AWS Big Data Blog
Real-time inference using deep learning within Amazon Managed Service for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
Apache Flink is a framework and distributed processing engine for stateful computations over data streams. Amazon Managed Service for Apache Flink is a fully managed service that enables you to use an Apache Flink application to process streaming data. The Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning.
In this blog post, we demonstrate how you can use DJL within Amazon Managed Service for Apache Flink for real-time machine learning inference. Real-time inference can be valuable in a variety of applications and industries where it is essential to make predictions or take actions based on new data as quickly as possible with low latencies. We show how to load a pre-trained deep learning model from the DJL model zoo into a Flink job and apply the model to classify data objects in a continuous data stream. The DJL model zoo includes a wide variety of pre-trained models for image classification, semantic segmentation, speech recognition, text embedding generation, question answering, and more. It supports HuggingFace, Pytorch, MXNet, and TensorFlow model frameworks and also helps developers create and publish their own models. We will focus on image classification and use a popular classifier called ResNet-18 to produce predictions in real time. The model has been pre-trained on ImageNet with 1.2 million images belonging to 1,000 class labels.
We provide sample code, architecture diagrams, and an AWS CloudFormation template so you can follow along and employ ResNet-18 as your classifier to make real-time predictions. The solution we provide here is a powerful design pattern for continuously producing ML-based predictions on streaming data within Amazon Managed Service for Apache Flink. You can adapt the provided solution for your use case and choose an alternative model from the model zoo or even provide your own model.
Image classification is a classic problem that takes an image and selects the best-fitting class, such as whether the image from an autonomous driving system is that of a bicycle or a pedestrian. Common use cases for real-time inference on streams of images include classifying images from vehicle cameras and license plate recognition systems, and classifying images uploaded to social media and ecommerce websites. The use cases typically need low latency while handling high throughput and potentially bursty streams. For example, in ecommerce websites, real-time classification of uploaded images can help in marking pictures of banned goods or hazardous materials that have been supplied by sellers. Immediate determination through streaming inference is needed to trigger alerts and follow-up actions to prevent these images from being part of the catalog. This enables faster decision-making compared to batch jobs that run on a periodic basis. The data stream pipeline can involve multiple models for different purposes, such as classifying uploaded images into ecommerce categories of electronics, toys, fashion, and so on.
Solution overview
The following diagram illustrates the workflow of our solution.

The application performs the following steps:
- Read in images from Amazon Simple Storage Service (Amazon S3) using the Apache Flink Filesystem File Source connector.
- Window the images into a collection of records.
- Classify the batches of images using the DJL image classification class.
- Write inference results to Amazon S3 at the path specified.
Images are recommended to be of reasonable size so that they may fit into a Kinesis Processing Unit. Images larger than 50MB in size may result in latency in processing and classification.
The main class for this Apache Flink job is located at src/main/java/com.amazon.embeddedmodelinference/EMI.java. Here you can find the main() method and entry point to our Flink job.
Prerequisites
To get started, configure the following prerequisites on your local machine:
- Java 11 installed for local development of Apache Flink applications
- Maven downloaded and installed for packaging of Apache Flink applications
- Apache Flink set up on IntelliJ IDE on your local machine
Once this is set up, you can clone the code base to access the source code for this solution. The Java application code for this example is available on GitHub. To download the application code, clone the remote repository using the following command:
Find and navigate to the folder of the image classification example, called image-classification.
An example set of images to stream and test the code is available in the imagenet-sample-images folder.
Let’s walk through the code step by step.
Test on your local machine
If you would like to test this application locally on your machine, ensure you have AWS credentials set up locally on your machine. Additionally, download the Flink S3 Filesystem Hadoop JAR to use with your Apache Flink installation and place it in a folder named plugins/s3 in the root of your project. Then configure the following environment variables either on your IDE or in your machine’s local variable scope:
Replace these values with your own.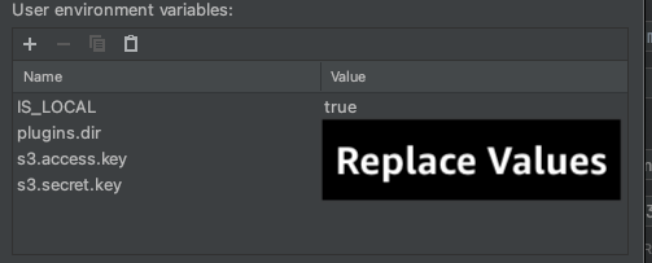
After configuring the environment variables and downloading the necessary plugin JAR, let’s look at the code.
