AWS Big Data Blog
Run Apache Hive workloads using Spark SQL with Amazon EMR on EKS
Apache Hive is a distributed, fault-tolerant data warehouse system that enables analytics at a massive scale. Using Spark SQL to run Hive workloads provides not only the simplicity of SQL-like queries but also taps into the exceptional speed and performance provided by Spark. Spark SQL is an Apache Spark module for structured data processing. One of its most popular use cases is to read and write Hive tables with connectivity to a persistent Hive metastore, supporting Hive SerDes and user-defined functions.
Starting from version 1.2.0, Apache Spark has supported queries written in HiveQL. HiveQL is a SQL-like language that produces data queries containing business logic, which can be converted to Spark jobs. However, this feature is only supported by YARN or standalone Spark mode. To run HiveQL-based data workloads with Spark on Kubernetes mode, engineers must embed their SQL queries into programmatic code such as PySpark, which requires additional effort to manually change code.
Amazon EMR on Amazon EKS provides a deployment option for Amazon EMR that you can use to run open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS).
Amazon EMR on EKS release 6.7.0 and later include the ability to run SparkSQL through the StartJobRun API. As a result of this enhancement, customers will now be able to supply SQL entry-point files and run HiveQL queries as Spark jobs on EMR on EKS directly. The feature is available in all AWS Regions where EMR on EKS is available.
Use case
FINRA is one of the largest Amazon EMR customers that is running SQL-based workloads using the Hive on Spark approach. FINRA, Financial Industry Regulatory Authority, is a private sector regulator responsible for analyzing equities and option trading activity in the US. To look for fraud, market manipulation, insider trading, and abuse, FINRA’s technology group has developed a robust set of big data tools in the AWS Cloud to support these activities.
FINRA centralizes all its data in Amazon Simple Storage Service (Amazon S3) with a remote Hive metastore on Amazon Relational Database Service (Amazon RDS) to manage their metadata information. They use various AWS analytics services, such as Amazon EMR, to enable their analysts and data scientists to apply advanced analytics techniques to interactively develop and test new surveillance patterns and improve investor protection. To make these interactions more efficient and productive, FINRA modernized their hive workloads in Amazon EMR from its legacy Hive on MapReduce to Hive on Spark, which resulted in query performance gains between 50 and 80 percent.
Going forward, FINRA wants to further innovate the interactive big data platform by moving from a monolithic design pattern to a job-centric paradigm, so that it can fulfill future capacity requirements as its business grows. The capability of running Hive workloads using SparkSQL directly with EMR on EKS is one of the key enablers that helps FINRA continuously pursue that goal.
Additionally, EMR on EKS offers the following benefits to accelerate adoption:
- Fine-grained access controls (IRSA) that are job-centric to harden customers’ security posture
- Minimized adoption effort as it enables direct Hive query submission as a Spark job without code changes
- Reduced run costs by consolidating multiple software versions for Hive or Spark, unifying artificial intelligence and machine learning (AI/ML) and exchange, transform, and load (ETL) pipelines into a single environment
- Simplified cluster management through multi-Availability Zone support and highly responsive autoscaling and provisioning
- Reduced operational overhead by hosting multiple compute and storage types or CPU architectures (x86 & Arm64) in a single configuration
- Increased application reusability and portability supported by custom docker images, which allows them to encapsulate all necessary dependencies
Running Hive SQL queries on EMR on EKS
Prerequisites
Make sure that you have AWS Command Line Interface (AWS CLI) version 1.25.70 or later installed. If you’re running AWS CLI version 2, you need version 2.7.31 or later. Use the following command to check your AWS CLI version:
If necessary, install or update the latest version of the AWS CLI.
Solution Overview
To get started, let’s look at the following diagram. It illustrates a high-level architectural design and different services that can be used in the Hive workload. To match with FINRA’s use case, we chose an Amazon RDS database as the remote Hive metastore. Alternatively, you can use AWS Glue Data Catalog as the metastore for Hive if needed. For more details, see the aws-sample github project. 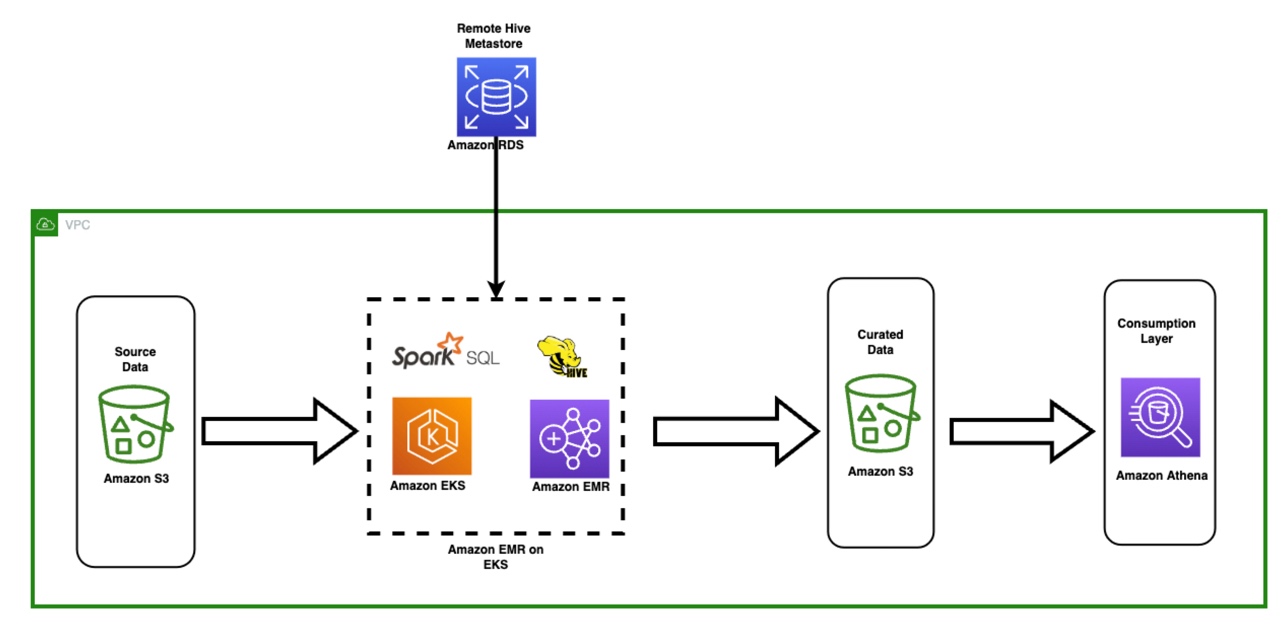
The minimum required infrastructure is:
- An S3 bucket to store a Hive SQL script file
- An Amazon EKS cluster with EMR on EKS enabled
- An Amazon RDS for MySQL database in the same virtual private cloud (VPC) as the Amazon EKS cluster
- A standalone Hive metastore service (HMS) running on the EKS cluster or a small Amazon EMR on EC2 cluster with the Hive application installed
To have a quick start, run the sample CloudFormation deployment. The infrastructure deployment includes the following resources:

