaching our analysts and business teams sooner. What made this even more compelling was a concurrent 30% reduction in compute spend alongside the gains. Delivering more for less is a rare outcome, and one worth highlighting. In a volume-heavy gaming industry at tombola, where query latency and cost compound at scale, this has been one of the more impactful platform decisions we’ve made this year.”
Modernizing your workloads to RG
Today, we are launching rg.xlarge and rg.4xlarge instance sizes, available now for you to modernize your existing Amazon Redshift provisioned workloads. RG instances support three migration paths, all accessible directly from the AWS Management Console:
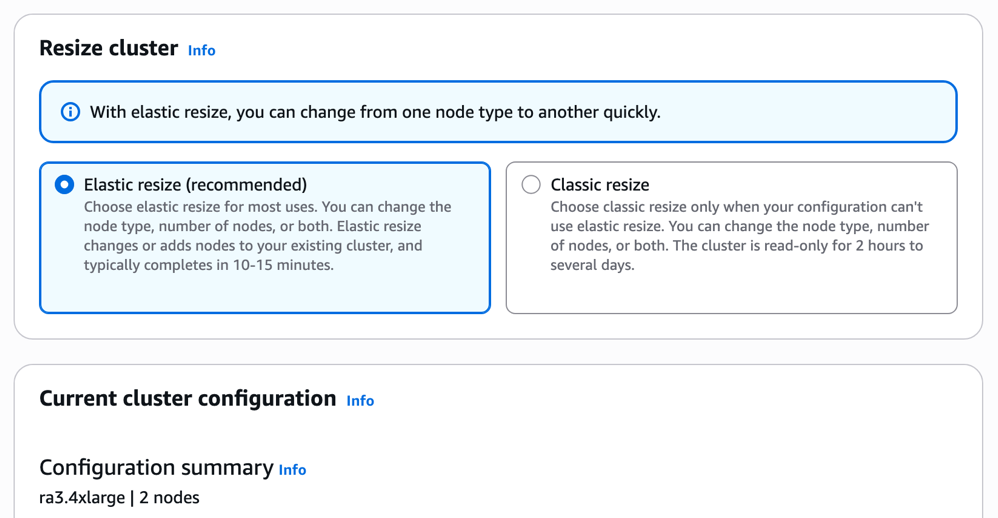
- Elastic Resize (recommended): The fastest path for most customers migrating from RA3 or DC2, with only 10-15 minutes of downtime.
- Snapshot & Restore: Best for you if you need to make configuration changes as part of your migration.
- Classic Resize: Available for workloads that require a full cluster rebuild.
Before migrating your production workloads, we strongly recommend validating your queries and workloads on RG instances first. We’ve published an Upgrade Guide to help you right-size your cluster and plan your migration with confidence.
Getting started
You can start using the RG instances (rg.xlarge and rg.4xlarge) today in the following AWS Regions: US East (N. Virginia), US East (Ohio), US West (Oregon), US West (N. California), Canada (Central), South America (São Paulo), Europe (Ireland), Europe (Frankfurt), Europe (London), Europe (Paris), Europe (Stockholm), Europe (Milan), Europe (Spain), Asia Pacific (Tokyo), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Mumbai), Asia Pacific (Jakarta), Asia Pacific (Hong Kong), Asia Pacific (Osaka), Asia Pacific (Malaysia), Asia Pacific (Hyderabad), Asia Pacific (Taipei), and Asia Pacific (Melbourne).
You can launch new clusters or migrate existing clusters through the AWS Management Console, AWS Command Line Interface (AWS CLI), or AWS API.
To create a new RG cluster in the Amazon Redshift console
- Review the Cluster and Nodes in the Amazon Redshift documentation.
- Choose Amazon Redshift on the AWS Management Console and choose Create Cluster.
- In the Create Cluster screen, choose the required RG node type.
