AWS Big Data Blog
Scale analytics with Amazon Redshift multi-warehouse enhancements
Onboard analytics workloads at scale with Amazon Redshift’s improved remote table data definition language (DDL), materialized view improvements, and concurrency scaling enhancements for zero-ETL and auto-copy.
As organizations scale their analytics capabilities, they need the ability to add workloads without disrupting production operation or being constrained by the resources of a single data warehouse. In this post, we introduce new capabilities of Amazon Redshift that enhance our multi-warehouse and scaling capabilities: remote materialized view (MV) operations, remote table DDL support, and concurrency scaling enhancements for zero-ETL and S3 event integration. These features help you build more scalable, performant decentralized analytics architectures on Amazon Redshift.
Let us review how these new features enable you to run analytics at scale.
New remote materialized view operations
- Amazon Redshift now classifies CREATE MATERIALIZED VIEW as a user workload, enabling concurrency scaling to execute MV logic on additional warehouses during resource contention. This ensures queries consistently benefit from MV performance advantages, even under heavy load.
- Amazon Redshift now supports creating MVs on remote data shares, allowing customers who share data across Redshift warehouses to leverage MV performance benefits on both local and shared data.
- Consumer warehouses can now refresh MVs created on a producer and create MVs on top of data-shared MVs, enabling full MV parity across producer and consumer warehouses in a data sharing architecture.
New remote table DDL operations
ALTER TABLE ALTER DISTSTYLEoperations now work on remote warehouses through concurrency scaling and data sharing. You can dynamically optimize data distribution across distributed environments, improving query performance and resource utilization without requiring data migration. This is especially valuable for data engineers fine-tuning performance across multiple warehouses and administrators adapting to changing query patterns.ALTER TABLE APPENDoperations now extend to remote warehouses through concurrency scaling and data sharing. This consolidates data across distributed environments, so you can efficiently combine tables without complex data movement or extract, transform, and load (ETL) processes. Organizations managing dynamic table operations across multiple environments can maintain data consistency while reducing operational overhead.
Concurrency scaling improvements
- Amazon Redshift’s enhanced zero-ETL feature now supports concurrency scaling for automated data ingestion from applications and operational sources.
- Amazon Redshift’s enhanced auto-copy feature now supports concurrency scaling for automated data ingestion from S3.
- Amazon Redshift now extends concurrency scaling to support COPY queries from Amazon S3. You can now scale data ingestion automatically with concurrency scaling for batch workloads.
With these new concurrency scaling capabilities, you can maintain consistent data freshness without compromising existing warehouse performance. This eliminates the traditional trade-off between analytics and data loading. Apart from turning on concurrency scaling, no additional changes are required to take advantage of these features.
Customer use cases
This section covers two industry use cases: the first for a financial services customer and the second for a gaming industry customer.
Financial services use case
The following is a sample architecture for a large financial services customer with global operations. This customer uses a multi-warehouse architecture built on Amazon Redshift.
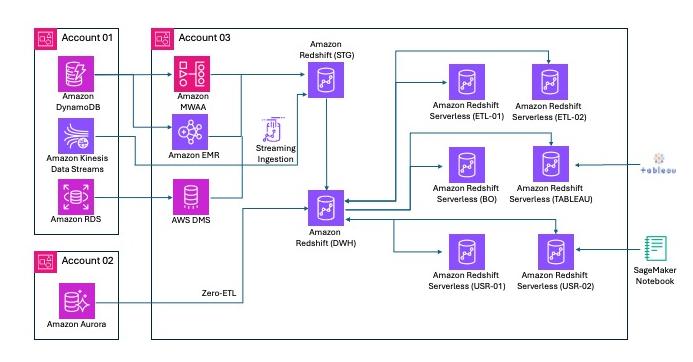
The staging (STG) warehouse serves as a raw zone for data from various sources, like the bronze layer of a medallion architecture. This warehouse also cleanses and standardizes the raw data to the silver layer and makes it available for further processing. The STG warehouse uses MVs to process millions of nested JSON messages and extract attributes into scalar columnar Amazon Redshift tables.
