AWS Big Data Blog
Securely process near-real-time data from Amazon MSK Serverless using an AWS Glue streaming ETL job with IAM authentication
Streaming data has become an indispensable resource for organizations worldwide because it offers real-time insights that are crucial for data analytics. The escalating velocity and magnitude of collected data has created a demand for real-time analytics. This data originates from diverse sources, including social media, sensors, logs, and clickstreams, among others. With streaming data, organizations gain a competitive edge by promptly responding to real-time events and making well-informed decisions.
In streaming applications, a prevalent approach involves ingesting data through Apache Kafka and processing it with Apache Spark Structured Streaming. However, managing, integrating, and authenticating the processing framework (Apache Spark Structured Streaming) with the ingesting framework (Kafka) poses significant challenges, necessitating a managed and serverless framework. For example, integrating and authenticating a client like Spark streaming with Kafka brokers and zookeepers using a manual TLS method requires certificate and keystore management, which is not an easy task and requires a good knowledge of TLS setup.
To address these issues effectively, we propose using Amazon Managed Streaming for Apache Kafka (Amazon MSK), a fully managed Apache Kafka service that offers a seamless way to ingest and process streaming data. In this post, we use Amazon MSK Serverless, a cluster type for Amazon MSK that makes it possible for you to run Apache Kafka without having to manage and scale cluster capacity. To further enhance security and streamline authentication and authorization processes, MSK Serverless enables you to handle both authentication and authorization using AWS Identity and Access Management (IAM) in your cluster. This integration eliminates the need for separate mechanisms for authentication and authorization, simplifying and strengthening data protection. For example, when a client tries to write to your cluster, MSK Serverless uses IAM to check whether that client is an authenticated identity and also whether it is authorized to produce to your cluster.
To process data effectively, we use AWS Glue, a serverless data integration service that uses the Spark Structured Streaming framework and enables near-real-time data processing. An AWS Glue streaming job can handle large volumes of incoming data from MSK Serverless with IAM authentication. This powerful combination ensures that data is processed securely and swiftly.