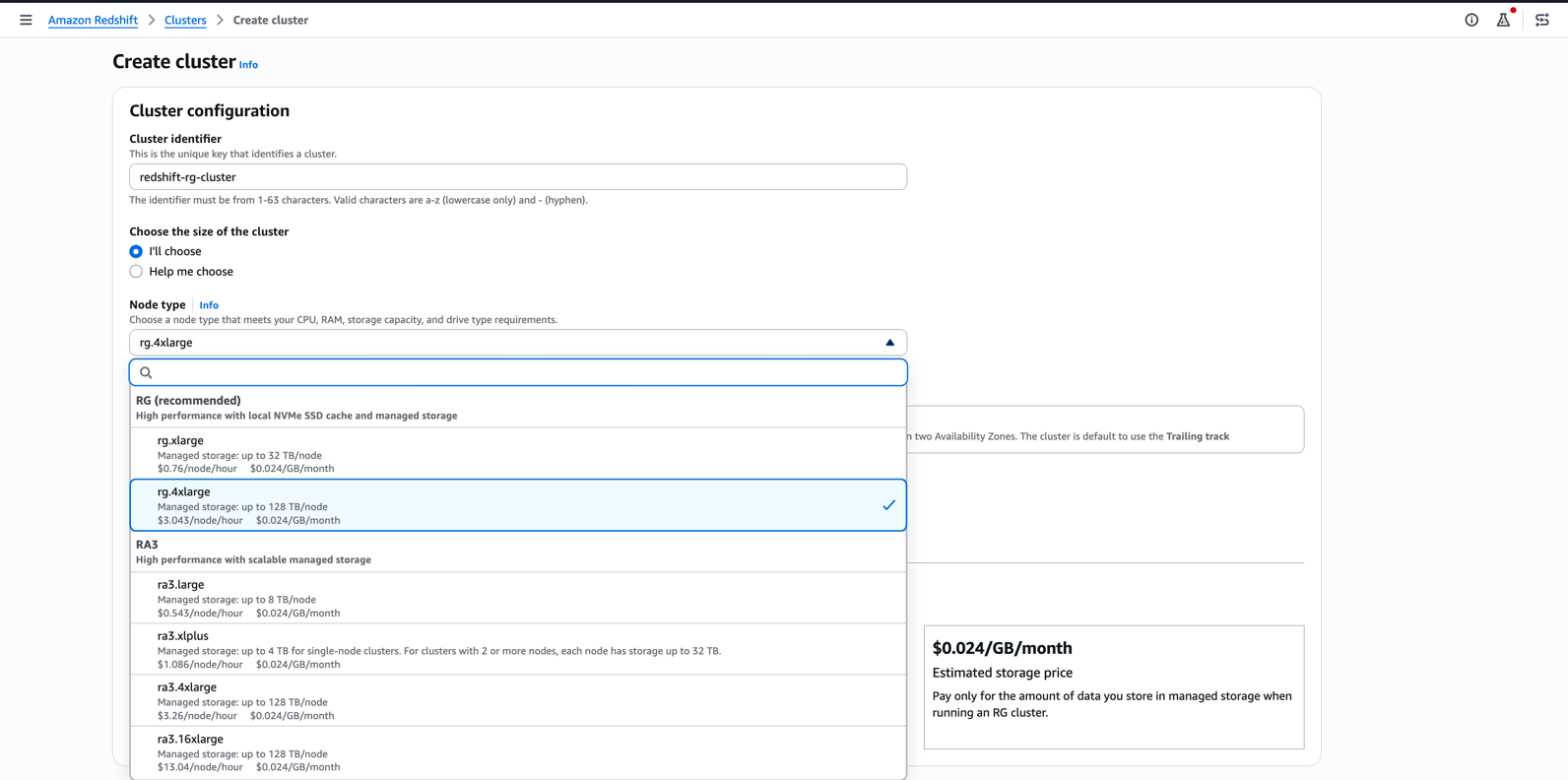
To modernize from RA3 or DC2 in the Amazon Redshift console
- Review the Upgrade Guide in the Amazon Redshift documentation.
- Choose your migration path. Elastic Resize is the right starting point for most customers.
- Choose the required RG node type.