The DWH warehouse serves as the primary Amazon Redshift instance and gold layer, providing data to consuming applications like Business Objects and Tableau. The zero-ETL concurrency scaling improvements provide consistent data freshness even when zero-ETL ingestion spikes occur alongside heavy DWH workloads. The DWH MVs provide fast access to aggregated data for Tableau extracts and Business Objects live reports. The DWH warehouse takes advantage of concurrency scaling when multiple MVs need to be refreshed on the DWH instance.
The ETL01/02 warehouses serve as dedicated compute environments for running project-specific ETL jobs, while the USR01/02 warehouses handle user workloads such as ad-hoc analysis or model building from dbt. When new objects are required by user workloads, they are created and maintained on the remote producer warehouse (DWH).
Gaming industry use case
A leading gaming company has built their entire analytics infrastructure on AWS, with their analytics team managing data streaming from games, data warehousing, and business intelligence tools. They standardized Amazon Redshift across the organization, migrating off Vertica running on Amazon Elastic Compute Cloud (Amazon EC2). After overcoming early challenges with cluster resize operations, the team became strong advocates for Amazon Redshift and now runs their primary production cluster on 32 ra3.16xlarge nodes.
As their data ingestion pipeline grew, query workloads began competing with data ingestion processes, creating performance bottlenecks. Rather than scaling up their primary cluster, they implemented a workload isolation strategy using Amazon Redshift data sharing. The customer launched a second 16-node ra3.4xlarge cluster as a data share consumer, with the primary cluster serving as the producer. This architecture allowed them to migrate consumption workloads to the consumer cluster while the producer focused on data ingestion, effectively supporting growth without increasing the primary cluster size.
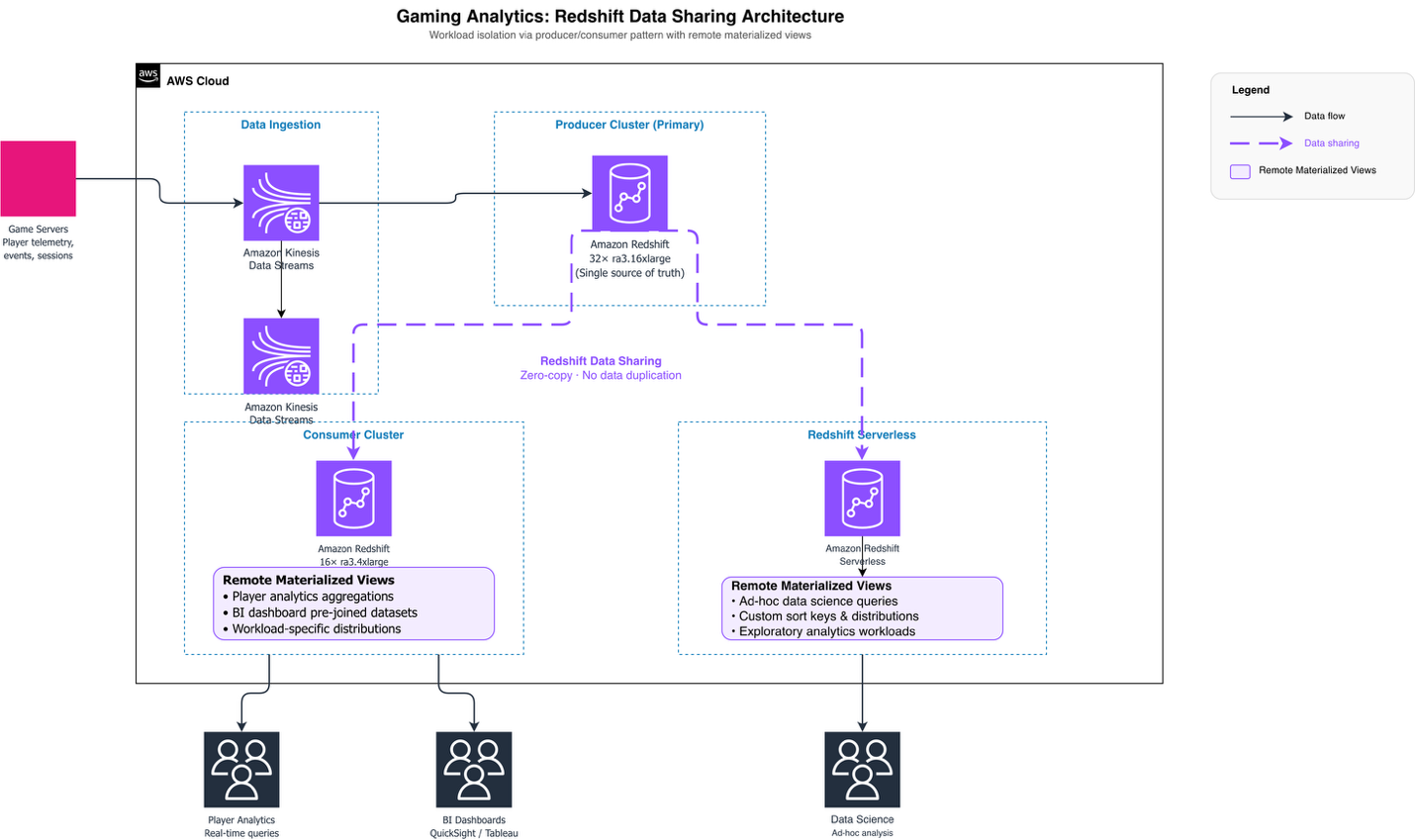
Recognizing the advantages of this distributed architecture, the gaming company expanded their approach by migrating workloads to Amazon Redshift Serverless, further using the data sharing model for workload isolation. Amazon Redshift’s remote materialized view capability allowed the gaming company to create materialized views directly on the data shared by the producer