The post demonstrates how to build an end-to-end implementation to process data from MSK Serverless using an AWS Glue streaming extract, transform, and load (ETL) job with IAM authentication to connect MSK Serverless from the AWS Glue job and query the data using Amazon Athena.
Solution overview
The following diagram illustrates the architecture that you implement in this post.
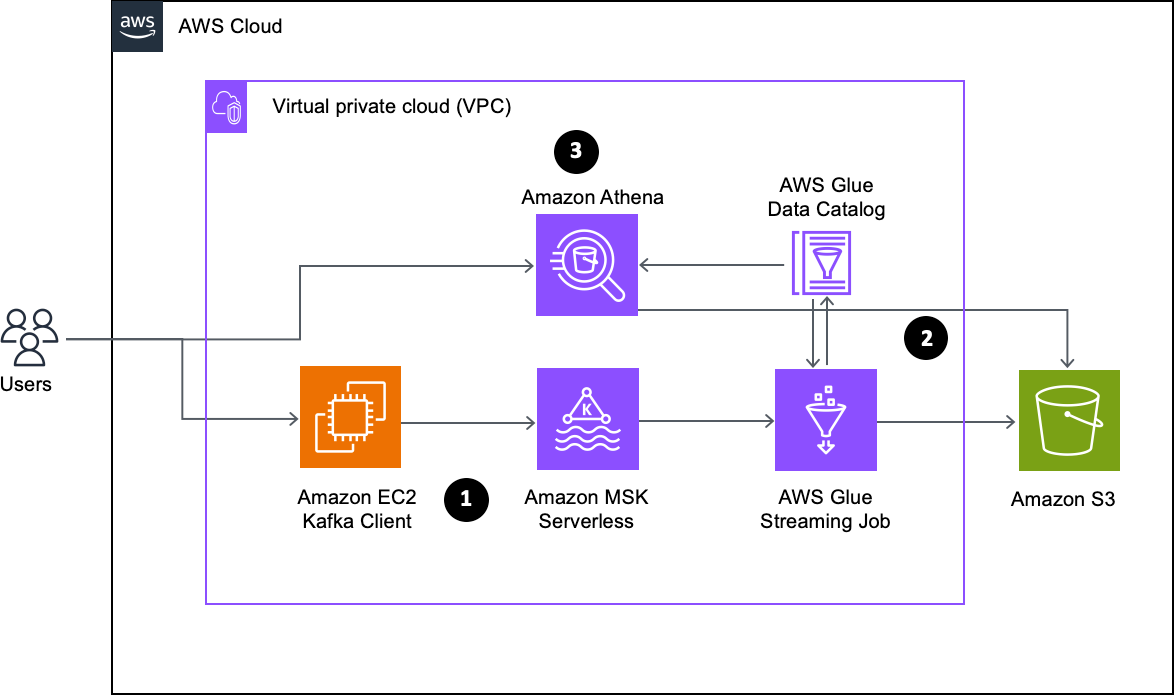
The workflow consists of the following steps:
- Create an MSK Serverless cluster with IAM authentication and an EC2 Kafka client as the producer to ingest sample data into a Kafka topic. For this post, we use the kafka-console-producer.sh Kafka console producer client.
- Set up an AWS Glue streaming ETL job to process the incoming data. This job extracts data from the Kafka topic, loads it into Amazon Simple Storage Service (Amazon S3), and creates a table in the AWS Glue Data Catalog. By continuously consuming data from the Kafka topic, the ETL job ensures it remains synchronized with the latest streaming data. Moreover, the job incorporates the checkpointing functionality, which tracks the processed records, enabling it to resume processing seamlessly from the point of interruption in the event of a job run failure.
- Following the data processing, the streaming job stores data in Amazon S3 and generates a Data Catalog table. This table acts as a metadata layer for the data. To interact with the data stored in Amazon S3, you can use Athena, a serverless and interactive query service. Athena enables the run of SQL-like queries on the data, facilitating seamless exploration and analysis.
For this post, we create the solution resources in the us-east-1 Region using AWS CloudFormation templates. In the following sections, we show you how to configure your resources and implement the solution.
Configure resources with AWS CloudFormation
In this post, you use the following two CloudFormation templates. The advantage of using two different templates is that you can decouple the resource creation of ingestion and processing part according to your use case and if you have requirements to create specific process resources only.
- vpc-mskserverless-client.yaml – This template sets up data the ingestion service resources such as a VPC, MSK Serverless cluster, and S3 bucket
- gluejob-setup.yaml – This template sets up the data processing resources such as the AWS Glue table, database, connection, and streaming job
Create data ingestion resources
The vpc-mskserverless-client.yaml stack creates a VPC, private and public subnets, security groups, S3 VPC Endpoint, MSK Serverless cluster, EC2 instance with Kafka client, and S3 bucket. To create the solution resources for data ingestion, complete the following steps:
- Launch the stack
vpc-mskserverless-clientusing the CloudFormation template:

- Provide the parameter values as listed in the following table.
| Parameters | Description | Sample Value |
EnvironmentName |
Environment name that is prefixed to resource names | . |
PrivateSubnet1CIDR |
IP range (CIDR notation) for the private subnet in the first Availability Zone | . |
PrivateSubnet2CIDR |
IP range (CIDR notation) for the private subnet in the second Availability Zone | . |
PublicSubnet1CIDR |
IP range (CIDR notation) for the public subnet in the first Availability Zone | . |
PublicSubnet2CIDR |
IP range (CIDR notation) for the public subnet in the second Availability Zone | . |
VpcCIDR |
IP range (CIDR notation) for this VPC | . |
InstanceType |
Instance type for the EC2 instance | t2.micro |
LatestAmiId |
AMI used for the EC2 instance | /aws/service/ami-amazon-linux- latest/amzn2-ami-hvm-x86_64-gp2 |
- When the stack creation is complete, retrieve the EC2 instance PublicDNS from the
vpc-mskserverless-clientstack’s Outputs tab.
The stack creation process can take around 15 minutes to complete.

- On the Amazon EC2 console, access the EC2 instance that you created using the CloudFormation template.
- Choose the EC2 instance whose
InstanceIdis shown on the stack’s Outputs tab.

Next, you log in to the EC2 instance using Session Manager, a capability of AWS Systems Manager.
- On the Amazon EC2 console, select the
instanceidand on the Session Manager tab, choose Connect.

After you log in to the EC2 instance, you create a Kafka topic in the MSK Serverless cluster from the EC2 instance.
- In the following export command, provide the
MSKBootstrapServersvalue from thevpc-mskserverless- clientstack output for your endpoint: - Run the following command on the EC2 instance to create a topic called
msk-serverless-blog. The Kafka client is already installed in the ec2-user home directory (/home/ec2-user).
After you confirm the topic creation, you can push the data to the MSK Serverless.
- Run the following command on the EC2 instance to create a console producer to produce records to the Kafka topic. (For source data, we use
nycflights.csvdownloaded at the ec2-user home directory/home/ec2-user.)
Next, you set up the data processing service resources, specifically AWS Glue components like the database, table, and streaming job to process the data.
Create data processing resources
The gluejob-setup.yaml CloudFormation template creates a database, table, AWS Glue connection, and AWS Glue streaming job. Retrieve the values for VpcId, GluePrivateSubnet, GlueconnectionSubnetAZ, SecurityGroup, S3BucketForOutput, and S3BucketForGlueScript from the vpc-mskserverless-client stack’s Outputs tab to use in this template. Complete the following steps:
- Launch the stack
gluejob-setup:
![]()
- Provide parameter values as listed in the following table.
| Parameters | Description | Sample value |
EnvironmentName |
Environment name that is prefixed to resource names. | Gluejob-setup |
VpcId |
ID of the VPC for security group. Use the VPC ID created with the first stack. | Refer to the first stack’s output. |
GluePrivateSubnet |
Private subnet used for creating the AWS Glue connection. | Refer to the first stack’s output. |
SecurityGroupForGlueConnection |
Security group used by the AWS Glue connection. | Refer to the first stack’s output. |
GlueconnectionSubnetAZ |
Availability Zone for the first private subnet used for the AWS Glue connection. | . |
GlueDataBaseName |
Name of the AWS Glue Data Catalog database. | glue_kafka_blog_db |
GlueTableName |
Name of the AWS Glue Data Catalog table. | blog_kafka_tbl |
S3BucketNameForScript |
Bucket Name for Glue ETL script. | Use the S3 bucket name from the previous stack. For example, aws-gluescript-${AWS::AccountId}-${AWS::Region}-${EnvironmentName} |
GlueWorkerType |
Worker type for AWS Glue job. For example, G.1X. | G.1X |
NumberOfWorkers |
Number of workers in the AWS Glue job. | 3 |
S3BucketNameForOutput |
Bucket name for writing data from the AWS Glue job. | aws-glueoutput-${AWS::AccountId}-${AWS::Region}-${EnvironmentName} |
TopicName |
MSK topic name that needs to be processed. | msk-serverless-blog |
MSKBootstrapServers |
Kafka bootstrap server. | boot-30vvr5lg.c1.kafka-serverless.us- east-1.amazonaws.com:9098 |
The stack creation process can take around 1–2 minutes to complete. You can check the Outputs tab for the stack after the stack is created.

In the gluejob-setup stack, we created a Kafka type AWS Glue connection, which consists of broker information like the MSK bootstrap server, topic name, and VPC in which the MSK Serverless cluster is created. Most importantly, it specifies the IAM authentication option, which helps AWS Glue authenticate and authorize using IAM authentication while consuming the data from the MSK topic. For further clarity, you can examine the AWS Glue connection and the associated AWS Glue table generated through AWS CloudFormation.
After successfully creating the CloudFormation stack, you can now proceed with processing data using the AWS Glue streaming job with IAM authentication.
Run the AWS Glue streaming job
To process the data from the MSK topic using the AWS Glue streaming job that you set up in the previous section, complete the following steps:
- On the CloudFormation console, choose the stack
gluejob-setup. - On the Outputs tab, retrieve the name of the AWS Glue streaming job from the
GlueJobNamerow. In the following screenshot, the name isGlueStreamingJob-glue-streaming-job.