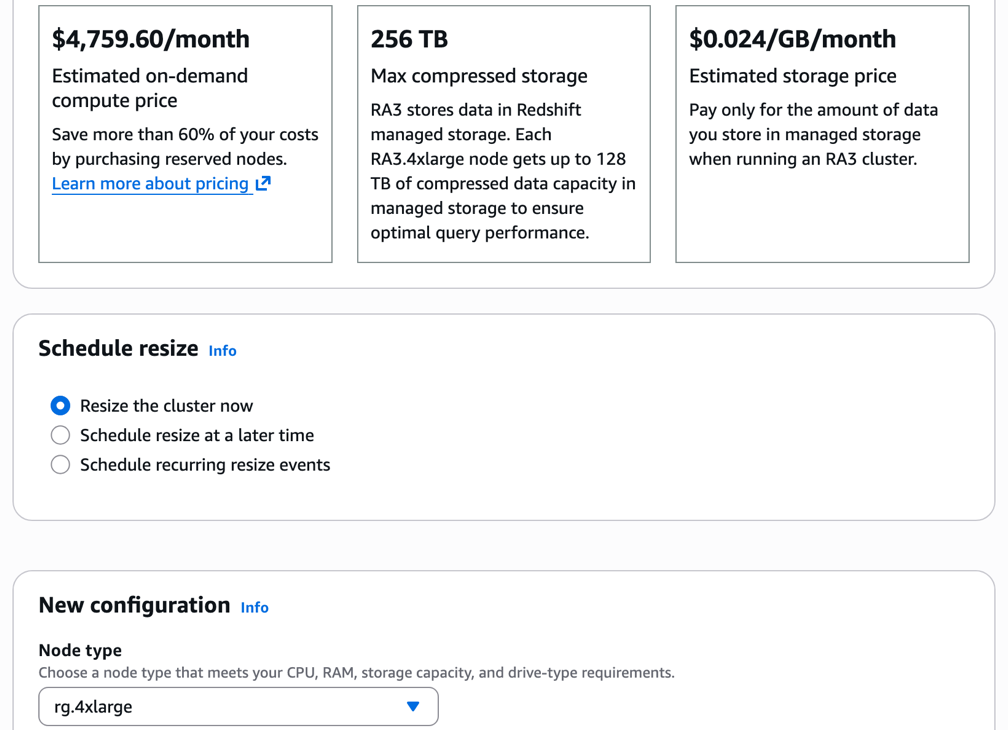
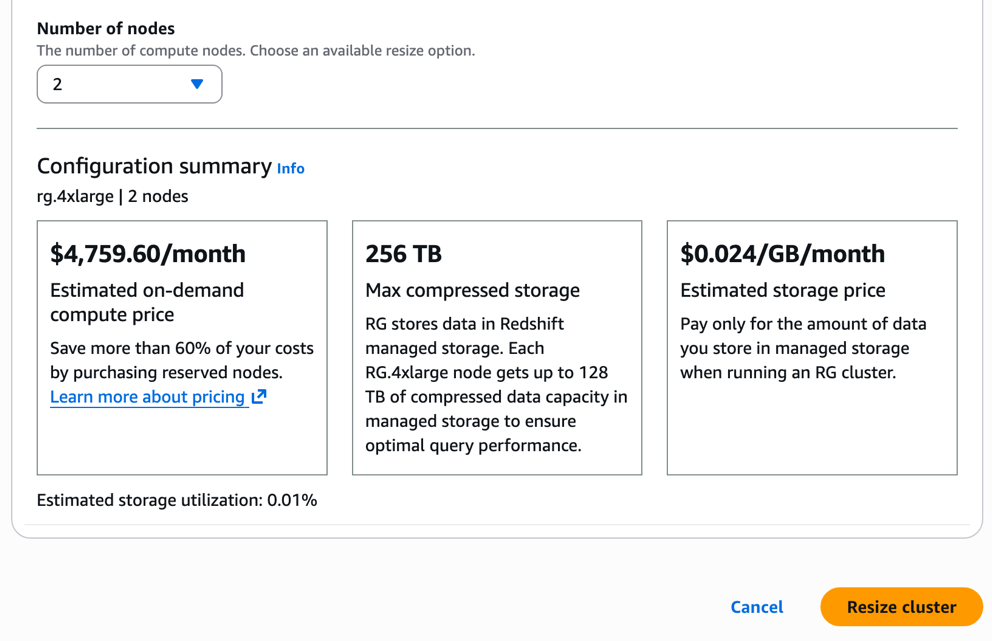
For pricing details, visit the Amazon Redshift pricing page.
Clean up
If you are evaluating RG instances in a test or development environment and do not wish to continue, you can delete your RG cluster directly from the AWS Management Console or by using the AWS CLI to avoid incurring additional charges. If you used Snapshot & Restore to create a test RG cluster alongside your existing RA3 cluster, make sure you delete the RG cluster and any associated snapshots you no longer need. If you are using Data Sharing during migration, remember to remove data shares and decommission your RA3 cluster after you have fully validated your workloads on RG.
Conclusion
Amazon Redshift RG instances represent a significant step forward for you if you run data warehouse and data lake workloads on AWS. By bringing AWS Graviton processors to Amazon Redshift Provisioned clusters for the first time, paired with a purpose-built vectorized native data lake engine, RG instances deliver up to 2.4x better performance on Iceberg workloads, up to 1.5x on Parquet, and up to 2.2x on RMS data warehouse workloads, all at 30% lower per-vCPU cost than RA3. The elimination of Amazon Redshift Spectrum scanning charges makes data lake query costs predictable for the first time.
To get started with RG instances, visit the Amazon Redshift RG documentation to assess your workload and plan your migration.
Resources
- Amazon Redshift RG Instance Documentation.
- Upgrade Guide.
- Amazon Redshift Pricing.
- AWS re:Post – Amazon Redshift Community.
Questions or feedback? Drop a comment or join the discussion on AWS re:Post.