cluster. Each consumer cluster could now build materialized views optimized for its specific workload patterns. This created pre-aggregated datasets, custom join strategies, and workload-specific data distributions, without impacting the producer cluster’s performance or requiring data duplication. The producer warehouse maintains data distribution and sorting strategies designed for generic enterprise needs, providing consistent data quality across all consumers. Meanwhile, consumer warehouses used remote materialized views to fine-tune query performance for their distinct analytical requirements, whether supporting real-time player analytics, business intelligence dashboards, or ad-hoc data science workloads. This distributed approach to data consumption optimization proved essential for the gaming company. It delivered fast query performance across diverse analytical workloads while maintaining a single source of truth in the producer cluster and avoiding the operational overhead of managing redundant data copies.
Best practices
To get the most out of these new capabilities, consider the following best practices:
- Enable concurrency scaling on your Amazon Redshift clusters and Serverless workgroups to allow ETLs and user queries to run even faster, providing consistent report and dashboard performance.
- Set up usage limits for concurrency scaling on both Amazon Redshift provisioned clusters and Serverless workgroups by configuring an appropriate
MaxRPUsetting. This helps you avoid unexpected additional costs. For more information, see the Amazon Redshift usage limits documentation. - Use remote MVs to offload resource-intensive MV creation and refresh operations from your primary warehouse to remote data share clusters.
Conclusion
In this post, we walked through the new MV refresh features, remote table DDL capabilities, and expanded concurrency scaling support for zero-ETL and S3 auto-copy. These features help you move beyond the constraints of a single warehouse. They are particularly valuable for organizations managing distributed data architectures that require dynamic table management across multiple environments while maintaining data consistency and adapting quickly to changing workloads. To get started, make sure you are running the latest Amazon Redshift version. Then visit the Amazon Redshift documentation to learn more about concurrency scaling, data sharing, and materialized views.