In the main method, after setting up our StreamExecutionEnvironment, we define our FileSource to read files from Amazon S3. By default, this source operator reads from a sample bucket. You can replace this bucket name with your own by changing the variable called bucket, or setting the application property on Amazon Managed Service for Apache Flink once deployed.
The FileSource is configured to read in files in the ImageReaderFormat, and will check Amazon S3 for new images every 10 seconds. This can be configured as well.
After we have read in our images, we convert our FileSource into a stream that can be processed:
Next, we create a tumbling window of a variable time window duration, specified in the configuration, defaulting to 60 seconds. Every window close creates a batch (list) of images to be classified using a ProcessWindowFunction.
This ProcessWindowFunction calls the classifier predict function on the list of images and returns the best probability of classification from each image. This result is then sent back to the Flink operator, where it’s promptly written out to the S3 bucket path of your configuration.
In Classifier.java, we read the image and apply crop, transpose, reshape, and finally convert to an N-dimensional array that can be processed by the deep learning model. Then we feed the array to the model and apply a forward pass. During the forward pass, the model computes the neural network layer by layer. At last, the output object contains the probabilities for each image object that the model is being trained on. We map the probabilities with the object name and return to the map function.
Deploy the solution with AWS CloudFormation
To run this code base on Amazon Managed Service for Apache Flink, we have a helpful CloudFormation template that will spin up the necessary resources. Simply open AWS CloudShell or your local machine’s terminal and enter the following commands. Complete the following steps to deploy the solution:
- If you don’t have the AWS Cloud Development Kit (AWS CDK) bootstrapped in your account, run the following command, providing your account number and current Region:
The script will clone a GitHub repo of images to classify and upload them to your source S3 bucket. Then it will launch the CloudFormation stack given your input parameters. 
- Enter the following code and replace the BUCKET variables with your own source bucket and sink bucket, which will contain the source images and the classifications, respectively:
This CloudFormation stack creates the following resources:
-
- An Amazon Managed Service for Apache Flink application with 1 Kinesis Processing Unit (KPU) preconfigured with some application properties
-
- An S3 bucket for your output results
-
- AWS Identity and Access Management (IAM) roles for the communication between the two services
- When the stack is complete, navigate to the Amazon Managed Service for Apache Flink console.
- Find the application called
blog-DJL-flink-ImageClassification-applicationand choose Run. - On the Amazon S3 console, navigate to the bucket you specified in the
outputBucketPathvariable.
If you have readable images in the source bucket listed, you should see classifications of those images within the checkpoint interval of the running application.
Deploy the solution manually
If you prefer to use your own code base, you can follow the manual steps in this section:
- After you clone the application locally, create your application JAR by navigating to the directory that contains your
pom.xmland running the following command:
This builds your application JAR in the target/ directory called embedded-model-inference-1.0-SNAPSHOT.jar.
- Upload this application JAR to an S3 bucket, either the one created from the CloudFormation template, or another one to store code artifacts.
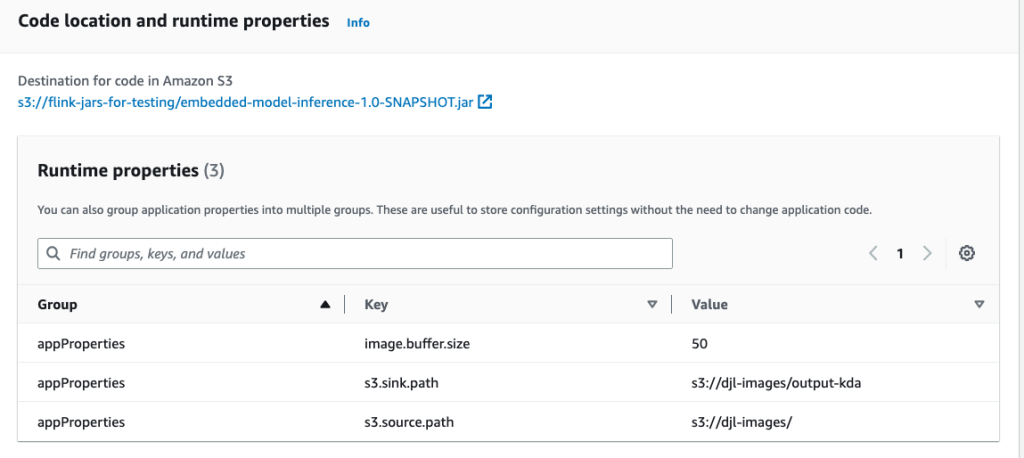
- You can then configure your Amazon Managed Service for Apache Flink application to point to this newly uploaded S3 JAR file.