Create a Hive script file
Store a few lines of Hive queries in a single file, then upload the file to your S3 bucket, which can be found in your AWS Management Console in the AWS CloudFormation Outputs tab. Search for the key value of CODEBUCKET as shown in preceding screenshot. For a quick start, you can skip this step and use the sample file stored in s3://<YOUR_S3BUCKET>/app_code/job/set-of-hive-queries.sql. The following is a code snippet from the sample file :
Submit the Hive script to EMR on EKS
First, set up the required environment variables. See the shell script post-deployment.sh:
Connect to the demo EKS cluster:
Ensure the entryPoint path is correct, then submit the set-of-hive-queries.sql to EMR on EKS.
Note that the shell script referenced the set-of-hive-queries.sql Hive script file as an entry point script. It uses the sparkSqlJobDriver attribute, not the usual sparkSubmitJobDriver designed for Spark applications. In the sparkSqlParameters section, we pass in two environment variables S3Bucket and key_ID to the Hive script.
The property "spark.hive.metastore.uris": "thrift://hive-metastore:9083" sets a connection to a Hive Metastore Service (HMS) called hive-metastore, which is running as a Kubernetes service on the demo EKS cluster as shown in the follow screenshot. If you’re running the thrift service on Amazon EMR on EC2, the URI should be thrift://<YOUR_EMR_MASTER_NODE_DNS_NAME>:9083. If you chose AWS Glue Data Catalog as your Hive metastore, replace the entire property with "spark.hadoop.hive.metastore.client.factory.class": "com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory".
Finally, check the job status using the kubectl command line tool: kubectl get po -n emr --watch

Expected output
- Go to the Amazon EMR console.
- Navigate to the side menu Virtual clusters, then select the HiveDemo cluster, You can see an entry for the SparkSQL test job.

- Click Spark UI hyperlink to monitor each query’s duration and status on a web interface.

- To query the Amazon RDS based Hive metastore, you need a MYSQL client tool installed. To make it easier, the sample CloudFormation template has installed the query tool on master node of a small Amazon EMR on EC2 cluster.
- Find the EMR master node by running the following command:

- Go to the Amazon EC2 console and connect to the master node through the Session Manager.