- On the AWS Glue console, choose ETL jobs in the navigation pane.
- Search for the AWS Glue streaming job named
GlueStreamingJob-glue-streaming-job. - Choose the job name to open its details page.
- Choose Run to start the job.
- On the Runs tab, confirm if the job ran without failure.

- Retrieve the
OutputBucketNamefrom thegluejob-setup templateoutputs. - On the Amazon S3 console, navigate to the S3 bucket to verify the data.

- On the AWS Glue console, choose the AWS Glue streaming job you ran, then choose Stop job run.
Because this is a streaming job, it will continue to run indefinitely until manually stopped. After you verify the data is present in the S3 output bucket, you can stop the job to save cost.
Validate the data in Athena
After the AWS Glue streaming job has successfully created the table for the processed data in the Data Catalog, follow these steps to validate the data using Athena:
- On the Athena console, navigate to the query editor.
- Choose the Data Catalog as the data source.
- Choose the database and table that the AWS Glue streaming job created.
- To validate the data, run the following query to find the flight number, origin, and destination that covered the highest distance in a year:
The following screenshot shows the output of our example query.

Clean up
To clean up your resources, complete the following steps:
- Delete the CloudFormation stack
gluejob-setup. - Delete the CloudFormation stack
vpc-mskserverless-client.
Conclusion
In this post, we demonstrated a use case for building a serverless ETL pipeline for streaming with IAM authentication, which allows you to focus on the outcomes of your analytics. You can also modify the AWS Glue streaming ETL code in this post with transformations and mappings to ensure that only valid data gets loaded to Amazon S3. This solution enables you to harness the prowess of AWS Glue streaming, seamlessly integrated with MSK Serverless through the IAM authentication method. It’s time to act and revolutionize your streaming processes.
Appendix
This section provides more information about how to create the AWS Glue connection on the AWS Glue console, which helps establish the connection to the MSK Serverless cluster and allow the AWS Glue streaming job to authenticate and authorize using IAM authentication while consuming the data from the MSK topic.
- On the AWS Glue console, in the navigation pane, under Data catalog, choose Connections.
- Choose Create connection.
- For Connection name, enter a unique name for your connection.
- For Connection type, choose Kafka.
- For Connection access, select Amazon managed streaming for Apache Kafka (MSK).
- For Kafka bootstrap server URLs, enter a comma-separated list of bootstrap server URLs. Include the port number. For example,
boot-xxxxxxxx.c2.kafka-serverless.us-east- 1.amazonaws.com:9098.

- For Authentication, choose IAM Authentication.
- Select Require SSL connection.
- For VPC, choose the VPC that contains your data source.
- For Subnet, choose the private subnet within your VPC.
- For Security groups, choose a security group to allow access to the data store in your VPC subnet.
Security groups are associated to the ENI attached to your subnet. You must choose at least one security group with a self-referencing inbound rule for all TCP ports.
- Choose Save changes.

After you create the AWS Glue connection, you can use the AWS Glue streaming job to consume data from the MSK topic using IAM authentication.
About the authors
 Shubham Purwar is a Cloud Engineer (ETL) at AWS Bengaluru specialized in AWS Glue and Amazon Athena. He is passionate about helping customers solve issues related to their ETL workload and implement scalable data processing and analytics pipelines on AWS. In his free time, Shubham loves to spend time with his family and travel around the world.
Shubham Purwar is a Cloud Engineer (ETL) at AWS Bengaluru specialized in AWS Glue and Amazon Athena. He is passionate about helping customers solve issues related to their ETL workload and implement scalable data processing and analytics pipelines on AWS. In his free time, Shubham loves to spend time with his family and travel around the world.
 Nitin Kumar is a Cloud Engineer (ETL) at AWS with a specialization in AWS Glue. He is dedicated to assisting customers in resolving issues related to their ETL workloads and creating scalable data processing and analytics pipelines on AWS.
Nitin Kumar is a Cloud Engineer (ETL) at AWS with a specialization in AWS Glue. He is dedicated to assisting customers in resolving issues related to their ETL workloads and creating scalable data processing and analytics pipelines on AWS.