- This is also a great opportunity to configure your runtime properties, as shown in the following screenshot.
- Choose Run to start your application.
You can open the Apache Flink Dashboard to check for application exceptions or to see data flowing through the tasks defined in the code.

Validate the results
To validate our results, let’s check the results in Amazon S3 by navigating to the Amazon S3 console and finding our S3 bucket. We can find the output in a folder called output-kda.

When we choose one of the data-partitioned folders, we can see partition files. Ensure that there is no underscore in front of your part file, because this indicates that the results are still being finalized according to the rollover interval defined in Apache Flink’s FileSink connector. After the underscores have disappeared, we can use Amazon S3 Select to view our data.

We now have a solution that continuously performs classification on incoming images in real time using Amazon Managed Service for Apache Flink. It extracts a pre-trained classification model (ResNet-18) from the DJL model zoo, applies some preprocessing, loads the model into a Flink operator’s memory, and continuously applies the model for online predictions on streaming images.
Although we used ResNet-18 in this post, you can choose another model by modifying the classifier. The DJL model zoo provides many other models, both for classification and other applications, that can be used out of the box. You can also load your custom model by providing an S3 link or URL to the criteria. DJL supports models in a large number of engines such as PyTorch, ONNX, TensorFlow, and MXNet. Using a model in the solution is relatively simple. All of the preprocessing and postprocessing code is encapsulated in the (built-in) translator, so all we have to do is load the model, create a predictor, and call predict(). This is done within the data source operator, which processes the stream of input data and sends the links to the data to the inference operator where the model you selected produces the prediction. Then the sink operator writes the results.
The CloudFormation template in this example focused on a simple 1 KPU application. You could extend the solution to further scale out to large models and high-throughput streams, and support multiple models within the pipeline.
Clean up
To clean up the CloudFormation script you launched, complete the following steps:
- Empty the source bucket you specified in the bash script.
- On the AWS CloudFormation console, locate the CloudFormation template called
KDAImageClassification. - Delete the stack, which will remove all of the remaining resources created for this post.
- You may optionally delete the bootstrapping CloudFormation template,
CDKToolkit, which you launched earlier as well.
Conclusion
In this post, we presented a solution for real-time classification using the Deep Java Library within Amazon Managed Service for Apache Flink. We shared a working example and discussed how you can adapt the solution for your specific ML use case. If you have any feedback or questions, please leave them in the comments section.
About the Authors
 Jeremy Ber has been working in the telemetry data space for the past 9 years as a Software Engineer, Machine Learning Engineer, and most recently a Data Engineer. At AWS, he is a Streaming Specialist Solutions Architect, supporting both Amazon Managed Streaming for Apache Kafka (Amazon MSK) and AWS’s managed offering for Apache Flink.
Jeremy Ber has been working in the telemetry data space for the past 9 years as a Software Engineer, Machine Learning Engineer, and most recently a Data Engineer. At AWS, he is a Streaming Specialist Solutions Architect, supporting both Amazon Managed Streaming for Apache Kafka (Amazon MSK) and AWS’s managed offering for Apache Flink.
 Deepthi Mohan is a Principal Product Manager for Amazon Kinesis Data Analytics, AWS’s managed offering for Apache Flink.
Deepthi Mohan is a Principal Product Manager for Amazon Kinesis Data Analytics, AWS’s managed offering for Apache Flink.
 Gaurav Rele is a Data Scientist at the Amazon ML Solution Lab, where he works with AWS customers across different verticals to accelerate their use of machine learning and AWS Cloud services to solve their business challenges.
Gaurav Rele is a Data Scientist at the Amazon ML Solution Lab, where he works with AWS customers across different verticals to accelerate their use of machine learning and AWS Cloud services to solve their business challenges.