- Before querying the MySQL RDS database (the Hive metastore), run the following commands on your local machine to get the credentials:
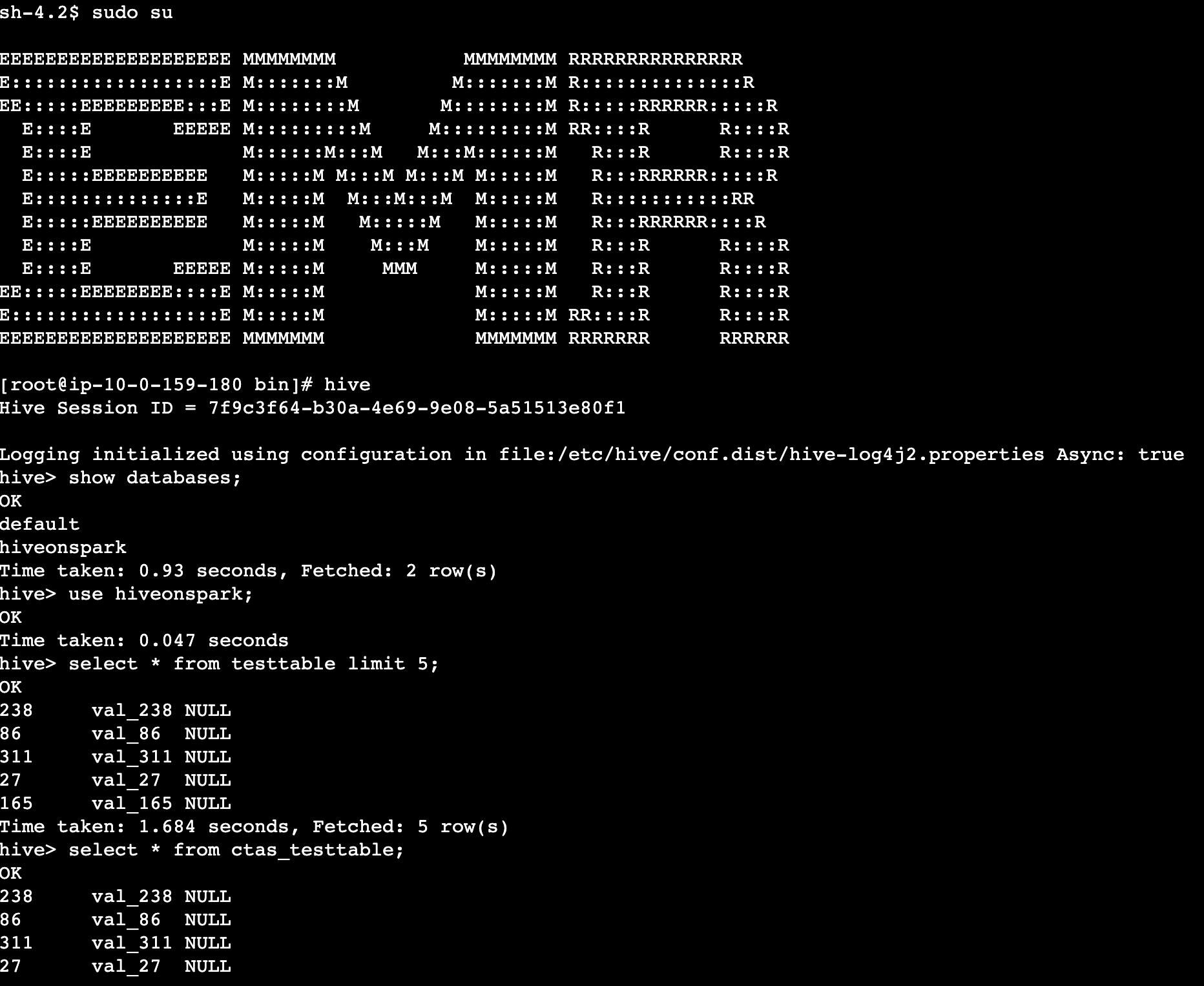
- After connected through Session Manager, query the Hive metastore from your Amazon EMR master node.

- Validate the Hive tables (created by
set-of-hive-queries.sql) through the interactive Hive CLI tool.
Note:-Your query environment must have the Hive Client tool installed and a connection to your Hive metastore or AWS Glue Data Catalog. For the testing purpose, you can connect to the same Amazon EMR on EC2 master node and query your Hive tables. The EMR cluster has been pre-configured with the required setups.
Clean up
To avoid incurring future charges, delete the resources generated if you don’t need the solution anymore. Run the following cleanup script.
Go to the CloudFormation console and manually delete the remaining resources if needed.
Conclusion
Amazon EMR on EKS releases 6.7.0 and higher include a Spark SQL job driver so that you can directly run Spark SQL scripts via the StartJobRun API. Without any modifications to your existing Hive scripts, you can directly execute them as a SparkSQL job on Amazon EMR on EKS.
FINRA is one of the largest Amazon EMR customers. It runs over 400 Hive clusters for its analysts who need to interactively query multi-petabyte data sets. Modernizing its Hive workloads with SparkSQL gives FINRA a 50 to 80 percent query performance improvement. The support to run Spark SQL through the StartJobRun API in EMR on EKS has further enabled FINRA’s innovation in data analytics.
In this post, we demonstrated how to submit a Hive script to Amazon EMR on EKS and run it as a SparkSQL job. We encourage you to give it a try and are keen to hear your feedback and suggestions.
About the authors
 Amit Maindola is a Senior Data Architect focused on big data and analytics at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.
Amit Maindola is a Senior Data Architect focused on big data and analytics at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.
 Melody Yang is a Senior Big Data Solutions Architect for Amazon EMR at AWS. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering, and DataOps.
Melody Yang is a Senior Big Data Solutions Architect for Amazon EMR at AWS. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering, and DataOps.